



📢 转载信息
原文作者:Roy Allela, Arun Kumar Lokanatha, Anirudh Viswanathan, Arun Nagarajan, Trevor Harvey, Oleg Talalov, and Qianlin Liang
现代人工智能基础设施需要在同一集群上为多种并发工作负载提供服务,包括基础模型(FM)预训练、微调、生产推理和评估。在这种共享环境中,由于推理工作负载随流量模式扩展,以及实验完成并释放资源,对 AI 加速器的需求会持续波动。尽管 AI 加速器的可用性是动态变化的,但传统的训练工作负载仍被锁定在其初始的计算分配中,无法在没有人工干预的情况下利用空闲的计算容量。
Amazon SageMaker HyperPod 现在支持弹性训练,使您的机器学习(ML)工作负载能够根据资源可用性自动扩展。在本文中,我们将演示弹性训练如何通过动态资源适应性,在保持训练质量和最小化人工干预的情况下,帮助您最大化 GPU 利用率、降低成本并加速模型开发。
静态分配对基础设施利用率的影响
考虑一个运行训练和推理工作负载的 256 GPU 集群。在夜间的非高峰时段,推理可能会释放 96 个 GPU。这留下了 96 个空闲的 GPU 可用于加速训练。传统训练作业以固定的规模运行;此类作业无法吸收空闲的计算容量。结果是,一个最初使用 32 个 GPU 的训练作业被锁定在此初始配置,而另外 96 个 GPU 保持空闲;这相当于每天浪费 2,304 个 GPU 小时,代表每天花费数千美元在利用率不足的基础设施投资上。随着集群规模的扩大,这个问题会更加严重。
动态扩展分布式训练在技术上很复杂。即使有了支持弹性的基础设施,您也需要停止作业、重新配置资源、调整并行化并重新划分检查点。保持训练进度和模型准确性贯穿这些转换的需要,使这一复杂性加剧。尽管 SageMaker HyperPod with Amazon EKS 以及 PyTorch 和 NeMo 等框架提供了底层支持,但手动干预仍然可能消耗 ML 工程师数小时的时间。根据加速器可用性反复调整训练运行的需求,会分散团队在模型开发上的精力。
资源共享和工作负载抢占增加了另一层复杂性。当前的系统缺乏优雅地处理来自更高优先级工作负载的部分资源请求的能力。考虑这样一个场景:一个关键的微调作业需要 8 个 GPU,而一个预训练工作负载占用了集群中的所有 32 个 GPU。今天的系统迫使我们做出二元选择:要么停止整个预训练作业,要么拒绝为更高优先级的加载程序分配资源,即使 24 个 GPU 已经足够以缩减的规模继续进行预训练。这种限制导致组织过度配置基础设施以避免资源争用,从而导致待处理作业队列变大、成本增加和集群效率降低。
解决方案概述
SageMaker HyperPod 现在提供弹性训练。训练工作负载可以自动扩展以利用可用的加速器,并在需要将资源用于其他地方时优雅地收缩,同时保持训练质量。SageMaker HyperPod 管理着检查点管理、等级重新分配和进程协调的复杂编排,最大限度地减少了手动干预,并帮助团队专注于模型开发而非基础设施管理。
SageMaker HyperPod 训练操作员与 Kubernetes 控制平面和资源调度器集成,以做出扩展决策。它会监控 Pod 生命周期事件、节点可用性和调度器优先级信号。这使得它几乎可以即时检测到扩展机会,无论是来自新可用的资源还是来自更高优先级工作负载的新请求。在启动任何转换之前,操作员会根据配置的策略(最小和最大节点边界、扩展频率限制)评估潜在的扩展操作,然后启动转换。
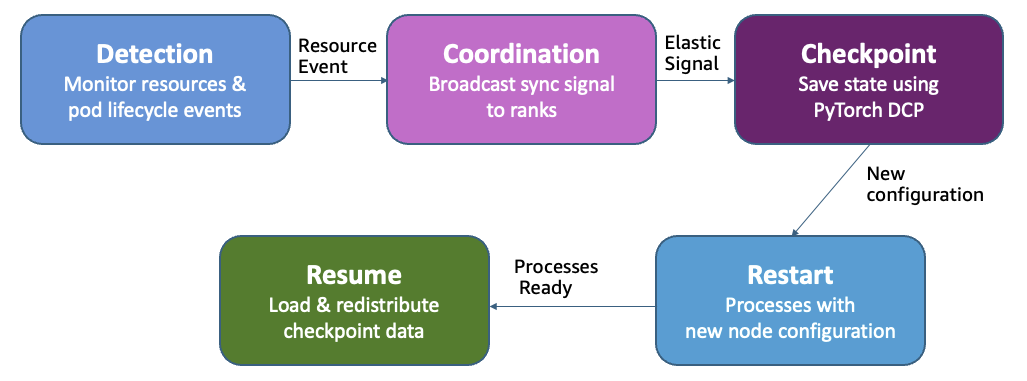
弹性训练扩展事件工作流
弹性训练在保持全局批次大小恒定的同时添加或移除数据并行副本。当资源可用时,新的副本加入并加速吞吐量,而不影响收敛。当更高优先级的作业需要资源时,系统会移除副本而不是终止整个作业。训练在降低的容量下继续。
当发生扩展事件时,操作员会向所有等级广播一个同步信号。每个进程完成其当前步骤并使用 PyTorch 分布式检查点(DCP)保存状态。随着新副本的加入或现有副本的离开,操作员会重新计算等级分配,并跨训练作业启动进程重启。然后 DCP 会加载并重新分配检查点数据以匹配新的副本计数,确保每个工作进程都具有正确的模型和优化器状态。训练在调整后的副本下恢复,并且恒定的全局批次大小确保了收敛不受影响。
对于使用 Kueue(包括 SageMaker HyperPod 任务治理)的集群,弹性训练通过多个准入请求实现智能工作负载管理。操作员首先以高优先级请求所需的最少资源,然后以较低优先级逐步请求额外的容量。这种方法支持部分抢占:当需要更高优先级的资源时,只有较低优先级的副本才会被撤销,从而允许训练在保证的基线上继续进行,而不是完全终止。

开始使用弹性训练
在接下来的部分中,我们将指导您完成在 SageMaker HyperPod 上设置和配置弹性训练的过程。
先决条件
在将弹性训练集成到您的训练工作负载之前,请确保您的环境满足以下要求:
- 由 Amazon EKS(Kubernetes v1.32 及更高版本)编排的 SageMaker HyperPod 集群。有关创建 SageMaker HyperPod EKS 集群的信息,请参阅使用 Amazon EKS 编排创建 SageMaker HyperPod 集群。
- 已在集群上安装了 v1.2 及更高版本的 HyperPod 训练操作员。
- 已安装 v1.3.1 及更高版本的 SageMaker HyperPod 任务治理,用于作业排队、优先级设置和调度。
配置命名空间隔离和资源控制
如果您使用集群自动伸缩(如 Karpenter),请设置命名空间级别的 ResourceQuotas。如果没有这些限制,弹性训练的资源请求可能会触发无限的节点预配。ResourceQuotas 限制了作业可以请求的最大资源,同时仍允许在定义的边界内进行弹性行为。
以下代码是命名空间(限制为 8 个 ml.p5.48xlarge 实例)的 ResourceQuota 示例(每个实例有 8 个 NVIDIA H100 GPU、192 个 vCPU 和 640 GiB 内存,因此 8 个实例 = 64 个 GPU、1,536 个 vCPU 和 5,120 GiB 内存):
apiVersion: v1
kind: ResourceQuota
metadata: name: training-quota namespace: team-ml
spec:
hard:
nvidia.com/gpu: "64"
vpc.amazonaws.com/efa: "256"
requests.cpu: "1536"
requests.memory: "5120Gi"
limits.cpu: "1536"
limits.memory: "5120Gi"
我们建议按团队或项目将工作负载组织到单独的命名空间中,并使用 AWS 身份和访问管理 (IAM) 基于角色的访问控制 (RBAC) 映射来支持适当的访问控制和资源隔离。
构建 HyperPod 训练容器
HyperPod 训练操作员使用来自 HyperPod Elastic Agent Python 包的自定义 PyTorch 启动器来检测扩展事件、协调检查点操作并在世界大小改变时管理集合过程。安装弹性代理,然后在启动命令中将 torchrun 替换为 hyperpodrun。有关更多详细信息,请参阅HyperPod 弹性代理。
以下代码是训练容器配置的示例:
FROM <YOUR-BASE-IMAGE>
RUN pip install hyperpod-elastic-agent # insall hyperpod-elastic-agent
ENTRYPOINT ["entrypoint.sh"] # entrypoint.sh ...
hyperpodrun --nnodes=node_count --nproc-per-node=proc_count \
--rdzv-backend hyperpod \
在训练代码中启用弹性扩展:
完成以下步骤以在训练代码中启用弹性扩展:
- 将 HyperPod 弹性代理导入添加到您的训练脚本中,以检测何时发生扩展事件:
from hyperpod_elastic_agent.elastic_event_handler import elastic_event_detected- 修改您的训练循环,以便在每个训练批次后检查弹性事件。当检测到扩展事件时,您的训练过程需要保存检查点并优雅地退出,以便操作员可以使用新的世界大小重新启动作业:
def train_epoch(model, dataloader, optimizer, args):
for batch_idx, batch_data in enumerate(dataloader):
# Forward and backward pass
loss = model(batch_data).loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Check if we should checkpoint (periodic or scaling event)
should_checkpoint = (batch_idx + 1) % args.checkpoint_freq == 0
elastic_event = elastic_event_detected() # Returns True when scaling is needed
# Save checkpoint if scaling-up or scaling down job
if should_checkpoint or elastic_event:
save_checkpoint(model, optimizer, scheduler, checkpoint_dir=args.checkpoint_dir, step=global_step)
if elastic_event:
# Exit gracefully - operator will restart with new world size
print("Elastic scaling event detected. Checkpoint saved.")
return
这里的关键模式是在训练循环中检查 elastic_event_detected(),并在保存检查点后从训练函数返回。这允许训练操作员协调所有工作进程之间的扩展转换。
- 最后,使用 PyTorch DCP 实现检查点保存和加载函数。DCP 对于弹性训练至关重要,因为它在作业以不同数量的副本恢复时会自动重新划分模型和优化器状态:
import torch.distributed.checkpoint as dcp
from torch.distributed.checkpoint.state_dict import get_state_dict, set_state_dict
def save_checkpoint(model, optimizer, lr_scheduler, user_content, checkpoint_path):
"""Save checkpoint using DCP for elastic training."""
state_dict = {
"model": model,
"optimizer": optimizer,
"lr_scheduler": lr_scheduler,
**user_content
}
dcp.save(
state_dict=state_dict,
storage_writer=dcp.FileSystemWriter(checkpoint_path)
)
def load_checkpoint(model, optimizer, lr_scheduler, checkpoint_path):
"""Load checkpoint using DCP with automatic resharding."""
state_dict = {
"model": model,
"optimizer": optimizer,
"lr_scheduler": lr_scheduler
}
dcp.load(
state_dict=state_dict,
storage_reader=dcp.FileSystemReader(checkpoint_path)
)
return model, optimizer, lr_scheduler
对于每个数据样本必须恰好查看一次的单周期训练场景,您必须在扩展事件中持久化数据加载器状态。没有它,当您的作业以不同的世界大小恢复时,先前处理的样本可能会被重复或跳过,从而影响训练质量。有状态的数据加载器在检查点期间保存和恢复数据加载器的位置,确保训练从停止的确切点继续。有关实现细节,请参阅文档中的有状态数据加载器指南。
提交弹性训练作业
构建了训练容器并对代码进行了检测后,您就可以提交弹性训练作业了。作业规范通过 elasticPolicy 配置定义了您的训练工作负载如何根据集群资源可用性进行扩展。
创建一个 HyperPodPyTorchJob 规范,使用以下代码定义您的弹性扩展行为:
apiVersion: sagemaker.amazonaws.com/v1
kind: HyperPodPyTorchJob
metadata: name: elastic-training-job
spec:
elasticPolicy:
minReplicas: 2 # Minimum replicas to keep training running
maxReplicas: 8 # Maximum replicas for scale-up
replicaIncrementStep: 2 # Scale in fixed increments of 2 nodes
# Alternative: use replicaDiscreteValues: [2, 4, 8] for specific scale points
gracefulShutdownTimeoutInSeconds: 600 # Time allowed for checkpoint save
scalingTimeoutInSeconds: 60 # Delay before initiating scale-up
faultyScaleDownTimeoutInSeconds: 30 # Wait time before scaling down on failures
replicaSpecs:
- name: worker
replicas: 2 # Initial replica count
maxReplicas: 8 # Must match elasticPolicy.maxReplicas
template:
spec:
containers:
- name: pytorch
image: <your-training-container>
command: ["hyperpodrun"]
args:
- "--nnodes=2"
- "--nproc-per-node=8"
- "--rdzv-backend=hyperpod"
- "train.py"
resources:
requests:
nvidia.com/gpu: 8
vpc.amazonaws.com/efa: 32
limits:
nvidia.com/gpu: 8
vpc.amazonaws.com/efa: 32
elasticPolicy 配置控制您的训练作业如何响应资源变化:
minReplicas和maxReplicas:这些定义了扩展边界。您的作业将始终保持至少minReplicas,且不超过maxReplicas,从而保持可预测的资源使用情况。replicaIncrementStep与replicaDiscreteValues:选择一种方法进行扩展粒度控制。使用replicaIncrementStep进行统一扩展(例如,步长为 2 意味着扩展到 2、4、6、8 个节点)。使用replicaDiscreteValues: [2, 4, 8]指定确切允许的配置。当某些世界大小更适合您模型的并行化策略时,这非常有用。gracefulShutdownTimeoutInSeconds:这会给予您的训练过程时间在操作员强制关机前完成检查点保存。根据您的检查点大小和存储性能设置此值。scalingTimeoutInSeconds:这会在扩展前引入一个稳定延迟,以防止在资源快速波动时出现剧烈抖动(thrashing)。操作员在检测到可用资源后会等待此持续时间,然后才触发扩展事件。faultyScaleDownTimeoutInSeconds:当 Pod 发生故障或崩溃时,操作员会等待此持续时间进行恢复,然后才向下扩展。这可以防止因瞬时故障而导致不必要的向下扩展。
弹性训练整合了抗抖动机制,以在资源可用性快速波动的环境中保持稳定性。这些保护措施包括对扩展事件之间强制执行的最小稳定周期以及针对频繁转换的指数退避策略。通过防止过度波动,系统确保训练作业在每个规模点都能取得有意义的进展,而不是被频繁的检查点操作所压倒。您可以在弹性策略配置中调整这些抗抖动策略,从而在响应式扩展和训练稳定性之间取得平衡,以符合其特定的集群动态和工作负载要求。
然后,您可以使用 kubectl 或 SageMaker HyperPod CLI 提交作业,如文档中所述:
kubectl apply -f elastic-job.yaml使用 SageMaker HyperPod 蓝图(Recipes)
我们为 Llama 和 GPT-OSS 等公开可用的 FM 创建了用于弹性训练的 SageMaker HyperPod 蓝图。这些蓝图提供了经过预先验证的配置,可以自动处理并行化策略、超参数调整和检查点管理,只需要对 YAML 配置进行更改即可指定弹性策略,无需修改代码。团队只需在作业规范中指定最小和最大节点边界,系统就会在集群资源波动时管理所有扩展协调。
# Enable elastic training in an existing recipe
python launcher.py \
recipes=llama/llama3_1_8b_sft \
recipes.elastic_policy.is_elastic=true \
recipes.elastic_policy.min_nodes=2 \
recipes.elastic_policy.max_nodes=8蓝图还通过 scale_config 字段支持特定于规模的配置,因此您可以为每个世界大小定义不同的超参数(批次大小、学习率)。当扩展需要调整批次分布或启用不均匀批次大小时,这特别有用。有关详细示例,请参阅 SageMaker HyperPod Recipes 仓库。
性能结果
为了演示弹性训练的影响,我们在一个最多包含 8 个 ml.p5.48xlarge 实例的 SageMaker HyperPod 集群上,使用 TAT-QA 数据集对 Llama-3 70B 模型进行了微调。此基准测试说明了弹性训练在响应资源可用性动态扩展时的实际表现,模拟了一个训练和推理工作负载共享集群容量的真实环境。
我们从两个关键维度评估了弹性训练:扩展转换期间的训练吞吐量和模型收敛情况。如以下图中所示,我们在 1 个节点到 8 个节点的各种扩展配置中观察到吞吐量持续提高。训练性能从 1 个节点的 2,000 tokens/秒提高到 8 个节点的 14,000 tokens/秒。在整个训练过程中,随着模型训练继续收敛,损失持续下降。
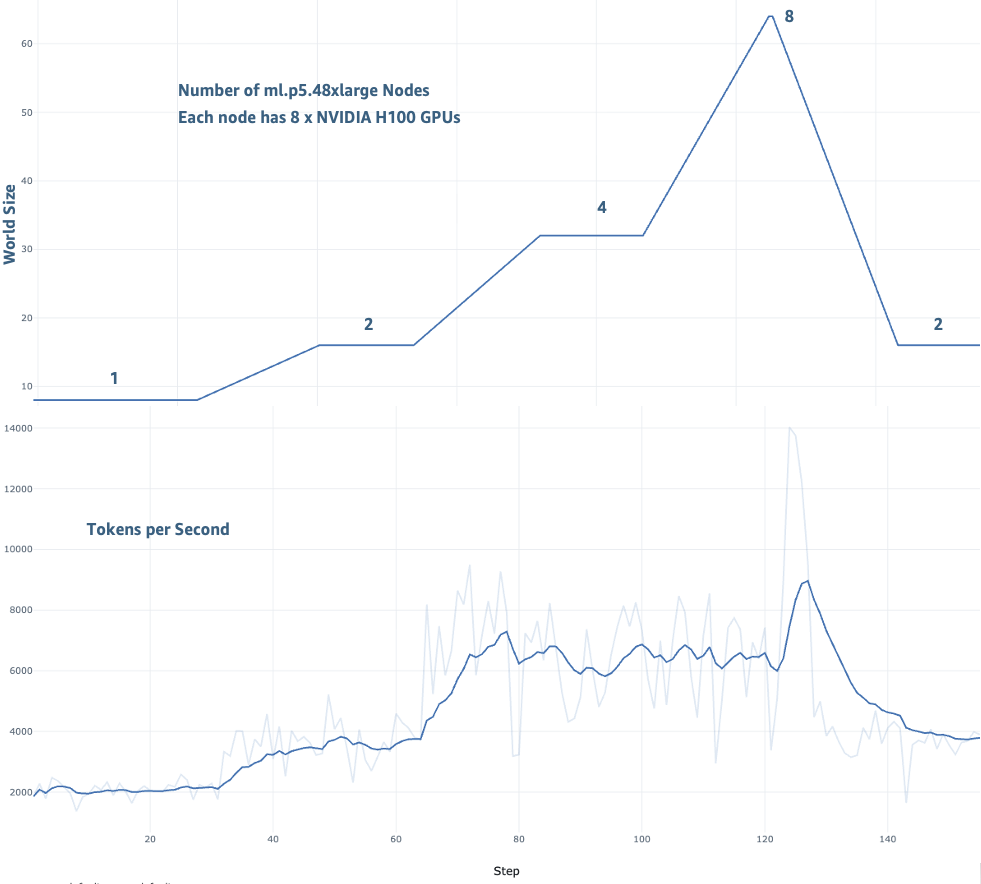
使用弹性训练的训练吞吐量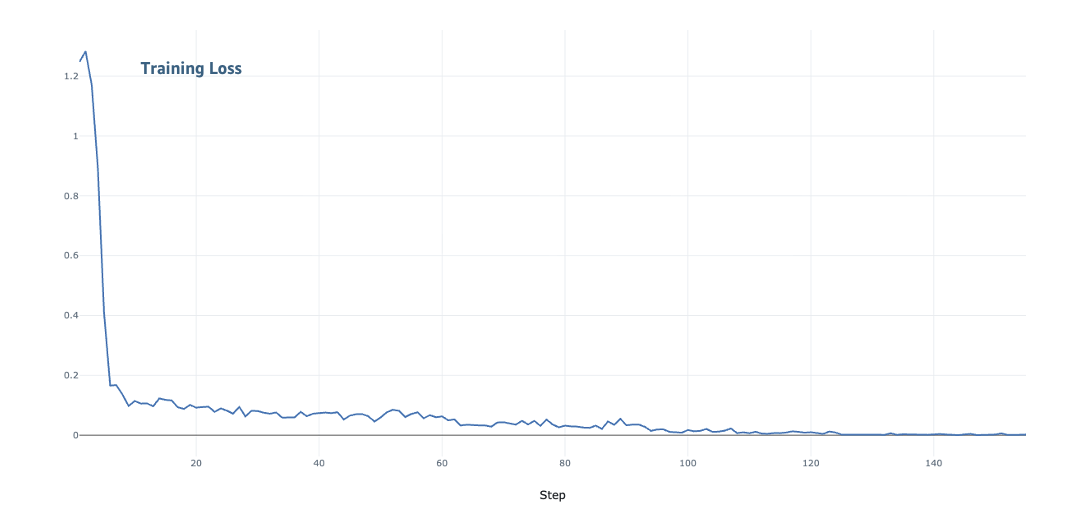
使用弹性训练的模型收敛情况
与 SageMaker HyperPod 功能集成
除了其核心扩展能力外,弹性训练还利用了与 SageMaker HyperPod 基础设施功能的集成。任务治理策略在工作负载优先级发生变化时自动触发扩展事件,使训练能够将资源让给更高优先级的推理或评估工作负载。对 SageMaker 训练计划的支持允许训练利用成本优化容量类型进行机会性扩展,同时通过在回收 Spot 实例时自动缩小规模来保持弹性。SageMaker HyperPod 可观察性插件补充了这些功能,提供了有关扩展事件、检查点性能和训练进度的详细见解,帮助团队监控和优化其弹性训练部署。
结论
SageMaker HyperPod 上的弹性训练解决了 AI 集群中资源浪费的问题。现在,训练作业可以在资源可用时自动扩展,而无需手动进行基础设施调整。弹性训练的技术架构在扩展转换过程中保持了训练质量。通过在不同的数据并行配置中保持全局批次大小和学习率恒定,系统确保了无论当前规模如何,收敛特性都能保持一致。
您可以期待三个主要好处。首先,从操作角度来看,减少手动重新配置周期从根本上改变了 ML 团队的工作方式。工程师可以专注于模型创新和开发,而不是基础设施管理,从而显著提高团队生产力并降低运营开销。其次,由于训练工作负载动态消耗可用容量,基础设施效率得到了显著提高,从而大幅减少了空闲 GPU 小时数和相应的成本节约。第三,由于训练作业自动扩展以利用可用资源,上市时间(time-to-market)大大加快,从而实现了更快的模型开发和部署周期。
要开始使用,请参阅文档指南。示例实现和蓝图可在GitHub 仓库中找到。
关于作者
 Roy Allela 是 AWS 的高级 AI/ML 解决方案架构师。他帮助 AWS 客户,从小型初创公司到大型企业,在 AWS 上高效地训练和部署基础模型。他拥有微处理器工程背景,热衷于计算优化问题和提高 AI 工作负载的性能。您可以在LinkedIn上与 Roy 联系。
Roy Allela 是 AWS 的高级 AI/ML 解决方案架构师。他帮助 AWS 客户,从小型初创公司到大型企业,在 AWS 上高效地训练和部署基础模型。他拥有微处理器工程背景,热衷于计算优化问题和提高 AI 工作负载的性能。您可以在LinkedIn上与 Roy 联系。
 Anirudh Viswanathan 是 AWS SageMaker 团队的高级技术产品经理,专注于机器学习。他拥有卡内基梅隆大学机器人学硕士学位和沃顿商学院 MBA 学位。Anirudh 是 50 多项 AI/ML 专利的署名发明人。他喜欢长跑、参观艺术画廊和观看百老汇演出。您可以在LinkedIn上与 Anirudh 联系。
Anirudh Viswanathan 是 AWS SageMaker 团队的高级技术产品经理,专注于机器学习。他拥有卡内基梅隆大学机器人学硕士学位和沃顿商学院 MBA 学位。Anirudh 是 50 多项 AI/ML 专利的署名发明人。他喜欢长跑、参观艺术画廊和观看百老汇演出。您可以在LinkedIn上与 Anirudh 联系。
 Arun Kumar Lokanatha 是 Amazon SageMaker AI 的高级 ML 解决方案架构师。他拥有伊利诺伊大学厄巴纳-香槟分校数据科学专业硕士学位。他专注于生成式 AI 工作负载,帮助客户使用 SageMaker HyperPod、SageMaker 训练作业和 SageMaker 分布式训练来构建和部署 LLM。工作之余,他喜欢跑步、徒步旅行和烹饪。
Arun Kumar Lokanatha 是 Amazon SageMaker AI 的高级 ML 解决方案架构师。他拥有伊利诺伊大学厄巴纳-香槟分校数据科学专业硕士学位。他专注于生成式 AI 工作负载,帮助客户使用 SageMaker HyperPod、SageMaker 训练作业和 SageMaker 分布式训练来构建和部署 LLM。工作之余,他喜欢跑步、徒步旅行和烹饪。
 Oleg Talalov 是 AWS 的高级软件开发工程师,在 SageMaker HyperPod 团队工作,专注于 ML 和用于 ML 训练的高性能计算基础设施。他拥有彼得大帝圣彼得堡理工大学硕士学位。Oleg 是多项 AI/ML 技术的发明人,喜欢骑自行车、游泳和跑步。您可以在LinkedIn上与 Oleg 联系。
Oleg Talalov 是 AWS 的高级软件开发工程师,在 SageMaker HyperPod 团队工作,专注于 ML 和用于 ML 训练的高性能计算基础设施。他拥有彼得大帝圣彼得堡理工大学硕士学位。Oleg 是多项 AI/ML 技术的发明人,喜欢骑自行车、游泳和跑步。您可以在LinkedIn上与 Oleg 联系。
 Qianlin Liang 是 AWS SageMaker 团队的软件开发工程师,专注于 AI 系统。他拥有马萨诸塞大学阿默斯特分校计算机科学博士学位。他的研究致力于开发用于高效和有弹性机器学习的系统技术。工作之余,他喜欢跑步和摄影。您可以在 LinkedIn 上与 Qianlin 联系。
Qianlin Liang 是 AWS SageMaker 团队的软件开发工程师,专注于 AI 系统。他拥有马萨诸塞大学阿默斯特分校计算机科学博士学位。他的研究致力于开发用于高效和有弹性机器学习的系统技术。工作之余,他喜欢跑步和摄影。您可以在 LinkedIn 上与 Qianlin 联系。
 Trevor Harvey 是亚马逊网络服务(AWS)的生成式 AI 首席专家和 AWS 认证解决方案架构师 – 专业级。在 AWS,Trevor 与客户合作设计和实施机器学习解决方案,并领导生成式 AI 服务的上市战略。
Trevor Harvey 是亚马逊网络服务(AWS)的生成式 AI 首席专家和 AWS 认证解决方案架构师 – 专业级。在 AWS,Trevor 与客户合作设计和实施机器学习解决方案,并领导生成式 AI 服务的上市战略。
 Anirban Roy 是 AWS SageMaker 团队的首席工程师,主要关注 AI 训练基础设施、弹性和可观察性。他拥有印度统计学院(加尔各答)计算机科学硕士学位。Anirban 是一位经验丰富的分布式软件系统构建者,拥有 20 多年的经验以及多项专利和出版物。他喜欢公路自行车、阅读非虚构类书籍、园艺和自然旅行。您可以在 LinkedIn 上与 Anirban 联系。
Anirban Roy 是 AWS SageMaker 团队的首席工程师,主要关注 AI 训练基础设施、弹性和可观察性。他拥有印度统计学院(加尔各答)计算机科学硕士学位。Anirban 是一位经验丰富的分布式软件系统构建者,拥有 20 多年的经验以及多项专利和出版物。他喜欢公路自行车、阅读非虚构类书籍、园艺和自然旅行。您可以在 LinkedIn 上与 Anirban 联系。
 Arun Nagarajan 是 Amazon SageMaker AI 的首席工程师,目前专注于整个技术栈的分布式训练。自 SageMaker 团队成立之初加入以来,Arun 为 SageMaker AI 中的多个产品做出了贡献,包括实时推理和 MLOps 解决方案。当他不从事机器学习基础设施工作时,他喜欢探索太平洋西北地区的户外活动和滑雪。
Arun Nagarajan 是 Amazon SageMaker AI 的首席工程师,目前专注于整个技术栈的分布式训练。自 SageMaker 团队成立之初加入以来,Arun 为 SageMaker AI 中的多个产品做出了贡献,包括实时推理和 MLOps 解决方案。当他不从事机器学习基础设施工作时,他喜欢探索太平洋西北地区的户外活动和滑雪。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区