



📢 转载信息
原文作者:Mike Koźmiński, Magdalena Gargas, Luca Perrozzi, and Simone Pomata
本文由 Beekeeper 的 Mike Koźmiński 撰写。
大型语言模型(LLM)正在快速发展,这使得组织难以针对每种特定用例选择最佳模型、优化提示词以兼顾质量和成本、适应不断变化的 বলল模型能力,并为不同用户提供个性化响应。
选择“正确”的 LLM 和提示词并非一劳永逸的决定——随着模型、价格和需求的改变,它会不断变化。系统提示词正变得越来越大(例如 Anthropic 的系统提示词)且越来越复杂。许多中型公司没有资源来快速评估和改进它们。为了解决这个问题,Beekeeper 构建了一个由 Amazon Bedrock 驱动的系统,该系统持续评估模型+提示词的候选者,根据实时排行榜进行排名,并将每个请求路由到当前该用例的最佳选择。
Beekeeper:连接和赋能一线员工
Beekeeper 提供了一个专为一线员工运营设计的全面数字化工作场所系统。该公司提供了一种移动优先的通信和生产力解决方案,连接非桌面员工彼此和总部,使组织能够简化运营、提高员工参与度和高效管理任务。其系统具有与现有业务系统(人力资源、排班、薪资)的强大集成能力,目标客户是拥有大量非桌面员工的行业,如酒店、制造、零售、医疗保健和交通运输。其核心在于,Beekeeper 通过提供易于访问的数字工具来增强沟通、运营效率和员工留存率,从而解决了传统上一线员工与组织之间的脱节问题,所有这些都通过基于云的 SaaS 系统、移动应用程序、管理仪表板和企业级安全功能交付。
Beekeeper 的解决方案:一个动态评估系统
Beekeeper 通过一个自动化的系统解决了这一挑战,该系统持续测试不同的模型和提示词组合,根据质量、成本和速度对选项进行排名,纳入用户反馈以个性化响应,并自动将请求路由到当前最佳选项。质量通过一小批合成测试集进行评分,并通过用户反馈(点赞/点踩和评论)在生产环境中进行验证。通过整合提示词变异,Beekeeper 创建了一个随时间演进的有机系统。结果是一个不断优化的设置,平衡了质量、延迟和成本,并在环境变化时自动适应。
真实世界案例:聊天摘要
Beekeeper 的“一线成功平台”(Frontline Success Platform)统一了跨行业桌面外员工的沟通。其 LLM 系统的实际应用之一是聊天摘要。当用户返回工作岗位时,他们可能会发现有很多未读消息——无需阅读所有内容,他们可以请求摘要。系统会生成一个简洁的概述,其中包含根据用户需求量身定制的行动项。然后,用户可以提供反馈以改进未来的摘要。这个看似简单的功能背后依赖于复杂的技术。系统必须理解对话上下文、识别要点、识别行动项,并简洁地呈现信息——同时适应用户偏好。

解决方案概述
Beekeeper 的解决方案主要包括两个阶段:构建基线排行榜和利用用户反馈进行个性化。
该系统使用了多个 AWS 组件,包括用于调度的 Amazon EventBridge、用于编排的 Amazon Elastic Kubernetes Service (EKS)、用于评估功能的 AWS Lambda、用于数据存储的 Amazon RDS,以及用于人工验证的 Amazon Mechanical Turk。
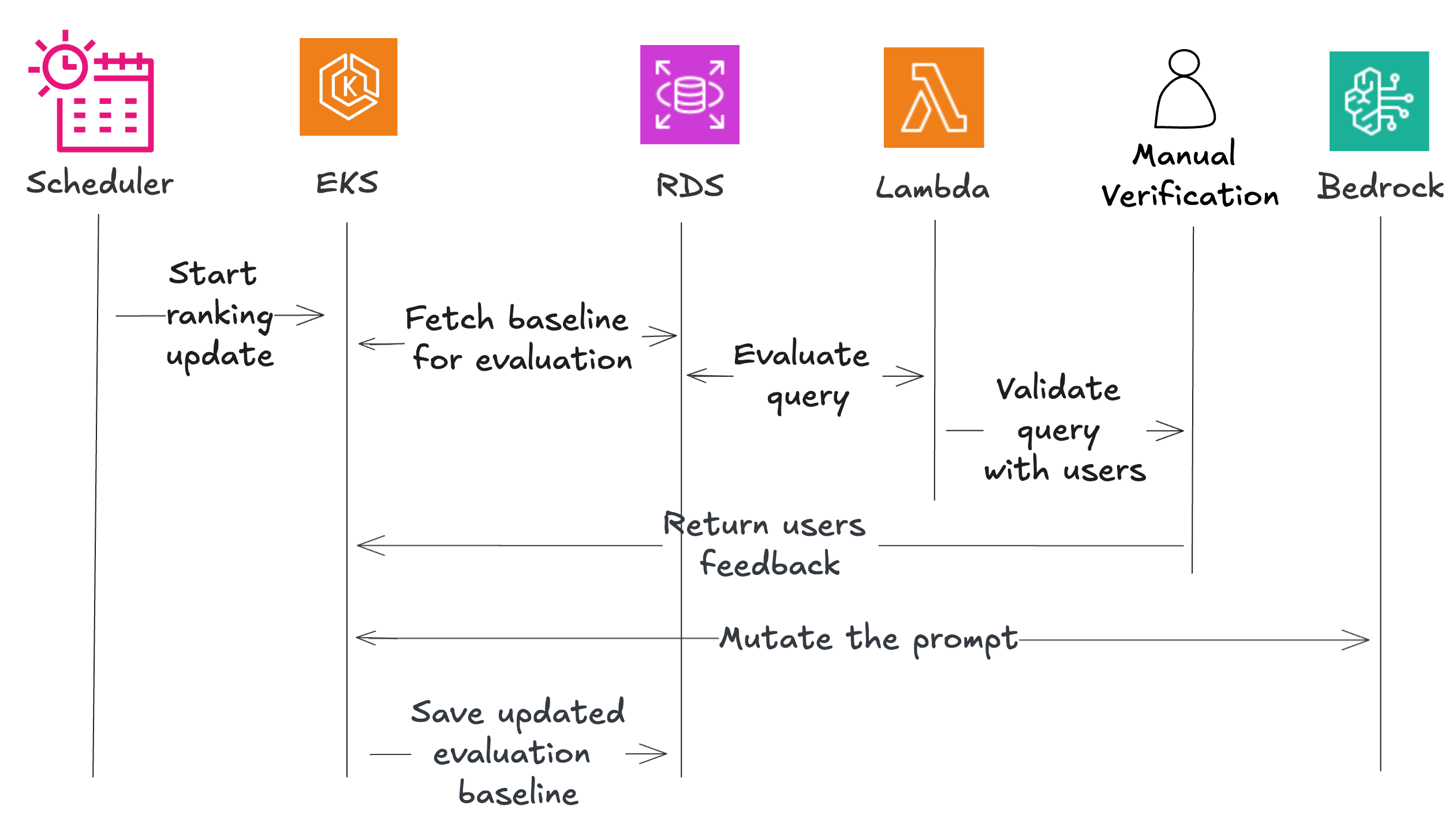
工作流程始于一个合成排名创建器,用于建立基线性能。调度器触发协调器,协调器获取测试数据并将其发送给评估器。这些评估器测试每个模型/提示词对并返回结果,其中一部分发送给人工验证。系统会变异有希望的提示词以创建变体,再次评估这些变体,并保存表现最佳的。当用户反馈到达时,系统通过第二阶段将其纳入。协调器获取排序后的模型/提示词对,并将它们与用户反馈一起发送给变异器,变异器返回个性化的提示词。漂移检测器确保这些个性化版本不会偏离质量标准太远,经验证的提示词会为特定用户保存下来。
构建基线排行榜
为了启动优化之旅,Beekeeper 的工程师选择了各种模型,并为它们提供了特定领域的、由人工编写的提示词。技术团队使用 LLM 生成的示例测试了这些提示词,以确保它们没有错误。强大的基线在这里至关重要。这个基础有助于他们在纳入真实用户反馈时完善方法。
在接下来的部分,我们将深入探讨他们的成功指标,这些指标指导了他们对提示词的改进,并有助于创造最佳的用户体验。
基线评估标准
模型/提示词对生成的摘要质量使用定量和定性指标来衡量,包括以下内容:
- 压缩率 – 衡量摘要长度与原始文本的比例,奖励符合目标长度的摘要,并惩罚过长的文本。
- 行动项的出现 – 确保用户特定的行动项得到明确识别。
- 缺乏幻觉 – 验证事实准确性和一致性。
- 向量比较 – 评估与人工生成的完美结果的语义相似性。
在接下来的部分,我们将逐一介绍每个评估标准及其实现方法。
压缩率
压缩率评估摘要文本与原始文本的长度比较,以及其对目标长度的遵守情况(它奖励与目标比率接近的压缩率,并惩罚偏离目标长度的文本)。相应的分数(0到100之间)通过以下 Python 代码以编程方式计算:
def calculate_compression_score(original_text, compressed_text):
max_length = 650
target_ratio = 1 / 5
margin = 0.05
max_penalty_points = 100 # 如果文本过长,最大扣分
original_length = len(original_text)
compressed_length = len(compressed_text)
# 计算超出最大长度的惩罚
excess_length = max(0, original_length - max_length)
penalty = (excess_length / original_length) * max_penalty_points
# 计算实际压缩率
actual_ratio = compressed_length / original_length
lower_bound = target_ratio * (1 - margin)
upper_bound = target_ratio * (1 + margin)
# 根据压缩率计算基础分数
if actual_ratio < lower_bound:
base_score = 100 * (actual_ratio / lower_bound)
elif actual_ratio > upper_bound:
base_score = 100 * (upper_bound / actual_ratio)
else:
base_score = 100
# 将惩罚应用于基础分数
score = base_score - penalty
# 确保分数不低于 0
score = max(0, score)
return round(score, 2)与用户相关的行动项的出现
为了检查摘要是否包含与用户相关的所有行动项,Beekeeper 依赖于与地面实况(ground truth)的比较。对于地面实况比较,预期的输出格式要求一个标记为“Action items:”的部分,后跟项目符号列表,这使用正则表达式来提取行动项列表,如下面的 Python 代码所示:
import re
def extract_action_items(text):
action_section = re.search(r'Action items:(.*?)(?=\n\n|\Z)', text, re.DOTALL)
if action_section:
action_content = action_section.group(1).strip()
action_items = re.findall(r'^\s*-\s*(.+)$', action_content, re.MULTILINE)
return action_items
else:
return []他们加入了这个额外的提取步骤,以确保数据格式化方式是 LLM 易于处理的。提取的列表会发送给 LLM,并附带检查其是否正确的请求。每项正确分配的行动项得分为 +1,如果出现误报则为 -1。之后,分数会被标准化,以避免因摘要包含的行动项数量不同而受到不公平的惩罚/奖励。
缺乏幻觉
为了评估幻觉,Beekeeper 使用两种方法:跨 LLM 评估和人工验证。

在跨 LLM 评估中,由 LLM A(例如 Mistral Large)创建的摘要与提示词和初始输入一起传递给评估组件。评估器将此文本提交给 LLM B(例如 Anthropic 的 Claude),询问摘要中的事实是否与原始上下文匹配。此评估使用了不同系列的 LLM。通过 Amazon Bedrock 的Converse API,这项工作变得特别简单——用户可以通过更改模型标识符字符串来选择不同的 LLM。
另一个重点是 Beekeeper 在一小部分评估中进行的人工验证,以避免出现双重幻觉的情况。如果未检测到幻觉,则得分为 1;如果检测到任何幻觉,则得分为 -1。对于整个管道,他们使用相同的 7% 人工评估的启发式方法(更多细节将在本文后面讨论)。
向量比较
作为一种额外的评估方法,对于具有可用地面实况信息的数据,会使用语义相似性。嵌入模型从 MTEB Leaderboard(嵌入模型的全能多任务和多语言比较)中选择,考虑到大的向量维度以最大化存储在向量中的信息量。Beekeeper 的基线使用了 Qwen3,这是一种提供 4096 维度并支持 16 位量化的模型,可实现快速计算。其他嵌入模型也直接从 Amazon Bedrock 使用。在计算出地面实况答案和给定模型/提示词对生成的答案的嵌入向量后,使用余弦相似度计算相似度,如下面的 Python 代码所示:
from sklearn.metrics.pairwise import cosine_similarity
cosine_similarity(synthetic_summary_embed, generated_summary_embed)评估基线
对每个模型/提示词对的评估基线是通过收集一组固定、预定义查询的生成输出来完成的,这些查询手动注释了包含“真实答案”(在本例中为内部和公共数据集中理想的摘要)的地面实况输出。如前所述,该集合是从公共数据集以及更好地代表客户领域的精心制作的示例中创建的。分数根据上述指标(压缩率、缺乏幻觉、行动项的出现和向量比较)自动评估,以构建排行榜的基线版本。
人工评估
为了进行额外验证,Beekeeper 使用 Amazon Mechanical Turk 手动审查了科学确定的评估样本。样本量是使用Cochran 公式计算的,以支持统计显著性。
Amazon Mechanical Turk 使企业能够利用人类智能来完成计算机无法有效执行的任务。这个众包市场将用户与全球的按需劳动力联系起来,以完成数据标记、内容审核和研究验证等微任务——有助于在不牺牲质量或增加开销的情况下扩大运营规模。如前所述,Beekeeper 利用人工反馈来验证基于 LLM 的自动评分系统是否正常工作。根据他们先前的假设,他们知道应该将多少百分比的响应归类为包含幻觉。如果人工验证检测到的数量与他们的估计偏差超过两个百分点,他们就知道自动化流程无法正常工作并需要修订。现在 Beekeeper 已经建立了基线,他们可以为客户提供最佳结果。通过不断更新模型,他们可以以自动化的方式带来新的价值。每当他们的工程师对新的提示词优化有想法时,他们可以使用基线结果来让管道评估它与以前的结果相比如何。Beekeeper 可以更进一步,嵌入用户反馈,从而实现更个性化的结果。然而,他们不希望用户反馈通过提示词注入完全改变其模型的行为。在下一节中,我们将研究 Beekeeper 管道中有机地将用户偏好嵌入到响应中而不影响其他用户的部分。
用户反馈评估
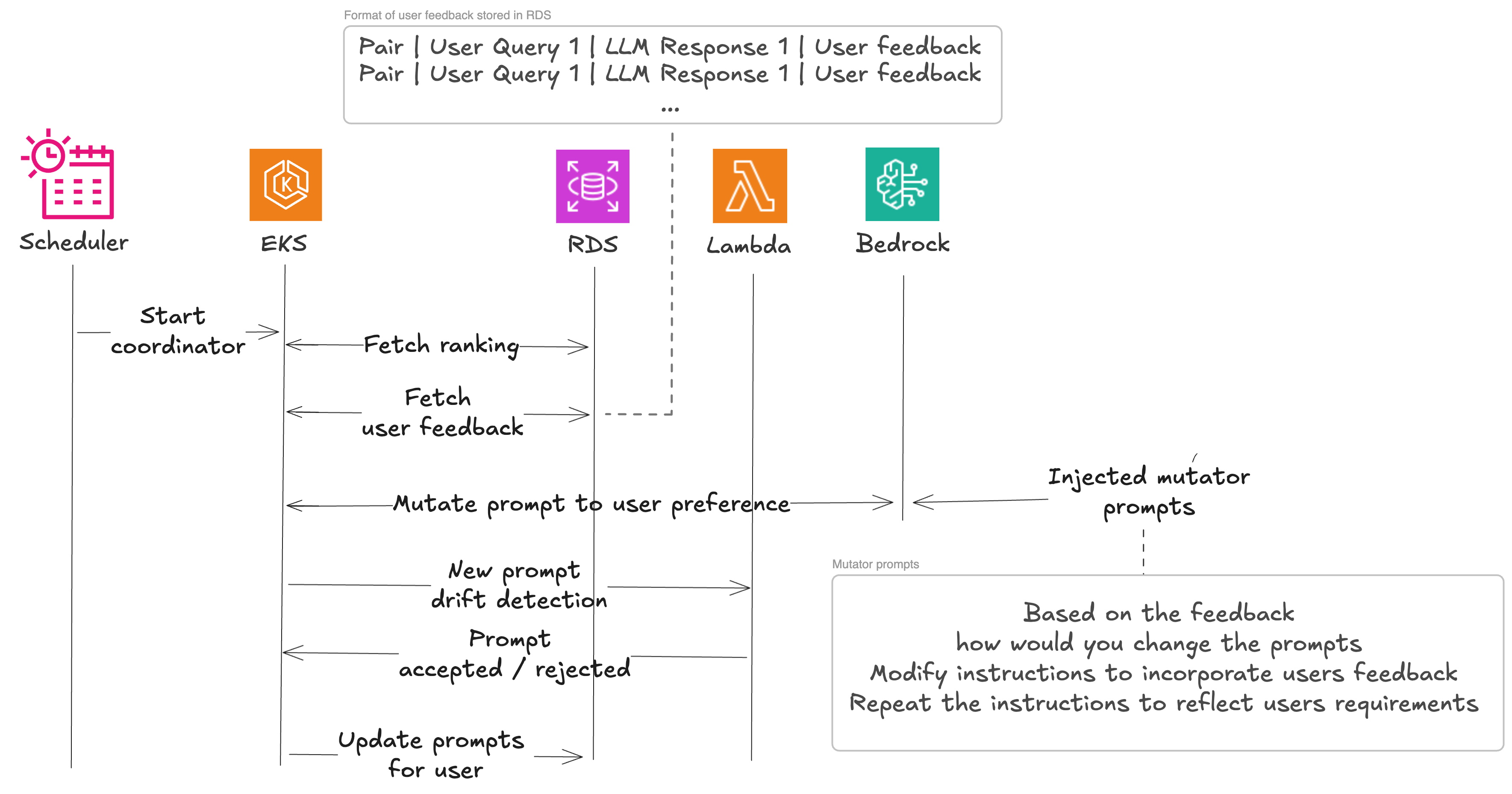
在 Beekeeper 使用地面实况数据集建立基线后,他们可以开始纳入人工反馈。这按照与先前描述的幻觉检测过程相同的原则运作。用户反馈与输入和 LLM 响应一起被收集。他们以以下格式向 LLM 提出问题:
You are given a task to identify if the hypothesis is in agreement with the context below. You will only use the contents of the context and not rely on external knowledge.
Answer with yes/no."context": {{input}} "summary": {{output}} "hypothesis": {{ statement }} "agreement":他们使用这个来检查在提示词-模型对更新后所提供的反馈是否仍然适用。这作为纳入用户反馈的基线。他们现在已准备好开始变异提示词。这样做是为了避免反馈被多次应用。如果模型更改或变异已经解决了问题,则无需再次应用。
变异过程包括在提示词变异后重新评估用户生成的数据集,直到输出结合了用户反馈,然后我们使用基线来理解差异,并在它们破坏模型工作时丢弃更改。
在基线评估中选出的四个表现最佳的模型/提示词对(用于变异提示词)将通过提示词变异过程进一步处理,以检查结果的残余改进。在与用户反馈结合使用时,即使提示词的微小修改也可能导致截然不同的结果,因此在环境中进行此操作至关重要。
初始提示词会通过提示词变异、收到的用户反馈、一种思维方式(一种指导 LLM 如何处理变异任务的具体认知方法,如“使其更具创意”或“逐步思考”),以及用户上下文进行丰富,然后发送给 LLM 以生成变异提示词。变异提示词被添加到列表中,进行评估,并将相应的分数纳入排行榜。变异提示词也可以包含用户反馈(如果存在)。
生成的变异提示词示例包括:
“添加提示词以帮助 LLM 解决此问题:” “修改指令使其更简单:” “用另一种方式重复该指令:” “你会给别人什么额外的指示来将此反馈 {feedback} 纳入该指令中:”解决方案示例
基线评估过程从八对提示词和相关模型开始(Amazon Nova、Anthropic Claude 4 Sonnet、Meta Llama 3 和 Mistral 8x7B)。Beekeeper 通常先使用四个基础提示词和两个模型。这些提示词会用于所有模型,但结果会以提示词-模型对的形式考虑。模型会在新版本通过 Amazon Bedrock 可用时自动更新。
Beekeeper 首先评估现有的八对:
- 每次评估需要为每对生成 20 个摘要(8 x 20 = 160)
- 每个摘要由三个静态检查和两个 LLM 检查(160 x 2 = 320)
总共,这会产生 480 次 LLM 调用。比较分数,生成排行榜,并选择两个提示词-模型对。使用用户反馈对这两个提示词进行变异,创建 10 个新提示词,再次进行评估,生成 600 次 LLM 调用(10 x 20 + 10 x 20 x 2 = 600)。
此过程可以运行 n 次以执行更多创意变异;Beekeeper 通常执行两个周期。
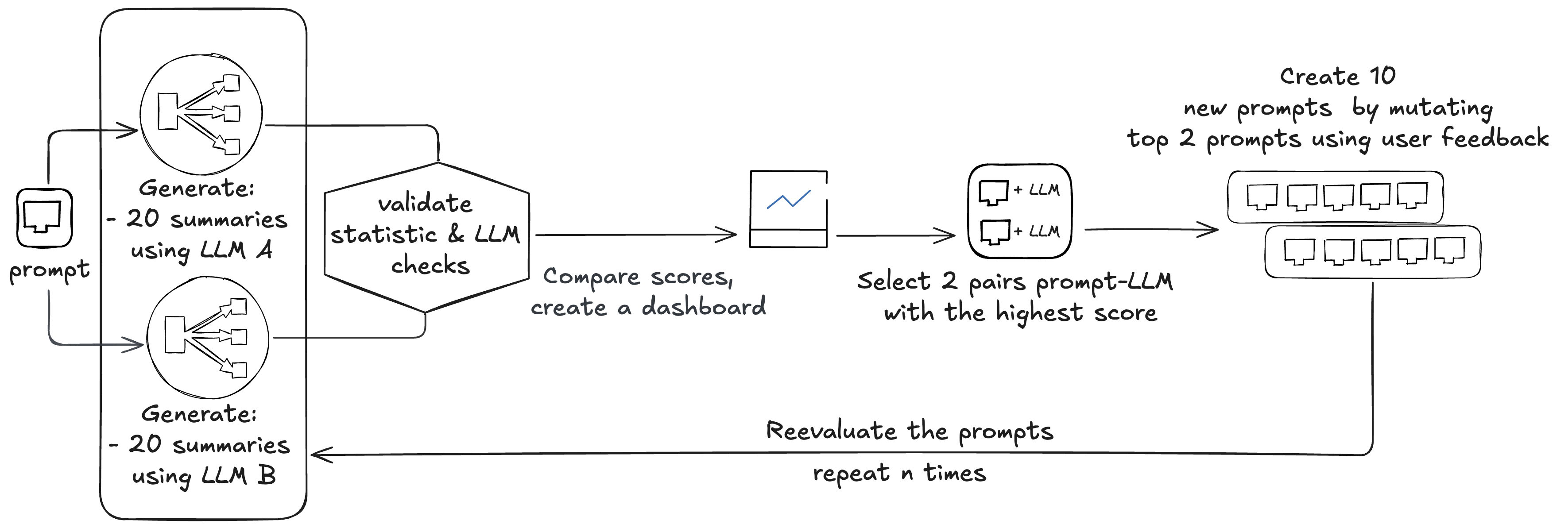
总而言之,这项工作对(8 + 10 + 10)x 2 个模型/提示词对进行了测试。整个过程平均需要大约 8,352,000 个输入 token 和大约 1,620,000 个输出 token,成本约为 48 美元。新选择的模型/提示词对以 1: 50%、2: 30% 和 3: 20% 的比例用于生产。在部署新的模型/提示词对后,Beekeeper 会收集用户反馈。此反馈用于为变异器提供输入,以创建三个新的提示词。这些提示词会经过漂移检测,与基线进行比较。总共,它们会产生四次 LLM 调用,成本约为 4,800 个输入 token 和 500 个输出 token。
优势
Beekeeper 解决方案的关键优势在于其快速演进并适应用户需求的能力。通过这种方法,他们可以对哪些模型/提示词对将是每项任务的最佳候选者做出初步估计,同时控制成本和结果质量。通过将合成数据和用户反馈的好处结合起来,该解决方案甚至适用于规模较小的工程团队。Beekeeper 不关注通用提示词,而是优先考虑针对每个租户的独特需求来定制提示词改进过程。通过这样做,他们可以完善提示词,使其高度相关且对用户友好。这种方法使用户能够开发自己的风格,从而在他们提供反馈并看到其影响时增强他们的体验。他们观察到的一个副作用是,某些人群偏好不同的沟通风格。通过将这些结果映射到客户交互,他们旨在呈现更量身定制的体验。这确保了一个用户的反馈不会影响另一个用户。他们的初步结果表明,按租户汇总时,响应的评分提高了 13%–24%。总之,所提出的解决方案提供了若干显著的好处。它通过自动化 LLM 和提示词选择过程减少了人工劳动,缩短了反馈周期,实现了用户或租户特定的改进,并提供了以与以前模型相同的方式无缝集成和估算新模型性能的能力。
结论
Beekeeper 的自动化排行榜方法和用于动态 LLM 及提示词对选择的人工反馈循环系统,解决了组织在快速发展的语言模型领域中面临的关键挑战。通过持续评估和优化质量、大小、速度和成本,该解决方案可帮助客户为其特定用例使用性能最佳的模型/提示词组合。展望未来,Beekeeper 计划进一步完善和扩展该系统的功能,纳入更先进的提示工程和评估技术。此外,该团队正在探索赋予用户开发自己定制提示词的方法,以培养更具个性化和吸引力的体验。如果您的组织正在探索优化 LLM 选择和提示工程的方法,则无需从头开始。使用 Amazon Bedrock 等 AWS 服务进行模型访问、使用 AWS Lambda 进行轻量级评估、使用 Amazon EKS 进行编排以及使用 Amazon Mechanical Turk 进行人工验证,可以构建一个管道,自动评估、排名和演化您的提示词。与其手动更新提示词或重新评估模型,不如专注于创建一个由反馈驱动的系统,持续为您的用户改进结果。从小规模的模型和提示词集开始,定义您的评估指标,并随着新模型和用例的出现,让系统随之扩展。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区