



📢 转载信息
原文作者:David Meredith, Josh Zacharias, Monica Raj, Dwaragha Sivalingam, Naman Sharma, Nkechinyere Nneka Agu, Tryambak Gangopadhyay, and Yingwei Yu
本文由 Associa 的 David Meredith 和 Josh Zacharias 联合撰写。
Associa 是北美最大的社区管理公司,负责管理约 750 万户房主,在 300 多个分支机构拥有 15,000 名员工。该公司管理着约 4800 万份文件,数据量达 26 TB,但其现有的文档管理系统缺乏高效的自动化分类功能,导致跨多种文档类型进行文档的组织和检索变得困难。每天,员工都会花费大量时间手动对收到的文件进行分类和整理,这是一个耗时、易出错的过程,造成运营效率瓶颈,并可能导致运营延误和生产力下降。
Associa 与 AWS 生成式 AI 创新中心合作,构建了一个生成式 AI 驱动的文档分类系统,以实现文档管理的运营效率这一长期愿景。该解决方案能够以高准确率自动对传入文档进行分类,高效处理文档,并在保持卓越运营的同时实现显著的成本节约。该文档分类系统是使用 生成式 AI 智能文档处理(GenAI IDP)加速器开发的,旨在与现有工作流程无缝集成。它通过减少花在手动分类任务上的时间,彻底改变了员工与文档管理系统的交互方式。
本文将讨论 Associa 如何使用 Amazon Bedrock 自动对文档进行分类,并帮助提高员工的生产力。
解决方案概述
GenAI IDP 加速器 是一个构建在 AWS 上的云端文档处理解决方案,可以自动从各种文档类型中提取和组织信息。该系统利用 OCR 技术和生成式 AI 将非结构化文档转换为结构化、可用的数据,同时无缝扩展以处理大量的文档。
该加速器采用灵活的模块化设计,使用 AWS CloudFormation 模板来处理不同类型的文档处理,同时共享用于作业管理、进度跟踪和系统监控的核心基础设施。该加速器支持三种处理模式。对于此解决方案,我们使用模式 2,它结合了 OCR(Amazon Textract)和分类(Amazon Bedrock)。下图说明了这种架构。
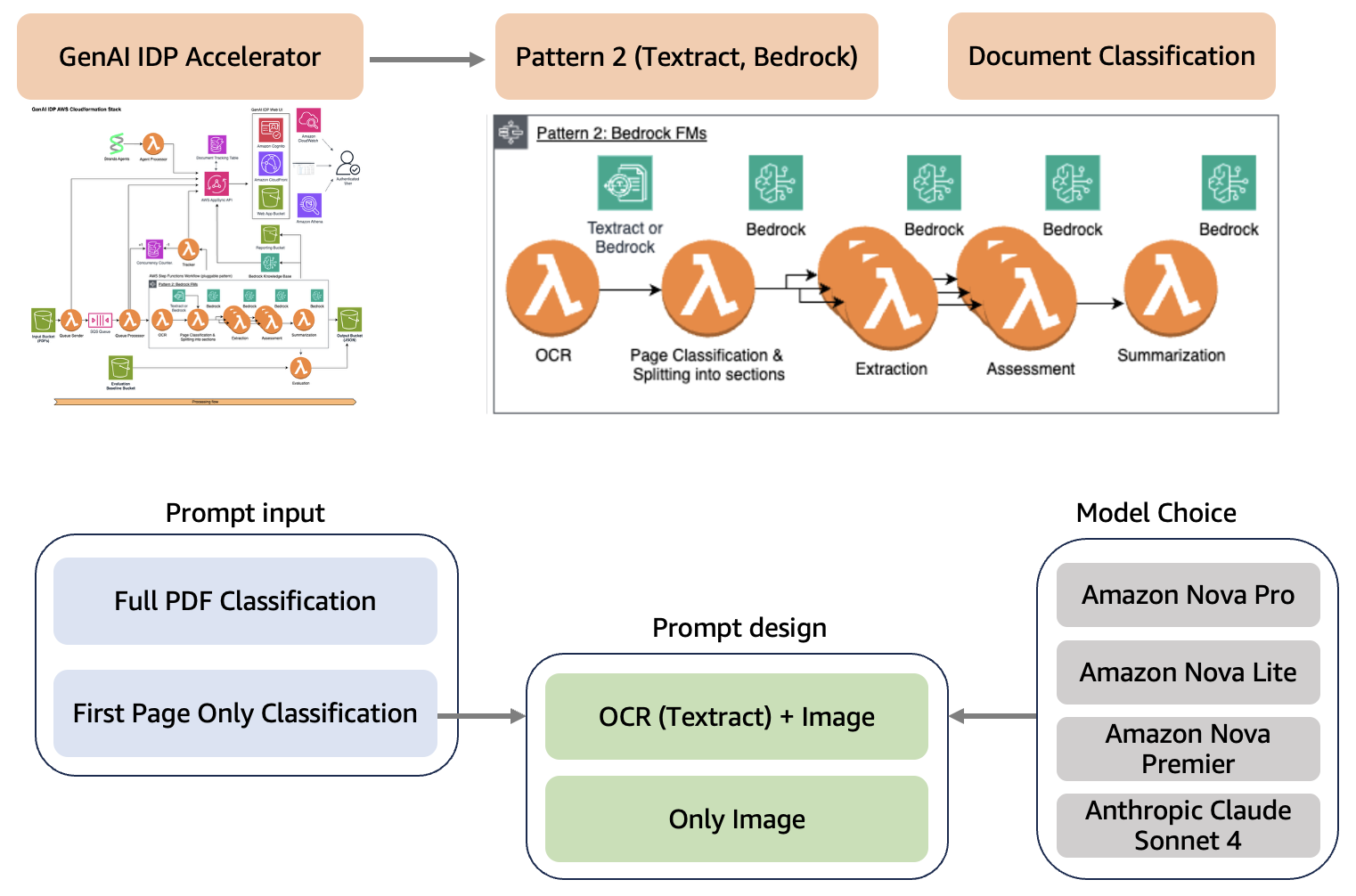
我们通过评估三个关键方面来优化文档分类工作流程:
- 提示输入(Prompt input) – 完整的 PDF 文档(所有页面)与仅第一页
- 提示设计(Prompt design) – 结合 OCR 数据(使用 Amazon Textract
analyze_document_layout)的多模态提示与仅文档图像 - 模型选择(Model choice) – Amazon Bedrock 上的 Amazon Nova Lite、Amazon Nova Pro、Amazon Nova Premier 和 Anthropic 的 Claude Sonnet 4
这种全面的评估框架帮助我们确定了在满足 Associa 特定文档类型和运营要求的同时,能提供最高准确率并最大限度降低处理推理成本的配置。评估数据集由 465 份 PDF 文档组成,涵盖八种不同的文档类型。数据集中包含一些被标记为草稿文件或电子邮件通信的样本。由于分类标准不足,这些样本被归类为 Unknown(未知)文档类型。文档类型在各个类别之间的分布不均衡,范围从 Policies and Resolutions(政策和决议)的 6 个样本到 Minutes(会议纪要)的 155 个样本。
评估:提示输入
我们开始的初步评估是使用完整的 PDF 文档,其中 PDF 的所有页面都作为分类提示的输入。下表显示了使用 Amazon Nova Pro 结合 OCR 和图像进行完整 PDF 分类的准确性。我们观察到,考虑到不同的文档类型,平均分类准确率为 91%,平均每份文档的成本为 1.10 美分。
| 文档类型 | 样本数量 | 正确分类的样本数量 | 分类准确率 | 分类成本(美分) |
| Bylaws (章程) | 46 | 42 | 91% | 1.52c |
| CCR Declarations (契约声明) | 22 | 19 | 86% | 1.55c |
| Certificate of Insurance (保险凭证) | 74 | 74 | 100% | 1.49c |
| Contracts (合同) | 71 | 66 | 93% | 1.48c |
| Minutes (会议纪要) | 155 | 147 | 95% | 1.47c |
| Plat Map (分区图) | 21 | 20 | 95% | 1.45c |
| Policies and Resolutions (政策和决议) | 6 | 5 | 83% | 0.35c |
| Rules and Regulations (规章制度) | 50 | 44 | 88% | 0.36c |
| Unknown (未知) | 20 | 8 | 40% | 0.24c |
| Overall (总体) | 465 | 425 | 91% | 1.10c |
使用完整 PDF 进行文档分类,对 Certificate of Insurance 的准确率达到了 100%,对 Minutes 达到了 95%。系统正确分类了 465 份文档中的 425 份。然而,对于 Unknown 文档类型,其准确率仅为 40%,正确分类了 20 份中的 8 份。
接下来,我们尝试仅使用 PDF 文档的第一页进行分类,如下表所示。这种方法将总体准确率从 91% 提高到 95%,正确分类了 465 份文档中的 443 份,同时将每份文档的分类成本从 1.10 美分降低到 0.55 美分。
| 文档类型 | 样本数量 | 正确分类的样本数量 | 分类准确率 | 分类成本(美分) |
| Bylaws (章程) | 46 | 44 | 96% | 0.55c |
| CCR Declarations (契约声明) | 22 | 21 | 95% | 0.55c |
| Certificate of Insurance (保险凭证) | 74 | 74 | 100% | 0.59c |
| Contracts (合同) | 71 | 64 | 90% | 0.56c |
| Minutes (会议纪要) | 155 | 153 | 99% | 0.55c |
| Plat Map (分区图) | 21 | 17 | 81% | 0.56c |
| Policies and Resolutions (政策和决议) | 6 | 4 | 67% | 0.57c |
| Rules and Regulations (规章制度) | 50 | 49 | 98% | 0.56c |
| Unknown (未知) | 20 | 17 | 85% | 0.55c |
| Overall (总体) | 465 | 443 | 95% | 0.55c |
除了提高准确率和降低成本外,仅使用首页的方法还将 Unknown 文档的分类准确率从 40% 显著提高到 85%。首页通常包含最独特的文件特征,而草稿或电子邮件主题的后续页面可能会引入使分类器混淆的噪声。结合更快的处理速度和更低的基础设施成本,我们为后续评估选择了仅使用首页的方法。
评估:提示设计
接下来,我们试验了提示设计,以评估 OCR 数据是否对文档分类有必要,或者仅使用文档图像是否足够。我们通过从提示中移除 OCR 文本提取数据,仅在多模态提示中使用图像来进行评估。此方法消除了 Amazon Textract 的成本,完全依赖于模型对视觉特征的理解。下表显示了使用 Amazon Nova Pro 仅使用图像进行单页分类的准确性。
| 文档类型 | 样本数量 | 正确分类的样本数量 | 分类准确率 | 分类成本(美分) |
| Bylaws (章程) | 46 | 45 | 98% | 0.19c |
| CCR Declarations (契约声明) | 22 | 20 | 91% | 0.19c |
| Certificate of Insurance (保险凭证) | 74 | 74 | 100% | 0.18c |
| Contracts (合同) | 71 | 63 | 89% | 0.18c |
| Minutes (会议纪要) | 155 | 151 | 97% | 0.18c |
| Plat Map (分区图) | 21 | 18 | 86% | 0.19c |
| Policies and Resolutions (政策和决议) | 6 | 4 | 67% | 0.18c |
| Rules and Regulations (规章制度) | 50 | 48 | 96% | 0.18c |
| Unknown (未知) | 20 | 10 | 50% | 0.18c |
| Overall (总体) | 465 | 433 | 93% | 0.18c |
仅图像分类方法显示出与完整 PDF 分类方法相似的问题。尽管此方法实现了 93% 的总体准确率,但在 Unknown 文档类型上,它只能正确分类 20 份中的 10 份,准确率仅为 50%。下表总结了我们对仅图像方法的评估。
| 总体分类准确率 (包含未知文档) | 分类准确率 (文档类型: 未知) | 分类成本(美分) | |
| 仅首页分类 (OCR + 图像) | 95% | 85% | 0.55c |
| 仅首页分类 (仅图像) | 93% | 50% | 0.18c |
仅图像方法消除了 OCR 成本,但将总体准确率从 95% 降至 93%,并将 Unknown 文档准确率从 85% 降至 50%。准确的 Unknown 文档分类对于 Associa 后续的人工审查和运营效率至关重要。我们选择了结合 OCR 和图像的方法来保持此功能。
评估:模型选择
使用最佳配置——即仅使用首页分类,并结合 OCR 和图像——我们评估了不同的模型,以确定准确性和成本的最佳平衡点,如下表所示。我们重点关注总体分类性能、未知文档的分类以及每份文档的分类成本。
| 总体分类准确率 (包含未知文档) | 分类准确率 (文档类型: 未知) | 分类成本(美分) | |
| Amazon Nova Pro | 95% | 85% | 0.55c |
| Amazon Nova Lite | 95% | 50% | 0.41c |
| Amazon Nova Premier | 96% | 90% | 1.12c |
| Anthropic Claude Sonnet 4 | 95% | 95% | 1.21c |
在不同模型中,总体分类准确率在 95%–96% 之间波动,未知文档类型的性能有所不同。Certificate of Insurance、Plat Map 和 Minutes 在所有模型上的准确率都达到了 98%–100%。Anthropic 的 Claude Sonnet 4 实现了最高的未知文档准确率(95%),其次是 Amazon Nova Premier(90%)和 Amazon Nova Pro(85%)。然而,Anthropic 的 Claude Sonnet 4 将分类成本从每份文档 0.55 美分增加到了 1.21 美分。Amazon Nova Premier 以每份文档 1.12 美分的价格实现了最佳的总体分类准确率。考虑到准确性和成本之间的权衡,我们选择 Amazon Nova Pro 作为最优模型选择。
结论
Associa 利用 Amazon Bedrock 上的 Amazon Nova Pro 构建了一个生成式 AI 驱动的文档分类系统,该系统实现了 95% 的准确率,平均成本为每份文档 0.55 美分。GenAI IDP 加速器有助于其分支机构可靠地扩展到处理大量文档的性能。“AWS 生成式 AI 创新中心开发的解决方案改善了我们员工管理和组织文档的方式,我们预计文档处理中的人工工作量将大大减少,”Associa 的数字与技术服务总裁兼首席信息官 Andrew Brock 表示。“文档分类系统在保持我们服务住宅社区的高准确性标准的同时,提供了显著的成本节约和运营改进。”
请参阅 GenAI IDP 加速器 GitHub 仓库以获取详细示例,并选择 Watch 以随时了解新版本。如果您想与 AWS GenAI 创新中心合作,请与我们联系或发表评论。
致谢
我们要感谢 Mike Henry、Bob Strahan、Marcelo Silva 和 Mofijul Islam 在整个过程中所做的重大贡献、战略决策和指导。
关于作者
David Meredith 是 Associa 的员工软件开发总监。他负责监督 Associa 团队为 15,000 名员工创建日常使用软件的工作。他在住宅物业管理行业拥有近 20 年的软件经验,居住在加拿大不列颠哥伦比亚省温哥华地区。
是 Associa 的员工软件开发总监。他负责监督 Associa 团队为 15,000 名员工创建日常使用软件的工作。他在住宅物业管理行业拥有近 20 年的软件经验,居住在加拿大不列颠哥伦比亚省温哥华地区。
 Josh Zacharias 是 Associa 的软件开发人员,是内部软件团队的首席工程师。他的工作包括为公司各个部门架构全栈解决方案,并帮助其他开发人员更高效地成为软件开发专家。
Josh Zacharias 是 Associa 的软件开发人员,是内部软件团队的首席工程师。他的工作包括为公司各个部门架构全栈解决方案,并帮助其他开发人员更高效地成为软件开发专家。
 Monica Raj 是 AWS 生成式 AI 创新中心的深度学习架构师,与各个行业的组织合作开发 AI 解决方案。她的工作重点是构建和部署智能体式 AI 解决方案、自然语言处理、联络中心自动化和智能文档处理。Monica 在为企业客户构建可扩展的 AI 解决方案方面拥有丰富的经验。
Monica Raj 是 AWS 生成式 AI 创新中心的深度学习架构师,与各个行业的组织合作开发 AI 解决方案。她的工作重点是构建和部署智能体式 AI 解决方案、自然语言处理、联络中心自动化和智能文档处理。Monica 在为企业客户构建可扩展的 AI 解决方案方面拥有丰富的经验。
 Tryambak Gangopadhyay 是 AWS 生成式 AI 创新中心的高级应用科学家,与来自不同行业的组织合作。他的工作涉及研究和开发生成式 AI 解决方案,以解决关键业务挑战并加速 AI 采用。在加入 AWS 之前,Tryambak 在爱荷华州立大学完成了博士学业。
Tryambak Gangopadhyay 是 AWS 生成式 AI 创新中心的高级应用科学家,与来自不同行业的组织合作。他的工作涉及研究和开发生成式 AI 解决方案,以解决关键业务挑战并加速 AI 采用。在加入 AWS 之前,Tryambak 在爱荷华州立大学完成了博士学业。
 Nkechinyere Agu 是 AWS 生成式 AI 创新中心的应用程序科学家,与各个行业的组织合作开发 AI 解决方案。她的工作重点是开发多模态 AI 解决方案、智能体式 AI 解决方案和自然语言处理。在加入 AWS 之前,Nkechinyere 在纽约州特洛伊的伦斯勒理工学院完成了博士学业。
Nkechinyere Agu 是 AWS 生成式 AI 创新中心的应用程序科学家,与各个行业的组织合作开发 AI 解决方案。她的工作重点是开发多模态 AI 解决方案、智能体式 AI 解决方案和自然语言处理。在加入 AWS 之前,Nkechinyere 在纽约州特洛伊的伦斯勒理工学院完成了博士学业。
 Naman Sharma 是 AWS 生成式 AI 创新中心的生成式 AI 战略师,他与组织合作,推动生成式 AI 的采用,以大规模解决业务问题。他的工作重点是与 GenAIIC 战略和应用科学团队一起,引导客户完成前沿解决方案的范围界定、部署和扩展。
Naman Sharma 是 AWS 生成式 AI 创新中心的生成式 AI 战略师,他与组织合作,推动生成式 AI 的采用,以大规模解决业务问题。他的工作重点是与 GenAIIC 战略和应用科学团队一起,引导客户完成前沿解决方案的范围界定、部署和扩展。
 Yingwei Yu 是生成式 AI 创新中心的应用科学经理,驻扎在德克萨斯州休斯顿。Yingwei 在应用机器学习和生成式 AI 方面拥有丰富的经验,领导着跨各个行业创新解决方案的开发。
Yingwei Yu 是生成式 AI 创新中心的应用科学经理,驻扎在德克萨斯州休斯顿。Yingwei 在应用机器学习和生成式 AI 方面拥有丰富的经验,领导着跨各个行业创新解决方案的开发。
 Dwaragha Sivalingam 是 AWS 专注于生成式 AI 的高级解决方案架构师,担任客户在云转型和 AI 战略方面的可信顾问。他拥有八项 AWS 认证,包括 ML 专长,曾帮助过保险、电信、公用事业、工程、建筑和房地产等多个行业的客户。作为机器学习爱好者,他通过公路旅行、电影和无人机摄影平衡着自己的专业生活和家庭时间。
Dwaragha Sivalingam 是 AWS 专注于生成式 AI 的高级解决方案架构师,担任客户在云转型和 AI 战略方面的可信顾问。他拥有八项 AWS 认证,包括 ML 专长,曾帮助过保险、电信、公用事业、工程、建筑和房地产等多个行业的客户。作为机器学习爱好者,他通过公路旅行、电影和无人机摄影平衡着自己的专业生活和家庭时间。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区