



📢 转载信息
原文作者:Jayashree R, Fahim Surani, and Harsha Pradha
在亚马逊阿联酋站(Amazon.ae),我们每月为中东和北非地区的五个国家(阿联酋、沙特阿拉伯、埃及、土耳其和南非)的大约1000万客户提供服务。我们的AMET(非洲、中东和土耳其)支付团队负责管理这些多元化国家/地区的支付选择、交易、体验和分期付款功能,平均每月发布五项新功能。每项功能都需要全面的测试用例生成,这传统上会占用每个项目一周的手动工作量。我们的质量保证(QA)工程师将这些时间用于分析业务需求文档(BRD)、设计文档、UI模拟和历史测试准备工作——仅测试用例创建每年就需要一名全职工程师。
为了改进这一手动流程,我们开发了SAARAM(QA生命周期应用),这是一个多智能体AI解决方案,可帮助将测试用例生成时间从1周缩短到几小时。使用Anthropic的Claude Sonnet和Strands Agents SDK的Amazon Bedrock,我们将生成测试用例所需的时间从1周缩短到短短几个小时,同时还提高了测试覆盖率质量。我们的解决方案展示了研究人类认知模式(而不是仅仅优化AI算法)如何能够创建出增强而非取代人类专业知识的生产级系统。
在本文中,我们将解释如何通过以人为本的方法克服单智能体AI系统的局限性,实施结构化输出来显著减少幻觉,并构建了一个可扩展的解决方案,该方案目前正计划扩展到整个AMET QA团队,随后扩展到国际新兴商店和支付组织(IESP)中的其他QA团队。
解决方案概述
AMET支付QA团队负责验证影响数百万客户在不同监管环境和支付方式下的支付功能的代码部署。我们手动化的测试用例生成流程增加了产品周期中的周转时间(TAT),占用了宝贵的工程资源用于重复性的测试准备和文档任务,而不是战略性测试工作。我们需要一个自动化的解决方案,该方案能够在保持我们质量标准的同时,减少所需的时间投入。
我们的目标包括将测试用例创建时间从1周缩短到几小时以内,捕获经验丰富的测试人员的机构知识,标准化跨团队的测试方法,并最大限度地减少AI系统中常见的幻觉问题。该解决方案需要处理跨越多种支付方式、区域法规和客户群的复杂业务需求,同时生成与我们现有测试管理系统保持一致的具体、可操作的测试用例。
该架构采用了复杂的多智能体工作流程。为实现这一点,我们经历了3次不同的迭代,并随着新技术的开发和新模型的部署而持续改进和增强。
传统AI方法的挑战
我们最初的尝试遵循了传统的AI方法,即将整个BRD输入给单个AI智能体以生成测试用例。这种方法通常会产生像“验证支付是否正确工作”这样泛泛的输出,而不是我们的QA团队所需要的具体、可操作的测试用例。例如,我们需要像这样具体的测试用例:“验证当阿联酋客户对高于1,000迪拉姆的订单选择货到付款(COD)并使用已保存的信用卡时,系统显示11迪拉姆的COD费用,并通过COD网关处理付款,订单状态转换为‘等待派送’。”
单智能体方法存在几个关键限制。上下文长度限制阻碍了对大型文档的有效处理,而缺乏专业化的处理阶段意味着AI无法理解测试优先级或基于风险的方法。此外,幻觉问题产生了与测试工作无关的场景,可能会误导QA工作。根本原因很明显:AI试图在没有经验丰富的测试人员在分析需求时所采用的迭代思维过程的情况下,压缩复杂的业务逻辑。
下面的流程图说明了我们尝试使用单个智能体和综合提示时遇到的问题。

以人为本的突破
我们的突破源于对方法的根本性转变。我们没有问“AI应该如何思考测试?”,而是问“有经验的人类是如何思考测试的?”,着重于遵循特定的分步流程,而不是仅仅依靠大型语言模型(LLM)自行实现这一点。这种理念上的转变促使我们对高级QA专业人员进行了研究访谈,详细研究了他们的认知工作流程。
我们发现,有经验的测试人员不会整体处理文档——他们会经历专门的思维阶段。首先,他们通过提取验收标准、识别客户旅程、理解用户体验要求、映射产品需求、分析用户数据和评估工作流能力来分析文档。然后,他们通过一个系统化的过程开发测试:旅程分析、场景识别、数据流映射、测试用例开发,最后是组织和优先级排序。
然后,我们将原始智能体的功能分解为作为各个步骤的顺序思维动作。我们使用Amazon Q Developer for CLI构建和测试了每个步骤,以确保基本理念是合理的,并且同时纳入了主要和次要输入。
这一见解使我们设计了模仿这些专家测试方法的专用智能体的SAARAM。每个智能体都专注于测试过程的特定方面,例如人类专家如何在精神上划分不同的分析阶段。
带有Strands Agents的多智能体架构
基于我们对人类QA工作流程的理解,我们最初尝试从头开始构建自己的智能体。我们必须创建自己的循环、串行或并行执行。我们还创建了自己的编排和工作流图,这需要大量的手动工作。为了解决这些挑战,我们迁移到了Strands Agents SDK。它提供了多智能体编排功能,这对于协调复杂、相互依赖的任务至关重要,同时保持清晰的执行路径,有助于提高我们的性能并缩短开发时间。
工作流程迭代1:端到端测试生成
SAARAM的第一版由一个单一输入组成,并创建了我们的第一个专用智能体。它涉及通过五个专用智能体处理工作文档,以生成全面的测试覆盖范围。
智能体1被称为客户细分创建器(Customer Segment Creator),它专注于客户细分分析,并使用四个子智能体:
- 客户细分发现(Customer Segment Discovery)识别产品用户细分
- 决策矩阵生成器(Decision Matrix Generator)创建基于参数的矩阵
- 端到端场景创建(E2E Scenario Creation)为每个细分开发端到端(E2E)场景
- 测试步骤生成(Test Steps Generation)详细的测试用例开发
智能体2被称为用户旅程映射器(User Journey Mapper),它采用四个子智能体来全面映射产品旅程:
- 流程图和序列图是使用Mermaid语法的创建者。
- 端到端场景生成器建立在这些图表之上。
- 测试步骤生成器用于详细的测试文档。
智能体3被称为客户细分x旅程覆盖率(Customer Segment x Journey Coverage),它结合了智能体1和2的输入,以创建细分的分析。它使用四个子智能体:
- 基于Mermaid的流程图
- 用户旅程
- 每个客户细分的序列图
- 相应的测试步骤。
智能体4被称为状态转换智能体(State Transition Agent)。它分析客户旅程流程中各种产品状态点。其子智能体创建代表不同旅程状态的Mermaid状态图、特定于细分的Are状态场景图,并生成相关的测试场景和步骤。
如下一图中所示的工作流程,以基本的提取、转换和加载(ETL)过程结束,该过程将来自智能体的数据整合和去重,并将最终输出保存为文本文件。
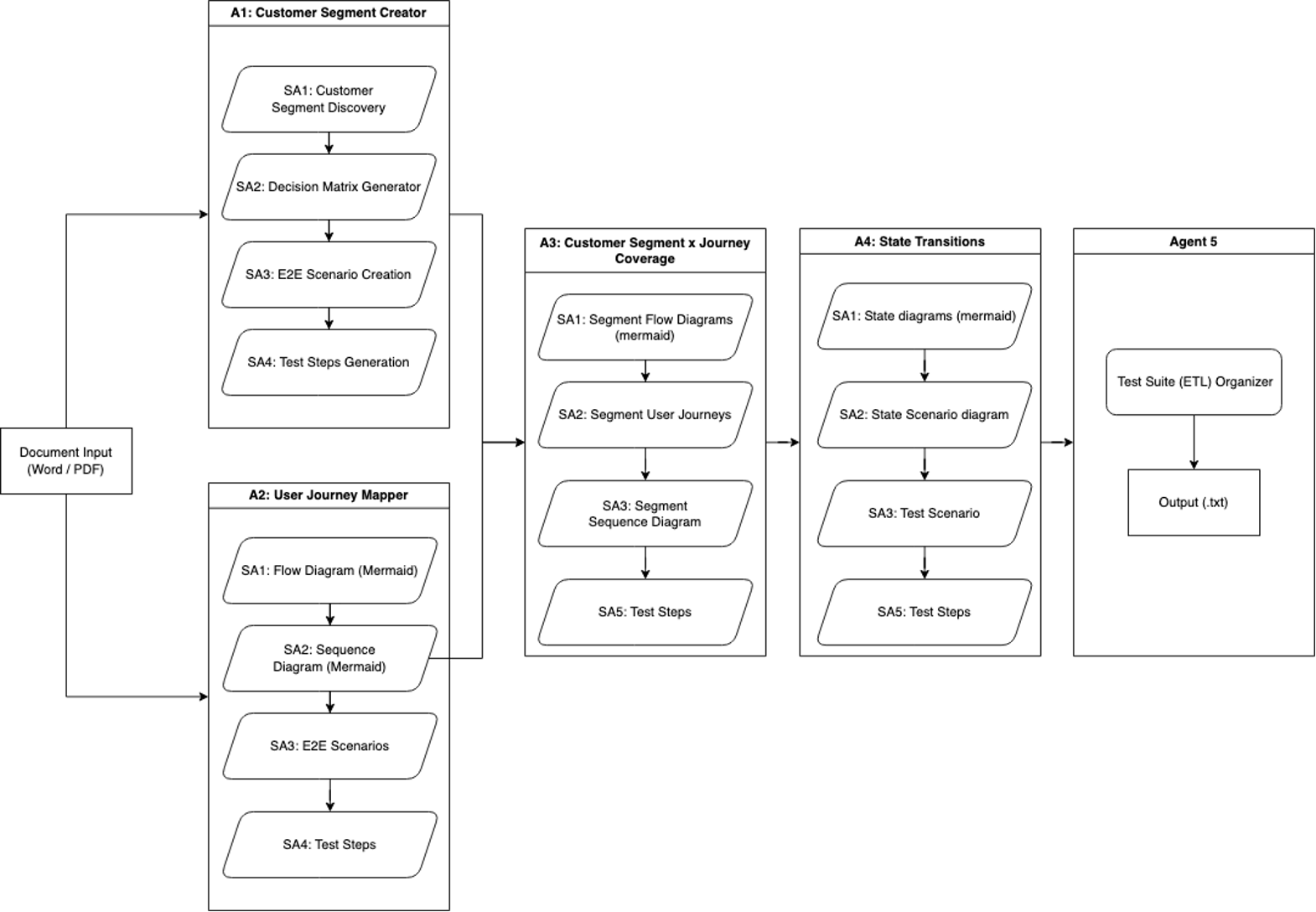
这种系统化的方法有助于全面覆盖客户旅程、细分和各种图表类型,通过智能体和子智能体的迭代处理,实现了彻底的测试覆盖范围生成。
解决限制并增强功能
在利用Strands Agents开发更强大、更高效的工具的过程中,我们确定了初始方法中的五个关键限制:
- 上下文和幻觉挑战——我们的第一个工作流程面临隔离的智能体操作带来的限制,其中单个智能体独立收集数据并创建可视化表示。这种隔离导致上下文理解有限,从而导致输出的准确性降低和幻觉增加。
- 数据生成效率低下——智能体可用的有限上下文引起了另一个关键问题:生成了过多的不相关数据。在没有适当上下文感知的情况下,智能体产生了不那么集中的输出,导致干扰了有价值的见解的噪声。
- 受限的解析能力——初始系统的 D数据解析范围太窄,仅限于客户细分、旅程映射和基本要求。这种限制阻止了智能体访问全面分析所需的全部信息范围。
- 单一来源输入限制——工作流程只能处理Word文档,造成了重大的瓶颈。现代开发环境需要来自多个源的数据,而这一限制阻碍了整体数据收集。
- 僵化的架构问题——重要的是,第一个工作流程采用了紧密耦合的系统和僵化的编排。这种架构使得修改、扩展或重用组件变得困难,限制了系统适应不断变化的需求的能力。
在我们的第二个迭代中,我们需要实施战略性解决方案来解决这些问题。
工作流程迭代2:全面分析工作流程
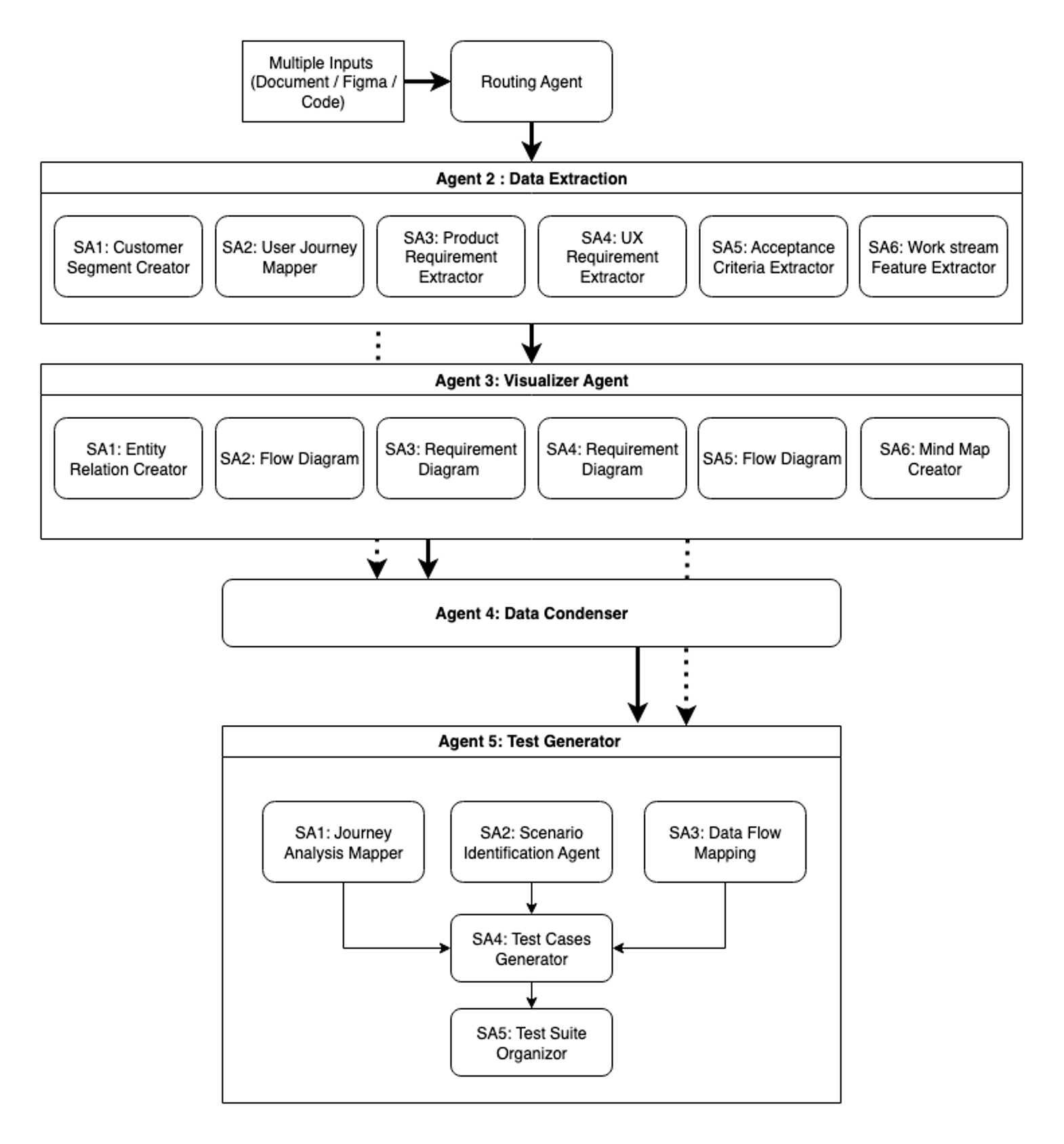
我们的第二个迭代是对智能体工作流程架构的彻底重新构想。我们没有修补单个问题,而是从头开始重建,将模块化、上下文感知和可扩展性作为核心原则:
智能体1是智能网关。文件类型决策智能体充当系统的入口点和路由器。它处理文档文件、Figma设计和代码存储库,将数据分类并定向到适当的下游智能体。这种智能路由对于在整个工作流程中保持效率和准确性至关重要。
智能体2用于专业数据提取。数据提取智能体采用六个专业的子智能体,每个子智能体都专注于特定的提取域。这种并行处理方法有助于实现全面覆盖,同时保持实际速度。每个子智能体都以领域特定的知识运行,提取通用方法可能会忽略的细微信息。
智能体3是可视化智能体(Visualizer agent),它将提取的数据转换为六种不同的Mermaid图表类型,每种类型都服务于特定的分析目的。实体关系图映射数据关系和结构,流程图可视化过程和工作流。需求图阐明了产品规范,用户体验需求可视化描绘了用户体验流程。流程图详细说明了系统操作,思维导图揭示了特征关系和层次结构。这些可视化为相同信息提供了多种视角,有助于人类审阅者和下游智能体理解复杂数据集中模式和连接。
智能体4是数据冷凝智能体(Data Condenser agent),它通过智能上下文蒸馏执行关键的综合,确保每个下游智能体接收到执行其特定任务所需的确切信息。这个由其浓缩信息生成器驱动的智能体,合并了来自数据提取智能体和可视化智能体的输出,同时执行复杂的分析。
该智能体从完整文本上下文中提取关键元素——验收标准、业务规则、客户细分和边缘案例——创建结构化摘要,同时保留基本细节并减少令牌使用。它将每个文本文件与其对应的Mermaid图表进行比较,捕获仅在视觉表示中可能遗漏的信息。这种仔细的处理确保了在智能体交接过程中信息完整性得以保持,确保重要数据在流经系统时不会丢失。结果是一组丰富了Mermaid图表的浓缩附录,其中包含全面的上下文。这种综合确保了在信息传递到测试生成阶段时,它是完整、结构化和优化以便处理的。
智能体5是测试生成智能体(Test Generator agent),它汇集了收集、可视化和浓缩的信息,以生成全面的测试套件。该智能体与六个Mermaid图表以及来自智能体4的浓缩信息协同工作,采用由五个子智能体组成的管道。旅程分析映射器、场景识别智能体和数据流映射子智能体根据从智能体4流入的输入数据生成全面的测试用例。在三个关键视角下生成测试用例后,测试用例生成器对其进行评估,并根据内部指南重新格式化以确保一致性。最后,测试套件组织器执行去重和优化,交付一个平衡了全面性和效率的最终测试套件。
该系统现在处理的远不止工作流程1中的基本需求和旅程映射——它处理产品需求、用户体验规范、验收标准和工作流提取,同时接受来自Figma设计、代码存储库和多种文档类型的输入。最重要的是,转向模块化架构从根本上改变了系统的运行和演变方式。与我们僵化的第一个工作流程不同,这种设计允许重用早期智能体的输出,集成新的测试类型智能体,并根据用户需求智能地选择测试用例生成器,使系统能够持续适应。
下图显示了SAARAM的第二个迭代,其中包含五个主要智能体和多个子智能体,并进行了上下文工程和压缩。
额外的Strands Agents功能
Strands Agents为我们的多智能体系统提供了基础,提供了一种模型驱动的方法,简化了复杂的智能体开发。由于SDK可以通过先进的推理能力将模型与工具连接起来,我们仅用几行代码就构建了复杂的工件。除了其核心功能外,两个关键功能对我们的生产部署至关重要:使用结构化输出来减少幻觉和工作流程编排。
使用结构化输出来减少幻觉
Strands Agents的结构化输出功能使用Pydantic模型将传统上不可预测的LLM输出转换为可靠的、类型安全的响应。这种方法解决了生成式AI中的一个根本挑战:尽管LLM在生成类人文本方面表现出色,但它们在为生产系统所需的*一致格式化输出*方面可能会遇到困难。通过Pydantic强制执行模式,我们确保响应符合预定义的结构,从而与现有的测试管理系统无缝集成。
下面的示例实现演示了结构化输出的实际工作方式:
from pydantic import BaseModel, Field
from typing import List
import json # 定义结构化输出模式
class TestCaseItem(BaseModel):
name: str = Field(description="Test case name")
priority: str = Field(description="Priority: P0, P1, or P2")
category: str = Field(description="Test category")
class TestOutput(BaseModel):
test_cases: List[TestCaseItem] = Field(description="Generated test cases")
# 带有验证的智能体工具
@tool
def save_results(self, results: str) -> str:
try:
# 解析和验证Claude的JSON输出
data = json.loads(results)
validated = TestOutput(**data)
# 仅在验证通过时保存
with open("results.json", 'w') as f:
json.dump(validated.dict(), f, indent=)
return "Validated results saved"
except ValidationError as e:
return f"Invalid output format: {e}"Pydantic会自动针对定义的模式验证LLM响应,以促进类型正确性和所需字段的存在。当响应不符合预期结构时,验证错误会提供有关需要更正内容的清晰反馈,有助于防止格式错误的数据在系统中传播。在我们的环境中,这种方法在不受提示变化或模型更新影响的情况下,提供了跨智能体的*一致、可预测的输出*,最大限度地减少了一整类数据格式错误。结果是,我们的开发团队在拥有全面IDE支持的情况下工作效率更高。
工作流程编排优势
Strands Agents的工作流程架构为我们的多智能体系统提供了所需的复杂协调功能。该框架支持使用明确的任务定义进行结构化协调、对独立任务进行自动并行执行以及对依赖操作进行顺序处理。这意味着我们可以构建手动实现起来很困难的复杂智能体间通信模式。
下面的示例片段显示了如何在Strands Agents SDK中创建工作流程:
from strands import Agent
from strands_tools import workflow
# 创建具有工作流程能力的智能体
main_agent_3 = create_main_agent_3()
# 创建带有结构化输出任务的工作流程
workflow_result = main_agent_3.tool.workflow(
action="create",
workflow_id="comprehensive_e2e_test_generation",
tasks=[
# 阶段1:并行执行(无依赖)
{
"task_id": "journey_analysis",
"description": "Generate journey scenario names with brief descriptions using structured output",
"dependencies": [],
"model_provider": "bedrock",
"model_settings": {
"model_id": "us.anthropic.claude-sonnet-4-20250514-v1:0",
"params": {"temperature": }
},
"system_prompt": load_prompt("journey_analysis"),
"structured_output_model": "JourneyAnalysisOutput",
"priority": ,
"timeout":
},
{
"task_id": "scenario_identification",
"description": "Generate scenario variations using structured output for different path types",
"dependencies": [],
"model_provider": "bedrock",
"model_settings": {
"model_id": "us.anthropic.claude-sonnet-4-20250514-v1:0",
"params": {"temperature": }
},
"system_prompt": load_prompt("scenario_identification"),
"structured_output_model": "ScenarioIdentificationOutput",
"priority": ,
"timeout":
},
{
"task_id": "data_flow_mapping",
"description": "Generate data flow scenarios using structured output covering information journey",
"dependencies": [],
"model_provider": "bedrock",
"model_settings": {
"model_id": "us.anthropic.claude-sonnet-4-20250514-v1:0",
"params": {"temperature": }
},
"system_prompt": load_prompt("data_flow_mapping"),
"structured_output_model": "DataFlowMappingOutput",
"priority": ,
"timeout":
},
# 阶段2:等待前3个任务完成
{
"task_id": "test_case_development",
"description": "Generate test cases from all scenario outputs using structured output",
"dependencies": ["journey_analysis", "scenario_identification", "data_flow_mapping"],
"model_provider": "bedrock",
"model_settings": {
"model_id": "us.anthropic.claude-sonnet-4-20250514-v1:0",
"params": {"temperature": }
},
"system_prompt": load_prompt("test_case_development"),
"structured_output_model": "TestCaseDevelopmentOutput",
"priority": ,
"timeout":
},
# 阶段3:等待测试用例开发完成
{
"task_id": "test_suite_organization",
"description": "Organize all test cases into final comprehensive test suite using structured output",
"dependencies": ["test_case_development"],
"model_provider": "bedrock",
"model_settings": {
"model_id": "us.anthropic.claude-sonnet-4-20250514-v1:0",
"params": {"temperature": }
},
"system_prompt": load_prompt("test_suite_organization"),
"structured_output_model": "TestSuiteOrganizationOutput",
"priority": ,
"timeout":
}
]
该工作流程系统为我们的用例提供了三个关键功能。首先,并行处理优化允许旅程分析、场景识别和覆盖范围分析同时运行,独立智能体处理不同方面而不会相互阻塞。系统根据可用性自动分配资源,最大限度地提高了吞吐量。
其次,智能依赖管理确保测试开发等待场景识别完成,并且组织任务依赖于测试用例的生成。上下文在依赖阶段之间得到有效保留和传递,确保了整个工作流程中的信息完整性。
最后,内置的可靠性功能为我们的系统提供了所需的弹性。自动重试机制可以优雅地处理瞬时故障,状态持久性支持长时间运行的工作流程的暂停和恢复功能,而全面的审计日志支持调试和性能优化工作。
下表显示了工作流程输入的示例以及可能的输出。
| 输入:业务需求文档 | 输出:生成的测试用例 |
功能要求:
|
TC006:信用卡支付成功
场景:客户使用有效信用卡完成购买 步骤: 1. 将商品添加到购物车并进行结账。预期结果:显示结账表单。 2. 输入运输信息。预期结果:运输详情已保存。 3. 选择信用卡支付方式。预期结果:显示卡表单。 4. 输入有效卡详细信息。预期结果:卡已验证。 5. 提交付款。预期结果:付款已处理,订单已确认。TC008:付款失败处理 场景:由于资金不足或卡被拒绝而导致付款失败 步骤: 1. 输入资金不足的卡。预期结果:显示付款被拒绝消息。 2. 系统提供重试选项。预期结果:重新显示付款表单。 3. 尝试替代支付方式。预期结果:替代支付成功。 TC009:支付网关超时
TC010:退款处理
|
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区