



📢 转载信息
原文作者:Sri Potluri and Luis Felipe Yepez Barrios
客户服务团队面临一个持续的挑战。现有的基于聊天的助手会因僵硬的响应使用户感到沮丧,而直接的 大型语言模型 (LLM) 的实现则缺乏可靠的业务运营所需的结构。当客户需要订单查询、取消或状态更新方面的帮助时,传统方法要么无法理解自然语言,要么无法在多步骤对话中保持上下文。
本文将探讨如何使用 Amazon Bedrock、LangGraph 以及 Amazon SageMaker AI 上的托管 MLflow来构建一个智能的对话式 AI 智能体。
解决方案概述
本文介绍的对话式 AI 智能体展示了一种实用的实现,用于处理客户订单查询,这是一个对现有客户服务自动化解决方案来说常见但通常具有挑战性的用例。我们实现了一个智能化的订单管理智能体,它通过帮助客户查找订单信息并通过自然对话执行取消等操作来解决这些挑战。该系统使用一个基于图的对话流程,包含三个关键阶段:
- 入口意图 (Entry intent) – 识别客户的需求并收集必要信息
- 订单确认 (Order confirmation) – 展示找到的订单详情并验证客户意图
- 解决 (Resolution) – 执行客户请求并提供结束语
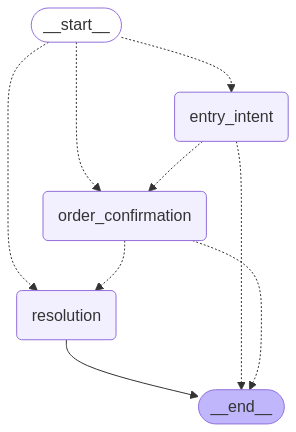
此智能体流程如图所示。
问题陈述
大多数客户服务自动化解决方案分为两大类,每种都有明显的局限性。
基于规则的聊天助手通常在自然语言理解方面存在不足,导致用户体验令人沮丧。它们通常遵循僵硬的决策树,无法处理人类对话的细微差别。当用户偏离预期输入时,这些系统就会失败,迫使用户适应助手,而不是反过来。例如,基于规则的聊天助手可能会识别“我想取消我的订单”,但如果用户说“我需要退回我刚买的东西”,它可能会因为不匹配预定义模式而失败。
与此同时,现代 LLM 在理解自然语言方面表现出色,但直接使用它们也会带来自己的挑战。LLM 本质上不维护状态或遵循多步骤流程,使得对话管理变得困难。将 LLM 连接到后端系统需要仔细的编排,并且监控它们的性能会带来独特的可观测性挑战。最关键的是,当 LLM 缺乏领域知识时,它们可能会生成看似合理但错误的信息。
为了通过一个真实世界的例子来理解这些限制,请考虑一个看似简单的客户服务场景:用户需要查询订单状态或请求取消。这次交互需要理解用户的意图,提取相关信息(如订单号和账户详情),根据后端系统验证信息,在执行前确认操作,并在整个对话中保持上下文。如果没有结构化的方法,基于规则的系统和原始 LLM 都无法处理这些需要记忆、规划和与外部系统集成的多步骤流程。
这些根本性的限制解释了为什么现有方法在实际应用中持续不足。基于规则的系统无法有效地将自然对话与结构化的业务流程联系起来,而 LLM 无法在多次交互中保持状态。这两种方法都无法与后端系统无缝集成以进行数据检索和更新,并且都对性能和用户体验的可见性有限。最关键的是,当前解决方案无法在自然对话所需的灵活性与可靠客户服务所需的业务规则执行之间取得平衡。
本解决方案通过AI 智能体解决了这些挑战——这些系统将 LLM 的自然语言能力与结构化工作流、工具集成和全面的可观测性相结合。
解决方案架构
本解决方案使用基于 WebSocket 的架构,利用 Amazon S3 上托管的 React 前端和通过 Amazon CloudFront 交付,来实现一个无服务器的对话式 AI 系统,以实现实时的客户交互。当客户发送消息时,系统通过 Amazon API Gateway 与 AWS Lambda 函数建立持久的 WebSocket 连接,这些 Lambda 函数负责编排对话流程。下图说明了解决方案架构。
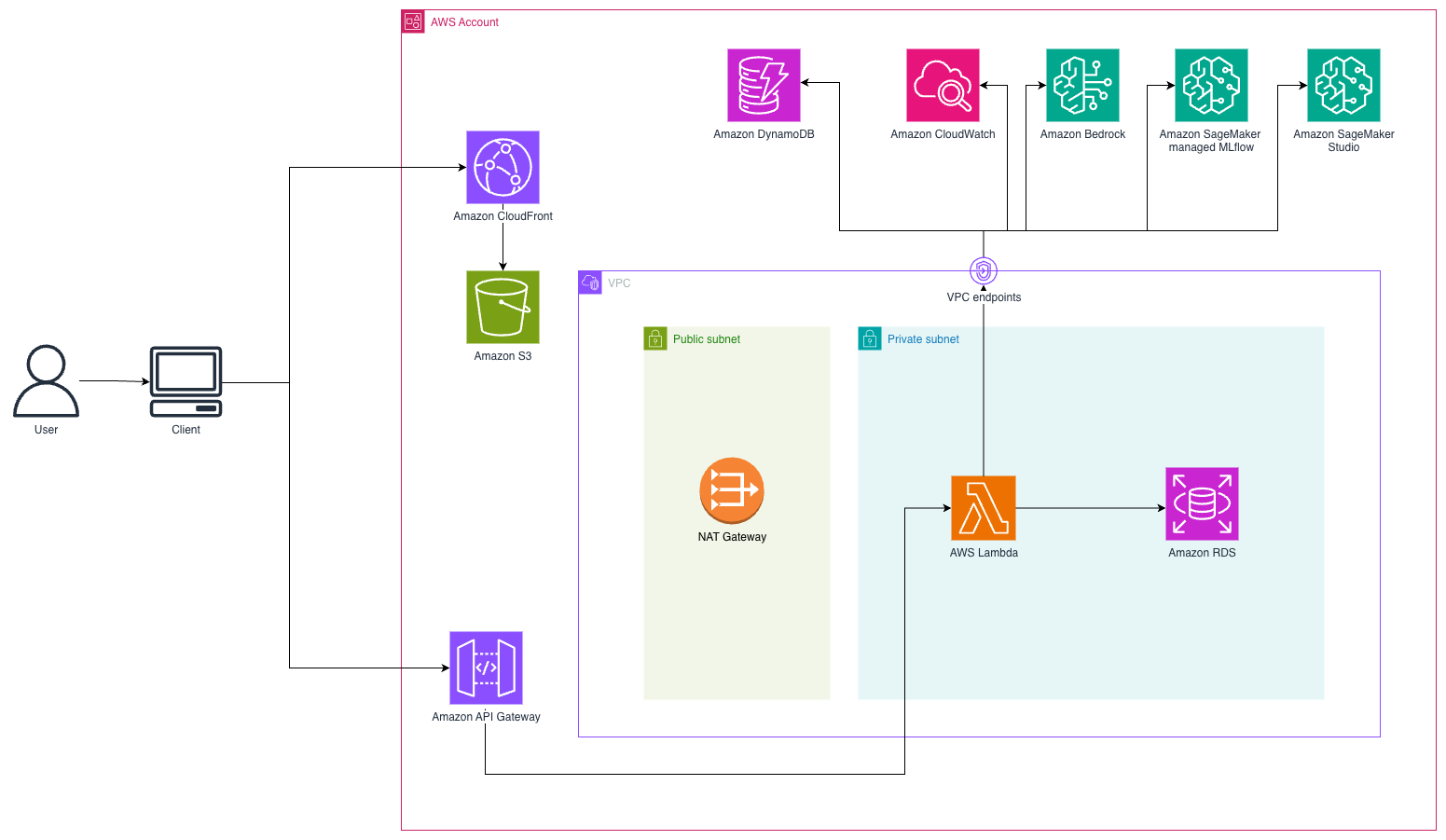
智能体架构
本解决方案采用AI 智能体,即 LLM 动态指导其自身流程和工具使用,同时保持对其完成任务方式的控制的系统。与简单的 LLM 应用不同,这些智能体在多次交互中维护状态和上下文,可以使用外部工具来收集信息或执行操作,根据先前结果推理下一步操作,并以一定的自主性运行。智能体工作流遵循结构化的模式:初始化、理解用户意图、规划所需操作、在需要时执行工具调用、生成响应以及更新对话状态以供将来交互使用。
要构建有效的对话式智能体,我们需要四项核心能力:
- 理解和响应用户的智能
- 跨对话维护上下文的记忆
- 在外部系统中执行操作的能力
- 管理复杂多步工作流的编排能力
我们的实现在特定 Amazon Web Services (AWS) 服务和框架中解决了这些要求。
Amazon Bedrock 作为智能层,通过一致的 API 提供了对最先进的 基础模型 (FM) 的访问。Amazon Bedrock 用于处理意图识别(理解用户尝试做什么)、实体提取(识别订单号和客户详情等关键信息)、自然语言生成(创建上下文适当的响应)、决策制定(确定对话流程中的下一个最佳操作)以及工具使用的协调(与外部系统交互)。此智能层使我们的智能体能够理解自然语言,同时保持可靠客户服务所需的结构化决策能力。
状态管理(智能体记忆)通过 Amazon DynamoDB 处理,它为对话上下文提供持久存储,即使在中断或系统重启时也是如此。状态包括:将 Amazon DynamoDB 作为会话 ID(唯一的对话标识符)、完整的对话历史(用于上下文维护)、针对模型上下文窗口优化的格式化文本记录、提取的信息(如订单号和客户详情)以及指示确认状态和信息检索成功的流程标志。这种持久状态使我们的智能体能够在多次交互中保持上下文,解决了原始 LLM 实现的关键限制之一。
状态管理片段代码(有关完整实现,您可以参考 backed/app.py 中的代码):
# Save conversation state to DynamoDB ttl_value = int(time.time()) + (3600 * 4) # 4 hrs item = { 'conversationId': session_id, 'state': json.dumps(state_dict), 'chat_status': state_dict['session_end'], 'update_ts_pst': str(datetime.now(pst)), 'ttl': ttl_value, 'timestamp': int(time.time()) } ddb_table.put_item(Item=item) 该状态包含一个生存时间 (TTL) 值,该值在一段时间不活动后自动使对话过期,有助于管理存储成本。
函数调用(也称为工具使用)使我们的智能体能够以结构化的方式与外部系统交互。模型不会生成描述操作的自由文本,而是生成对预定义函数和特定参数的结构化调用。您可以将其视为向 LLM 提供一套带有说明手册的工具,LLM 决定何时使用这些工具以及提供什么信息。我们的实现在定义特定的工具,这些工具连接到 Amazon Relational Database (Amazon RDS) for PostgreSQL 数据库:get_user 用于客户查找,get_order_by_id 用于订单详情,get_customer_orders 用于列出客户订单,cancel_order 用于订单取消,update_order 用于订单修改。
以下代码片段允许正确处理助手和用户之间的消息序列,以及正确的工具名称和所需的输入或参数。(有关实施细节,请参阅 backend/utils/utils.py):
def use_tool(messages): tool_use = messages[-1]["content"][-1].get("toolUse") if tool_use: tool_name = tool_use["name"] tool_input = tool_use["input"] # Process the tool call tool_result = _process_tool_call(tool_name, tool_input) # Format response for the model message = { "role": "user", "content": [ { "toolResult": { "toolUseId": tool_use["toolUseId"], "content": [ {"text": json.dumps(tool_result)} ], "status": "success", } } ], } return message 这些工具使用 JSON 模式定义,为模型遵循提供了清晰的契约:
tool_config = { "toolChoice": {"auto": {}}, "tools": [ { "toolSpec": { "name": "get_order_by_id", "description": "Retrieves the details of a specific order based on the order ID.", "inputSchema": { "json": { "type": "object", "properties": { "order_id": { "type": "string", "description": "The unique identifier for the order.", } }, "required": ["order_id"], }, }, }, } ] }上一个片段代码只显示了一个工具定义的示例,但在实现中配置了三种不同的工具。有关完整的详细信息,请参阅 backend/tools_config/entry_intent_tool.py 或 backend/tools_config/agent_tool.py
此功能将模型与现实世界的数据和系统相结合,通过提供事实信息减少幻觉,将模型的能力扩展到它单独所能做的之外,并对系统交互强制执行一致的模式。函数调用的结构化特性意味着模型只能通过定义明确的接口请求特定数据,而不是做出假设。
LangGraph 为使用有向图方法构建有状态、多步骤应用程序提供了编排框架。它提供了对话状态的显式跟踪、每个节点处理特定对话阶段的关注点分离、基于上下文的动态决策的条件路由、处理循环和重复模式的循环检测,以及一个易于使用新节点扩展或修改现有流程的灵活架构。您可以将 LangGraph 视为为您创建对话的流程图,其中每个框代表对话的一个特定部分,箭头显示如何在它们之间移动。
对话流程是使用 LangGraph 实现的有向图。有关参考,请参阅解决方案架构部分中的智能体流程图。
以下代码片段显示了状态图,它是一个结构上下文,用于在不同的用户交互中收集信息,为智能体提供适当的上下文:
class State(TypedDict): # Messages tracked in the conversation history messages: list # Transcription attributes tracks updates posted by the agent transcript: list # Session Id is the unique identifier attribute of the conversation session_id: str # Order number order_number: str # tracks in the conversation is still active session_end: bool # tracks the current node in the conversation current_turn: int # tracks the next node in the conversation next_node: str # track status of the confirmation order_confirmed: bool # track status of the orders eligible order_info_found: bool 此状态对象维护有关对话的相关信息,允许系统对路由和响应做出知情的决策。
我们的对话流程使用三个主要节点:入口意图节点处理初始用户请求并提取关键信息,订单确认节点验证详情并确认用户意图,解决节点执行请求的操作并提供结束语。此方法提供了显式的状态管理、条件路由、关注点分离、跨不同对话流程的可重用性,以及对话路径的清晰可视化:
# Define nodes and edges graph_builder = StateGraph(State) # Add nodes graph_builder.add_node("entry_intent", entry_intent.node) graph_builder.add_node("order_confirmation", order_confirmation.node) graph_builder.add_node("resolution", resolution.node) # Add conditional edges with routing logic graph_builder.add_conditional_edges( START, initial_router, { 'entry_intent': 'entry_intent', 'order_confirmation': 'order_confirmation', 'resolution': 'resolution' } ) 节点之间的边使用条件逻辑来确定运行时执行中的流程,如以下代码片段所示,该逻辑基于 StateGraph 的内容:
graph_builder.add_conditional_edges( 'entry_intent', lambda x: x["next_node"], { 'order_confirmation': 'order_confirmation', '__end__': END } ) 对话图中的每个节点都实现为一个 Python 函数,用于处理当前状态并返回更新后的状态。入口意图节点处理初始用户请求,提取订单号等关键信息,并通过解释客户查询来确定后续步骤。它使用工具来搜索相关的订单信息,提取订单号或客户标识符等关键详细信息,并确定是否有足够的信息可以继续进行。订单确认节点通过向客户展示找到的订单详情、验证正在讨论的订单是否正确以及确认客户关于该订单的意图来验证详情并确认用户意图。解决节点通过执行必要的动作(如提供状态或取消订单)、确认请求操作成功完成、回答有关订单的后续问题以及提供对话的自然结束,来执行请求的操作并提供结束语:
@mlflow.trace(span_type=SpanType.AGENT) def node(state: Dict[str, Any]) -> Dict[str, Any]: """ Entry intent node for processing chat messages and managing order information. This node handles: 1. Initial message processing with the chat model 2. Tool execution for order information retrieval 3. State management and updates 4. Dynamic routing based on order information """ 有关完整的实施细节,请参阅:backend/nodes。
这些节点使用一致的模式:从状态中提取相关信息,使用 LLM 处理用户消息,执行必要的工具,使用新信息更新状态,并确定流程中的下一个节点。
可观测性变得至关重要,因为 LLM 应用带来了独特的挑战,包括:输出不确定性(相同输入可能产生不同结果)、复杂链(多个模型和工具按顺序交互)、性能监控(延迟影响用户体验)以及需要专业指标的质量评估。Amazon SageMaker AI 上的托管 MLflow 通过专门的跟踪功能解决了这些挑战,这些功能可以监控模型交互、延迟、Token 使用情况和对话路径。
每个对话节点都使用 MLflow 跟踪进行装饰:
@mlflow.trace(span_type=SpanType.AGENT) def node(state: Dict[str, Any]) -> Dict[str, Any]: # Node implementation 这个简单的装饰器会自动捕获关于每个节点执行的丰富信息。它会记录模型调用,显示调用了哪些模型以及使用了哪些参数。它会跟踪响应指标,如延迟、Token 使用量和完成原因。它会映射对话路径,显示用户如何遍历对话图。它还会记录工具使用情况,指明调用了哪些工具及其结果,以及识别何时以及为何发生故障的错误模式。
捕获的数据在 MLflow UI 中可视化,为生产性能监控、优化机会、调试和业务影响衡量提供了见解。
MLflow 跟踪捕获了整个智能体工作流的执行情况,包括交互中涉及的节点、每个节点的输入和输出,以及延迟、工具调用和对话序列等附加元数据。
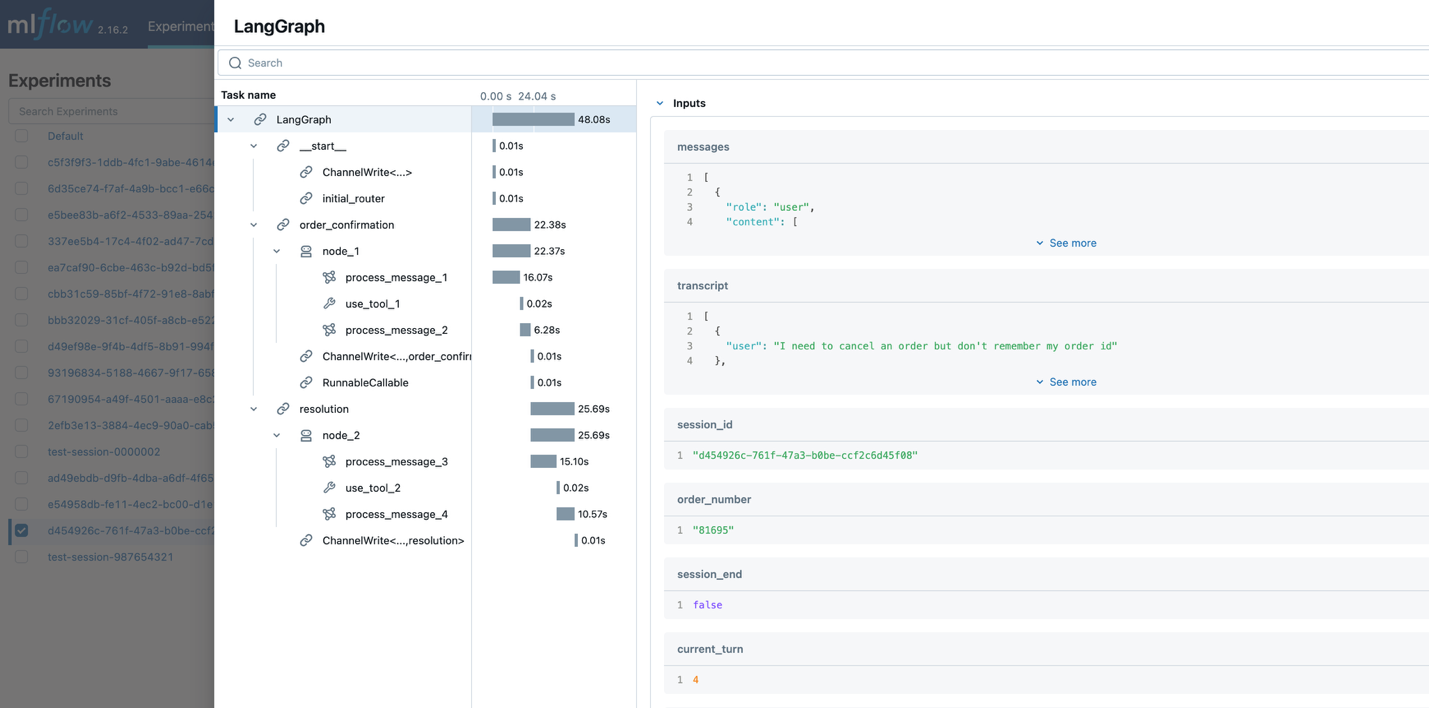
这种可追溯性对于智能体的持续改进至关重要。开发人员可以识别成功对话中的模式,并发现优化机会。
先决条件
要使用 Claude、LangGraph 和 Amazon SageMaker AI 上的托管 MLflow 构建无服务器对话式 AI 智能体,您需要满足以下先决条件:
AWS 账户要求:
- 一个有权创建 Lambda 函数、DynamoDB 表、API 网关、S3 存储桶、CloudFront 分配、Amazon RDS for PostgreSQL 实例和 Amazon Virtual Private Cloud (Amazon VPC) 资源的 AWS 账户
- Amazon Bedrock 访问权限,并启用 Anthropic 的 Claude 3.5 Sonnet
开发环境:
- 在本地机器上安装了 AWS 命令行界面 (AWS CLI)
- 在本地机器上安装了 Git 和 Docker 工具
- 创建 AWS 资源的权限
- Python 3.12 或更高版本
- 安装了 Node.js 20+ 和 npm
- AWS Cloud Development Kit (AWS CDK) CLI 已安装 (
`npm install -g aws-cdk`) - Amazon CloudWatch Logs 角色 Amazon Resource Name (ARN) 已在 API Gateway 账户设置中配置(API Gateway 日志记录要求):
- 创建一个具有所需权限的 AWS Identity and Access Management (IAM) 角色。有关指导,请参阅 CloudWatch 日志记录的权限。
- 在 API Gateway 控制台中配置角色。仅遵循步骤 1–3。
技能和知识:
- 熟悉无服务器架构
- Python 和 React 的基本知识
- 对 AWS 服务(AWS Lambda、Amazon DynamoDB、Amazon VPC)的理解
部署指南
要使用 Claude、LangGraph 和 Amazon SageMaker AI 上的托管 MLflow 构建无服务器对话式 AI 智能体,请按照以下步骤操作:
- 克隆 仓库并设置项目根目录:
git clone https://github.com/aws-samples/sample-aws-genai-serverless-orchestration-chatbot-mlflow.git cd sample-aws-genai-serverless-orchestration-chatbot-mlflow export PROJECT_ROOT=$(pwd)- 引导您的 AWS 环境(如果之前没有引导过,则需要):
cd $PROJECT_ROOT/infra cdk bootstrap- 安装依赖项:
# Install dependencies cd $PROJECT_ROOT make install- 构建和部署应用程序:
cd $PROJECT_ROOT make deploy此脚本将:
- 部署后端基础设施,包括 VPC、Lambda 函数、数据库和 MLflow
- 从后端堆栈获取 Lambda ARN
- 部署带有集成 WebSocket API Gateway 的前端
- 从已部署的堆栈获取实际的 WebSocket API URL
- 创建
config.json并将运行时配置上传到 Amazon S3
清理
为避免因本帖中创建的资源产生持续费用,请在不再需要资源时进行清理。使用以下命令:
cd $PROJECT_ROOT make clean 结论
在本文中,我们展示了如何结合使用来自 Amazon Bedrock 的 LLM 的推理能力、LangGraph 的编排能力以及 Amazon SageMaker AI 上的托管 MLflow 的可观测性来构建客户服务智能体。该架构支持自然、多轮对话,同时在交互中保持上下文,并与后端系统无缝集成以执行订单查找和取消等现实世界操作。
MLflow 提供了全面的可观测性,使开发人员能够监控对话流程、跟踪模型性能并根据实际使用模式优化系统。通过使用 AWS 无服务器服务,此解决方案可以自动扩展以处理不断变化的负载,并通过按使用付费定价来保持成本效益。您可以使用此蓝图来构建复杂的对话式 AI 解决方案,这些方案可以弥合自然语言交互与结构化业务流程之间的差距,从而通过改善客户体验和运营效率来创造业务价值。
准备好将您的对话式 AI 智能体推向更远吗? 立即开始使用 Amazon Bedrock AgentCore,利用智能内存和访问工具及数据的网关,加速您的智能体投入生产。了解 MLflow 如何与 Bedrock AgentCore Runtime 集成,以在您的智能体生态系统中实现全面的可观测性。
关于作者
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区