



📢 转载信息
原文链接:https://www.kdnuggets.com/data-lake-vs-data-warehouse-vs-lakehouse-vs-data-mesh-whats-the-difference
原文作者:Shittu Olumide

Image by Author
数据管理架构的介绍
数据工程的世界充满了流行词汇。对于初级数据科学家来说,在同一场对话中听到“数据湖”、“数据仓库”、“湖仓一体”和“数据网格”等术语可能会令人困惑。它们是相同的东西吗?它们会相互竞争吗?你真正需要的是哪一个呢?
了解这些概念非常重要,因为你选择的结构决定了你如何存储、访问和分析数据。它影响着从机器学习模型的速度到你对业务报告的依赖程度的方方面面。
在本文中,我将用简单的术语解释这四种数据管理方法。读完之后,你将了解每种架构的区别、优势和劣势,并知道何时使用它们。文章的最后,你将获得一个清晰的路线图,帮助你驾驭现代数据格局。
理解数据仓库
让我们从最古老、最成熟的概念开始:数据仓库。想象一个干净、有序的图书馆。每一本书(数据片段)都在其正确的位置,经过编目,并格式化为易于阅读。
数据仓库正是结构化数据的干净、有序的图书馆。数据仓库是一个集中的位置,用于存储结构化、经过处理的数据,这些数据已针对分析和报告进行了优化。它遵循“写入时模式”(schema-on-write)原则。这意味着在数据加载到仓库之前,它必须经过清理、转换并组织成特定的格式——通常是具有行和列的表。
关键特征
- 它主要存储来自交易系统、操作数据库和业务线应用程序的结构化数据。
- 它严重依赖提取、转换、加载(ETL)过程。数据从源头提取出来,经过转换(清理、聚合),然后加载到仓库中。
- 由于数据是预先处理和结构化的,因此查询速度极快且高效。它针对 Tableau 或 Power BI 等商业智能(BI)工具进行了优化。
- 业务分析师可以使用 SQL 轻松查询数据,而无需深厚的专业技术知识。
数据仓库的四个组成部分
每个数据仓库都包含四个基本组成部分,它们是:
- 中央数据库:核心存储系统
- ETL 工具:用于处理数据的提取、转换、加载工具
- 元数据:关于数据的数据(描述、上下文)
- 访问工具:用于查询和报告的接口
定义数据仓库中的加载管理器
加载管理器是处理 ETL 过程的组件。它从源头提取数据,根据业务规则转换数据,然后将其加载到仓库中。可以将其视为装卸码头的工作人员,他们接收货物、清点库存并将物品放置在正确的位置。
回顾常见工具
流行的现代数据仓库解决方案包括 Snowflake、Amazon Redshift、Google BigQuery 和 Microsoft Azure Synapse。Snowflake 是数据仓库吗?是的,Snowflake 是一个云数据仓库,它将存储与计算分离,允许两者独立扩展。
了解何时使用数据仓库
当你需要以下功能时,请使用数据仓库:
- 针对结构化数据的快速查询性能
- 商业智能和报告
- 业务指标的单一事实来源
- 数据一致性和高数据质量
- 基于历史可靠数据支持业务决策
理解数据湖
随着数据量和多样性(如社交媒体帖子、图像和物联网(IoT)传感器数据)的增加,数据仓库的刚性结构就成了一个问题。这时你就需要使用数据湖了。
如果数据仓库是一个图书馆,那么数据湖就是一个水库。它遵循“读取时模式”(schema-on-read)原则。你首先以原始、原生格式存储数据,只有在你准备好读取和分析它时才应用结构。
关键特征
数据湖使用读取时模式,这意味着你在读取数据时定义结构,而不是在存储数据时定义。它们可以处理所有数据类型:
- 结构化数据(表、CSV 文件)
- 半结构化数据(JSON、XML、日志)
- 非结构化数据(图像、视频、音频文件)
明确数据湖工作负载
数据湖主要支持用于分析和大数据处理的在线分析处理(OLAP)工作负载。但是,它们也可以通过变更数据捕获(CDC)流程从在线事务处理(OLTP)系统摄取数据。
澄清 Apache Kafka 和数据湖
不,Apache Kafka 不是数据湖。Kafka 是一个分布式事件流处理平台,用于实时数据插入。然而,Kafka 通常会向数据湖输入数据,充当将流数据传输到存储的管道。
回顾常见工具
流行的现代数据湖解决方案包括 Amazon S3、Azure Data Lake Storage (ADLS)、Google Cloud Storage 和 Hadoop HDFS。
了解何时使用数据湖
当你需要以下功能时,请使用数据湖:
- 存储大量的物联网传感器数据以供未来的机器学习项目使用
- 保存用户点击流日志以进行行为分析
- 为合规性目的存档原始数据
- 存储任何数据类型的灵活性
- 数据科学和机器学习用例
- 经济高效的存储(数据湖比数据仓库便宜)
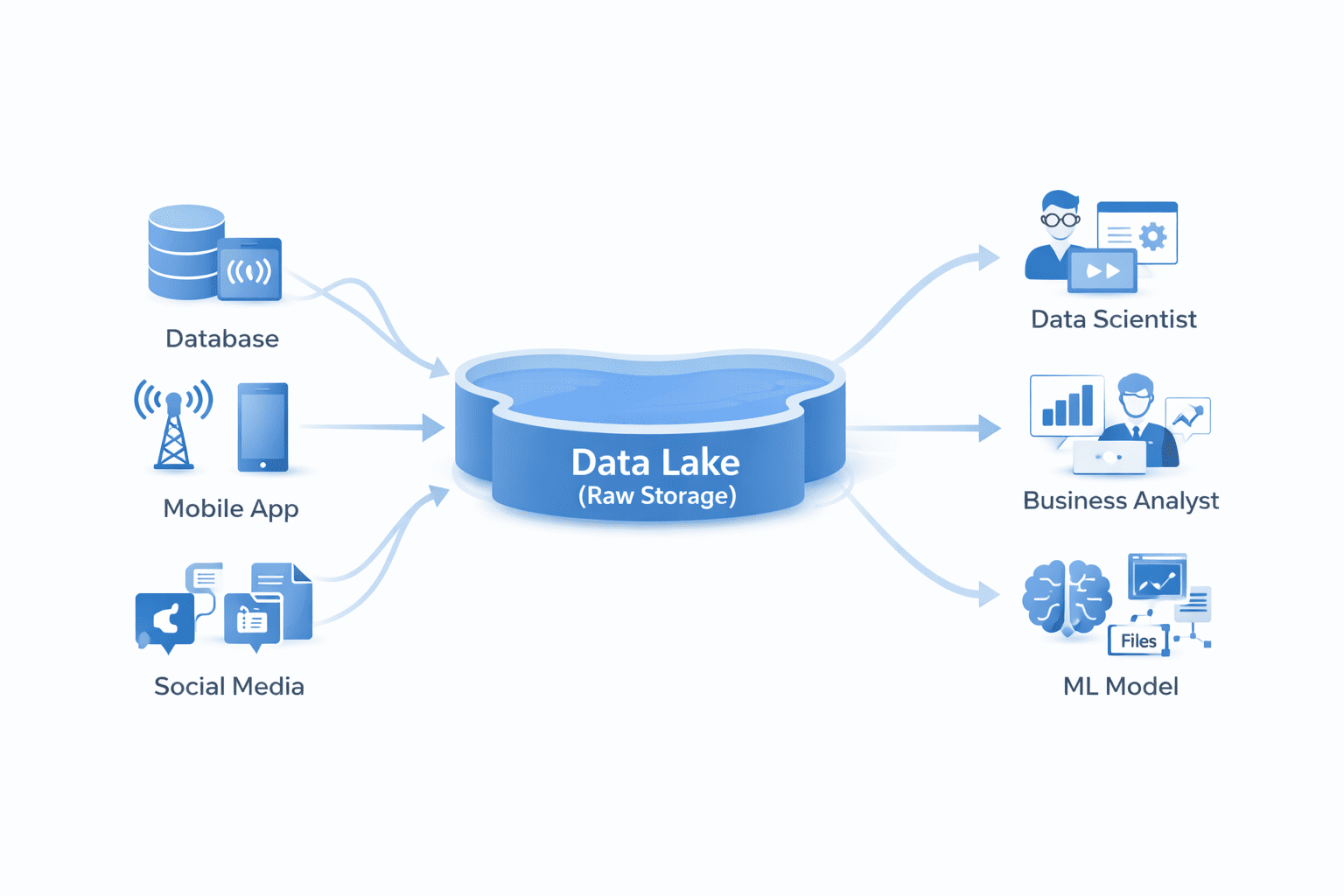
数据湖架构,展示了多样化的数据源流入原始存储,各种使用者访问数据 | Image by Author
进一步的关键特征
- 它存储所有数据类型,包括结构化和半结构化数据(JSON、XML、日志)以及非结构化数据(图像、视频、音频)。
- 它使用提取、加载、转换(ELT)。数据首先以原始形式提取和加载。转换在稍后读取数据进行分析时发生。
- 它构建在廉价、可扩展的对象存储(如 Amazon S3 或 Azure Blob Storage)之上;这是一种经济高效的存储方式;与仓库相比,存储 PB 级数据要便宜得多。
- 数据科学家喜欢数据湖,因为他们可以探索原始数据、进行实验和构建模型,而不会受到预定义模式的限制。
然而,这种灵活性是有代价的。如果没有适当的管理,数据湖可能会迅速变成“数据沼泽”,即一堆混乱的、不可用、未经编目的数据。
一个宽阔的水库,有多个管道流入(日志、图像、数据库、JSON) | Image by Author
理解湖仓一体(Lakehouse)
现在你有了低成本、灵活的数据湖,以及高性能、可靠的数据仓库。多年来,组织不得不二选一,或者维护两个独立的系统(成本高昂的“两层”架构),这导致了不一致和延误。
湖仓一体是解决这个问题的方案。它是一种新的、开放的架构,结合了两者的优点。可以将湖仓一体视为直接建立在那个原始水库之上的图书馆。它将仓库级别的结构和管理功能(如原子性、一致性、隔离性、持久性(ACID)事务和数据版本控制)直接添加到了数据湖的低成本存储之上。
关键特征
- 数据湖存储:使用数据湖廉价、可扩展的对象存储来存储所有数据。
- 仓库功能:在数据湖存储之上添加了一个管理层,提供了传统上仅在数据仓库中找到的功能,例如:
- ACID 事务:确保数据一致性,即使有多个用户同时读写。
- 模式执行:在需要时定义和强制执行数据结构的能力。
- 性能优化:如缓存和索引等技术,使查询速度变快,类似于数据仓库。
- 直接访问:数据科学家和工程师可以直接处理原始数据文件进行机器学习,而 业务分析师 可以通过优化层使用 BI 工具查询相同的数据。
这消除了维护单独的数据仓库和数据湖的需要。它为你的所有数据需求创建了一个单一的事实来源。
回顾使用案例
- 在相同、一致的数据集上同时运行 BI 报告和高级机器学习模型
- 基于流式数据构建实时仪表板,同时这些数据也用于历史分析
- 通过简化在湖和仓库之间移动数据的复杂 ETL 管道来简化数据架构
理解数据网格(Data Mesh)
我们讨论了数据湖、数据仓库和湖仓一体;它们主要都是技术架构。它们回答的问题是:“我如何存储和处理我的数据?”
数据网格是不同的。它是一种社会技术架构。它回答的问题是:“在一个大型组织中,我如何组织我的团队和我的数据才能有效扩展?”
想象一个由一个庞大团队构建的庞大、单一的应用程序。它会变得缓慢、不稳定且难以管理。解决方案是将应用程序分解成由不同团队拥有的更小、独立的服务。数据网格将同一原则应用于数据。
数据网格不再由一个负责公司所有数据的中央数据团队(一个中央数据湖或仓库)来管理,而是将数据的所有权分配给最了解这些数据的域团队。
数据网格的四个支柱
数据网格建立在四个基本原则之上,它们是:
- 业务域(市场、销售、财务)对其数据拥有端到端的控制权。
- 数据集被视为具有清晰文档和质量标准的产品。
- 一个自助式数据平台,基础设施使域团队可以轻松管理和共享数据。
- 集中策略与分散执行相结合。
考察数据网格的示例
以一家大型电子商务公司为例。不再由一个中央数据团队处理所有数据:
- 市场域负责客户互动数据,提供干净、记录完善的数据集。
- 库存域负责产品和库存数据,作为可靠的产品提供。
- 履约域负责运输和物流数据。
- 所有域都使用共享的自助服务平台,但维护自己的数据管道。
比较数据网格和数据仓库
数据网格和数据仓库服务于不同的目的。数据仓库是一种技术;数据网格是一种组织框架。它们本质上并不互相排斥;你可以使用数据仓库、数据湖或湖仓一体作为底层技术,同时实施数据网格原则。
在以下情况下,数据网格效果更好:
- 你的组织有多个独立的业务域
- 中央数据团队成为瓶颈
- 你需要跨大型组织扩展数据工作
- 领域专家最了解他们的数据
数据仓库在以下情况下仍然更好:
- 集中报告和分析
- 具有强大中央数据治理的组织
- 没有多个不同领域的较小组织
回顾常见工具
数据网格平台包括用于数据发现、共享和治理的工具:Apache Atlas、DataHub、Amundsen,以及云提供商的数据网格解决方案。
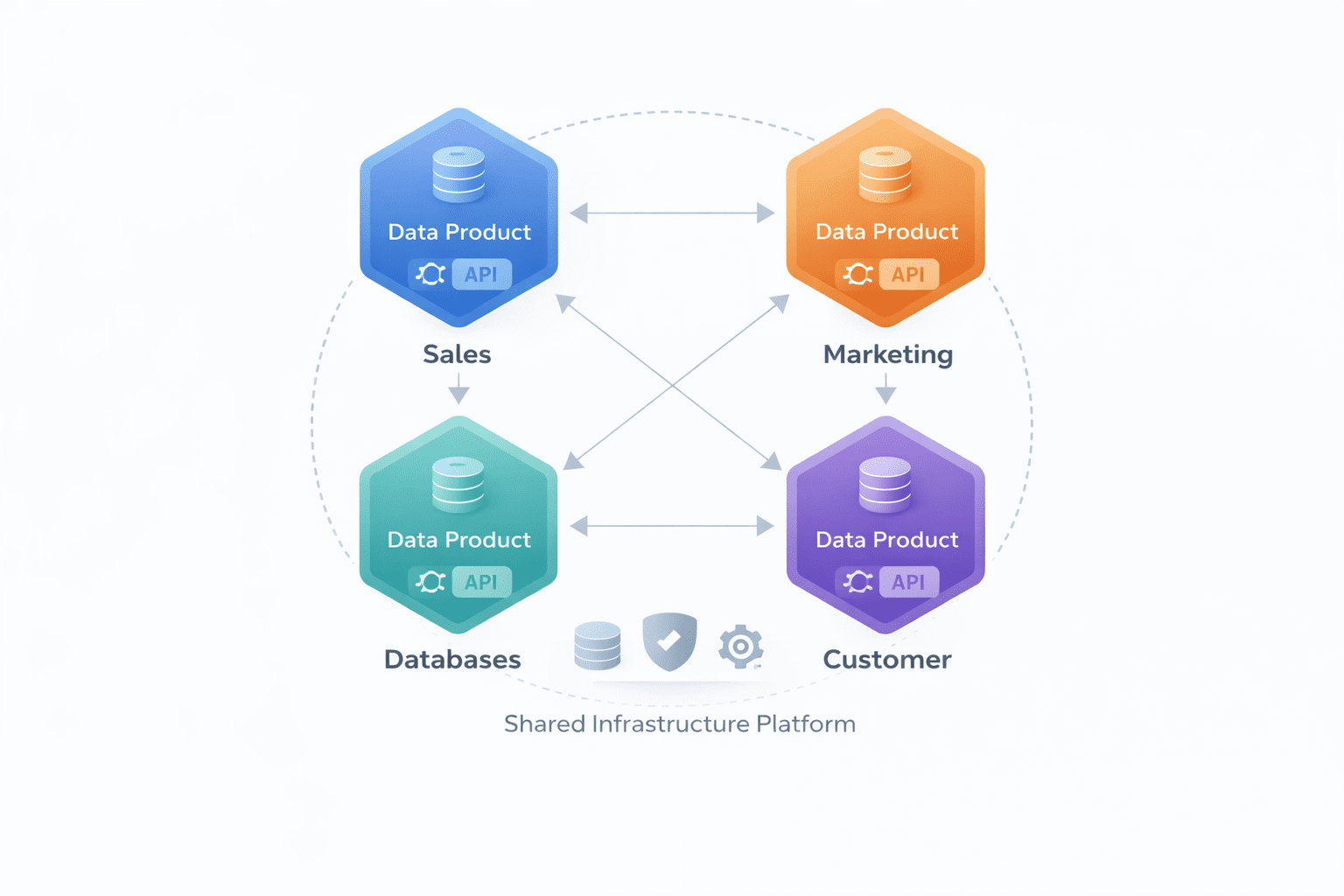
数据网格架构,展示了相互关联的域,每个域都拥有自己的数据产品,并拥有一个共享的基础设施平台 | Image by Author
数据网格的关键原则
- 数据由生成它的职能业务域拥有(例如,销售团队拥有销售数据,市场团队拥有营销数据)。他们有责任将自己的数据作为“数据产品”提供服务。
- 每个域团队都将其数据集视为产品,并充当其管家。这意味着数据必须干净、文档齐全、安全,并通过定义的接口(如 API)可访问。
- 一个中央平台团队提供工具和基础设施,例如“数据平面”,使域团队可以轻松创建、维护和共享其数据产品。这通常建立在湖仓一体架构之上。
- 治理不是自上而下的中央授权。相反,一个由来自不同域的领导组成的联合团队就必须遵循的全局标准(如安全、互操作性等)达成一致。
可以这样理解:你可以构建一个湖仓一体(技术),但要在庞大的公司中管理它而不产生混乱,你需要一个数据网格(组织模型)。
回顾使用案例
- 数以百计的团队在大型企业中,正努力从中央数据湖中查找和信任数据
- 希望减少中央数据工程团队瓶颈的组织
- 正在寻求在业务部门中培养数据所有权和协作文化的公司
显示多个域的图表 | Image by Author
为了总结这些架构之间的差异,这里有一个简单的比较表。
| 特性 | 数据仓库 | 数据湖 | 湖仓一体 | 数据网格 |
|---|---|---|---|---|
| 主要焦点 | 技术(存储) | 技术(存储) | 技术(存储 + 管理) | 组织(人员 + 流程) |
| 数据类型 | 仅结构化 | 结构化、半结构化、非结构化 | 结构化、半结构化、非结构化 | 所有类型,按域组织 |
| 模式(Schema) | 写入时模式(强制执行) | 读取时模式(灵活) | 支持两者 | 由域数据产品定义 |
| 主要用户 | 业务分析师 | 数据科学家、工程师 | 数据科学家、分析师和工程师 | 所有人员,跨域 |
| 核心目标 | 快速 BI 报告与性能 | 经济的存储与灵活性 | 单一事实来源,多功能性 | 去中心化所有权与扩展性 |
为你的项目选择正确的架构
那么,作为一个初级数据科学家,你该如何决定使用哪一个呢?答案在很大程度上取决于你组织的具体情况。
- 如果你在一家具有传统业务需求的小公司工作,你很可能会接触到数据仓库。你的重点将是运行 SQL 查询来生成报告给利益相关者。
- 如果你在一家处理多样化数据的科技公司工作,你可能会在数据湖或湖仓一体中工作。你将提取原始数据进行测试和构建模型特征,可能需要使用 Spark 或 Python 等工具进行处理。
- 如果你加入一家大型跨国公司,你可能会听到数据网格。在网格架构中,作为一名数据科学家,你将是来自其他域的数据产品的消费者(例如使用销售域提供的干净的 customer_360 数据产品),并可能成为自己数据产品的生产者(例如 model_predictions 数据产品)。
结论
在本文中,你了解到数据架构的世界并非要选出一个赢家。每种概念都在解决一个特定的问题。
- 数据仓库为业务报告提供了可靠性和性能
- 数据湖拥抱了大数据的数据多样性和体量
- 湖仓一体将两者融合,为所有数据工作负载创建了一个灵活而强大的基础
- 数据网格解决了在大型公司中扩展数据所有权的人员和组织挑战
在你开始数据科学之旅时,了解每种方法的优势和劣势将使你成为一个更有效、更全面的实践者。你将不仅知道如何构建模型,还知道在哪里找到正确的数据、如何存储你的输出,以及你的工作如何融入组织的整体数据战略。
Shittu Olumide 是一位软件工程师和技术作家,热衷于利用尖端技术来构建引人入胜的叙事,对细节有敏锐的洞察力,并擅长简化复杂的概念。你也可以在 Twitter 上找到 Shittu。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区