



📢 转载信息
原文作者:Jason Salcido
在我们的系列文章第 1 部分中,我们介绍了一种针对 Amazon Bedrock 的主动式成本管理解决方案,其核心是一个旨在强制执行实时 Token 使用限制的稳健成本监控机制。我们探讨了核心架构、Token 跟踪策略以及最初的预算执行技术,这些技术有助于组织控制其生成式 AI 支出。
在此基础上,本文将探讨针对生成式 AI 部署的高级成本监控策略。我们将引入分层自定义标签方法以实现精确的成本分配,并开发全面的报告机制。
解决方案概览
第 1 部分中介绍的成本监控解决方案被开发为一个集中机制,用于主动限制生成式 AI 的使用,以遵守规定的预算。下图说明了该解决方案的核心组件,并增加了通过 AWS 账单和成本管理进行的成本监控。
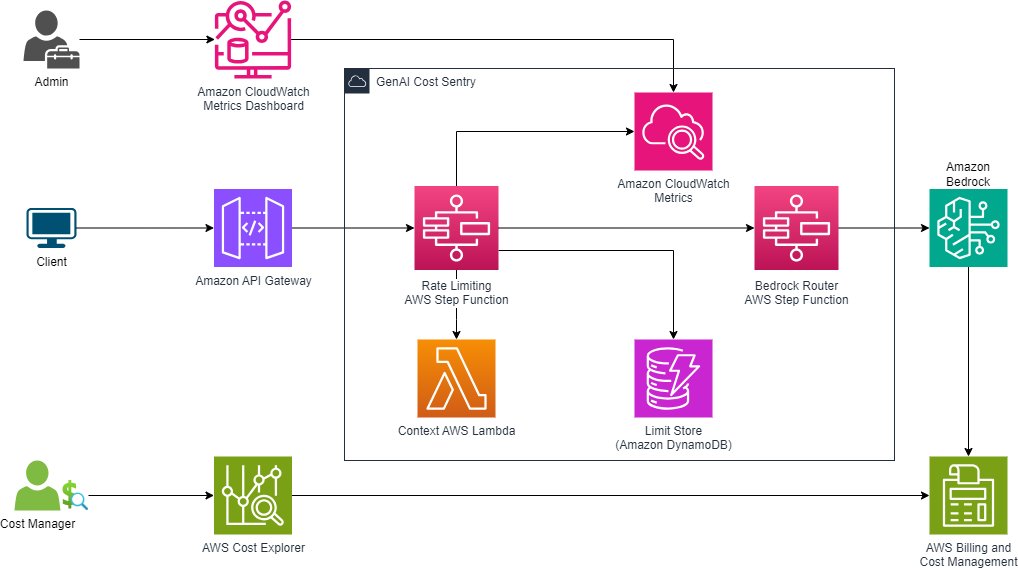
调用级别标签,增强可追溯性
调用级别标签通过将丰富的元数据附加到每个 API 请求来扩展我们解决方案的能力,在 Amazon CloudWatch 日志中创建了全面的审计跟踪。当需要调查与预算相关的决策、分析速率限制影响或了解不同应用程序和团队的使用模式时,这变得特别有价值。为此,主 AWS Step Functions 工作流进行了更新,如下图所示。
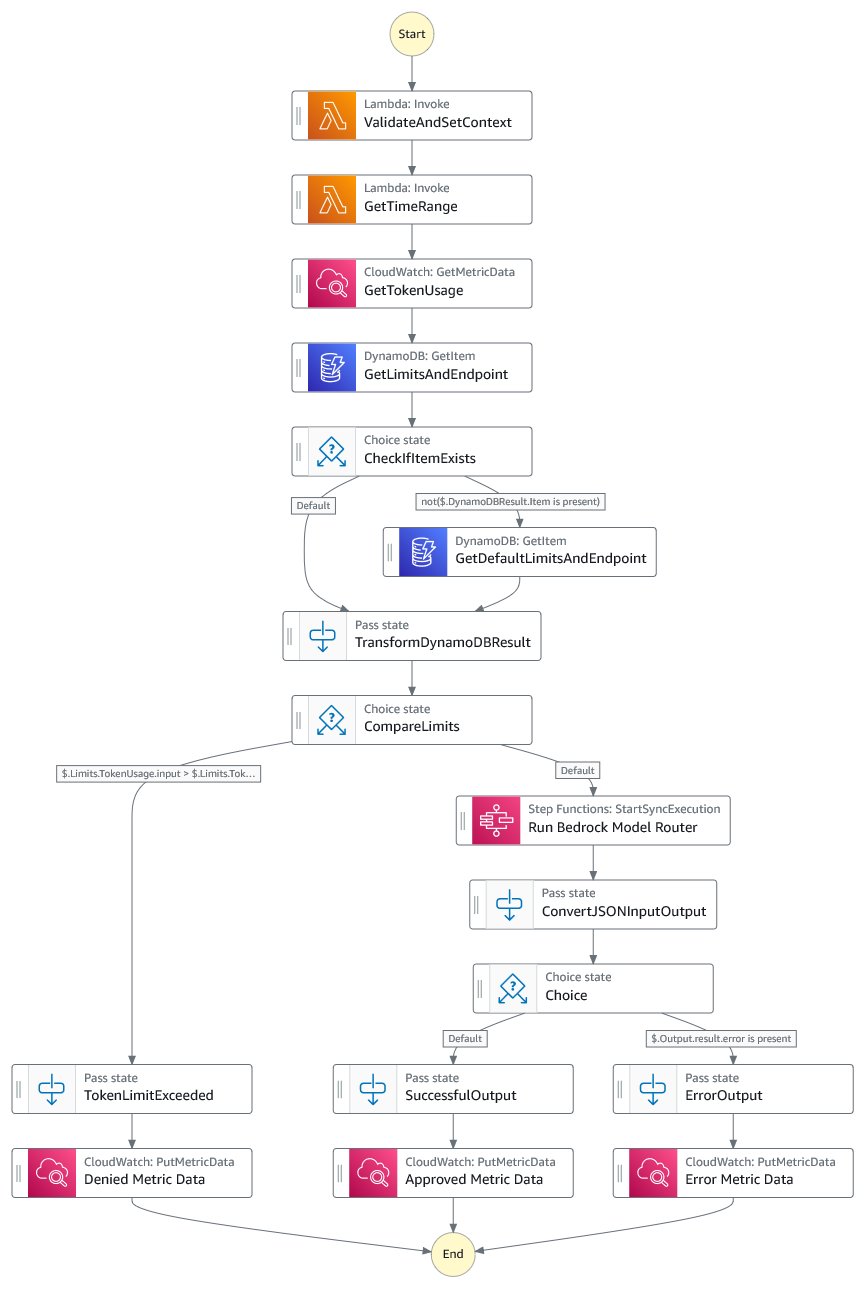
增强的 API 输入
我们还演变了 API 输入以支持自定义标签。新的输入结构引入了用于模型特定配置和自定义标签的可选参数:
{
"model": "string", // 例如,"claude-3" 或 "anthropic.claude-3-sonnet-20240229-v1:0"
"prompt": {
"messages": [
{
"role": "string", // "system", "user", 或 "assistant"
"content": "string"
}
],
"parameters": {
"max_tokens": number, // 可选,模型特定默认值
"temperature": number, // 可选,模型特定默认值
"top_p": number, // 可选,模型特定默认值
"top_k": number // 可选,模型特定默认值
}
},
"tags": {
"applicationId": "string", // 必需
"costCenter": "string", // 可选
"environment": "string" // 可选 - dev/staging/prod
}
}输入结构包含三个关键组件:
- model – 将简单名称(例如
claude-3)映射到完整的 Amazon Bedrock 模型 ID(例如anthropic.claude-3-sonnet-20240229-v1:0) - input – 提供一个用于提示的
messages数组,支持单轮和多轮对话 - tags – 支持应用程序级别的跟踪,其中
applicationId是必需字段,costCenter和environment是可选字段
在这个例子中,我们为 sales、services 和 support 使用不同的成本中心,以模拟使用业务属性来跟踪 Amazon Bedrock 中推理的使用情况和支出。例如:
{
"model": "claude-3-5-haiku",
"prompt": {
"messages": [
{
"role": "user",
"content": "Explain the benefits of using S3 using only 100 words."
},
{
"role": "assistant",
"content": "You are a helpful AWS expert."
}
],
"parameters": {
"max_tokens": 2000,
"temperature": 0.7,
"top_p": 0.9,
"top_k": 50
}
},
"tags": {
"applicationId": "aws-documentation-helper",
"costCenter": "support",
"environment": "production"
}
}验证和标记
在工作流中增加了一个新的验证步骤用于标记。此步骤使用 AWS Lambda 函数来添加验证检查,并将请求的模型映射到 Amazon Bedrock 中的特定模型 ID。它使用补充了 tags 对象,包含下游分析所需的标签。
以下代码是一个简单的映射示例,用于从指定的模型获取适当的模型 ID:
MODEL_ID_MAPPING = {
"nova-lite": "amazon.nova-lite-v1:0",
"nova-micro": "amazon.nova-micro-v1:0",
"claude-2": "anthropic.claude-v2:0",
"claude-3-haiku": "anthropic.claude-3-haiku-20240307-v1:0",
"claude-3-5-sonnet-v2": "us.anthropic.claude-3-5-sonnet-20241022-v2:0",
"claude-3-5-haiku": "us.anthropic.claude-3-5-haiku-20241022-v1:0"
}日志记录和分析
通过使用带有自定义生成标签和维度的 CloudWatch 指标,您可以跨多个维度(如模型类型、成本中心、应用程序和环境)跟踪详细指标。自定义标签和维度显示了团队如何使用 AI 服务。为了查看此分析,我们实现了生成自定义标签、存储指标数据和分析指标数据的步骤:
- 我们包含一组唯一的标签来捕获上下文信息。这可以包括用户提供的标签以及动态生成的标签,例如
requestId和timestamp:"tags": { "requestId": "ded98994-eb76-48d9-9dbc-f269541b5e49", "timestamp": "2025-01-31T14:05:26.854682", "applicationId": "aws-documentation-helper", "costCenter": "support", "environment": "production" } - 随着每个工作流的执行,将评估每个模型的限制,以确保请求在预算准则范围内。工作流将根据三种可能的结果结束:
- 速率限制批准且调用成功
- 速率限制批准但调用失败
- 速率限制被拒绝
自定义指标数据存储在 CloudWatch 的
GenAIRateLimiting命名空间中。此命名空间包括以下关键指标:- TotalRequests – 计算每一次调用尝试,无论结果如何
- RateLimitApproved – 跟踪通过速率限制检查的请求
- RateLimitDenied – 跟踪被速率限制阻止的请求
- InvocationFailed – 计算模型调用期间失败的请求数
- InputTokens – 衡量成功请求的输入 Token 消耗
- OutputTokens – 衡量成功请求的输出 Token 消耗
每个指标都包含
Model、ModelId、CostCenter、Application和Environment等维度,用于数据分析。 - 我们使用 CloudWatch 指标查询功能和数学表达式来分析工作流收集的数据。数据可以以各种可视化格式显示,以获得按提供的维度(如模型或成本中心)划分的请求的粒度视图。以下屏幕截图显示了一个仪表板示例,其中显示了一个模型已达到其限制的调用指标。
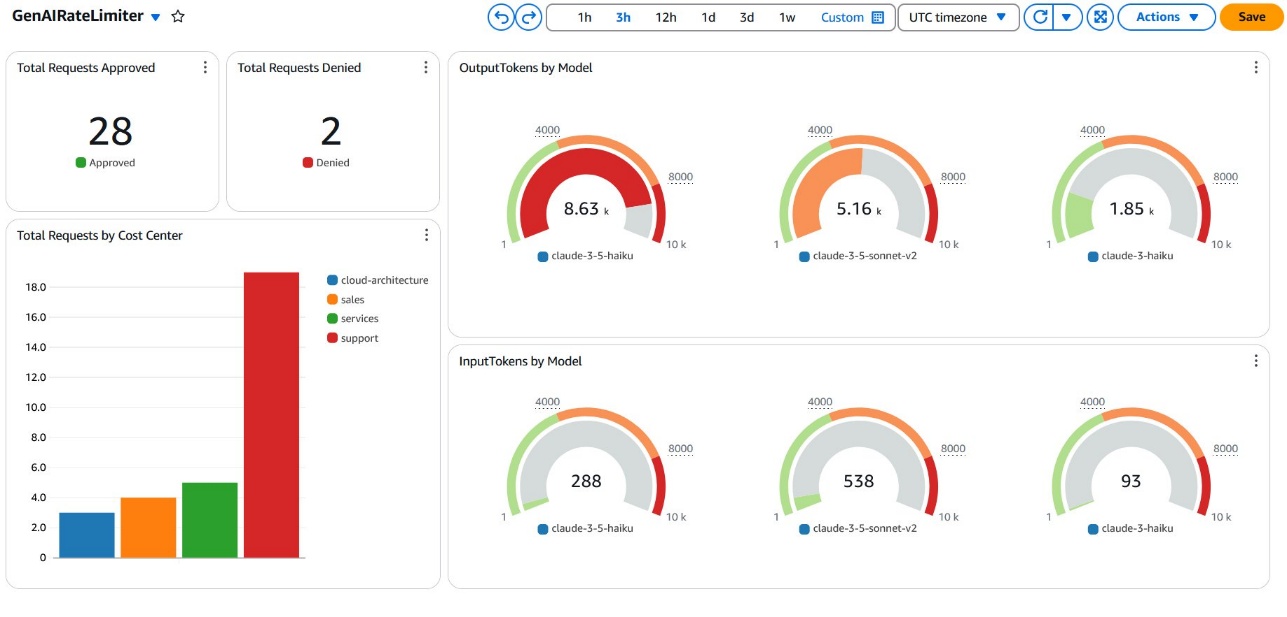
其他 Amazon Bedrock 分析
除了自定义指标仪表板外,CloudWatch 还提供用于监控 Amazon Bedrock 性能和使用情况的自动仪表板。Bedrock 仪表板提供了对关键性能指标和操作洞察力的可见性,如下面的屏幕截图所示。
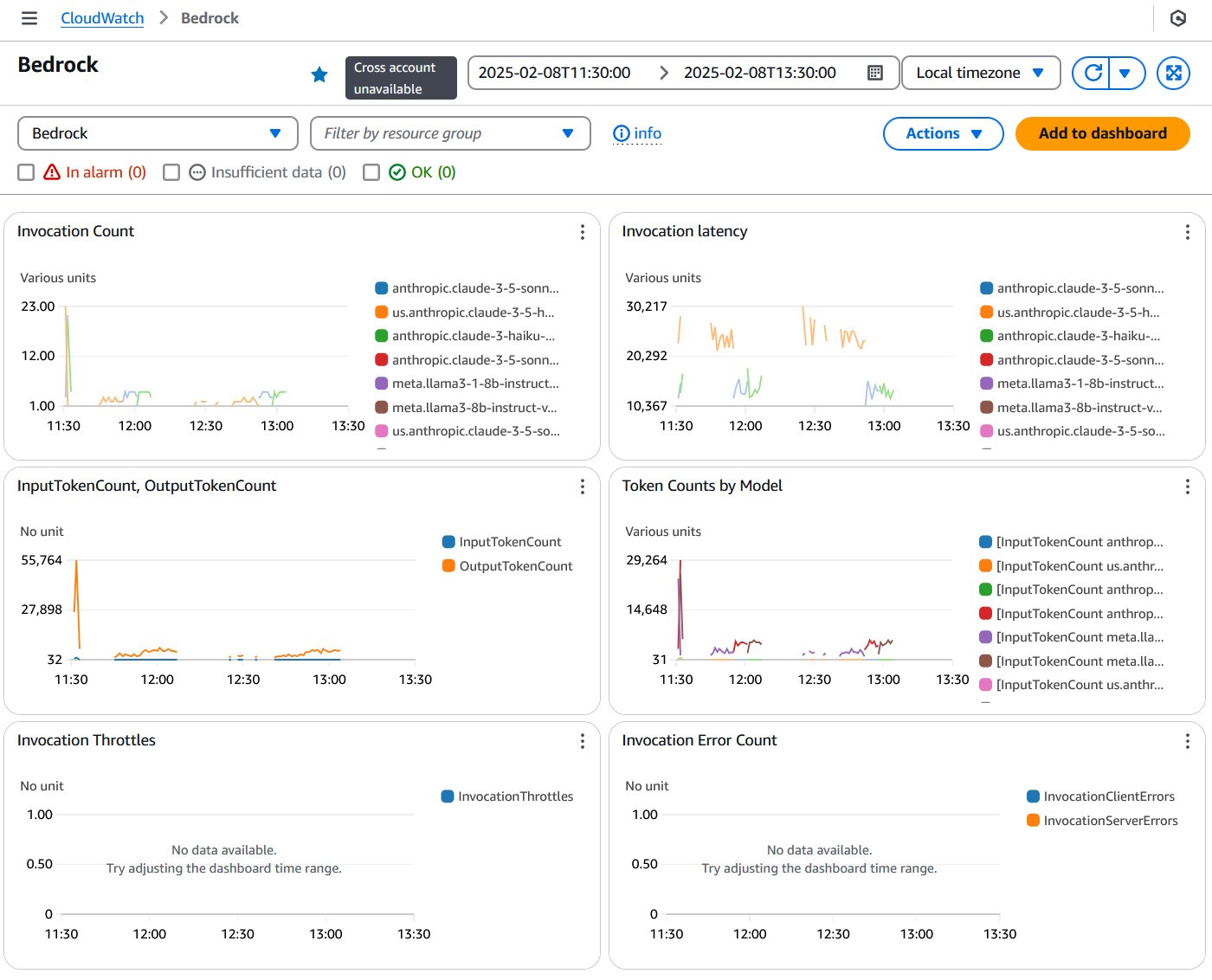
成本标记和报告
Amazon Bedrock 推出了应用推理配置文件,这是一项新功能,组织可以利用它来应用自定义成本分配标签,以跟踪和管理其按需基础模型 (FM) 的使用情况。此功能解决了先前无法对按需 FM 进行标记的限制,使得跨不同业务部门和应用程序跟踪成本变得困难。现在,您可以为基础 FM 创建自定义推理配置文件,并应用成本分配标签,如部门、团队和应用程序标识符。这些标签与 AWS 成本管理工具集成,包括 AWS Cost Explorer、AWS Budgets 和 AWS Cost Anomaly Detection,从而实现详细的成本分析和预算控制。
应用推理配置文件
首先,您必须为要跟踪的每种使用类型创建应用推理配置文件。在这种情况下,解决方案为 costCenter、environment 和 applicationId 定义了自定义标签。推理配置文件还将基于现有的 Amazon Bedrock 模型配置文件,因此您必须将所需的标签和模型组合到配置文件中。在撰写本文时,您必须使用 AWS 命令行界面 (AWS CLI) 或 AWS API 来创建配置文件。请看以下示例代码:
aws bedrock create-inference-profile \n --inference-profile-name "aws-docs-sales-prod" \n --model-source '{"copyFrom": "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-haiku-20240307-v1:0"}' \n --tags '[\n {"key": "applicationId", "value": "aws-documentation-helper"},\n {"key": "costCenter", "value": "sales"},\n {"key": "environment", "value": "production"}\n ]'此命令使用 Anthropic 的 Claude Haiku 3.5 模型为销售成本中心和生产环境创建配置文件。此命令的输出是一个 Amazon 资源名称 (ARN),您将用作模型 ID。在此解决方案中,修改了 ValidateAndSetContext Lambda 函数,允许通过成本中心(例如 sales)指定模型。要查看已创建的配置文件,请使用以下命令:
aws bedrock list-inference-profiles --type-equals APPLICATION
在创建了配置文件并更新了验证以将成本中心映射到配置文件 ARN 之后,工作流将开始运行推理请求并对齐配置文件。例如,当用户提交请求时,他们将指定模型为 sales、services 或 support,以与定义的三个成本中心对齐。以下代码与上一个示例中的映射类似:
MODEL_ID_MAPPING = {
"sales": "arn:aws:bedrock:<region>:<account>:application-inference-profile/<unique id1>",
"services": "arn:aws:bedrock:<region>:<account>:application-inference-profile/<unique id2>",
"support": "arn:aws:bedrock:<region>:<account>:application-inference-profile/<unique id3>"
}要在使用应用推理配置文件时正确查询 CloudWatch 指标中的模型使用情况,您必须指定该配置文件的唯一 ID(ARN 的最后一部分)。CloudWatch 将根据唯一 ID 存储诸如 Token 使用量之类的指标。为了同时支持配置文件和直接的模型使用,修改了 Lambda 函数,添加了一个新的 modelMetric 标签,使其成为查询 Token 使用量的适当术语。请看以下代码:
"tags": {
"requestId": "ded98994-eb76-48d9-9dbc-f269541b5e49",
"timestamp": "2025-01-31T14:05:26.854682",
"applicationId": "aws-documentation-helper",
"costCenter": "support",
"environment": "production",\n "modelMetric": "<unique id> | <model id>"
}
Cost Explorer
Cost Explorer 是一款强大的成本管理工具,它提供对包括 Amazon Bedrock 在内的 AWS 服务云支出的全面可视化和分析。它提供直观的仪表板来跟踪历史成本、预测未来支出,并深入了解您的云消耗情况。使用 Cost Explorer,您可以按服务、标签和自定义维度细分支出,以进行详细的财务分析。该工具每天更新。
当您将 Amazon Bedrock 与应用推理配置文件结合使用时,您的 AI 服务使用情况将自动标记并直接流入账单和成本管理。这些标签支持跨成本中心、应用程序和环境等不同维度的详细成本跟踪。这意味着您可以生成报告,按特定的业务部门、项目或组织层级细分 Amazon Bedrock AI 支出,从而为您的生成式 AI 支出提供清晰的可见性。
成本分配标签
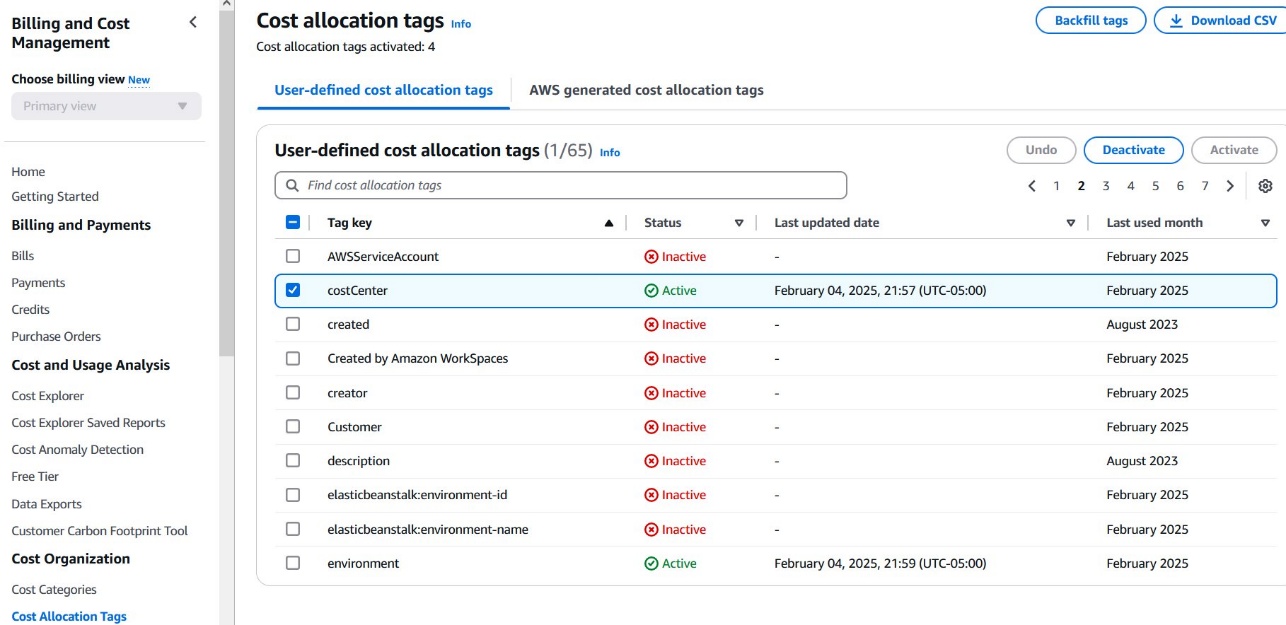
成本分配标签是帮助您在组织内对 AWS 资源成本进行分类和跟踪的键值对。在 Amazon Bedrock 的背景下,这些标签可以包括应用程序名称、成本中心、环境或项目 ID 等属性。要激活成本分配标签,您必须首先在 Billing and Cost Management 控制台中启用它。激活后,这些标签将出现在您的 AWS 成本和使用情况报告 (CUR) 中,帮助您精细地细分 Amazon Bedrock 支出。
要激活成本分配标签,请完成以下步骤:
- 在 Billing and Cost Management 控制台中,在导航窗格中,选择 Cost Allocation Tags。
- 找到您的标签(在此示例中,它命名为
costCenter)并选择 Activate。 - 确认激活。
激活后,costCenter 标签将出现在您的 CUR 中,并用于 Cost Explorer。标签可能需要 24 小时才能在您的账单报告中完全生效。
Cost Explorer 报告
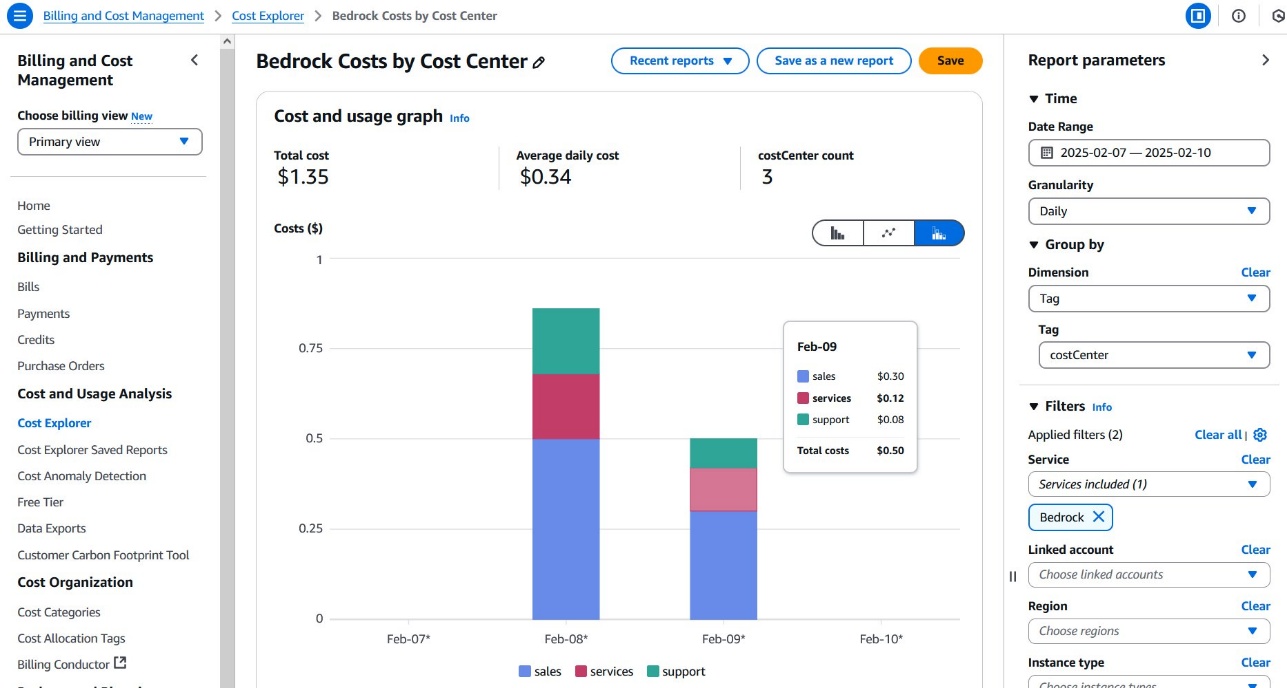
要在 Cost Explorer 中根据您的标签创建 Amazon Bedrock 使用情况报告,请完成以下步骤:
- 在 Billing and Cost Management 控制台中,在导航窗格中选择 Cost Explorer。
- 设置所需的日期范围(相对时间范围或自定义期间)。
- 选择 Daily 或 Monthly 粒度。
- 在 Group by 下拉菜单中,选择 Tag。
- 选择
costCenter作为标签键。 - 查看按每个唯一的成本中心值细分的显示的 Amazon Bedrock 成本。
- 可以选择在 Filters 部分应用过滤器来细化值:
- 选择 Tag 过滤器。
- 选择 costCenter 标签。
- 选择要分析的特定成本中心值。
生成的报告将提供 Amazon Bedrock AI 服务支出的详细视图,帮助您精确地比较不同组织单位或项目之间的支出。
总结
AWS 成本和使用情况报告(包括预算)充当滞后指标,因为它们在事后才显示您已经在 Amazon Bedrock 上花费了多少。通过将 Step Functions 的实时警报与全面的成本报告相结合,您可以获得 Amazon Bedrock 使用情况的 360 度视图。此报告可以在您超支之前提醒您,并帮助您了解您的实际消耗情况。这种方法使您能够主动管理 AI 资源,使您的创新预算保持正轨,并确保您的项目顺利运行。
请尝试将此成本管理方法用于您自己的用例,并在评论中分享您的反馈。
关于作者
 Jason Salcido 是一位初创企业高级解决方案架构师,拥有近 30 年的经验,为从初创公司到企业级的组织构建创新解决方案。他的专业知识涵盖云架构、无服务器计算、机器学习、生成式 AI 和分布式系统。Jason 将深厚的技术知识与前瞻性方法相结合,设计能够创造价值的可扩展解决方案,同时将复杂概念转化为可操作的战略。
Jason Salcido 是一位初创企业高级解决方案架构师,拥有近 30 年的经验,为从初创公司到企业级的组织构建创新解决方案。他的专业知识涵盖云架构、无服务器计算、机器学习、生成式 AI 和分布式系统。Jason 将深厚的技术知识与前瞻性方法相结合,设计能够创造价值的可扩展解决方案,同时将复杂概念转化为可操作的战略。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区