



📢 转载信息
原文作者:Prashant Patel, Ainesh Sootha, and Sandeep Akhouri
Amazon Bedrock Custom Model Import现已支持OpenAI具有开放权重的模型,包括参数量为200亿和1200亿的GPT-OSS变体。GPT-OSS模型提供了推理能力,并可与OpenAI聊天补全API配合使用。通过保持对OpenAI API的完全兼容性,组织可以将其现有应用程序迁移到AWS,从而获得企业级的安全性、扩展性和成本控制。
在本文中,我们将展示如何使用Amazon Bedrock自定义模型导入功能在Amazon Bedrock上部署GPT-OSS-20B模型,同时保持与当前应用程序的完全API兼容性。
Amazon Bedrock自定义模型导入概述
Amazon Bedrock自定义模型导入功能允许您将自定义模型引入到访问基础模型(FM)的同一无服务器环境中。您获得了一个统一的API来处理所有事务;您无需处理多个端点或管理单独的基础设施。
要使用此功能,请将模型文件上传到Amazon Simple Storage Service (Amazon S3),然后通过Amazon Bedrock控制台启动导入。AWS将处理繁重的工作,包括配置GPU、配置推理服务器以及根据需求自动扩展。您可以专注于您的应用程序,而AWS则负责管理基础设施。
GPT-OSS模型支持OpenAI聊天补全API,包括消息数组、角色定义(系统、用户或助手)以及带有令牌使用指标的标准响应结构。您可以将应用程序指向Amazon Bedrock端点,它们只需对代码库进行微小更改即可工作。
GPT-OSS模型概述
GPT-OSS模型是OpenAI自GPT-2以来发布的第一个开放权重语言模型,根据Apache 2.0许可证发布。您可以免费下载、修改和使用它们,包括用于商业应用。这些模型专注于推理、工具使用和高效部署。请根据您的需求选择合适的模型:
- GPT-OSS-20B (210亿参数) – 该模型最适合对速度和效率要求高的应用。尽管它有210亿参数,但每个token仅激活36亿参数,因此它可以在仅有16 GB内存的边缘设备上流畅运行。它具有24层、32个专家(每个token激活4个),以及128k的上下文窗口,其性能与OpenAI的o3-mini相当,同时可以本地部署以获得更快的响应时间。
- GPT-OSS-120B (1170亿参数) – 专为复杂的推理任务(如编码、数学和代理工具使用)而构建,每个token激活51亿参数。它具有36层、128个专家(每个token激活4个),以及128k的上下文窗口,性能与OpenAI的o4-mini相当,同时可以在单个80GB GPU上高效运行。
这两个模型都使用了专家混合(MoE)架构——模型的子集(专家)处理不同类型的任务,每个请求只激活最相关的专家。这种方法在保持计算成本可控的同时提供了强大的性能。
理解GPT-OSS模型格式
当您从Hugging Face下载GPT-OSS模型时,您会得到协同工作的几种文件类型:
- 权重文件 (.safetensors) – 实际的模型参数
- 配置文件 (config.json) – 定义模型如何工作的设置
- 分词器文件 – 处理文本
- 索引文件 (model.safetensors.index.json) – 将权重数据映射到特定文件
索引文件需要特定的结构才能与Amazon Bedrock配合使用。它必须在根级别包含一个metadata字段。这可以是空的 ({}),也可以包含模型总大小(文本模型必须小于200 GB)。
来自Hugging Face的模型有时会包含Amazon Bedrock不支持的额外元数据字段,例如total_parameters。在导入之前,您必须删除它们。正确的结构应如下所示:
{
"metadata": {},
"weight_map": {
"lm_head.weight": "model-00009-of-00009.safetensors",
...
}
}确保在启动Amazon S3上传之前排除metal目录。
解决方案概述
在本文中,我们将通过Amazon Bedrock自定义模型导入功能,介绍完整的部署流程。我们使用Tonic/med-gpt-oss-20b模型,这是OpenAI GPT-OSS-20B的微调版本,专门针对医疗推理和指令遵循进行了优化。
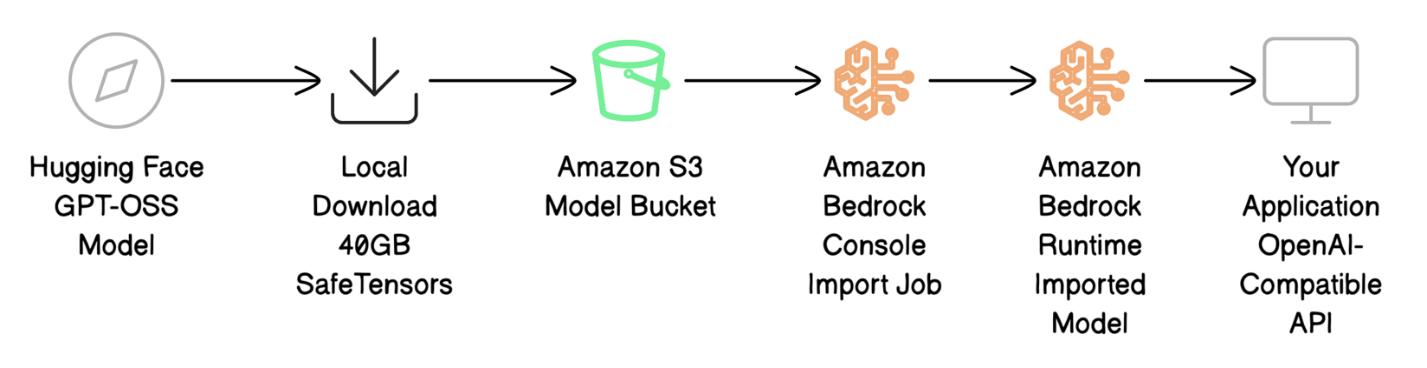
部署过程包括四个主要步骤:
- 从Hugging Face下载模型文件并准备用于AWS。
- 将模型文件上传到Amazon S3。
- 使用Amazon Bedrock自定义模型导入将您的模型引入Amazon Bedrock。
- 使用OpenAI兼容的API调用来调用您的模型以测试部署。
下图说明了部署工作流程。
先决条件
在开始部署GPT-OSS模型之前,请确保您具备以下条件:
- 具有适当权限的活动AWS账户
- AWS Identity and Access Management (IAM) 权限,包括:
- 在Amazon Bedrock中创建模型导入作业
- 向Amazon S3上传文件
- 部署后调用模型
- 使用自定义模型导入服务角色
- 您目标AWS区域中的一个S3存储桶
- 大约40 GB的本地磁盘空间用于模型下载
- 对美国东部 1 (弗吉尼亚北部) 区域的访问权限(GPT-OSS基于自定义模型的必需区域)
- 已安装AWS命令行工具 (AWS CLI) 2.x版本
- Hugging Face CLI(使用
pip install -U "huggingface_hub[cli]"安装)
下载和准备模型文件
要使用Hugging Face Hub库下载GPT-OSS模型并启用快速传输,请使用以下代码:
import os
os.environ['HF_HUB_ENABLE_HF_TRANSFER'] = '1'
from huggingface_hub import snapshot_download
local_dir = snapshot_download(
repo_id="Tonic/med-gpt-oss-20b",
local_dir="./med-gpt-oss-20b",
)
print(f"Download complete! Model saved to: {local_dir}")下载完成后(40 GB需要10-20分钟),验证model.safetensors.index.json文件的结构。如有必要,请编辑它以确保metadata字段存在(可以为空):
{
"metadata": {},
"weight_map": {
"lm_head.weight": "model-00009-of-00009.safetensors",
...
}
}
ec2-user@ip-XYZ ~/gptoss/med-gpt-oss-20b ls -lah
total 39G
drwxr-xr-x. 3 ec2-user ec2-user 16K Nov 10 19:38 .
drwxr-xr-x. 3 ec2-user ec2-user 44 Nov 10 21:31 ..
drwxr-xr-x. 3 ec2-user ec2-user 25 Nov 10 18:57 .cache
-rw-r--r--. 1 ec2-user ec2-user 17K Nov 10 18:57 chat_template.jinja
-rw-r--r--. 1 ec2-user ec2-user 1.6K Nov 10 18:57 config.json
-rw-r--r--. 1 ec2-user ec2-user 160 Nov 10 18:57 generation_config.json
-rw-r--r--. 1 ec2-user ec2-user 1.6K Nov 10 18:57 .gitattributes
-rw-r--r--. 1 ec2-user ec2-user 4.2G Nov 10 18:57 model-00001-of-00009.safetensors
-rw-r--r--. 1 ec2-user ec2-user 4.6G Nov 10 18:57 model-00002-of-00009.safetensors
-rw-r--r--. 1 ec2-user ec2-user 4.6G Nov 10 18:57 model-00003-of-00009.safetensors
-rw-r--r--. 1 ec2-user ec2-user 4.6G Nov 10 18:57 model-00004-of-00009.safetensors
-rw-r--r--. 1 ec2-user ec2-user 4.6G Nov 10 18:57 model-00005-of-00009.safetensors
-rw-r--r--. 1 ec2-user ec2-user 4.6G Nov 10 18:57 model-00006-of-00009.safetensors
-rw-r--r--. 1 ec2-user ec2-user 4.6G Nov 10 18:57 model-00007-of-00009.safetensors
-rw-r--r--. 1 ec2-user ec2-user 4.6G Nov 10 18:57 model-00008-of-00009.safetensors
-rw-r--r--. 1 ec2-user ec2-user 2.6G Nov 10 18:57 model-00009-of-00009.safetensors
-rw-r--r--. 1 ec2-user ec2-user 33K Nov 10 19:38 model.safetensors.index.json
-rw-r--r--. 1 ec2-user ec2-user 5.4K Nov 10 18:57 README.md
-rw-r--r--. 1 ec2-user ec2-user 440 Nov 10 18:57 special_tokens_map.json
-rw-r--r--. 1 ec2-user ec2-user 4.2K Nov 10 18:57 tokenizer_config.json
-rw-r--r--. 1 ec2-user ec2-user 27M Nov 10 18:57 tokenizer.json将模型文件上传到Amazon S3
在导入模型之前,必须将模型文件存储在Amazon Bedrock可以访问的S3存储桶中。请完成以下步骤:
- 在Amazon S3控制台中,在导航窗格中选择Buckets。
- 创建新存储桶或打开现有存储桶。
- 上传您的模型文件。
或者,使用AWS CLI将文件上传到目标Amazon Bedrock区域的S3存储桶中:
aws s3 sync ./med-gpt-oss-20b/ s3://amzn-s3-demo-bucket/med-gpt-oss-20b/40 GB的上传通常需要5到10分钟才能完成。验证文件是否已上传:
aws s3 ls s3://amzn-s3-demo-bucket/med-gpt-oss-20b/ --human-readable以下屏幕截图显示了S3存储桶中文件的示例。

记下您的S3 URI(例如,s3://amzn-s3-demo-bucket/med-gpt-oss-20b/)以供导入作业使用。
输出文件使用S3存储桶的加密配置进行加密。根据S3存储桶的设置方式,这些文件将使用SSE-S3服务器端加密或AWS密钥管理服务 (AWS KMS) SSE-KMS加密进行加密。
使用Amazon Bedrock自定义导入模型
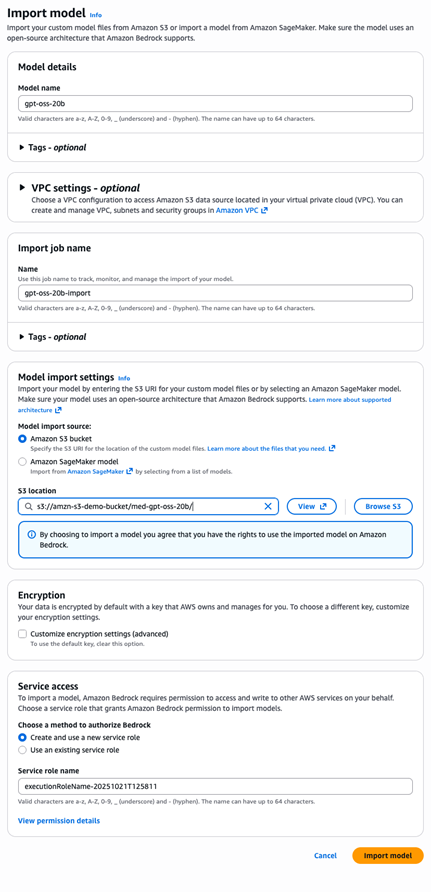
现在您的模型文件已上传到Amazon S3,您可以将模型导入Amazon Bedrock,在那里它将被处理并可用于推理。完成以下步骤:
- 在Amazon Bedrock控制台中,在导航窗格中选择Imported models。
- 选择Import model。
- 对于Model name,输入
gpt-oss-20b。 - 对于Model import source,选择Amazon S3 bucket。
- 对于S3 location,输入
s3://amzn-s3-demo-bucket/med-gpt-oss-20b/。 - 对于Service access,选择Create and use a new service role。Amazon Bedrock控制台会自动生成一个具有正确信任关系和Amazon S3读取权限的角色。
- 选择Import model开始导入作业。
要使用AWS CLI,请使用以下代码:
aws bedrock create-model-import-job \
--job-name "gpt-oss-20b-import-$(date +%Y%m%d-%H%M%S)" \
--imported-model-name "gpt-oss-20b" \
--role-arn "arn:aws:iam::YOUR-ACCOUNT-ID:role/YOUR-ROLE-NAME" \\n --model-data-source "s3DataSource={s3Uri=s3://amzn-s3-demo-bucket/med-gpt-oss-20b/}"对于20B参数模型,模型导入通常在10到15分钟内完成。您可以在Amazon Bedrock控制台或使用AWS CLI监控进度。完成后,记下importedModelArn,您将用它来调用模型。
使用OpenAI兼容的API调用模型
模型导入完成后,您可以使用熟悉的OpenAI聊天补全API格式来测试它,以验证它是否按预期工作:
- 创建一个名为
test-request.json的文件,其中包含以下内容:
{
"messages": [
{
"role": "system",
"content": "You are a helpful AI assistant."
},
{
"role": "user",
"content": "What are the common symptoms of Type 2 Diabetes?"
}
],
"max_tokens": 500,
"temperature": 0.7
}- 使用AWS CLI将请求发送到导入的模型端点:
aws bedrock-runtime invoke-model \
--model-id "arn:aws:bedrock:us-east-1:YOUR-ACCOUNT-ID:imported-model/MODEL-ID" \
--body file://test-request.json \
--cli-binary-format raw-in-base64-out
response.json
cat response.json | jq '.'响应以标准的OpenAI格式返回:
{
"id": "chatcmpl-f06adcc78daa49ce9dd2c58f616bad0c",
"object": "chat.completion",
"created": 1762807959,
"model": "YOUR-ACCOUNT-ID-MODEL-ID",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Type 2 Diabetes often presents with a range of symptoms...",
"refusal": null,
"function_call": null,
"tool_calls": []
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 98,
"completion_tokens": 499,
"total_tokens": 597
}
}响应结构与OpenAI的格式完全匹配——choices包含响应,usage提供令牌计数,finish_reason指示完成状态。现有的OpenAI响应解析代码无需修改即可工作。
该模型的一个强大优势是其透明度。reasoning_content字段为我们提供了有关模型在生成最终响应之前的内部推理过程的信息。这种透明度是闭源API所不具备的。
清理
完成后,清理资源以避免不必要的费用:
aws bedrock delete-imported-model --model-identifier "arn:aws:bedrock:us-east-1:ACCOUNT:imported-model/MODEL-ID" aws s3 rm s3://amzn-s3-demo-bucket/med-gpt-oss-20b/ --recursive如果您不再需要IAM角色,请使用IAM控制台将其删除。
从OpenAI迁移到Amazon Bedrock
从OpenAI迁移只需要最少的代码更改——只有调用方法发生变化,而消息结构保持不变。
对于OpenAI,使用以下代码:
import openai
response = openai.ChatCompletion.create(model="....", messages=[...])对于Amazon Bedrock,使用以下代码:
import boto3, json
bedrock = boto3.client('bedrock-runtime')
response = bedrock.invoke_model(
modelId='arn:aws:bedrock:us-east-1:ACCOUNT:imported-model/MODEL-ID',
body=json.dumps({"messages": [...]})
)迁移是直接的,您将获得可预测的成本、更好的数据隐私以及根据您的特定需求微调模型的潜力。
最佳实践
请考虑以下最佳实践:
- 文件验证 – 在上传之前,验证
model.safetensors.index.json具有正确的元数据结构,引用的safetensors文件存在,并且分词器受支持。本地验证可以节省导入重试时间。 - 安全性 – 在Amazon Bedrock控制台上,自动创建具有最小权限的IAM角色。对于多个模型,使用单独的S3前缀来保持隔离。
- 版本控制 – 使用描述性的S3路径(
gpt-oss-20b-v1.0/)或带日期的导入作业名称来跟踪部署。
定价
对于导入Amazon Bedrock的自定义模型的推理运行,您需要付费。有关更多详细信息,请参阅计算运行自定义模型的成本和Amazon Bedrock定价。
结论
在本文中,我们展示了如何使用自定义模型导入功能在Amazon Bedrock上部署GPT-OSS模型,同时保持对OpenAI API的完全兼容性。现在,您只需最少的代码更改即可将现有应用程序迁移到AWS,并获得企业级优势,包括完全的模型控制、微调能力、可预测的定价和增强的数据隐私。
准备开始了吗?以下是您的后续步骤:
- 选择您的模型大小 – 从20B模型开始以获得更快的响应,或使用120B变体处理复杂的推理任务
- 设置您的环境 – 确保您具有所需的AWS权限和S3存储桶访问权限
- 尝试Amazon Bedrock控制台 – 使用Amazon Bedrock控制台导入您的第一个GPT-OSS模型
- 探索高级功能 – 在基本设置正常工作后,考虑使用专有数据进行微调
Amazon Bedrock自定义模型导入功能在多个区域可用,并将在更多区域扩展支持。请参阅Amazon Bedrock中的按AWS区域划分的功能支持以获取最新信息。GPT-OSS模型最初将在美国东部-1(弗吉尼亚北部)区域提供。
有任何疑问或反馈?请通过AWS re:Post for Amazon Bedrock联系我们的团队——我们期待听到您的使用体验。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
关于作者
 Prashant Patel 是AWS Bedrock的高级软件开发工程师。他对为企业应用扩展大型语言模型充满热情。在加入AWS之前,他曾在IBM从事在Kubernetes上生产化大规模AI/ML工作负载的工作。Prashant拥有纽约大学坦登工程学院的硕士学位。工作之余,他喜欢旅行和与他的狗玩耍。
Prashant Patel 是AWS Bedrock的高级软件开发工程师。他对为企业应用扩展大型语言模型充满热情。在加入AWS之前,他曾在IBM从事在Kubernetes上生产化大规模AI/ML工作负载的工作。Prashant拥有纽约大学坦登工程学院的硕士学位。工作之余,他喜欢旅行和与他的狗玩耍。
 Ainesh Sootha 是AWS的软件开发工程师。他对性能优化和为企业应用扩展大型语言模型充满热情。在加入AWS Bedrock之前,他曾从事亚马逊“Just Walk Out”技术的身份验证系统工作。Ainesh拥有普渡大学计算机工程学士学位。工作之余,他喜欢弹吉他和读书。
Ainesh Sootha 是AWS的软件开发工程师。他对性能优化和为企业应用扩展大型语言模型充满热情。在加入AWS Bedrock之前,他曾从事亚马逊“Just Walk Out”技术的身份验证系统工作。Ainesh拥有普渡大学计算机工程学士学位。工作之余,他喜欢弹吉他和读书。
 Sandeep Akhouri 是一位经验丰富的产品和上市 (GTM) 领导者,在产品管理、工程和上市方面拥有超过20年的经验。在他目前的职位之前,Sandeep曾在Splunk、KX Systems、Hazelcast和Software AG等领先技术公司领导构建AI/ML产品的产品管理工作。他对代理AI、模型定制以及利用生成式AI推动现实世界的影响充满热情。
Sandeep Akhouri 是一位经验丰富的产品和上市 (GTM) 领导者,在产品管理、工程和上市方面拥有超过20年的经验。在他目前的职位之前,Sandeep曾在Splunk、KX Systems、Hazelcast和Software AG等领先技术公司领导构建AI/ML产品的产品管理工作。他对代理AI、模型定制以及利用生成式AI推动现实世界的影响充满热情。
评论区