



📢 转载信息
原文作者:Anirudh Viswanathan, Arun Nagarajan, Fei Wu, Trevor Harvey, and Roy Allela
基础模型训练已达到一个转折点,此时传统的基于检查点的恢复方法已成为影响效率和成本效益的瓶颈。随着模型参数扩展到数万亿级别,训练集群扩展到数千个 AI 加速器,即使是微小的中断也可能导致巨大的成本和延误。
在本文中,我们介绍了 Amazon SageMaker HyperPod 上的无检查点训练,这是一种模型训练的范式转变,它通过实现对等状态恢复,减少了对传统检查点的需求。生产规模验证结果显示,恢复时间减少了 80%–93%(从 15–30 分钟或更长时间缩短到 2 分钟以内),并在具有数千个 AI 加速器的集群规模上实现了高达 95% 的训练 goodput(有效吞吐量)。
理解 Goodput(有效吞吐量)
基础模型训练是 AI 中资源最密集的过程之一,通常涉及数百万美元的计算支出,跨越数千个 AI 加速器运行数天到数月。由于所有计算进程(rank)之间固有的全有或全无(all-or-none)分布式同步,单个进程因软件或硬件故障而丢失,就会导致训练工作负载完全停止。为减轻此类局部故障,业界一直依赖于基于检查点的恢复:根据用户定义的检查点间隔,定期将训练状态(检查点)保存到持久存储中。当发生故障时,训练工作负载会从最新的保存检查点恢复。随着模型规模从数十亿扩展到数万亿参数,训练负载从数百个扩展到数千个 AI 加速器,这种传统的“重启恢复”模式变得越来越站不住脚。
这种在大规模上保持高效训练操作的挑战,催生了 goodput(有效吞吐量)的概念——AI 训练系统中完成的实际有用工作与理论最大容量之比。在基础模型训练中,goodput 受系统故障和恢复开销的影响。系统理论最大吞吐量与其实际生产输出(goodput)之间的差距会随着以下因素而扩大:故障频率增加(集群规模越大,频率越高)、恢复时间延长(与模型规模和集群规模成正比),以及恢复期间资源闲置成本的增加。这个定义有助于说明,随着 AI 训练扩展到更大的集群和更复杂的模型,衡量和优化 goodput 变得越来越关键,因为即使是微小的效率低下也可能导致重大的财务和时间成本。
在一个拥有 256 个 P5 实例的 HyperPod 集群上进行预训练工作负载,每 20 分钟检查一次点,中断时会面临两个挑战:10 分钟的工作丢失,加上 10 分钟的恢复时间。使用成本为每小时 55 美元的 ml.p5.24xlarge 实例,每次中断的计算时间成本为 4,693 美元。对于一个为期一个月的训练,每日中断的额外成本将累积到 141,000 美元,并使完成时间延迟 10 小时。
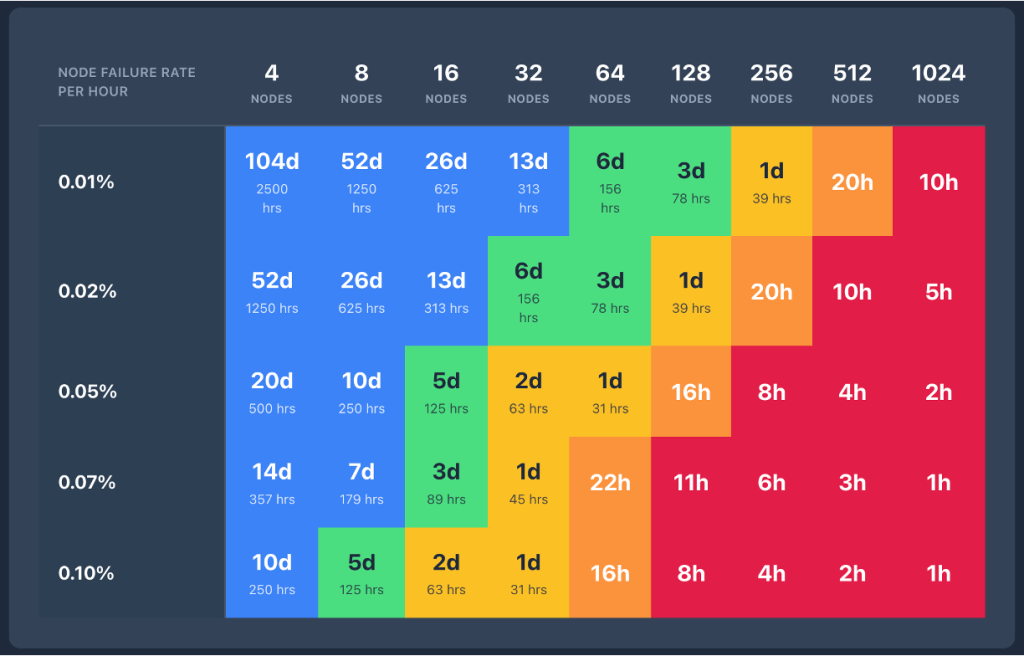
随着集群规模的增长,发生故障的概率和频率可能会增加。
随着训练跨越数千个节点,故障引起的干扰变得越来越频繁。与此同时,恢复速度变慢,因为工作负载重新初始化的开销与集群规模成线性增长。大规模 AI 训练故障的累积影响每年可能达到数百万美元,并直接转化为上市时间延迟、模型迭代周期减慢和竞争劣势。每一小时闲置的 GPU 时间,都是一小时没有用于提升模型能力的时间。
基于检查点的恢复
分布式训练中的基于检查点的恢复比通常理解的要复杂和耗时得多。当传统分布式训练中发生故障时,重启过程涉及的远不止是加载最后一个检查点。了解恢复过程中发生的情况,就能明白为什么需要这么长时间,以及为什么整个集群都必须保持空闲。
全有或全无的级联效应
单次故障——一个 GPU 错误、一次网络超时或一次硬件故障——都可能触发整个训练集群的关闭。由于分布式训练将所有进程视为紧密耦合的,任何单一故障都需要完全重启。当任何进程失败时,编排系统(例如 TorchElastic 或 Kubernetes)必须终止所有节点上的所有进程,然后从头开始重启训练作业。每次重启都需要经历一个复杂的多阶段恢复过程,其中每个阶段都是顺序且阻塞的:
- 阶段 1:训练作业重启 – 训练作业编排器检测到故障,终止所有节点上的所有进程,然后进行集群范围的重启或重新启动训练作业。
- 阶段 2:进程和网络初始化 – 每个进程必须从头开始重新执行训练脚本。这包括 rank(进程)初始化、从持久存储(如网络文件系统 (NFS) 或对象存储)加载 Python 模块,以及通过对等发现和进程组创建来建立训练拓扑和通信后端。仅进程组初始化在大型集群上就可能需要花费数十分钟。
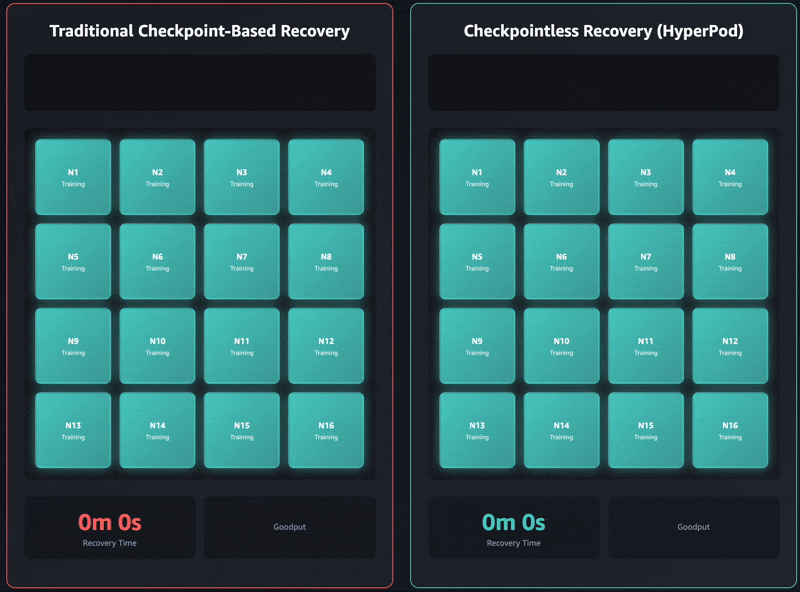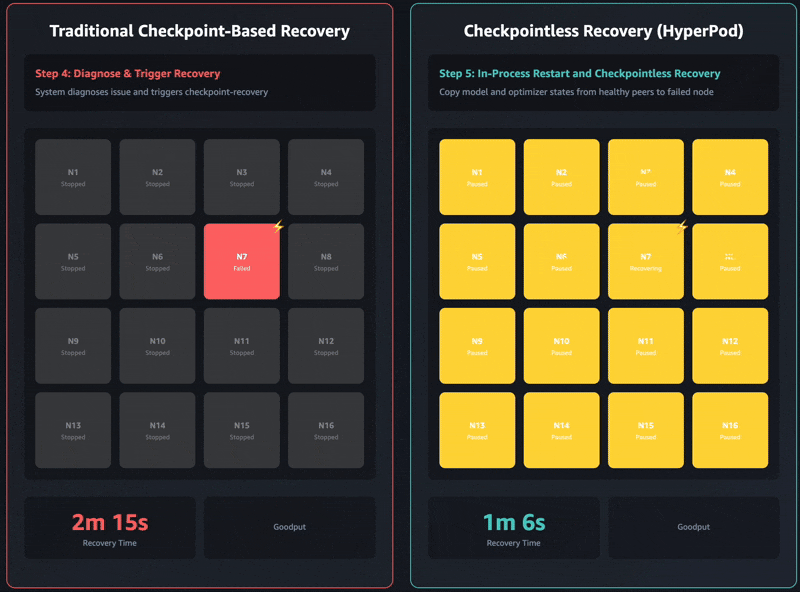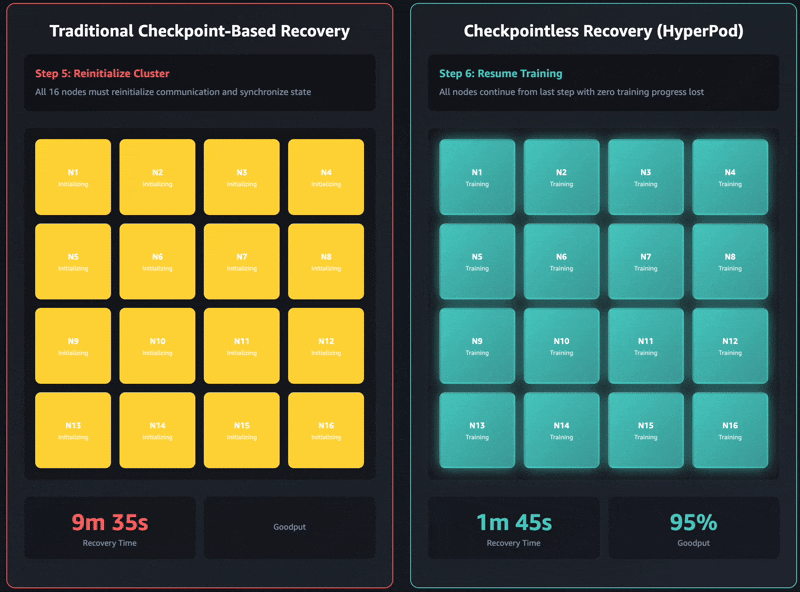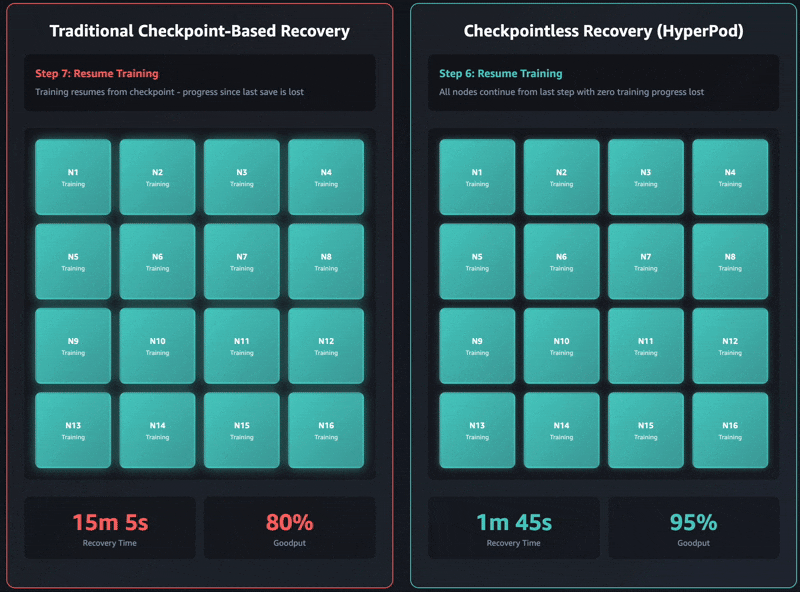
- 阶段 3:检查点检索 – 每个进程首先必须确定最后完全保存的检查点,然后从持久存储(例如 NFS 或对象存储)中检索它,并加载多个状态字典:模型的参数和缓冲区、优化器的内部状态(动量、方差等)、学习率调度器以及训练循环元数据(epoch、批次编号)。此步骤根据集群和模型大小,可能需要花费数十分钟或更长时间。
- 阶段 4:数据加载器初始化 – 负责数据加载的进程有额外的责任来初始化数据缓冲区。这包括从持久存储(如 Amazon FSx 或 Amazon Simple Storage Service (Amazon S3))中检索数据检查点,并预取训练数据以开始训练循环。数据检查点是避免在训练中断时重复处理相同数据样本或跳过样本的关键步骤。根据数据混合策略、数据局部性和带宽,此过程可能需要几分钟时间。
- 阶段 5:第一步开销 – 在检索并加载检查点和训练数据之后,运行第一步训练还会产生额外的开销,我们称之为第一步开销 (FSO)。在第一步中,通常需要时间进行内存分配、为与 GPU 通信创建和设置 CUDA 上下文,以及 CUDA 图的编译部分等等。
- 阶段 6:丢失步数开销 – 只有在所有先前阶段成功完成后,训练循环才能恢复其常规进度。由于训练是从最后保存的模型检查点恢复的,因此在检查点和遇到故障之间计算出的所有步骤都会丢失。这些丢失的步骤需要重新计算,我们称之为丢失步数开销 (LSO)。在重新计算阶段之后,训练作业恢复产生直接贡献于 goodput 的生产性工作。
无检查点训练如何消除这些瓶颈
上面概述的五个阶段——终止和重启、进程发现和网络设置、检查点检索、GPU 上下文重新初始化以及训练循环恢复——代表了基于检查点恢复中的基本瓶颈。每个阶段都是顺序且阻塞的,对于大型模型,训练恢复可能需要几分钟到数小时。关键在于,整个集群必须等待每个阶段完成,训练才能恢复。
无检查点训练消除了这种级联效应。它在整个分布式集群中保持模型状态一致性,消除了定期快照的需求。当发生故障时,系统通过使用健康的对等节点快速恢复,避免了传统检查点方法通常需要的存储 I/O 操作和完全进程重启。
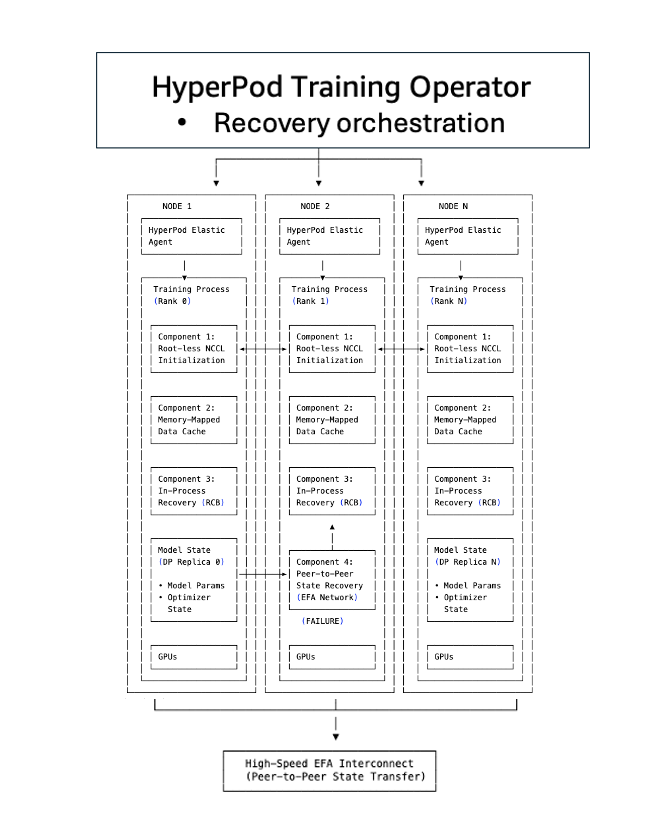
无检查点训练架构
无检查点训练建立在五个组件之上,它们协同工作以消除传统的检查点-重启瓶颈。每个组件都针对恢复过程中的特定瓶颈,它们共同实现了在数分钟内自动检测和恢复基础设施故障的能力,无需人工干预,即使在拥有数千个 AI 加速器的情况下也是如此。
组件 1:无 TCPStore/无根的 NCCL 和 Gloo 初始化(优化阶段 2)
在典型的分布式训练设置中(例如,使用 torch.distributed),所有 rank 都必须初始化一个进程组。进程组创建一个通信层,允许所有进程(或 rank,即单个节点)相互了解并交换信息。通常使用 TCPStore 作为集合点,所有 rank 在此签到以发现彼此的连接信息。当数千个 rank 同时尝试联系一个指定的根服务器(通常是 rank 0)时,这会成为一个瓶颈。这会导致单个根服务器的网络请求泛滥,可能导致网络拥塞、延迟增加数十分钟,并进一步减慢通信过程。
无检查点训练消除了这种集中式依赖。系统不再通过单个根服务器引导所有连接请求,而是使用对称地址模式,其中每个 rank 使用全局组计数器独立计算对等连接信息。rank 使用预先确定的端口分配直接相互连接,从而避免了 TCPStore 瓶颈。进程组初始化时间从数十分钟缩短到几秒钟,即使在拥有数千个节点的集群上也是如此。该系统还消除了基于根的初始化固有的单点故障风险。
组件 2:内存映射数据加载(优化阶段 4)
传统恢复中隐藏的成本之一是重新加载训练数据。当进程重启时,它必须从磁盘重新加载批次,重建数据加载器状态,并小心地定位自己,以避免处理重复样本或跳过数据。在大规模训练中,这种数据加载可能会给每次恢复周期增加几分钟的时间。
无检查点训练使用内存映射数据加载在加速器之间维护缓存的数据。训练数据被映射到共享内存区域,这些区域即使在单个进程失败时也会持久存在。当节点恢复时,它不需要从磁盘重新加载数据,而是重新连接到现有的内存映射缓存。数据加载器状态得以保留,有助于确保训练从正确的位置继续,而不会出现重复或跳过的数据。MMAP 还可以通过每个节点只维护一份数据副本(相比传统数据加载器在 8 GPU 节点上有八份副本)来减少主机 CPU 内存使用量,并且训练可以在使用缓存批次的同时立即恢复,而数据加载器会同时在后台预取下一批数据。
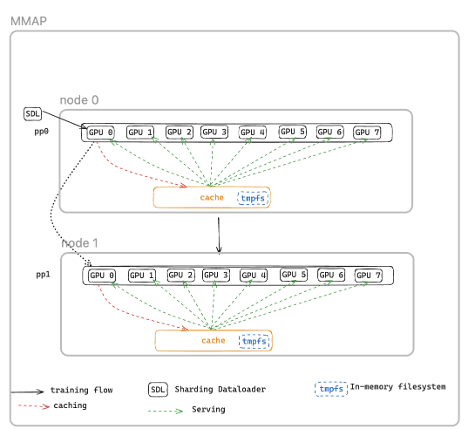
内存映射数据加载工作流程
组件 3:进程内恢复(优化阶段 1、2 和 5)
传统的基于检查点的恢复将故障视为作业级别的事件:单个 GPU 错误触发整个分布式训练作业的终止。集群中的每个进程都必须被杀死并重启,即使只有一个组件发生故障。
无检查点训练使用进程内恢复将故障隔离到进程级别。当 GPU 或进程失败时,只有失败的进程执行进程内恢复,在几秒钟内重新加入训练循环,克服可恢复或瞬态错误。健康的进程继续运行而不会中断。失败的进程保持运行(避免完全进程终止),保留 CUDA 上下文、编译器缓存和 GPU 状态,从而消除了数分钟的重新初始化开销。在错误不可恢复的情况下(例如硬件故障),系统会自动用预热的热备件替换有故障的组件,使训练得以不中断地继续。
这消除了对完全集群终止和重启的需求,从而极大地减少了恢复开销。
组件 4:对等状态复制(优化阶段 3 和 6)
基于检查点的恢复需要从持久存储(如 Amazon S3 或 FSx for Lustre)加载模型和优化器状态。对于包含数十亿到数万亿参数的模型,这意味着通过网络传输数十到数百 GB 的数据,反序列化状态字典,并重建优化器缓冲区,这可能需要数十分钟,并产生巨大的 I/O 瓶颈。
无检查点训练最关键的创新是持续的对等状态复制。每个 GPU 不再定期将模型状态保存到集中式存储,而是将模型分片(shard)的冗余副本保存在对等 GPU 上。当发生故障时,恢复中的进程不会从 Amazon S3 加载。它会直接从健康的对等节点通过高速 Elastic Fabric Adapter (EFA) 网络互连复制状态。这种对等架构消除了主导传统检查点恢复的 I/O 瓶颈。状态传输在几秒钟内完成,而从存储加载多 GB 检查点则需要数分钟。恢复中的节点仅拉取其所需的分片,进一步减少了传输时间。
组件 5:SageMaker HyperPod 训练操作员(优化所有阶段)
SageMaker HyperPod 训练操作员(Training Operator)负责编排无检查点训练组件,充当连接初始化、数据加载、无检查点恢复和检查点回退机制的协调层。它维护一个集中的控制平面,对整个集群中的训练进程健康状况拥有全局视图,协调故障检测、恢复决策和集群范围的同步。
该操作员实施智能恢复升级:它首先尝试对失败的组件执行进程内重启,如果不可行(例如,由于容器崩溃或节点故障),它会升级到进程级别恢复。在进程级别恢复期间,当发生故障时,操作员仅重启训练进程,而保持容器存活,而不是重启整个作业。因此,恢复时间比作业级别重启要快,后者需要拆除和重新创建训练基础设施,涉及 pod 重新调度、容器拉取、环境初始化以及从检查点重新加载。当发生故障时,操作员会广播协调的停止信号以防止级联超时,并与 SageMaker HyperPod 健康监控代理集成,以自动检测硬件问题并触发恢复,无需人工干预。
开始使用无检查点训练
本节将指导您如何在 SageMaker HyperPod 上设置和配置无检查点训练,以将故障恢复时间从数小时缩短到几分钟。
先决条件
在将无检查点训练集成到您的训练工作负载之前,请验证您的环境是否满足以下要求:
基础设施要求:
- 由 Amazon Elastic Kubernetes Service (Amazon EKS) 编排的 Amazon SageMaker HyperPod 集群
- 集群上安装了 HyperPod 训练操作员 v1.2 或更高版本
- 推荐的实例类型:
ml.p5.、p5e.或p5en.48xlarge、ml.p6.p6-b200.48xlarge或ml.p6e-gb200.36xlarge - 最小集群规模:用于对等无检查点恢复的两个节点
软件要求:
- 支持的框架:Nemo、PyTorch、PyTorch Lightning
- 训练数据格式:JSON、JSONGZ(压缩 JSON)或 ARROW
- 用于容器镜像的 Amazon Elastic Container Registry (Amazon ECR) 仓库。使用 HyperPod 无检查点训练容器——这是无根 NCCL 初始化(Tier 1)和对等无检查点恢复(Tier 4)所必需的
658645717510.dkr.ecr.<region>.amazonaws.com/sagemaker-hyperpod/pytorch-training:2.3.0-checkpointless无检查点训练工作流程
无检查点训练旨在增量采用。您可以从基本功能开始,并随着训练规模的扩大逐步启用高级功能。集成分为四个层级,每一层都建立在前一层的基础上:
Tier 1:NCCL 初始化优化
NCCL 初始化优化消除了初始化期间集中式根进程的瓶颈。节点使用基础设施信号独立发现并连接到对等节点。这使得进程组初始化更快(几秒而不是几分钟),并消除了启动期间的单点故障风险。
集成步骤:在作业规范中启用一个环境变量,并验证作业是否使用无检查点训练容器运行。
# kubernetes job spec
env: - name: HPCT_USE_CONN_DATA # Enable Rootless value: "1" - name: TORCH_SKIP_TCPSTORE # Enable TCPStore Removal value: "1"Tier 2:内存映射数据加载
内存映射数据加载将训练数据缓存到跨进程重启的共享内存中,消除了恢复期间的数据重新加载开销。这使得在恢复期间可以即时访问数据。进程重启时无需重新加载或重新洗牌数据。
集成步骤:使用内存映射缓存增强现有的数据加载器
from hyperpod_checkpointless_training.dataloader.mmap_data_module import MMAPDataModule
from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig
base_data_module = MY_DATA_MODULE(...). # Customer's own datamodule
mmap_config = CacheResumeMMAPConfig(
cache_dir=self.cfg.mmap.cache_dir,
)
mmap_dm = MMAPDataModule(
data_module=base_data_module,
mmap_config=CacheResumeMMAPConfig(
cache_dir=self.cfg.mmap.cache_dir,
),
)
Tier 3:进程内恢复
进程内恢复将故障隔离到单个进程,而不是要求完全重新启动作业。失败的进程独立恢复,而健康的进程继续训练。它实现了对进程级别故障的亚分钟级恢复。健康的进程保持存活,而失败的进程独立恢复。
集成步骤:
from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck
from hyperpod_checkpointless_training.inprocess.wrap import HPCallWrapper, HPWrapper
from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory
@HPWrapper(
health_check=CudaHealthCheck(),
hp_api_factory=HPAgentK8sAPIFactory(),
abort_timeout=60.0,
)
def re_executable_codeblock(): # The re-executable codeblock defined by user, usually it's main function or train loop
...
Tier 4:无检查点(对等恢复)(NeMo 集成)
无检查点恢复实现了完全的对等状态复制和恢复。失败的进程直接从健康的对等节点恢复模型和优化器状态,而无需从存储中加载。此步骤实现了检查点加载的消除。失败的进程通过高速 EFA 互连从健康的副本恢复模型和优化器状态。
集成步骤:
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper
from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck
from hyperpod_checkpointless_training.inprocess.wrap import HPCallWrapper
from hyperpod_checkpointless_training.checkpoint_manager import PEFTCheckpointManager
from hyperpod_checkpointless_training.abort_manager import CheckpointlessAbortManager
from hyperpod_checkpointless_training.finalize_cleanup import CheckpointlessFinalizeCleanup
from pytorch_lightning.plugins.precision import CheckpointlessMegatronStrategy
from pytorch_lightning.callbacks import Callback
from pytorch_lightning.plugins.connector import CheckpointlessCompatibleConnector
from typing import Optional
wait_rank()
def main():
@HPWrapper(
health_check=CudaHealthCheck(),
hp_api_factory=HPAgentK8sAPIFactory(),
abort_timeout=60.0,
checkpoint_manager=PEFTCheckpointManager(enable_offload=True),
abort=CheckpointlessAbortManager.get_default_checkpointless_abort(),
finalize=CheckpointlessFinalizeCleanup(),
)
def run_main(cfg, caller: Optional[HPCallWrapper] = None):
...
trainer = Trainer(
strategy=CheckpointlessMegatronStrategy(
...,
num_distributed_optimizer_instances=2
),
callbacks=[..., CheckpointlessCallback(...)],
)
trainer.fresume = resume
trainer._checkpoint_connector = CheckpointlessCompatibleConnector(trainer)
trainer.wrapper = caller
# 示例:需要根据实际代码结构调整,此处仅为展示相关组件的使用
wait_rank:所有 rank 将等待来自 HyperPod 训练操作员基础设施的 rank 信息。
HPWrapper:Python 函数包装器,为可重启代码块 (RCB) 启用重启功能。该实现使用上下文管理器而不是 Python 装饰器,因为调用包装器缺乏它应该监控的 RCB 数量信息。
CudaHealthCheck:有助于确保当前进程的 CUDA 上下文处于健康状态。它与 GPU 同步,并使用对应于 LOCAL_RANK 环境变量的设备,或者如果环境中未指定 LOCAL_RANK,则使用主线程的默认 CUDA 设备。
HPAgentK8sAPIFactory:这是无检查点训练将用来了解 K8s 训练集群中其他 pod 训练状态的 API。它还提供了一个基础设施级别的屏障,确保每个 rank 都能成功执行中止和重启操作。
CheckpointManager:管理内存中检查点和对等恢复,以实现无检查点容错。
我们建议从 Tier 1 开始并在您的环境中进行验证。当数据加载开销成为瓶颈时,添加 Tier 2。在最大的训练集群上采用 Tier 3 和 Tier 4 以实现最大的弹性。
对于 NeMo 用户和 HyperPod recipe 用户,Tier 4 开箱即用,只需对 Llama 和 GPT 开源 recipe 进行最少的配置更改。Llama 和 GPT 开源模型的 NeMo 示例可在 SageMaker HyperPod 无检查点训练中找到。
性能结果
无检查点训练已在多个集群配置上进行了生产规模验证。最新的 Amazon Nova 模型就是使用这项技术在数万个 AI 加速器上训练的。
在本节中,我们展示了跨越 16 个 GPU 到 2,304 个 GPU 的一系列集群规模的广泛测试结果。与传统的基于检查点的恢复相比,无检查点训练在恢复时间上显示出显著的改进,一致地将停机时间减少了 80%–93%。
| 集群(H100s) | 模型 | 传统恢复 | 无检查点恢复 | 改进率 |
|---|---|---|---|---|
| 2,304 个 GPU | 内部模型 | 15–30 分钟 | 少于 2 分钟 | ~87–93% 更快 |
| 256 个 GPU | Llama-3 70B(预训练) | 4 分 52 秒 | 47 秒 | ~84% 更快 |
| 16 个 GPU | Llama-3 70B(微调) | 5 分 10 秒 | 50 秒 | ~84% 更快 |
这些恢复时间上的改进与 ML goodput(定义为集群在训练中取得进展的百分比,而不是在故障期间闲置的时间)直接相关。随着集群扩展到数千个节点,故障频率按比例增加。同时,由于协调开销的增加,传统基于检查点的恢复时间也随集群规模的增加而增加。这就产生了一个复合问题:更频繁的故障与更长的恢复时间相结合,在大规模上快速侵蚀 goodput。
无检查点训练对整个恢复堆栈进行了优化,即使在拥有数千个 AI 加速器的集群上也能实现超过 95% 的 goodput。根据我们的内部研究,我们在超过 2,300 个 GPU 的大规模部署中一致观察到 goodput 高达 95% 以上。
我们还验证了模型训练准确性不受无检查点训练的影响。具体来说,我们测量了传统基于检查点的训练和无检查点训练的校验和匹配,并在每个训练步骤中验证了训练损失的逐位匹配。下图显示了在 32 个 ml.p5.48xlarge 实例上进行 Llama-3 70B 预训练工作负载时,传统检查点与无检查点训练的损失对比。

结论
基础模型训练已达到一个转折点。随着集群扩展到数千个 AI 加速器,训练运行延长至数月,传统的基于检查点的恢复范式正日益成为瓶颈。过去可能只导致几分钟停机的单个 GPU 故障,现在会在数千个 AI 加速器上引发数十分钟的集群空闲时间,累计成本每年达到数百万美元。
无检查点训练彻底重新思考了这一范式,将故障视为局部的、可恢复的事件,而不是集群范围的灾难。失败的进程在几秒钟内从健康的对等节点恢复状态,使集群的其余部分能够继续向前推进。这一转变是根本性的:从...
🚀 想要体验更好更全面的 AI 调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区