



📢 转载信息
原文链接:https://www.kdnuggets.com/context-engineering-explained-in-3-levels-of-difficulty
原文作者:Bala Priya C

情境工程的三个难度等级详解 | 图片来源:作者
# 引言
大型语言模型(LLM)应用的上下文窗口限制问题层出不穷。模型会忘记早先的指令,丢失相关信息的追踪,或者随着交互的延长而导致质量下降。这是因为LLM具有固定的Token预算,但应用会生成无界限的信息——包括对话历史、检索到的文档、文件上传、应用程序编程接口(API)响应以及用户数据。如果没有管理,重要信息可能会被随机截断或根本无法进入上下文。
情境工程将上下文窗口视为一种受管理的资源,采用明确的分配策略和记忆系统。您决定哪些信息进入上下文、何时进入、停留多久,以及哪些内容需要被压缩或归档到外部记忆中以便检索。这种方式在应用运行时编排信息的流动,而不是寄希望于一切都能塞进去,或接受性能下降的结果。
本文将从三个层面解释情境工程:
- 理解情境工程的基本必要性
- 在生产系统中实施实用的优化策略
- 回顾高级的记忆架构、检索系统和优化技术
接下来的部分将详细探讨这些层面。
# 级别 1:理解上下文瓶颈
LLM具有固定的上下文窗口。在推理时,模型所知道的一切都必须装入这些Token中。对于单轮补全任务来说,这不是一个大问题。但对于进行多步骤任务的检索增强生成(RAG)应用和AI智能体(Agent)而言,这些任务涉及工具调用、文件上传、对话历史和外部数据,这就产生了一个优化问题:哪些信息应该获得关注,哪些信息应该被丢弃?
假设您有一个运行多步的智能体,它进行了50次API调用并处理了10份文档。这种智能体AI系统在没有明确情境管理的情况下,很可能会失败。模型会忘记关键信息、误报工具输出,或者随着对话的延长而质量下降。
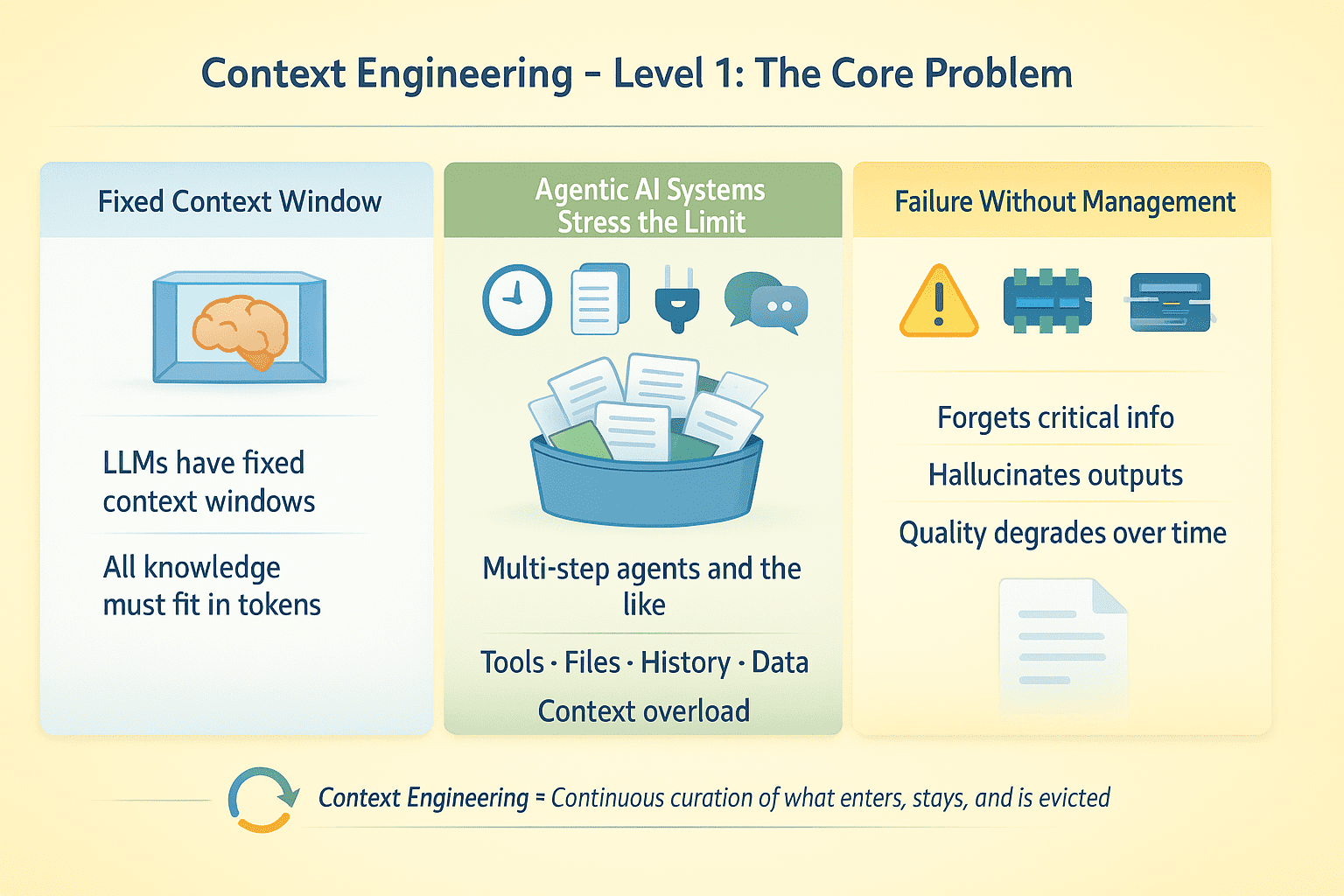
情境工程级别 1 | 图片来源:作者
情境工程在于设计在模型执行过程中持续策展围绕LLM的信息环境。这包括管理哪些信息进入上下文、何时进入、停留多久,以及空间不足时哪些信息被逐出。
# 级别 2:实践中优化上下文
有效的上下文工程需要在多个维度上采取明确的策略。
// Token预算分配
请有计划地分配您的上下文窗口。系统指令可能占用2K个Token。对话历史、工具模式、检索到的文档和实时数据都可能迅速累积。如果上下文窗口非常大,则有足够的余量。如果窗口小得多,您就必须在保留什么和丢弃什么之间做出艰难的权衡。
// 截断对话
保留最近的轮次,丢弃中间轮次,并保留关键的早期上下文。总结(Summarization)有效,但会损失保真度。有些系统实施了语义压缩——提取关键事实而不是逐字保留文本。测试您的智能体在对话延长时何处会中断。
// 管理工具输出
大型API响应会快速消耗Token。请求特定字段而不是完整的有效载荷,截断结果,在返回给模型之前进行总结,或使用多轮策略,即智能体首先获取元数据,然后仅请求相关项的详细信息。
// 使用模型上下文协议和按需检索
不要预先加载所有内容,而是将模型连接到它在需要时查询的外部数据源,使用模型上下文协议(MCP)。智能体根据任务需求决定获取什么。这使得问题从“将所有内容塞进上下文”转变为“在正确的时间获取正确的东西”。
// 分离结构化状态
将稳定的指令放入系统消息中。将可变数据放入用户消息中,以便在不修改核心指令的情况下更新或移除它。将对话历史、工具输出和检索到的文档视为具有独立管理策略的单独流。

情境工程级别 2 | 图片来源:作者
这里的实际转变是,将上下文视为一种在智能体运行时需要主动管理的动态资源,而不是一次性配置的静态事物。
# 级别 3:在生产环境中实施情境工程
大规模的情境工程需要复杂的记忆架构、压缩策略和检索系统协同工作。以下是如何构建生产级别的实现方法。
// 设计记忆架构模式
在智能体AI系统中,将记忆划分为多个层级:
- 工作记忆(活动的上下文窗口)
- 情景记忆(压缩的对话历史和任务状态)
- 语义记忆(事实、文档、知识库)
- 程序记忆(指令)
工作记忆是模型当前所见,应针对即时任务需求进行优化。情景记忆存储了发生过的事情。您可以进行激进的压缩,但要保留时间关系和因果链。对于语义记忆,按主题、实体和相关性存储索引以便快速检索。
// 应用压缩技术
天真的总结会丢失关键细节。更好的方法是提取式压缩,即识别并保留高信息密度的句子,同时丢弃填充内容。
- 对于工具输出,提取结构化数据(实体、指标、关系)而不是散文式总结。
- 对于对话,精确保留用户意图和智能体承诺,同时压缩推理链。
// 设计检索系统
当模型需要上下文中不存在的信息时,检索质量决定了成功与否。实施混合搜索:使用密集嵌入进行语义相似性搜索,使用BM25进行关键词匹配,并使用元数据过滤器来提高精度。
根据新近度、相关性和信息密度对结果进行排序。返回前 K 个结果,但也要展示接近匹配项;模型应该知道哪些内容几乎匹配。检索是在上下文内发生的,因此模型会看到查询的构建和结果。糟糕的查询产生糟糕的结果;暴露这一点可以实现自我修正。
// 在Token级别进行优化
持续分析您的Token使用情况。
- 系统指令消耗了5K Token却可以缩减到1K?重写它们。
- 工具模式是否冗长?使用紧凑的
JSON模式而不是完整的OpenAPI规范。 - 对话轮次是否重复相似内容?进行去重。
- 检索到的文档是否有重叠?在添加到上下文之前进行合并。
节省的每一个Token,都是可用于任务关键信息的Token。
// 触发记忆检索
模型不应持续检索;这既昂贵又会增加延迟。实施智能触发器:当模型明确请求信息时检索,检测到知识差距时检索,任务切换时检索,或当用户引用了过去的上下文时检索。
当检索没有返回有用信息时,模型应该明确地知道这一点,而不是产生幻觉。返回空结果并附带元数据:“在知识库 Y 中未找到匹配查询 X 的文档。”这允许模型通过重新构建查询、搜索另一个源或告知用户信息不可用,来调整策略。

情境工程级别 3 | 图片来源:作者
// 合成多文档信息
当推理需要多个来源时,分层处理。
- 第一遍:从每个文档中提取关键事实(可并行化)。
- 第二遍:将提取的事实加载到上下文中并进行综合。
这种方法避免了因加载10个完整文档而耗尽上下文,同时保留了多源推理能力。对于相互矛盾的来源,保留其矛盾之处。让模型看到冲突的信息,并解决它或向用户标记出来。
// 持久化对话状态
对于暂停和恢复的智能体,将上下文状态序列化到外部存储中。保存压缩的对话历史、当前任务图、工具输出和检索缓存。恢复时,重建最小必需上下文;不要重新加载所有内容。
// 评估和衡量性能
跟踪关键指标以了解您的情境工程策略的表现情况。监控上下文利用率,查看窗口的平均使用百分比,以及逐出频率,以了解您多久会达到上下文限制一次。通过检查检索到的文档中有多少比例是相关且被使用的,来衡量检索精度。最后,跟踪信息持久性,查看重要事实在丢失前能保留多少轮次。
# 总结
情境工程归根结底是信息架构。您正在构建一个系统,其中模型可以访问其上下文窗口中的所有内容,但无法访问窗口之外的内容。每一个设计决策——压缩什么、检索什么、缓存什么、丢弃什么——都决定了应用程序运行的信息环境。
如果您不关注情境工程,您的系统可能会产生幻觉、忘记重要细节或随着时间的推移而崩溃。把它做好,您就能得到一个在复杂、延长的交互过程中保持连贯、可靠和有效的LLM应用,尽管其底层架构存在局限性。
祝您情境工程顺利!
# 参考文献与进一步学习
Bala Priya C 是来自印度的开发人员和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点工作。她的兴趣和专长领域包括DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正致力于通过撰写教程、操作指南、观点文章等内容来学习并与开发者社区分享她的知识。Bala还创建了引人入胜的资源概述和编码教程。
{kind=link}
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区