



📢 转载信息
原文作者:Prashant Patel, Ainesh Sootha, and Sandeep Akhouri
Amazon Bedrock 自定义模型导入现已支持 OpenAI 具有开放权重的模型,包括参数量为 200 亿和 1200 亿的 GPT-OSS 变体。GPT-OSS 模型提供了推理能力,可与 OpenAI 聊天补全 API 配合使用。通过保持对完整 OpenAI API 的兼容性,组织可以将现有应用程序迁移到 AWS,从而获得企业级的安全性、扩展性和成本控制。
在本文中,我们将展示如何使用 Amazon Bedrock 自定义模型导入来部署 GPT-OSS-20B 模型,同时与您当前的应用程序保持完全的 API 兼容性。
Amazon Bedrock 自定义模型导入概览
Amazon Bedrock 自定义模型导入允许您将定制的模型带入与访问基础模型 (FM) 相同的无服务器环境中。您获得的是一个统一的 API 接口,无需管理多个端点或单独的基础设施。
要使用此功能,请将模型文件上传到 Amazon Simple Storage Service (Amazon S3),然后通过 Amazon Bedrock 控制台启动导入。AWS 负责繁重的工作,包括配置 GPU、设置推理服务器以及根据需求自动扩展。您可以专注于您的应用程序,而 AWS 则负责管理基础设施。
GPT-OSS 模型支持 OpenAI 聊天补全 API,包括消息数组、角色定义(system、user 或 assistant)以及带有 token 使用指标的标准响应结构。您可以将应用程序指向 Amazon Bedrock 端点,它们只需对代码库进行最少的更改即可运行。
GPT-OSS 模型概览
GPT-OSS 模型是 OpenAI 自 GPT-2 以来发布的第一个开放权重语言模型,根据 Apache 2.0 许可证发布。您可以免费下载、修改和使用它们,包括用于商业应用。这些模型专注于推理、工具使用和高效部署。请根据您的需求选择合适的模型:
- GPT-OSS-20B (210 亿参数) – 该模型非常适合对速度和效率要求最高的应用程序。尽管它有 210 亿个参数,但每个 token 仅激活 36 亿个参数,因此可以在仅具有 16 GB 内存的边缘设备上流畅运行。它具有 24 层、32 个专家(每个 token 激活 4 个)和 128k 的上下文窗口,性能可媲美 OpenAI 的 o3-mini,同时可以通过本地部署实现更快的响应时间。
- GPT-OSS-120B (1170 亿参数) – 专为复杂的推理任务(如编码、数学和代理工具使用)而构建,每个 token 激活 51 亿个参数。它具有 36 层、128 个专家(每个 token 激活 4 个)和 128k 的上下文窗口,性能可媲美 OpenAI 的 o4-mini,同时可在单个 80GB GPU 上高效运行。
这两个模型都使用专家混合 (MoE) 架构——模型组件(专家)的子集处理不同类型的任务,并且每次请求只激活最相关的专家。这种方法为您提供了强大的性能,同时将计算成本控制在可接受的范围内。
了解 GPT-OSS 模型格式
当您从 Hugging Face 下载 GPT-OSS 模型时,会获得协同工作的多种文件类型:
- 权重文件 (.safetensors) – 实际的模型参数
- 配置文件 (config.json) – 定义模型如何工作的设置
- 分词器文件 – 处理文本
- 索引文件 (model.safetensors.index.json) – 将权重数据映射到特定文件
索引文件需要特定的结构才能与 Amazon Bedrock 配合使用。它必须在根级别包含一个 metadata 字段。此字段可以为空 ({}) 或包含总模型大小(文本模型的总大小必须小于 200 GB)。
来自 Hugging Face 的模型有时会包含 Amazon Bedrock 不支持的额外元数据字段,例如 total_parameters。在导入之前,您必须删除这些字段。正确的结构应如下所示:
{
"metadata": {},
"weight_map": {
"lm_head.weight": "model-00009-of-00009.safetensors",
...
}
}请确保在启动 Amazon S3 上传之前排除 metal 目录。
解决方案概述
在本文中,我们将通过 Amazon Bedrock 自定义模型导入完成完整的部署过程。我们使用 Tonic/med-gpt-oss-20b 模型,它是 OpenAI GPT-OSS-20B 的微调版本,专门针对医疗推理和指令遵循进行了优化。
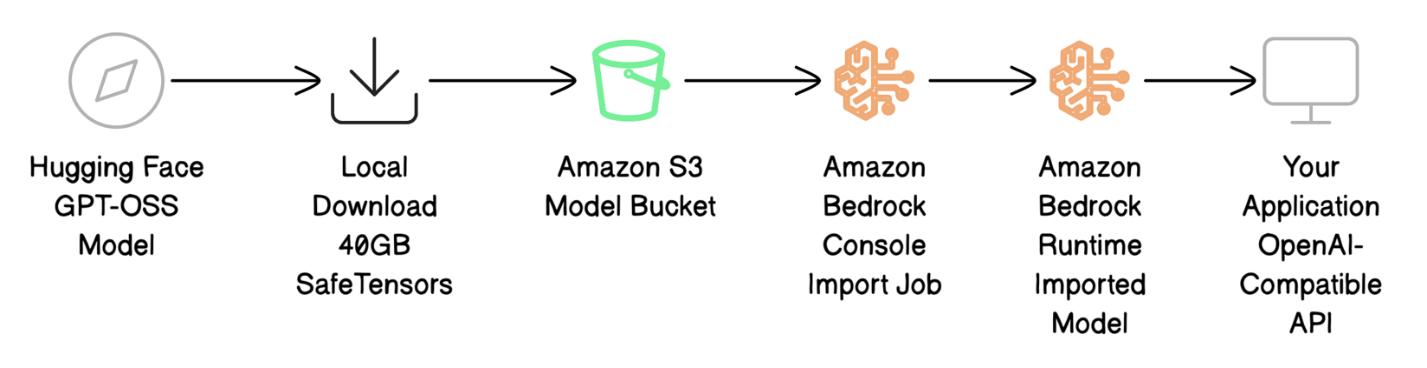
部署过程涉及四个主要步骤:
- 从 Hugging Face 下载模型文件并为 AWS 准备。
- 将模型文件上传到 Amazon S3。
- 使用 Amazon Bedrock 自定义模型导入进行导入,将模型引入 Amazon Bedrock。
- 使用兼容 OpenAI 的 API 调用来调用您的模型,以测试部署情况。
下图说明了部署工作流程。
先决条件
在开始部署 GPT-OSS 模型之前,请确保您具备以下条件:
- 具有适当权限的有效 AWS 账户
- AWS Identity and Access Management (IAM) 权限,包括:
- 在 Amazon Bedrock 中创建模型导入作业
- 向 Amazon S3 上传文件
- 部署后调用模型
- 使用自定义模型导入服务角色
- 目标 AWS 区域中的 S3 存储桶
- 大约 40 GB 的本地磁盘空间用于模型下载
- 对美国东部 1 区(弗吉尼亚北部)区域的访问权限(GPT-OSS 自定义模型要求)
- 已安装 AWS 命令行界面 (AWS CLI) 2.x 版本
- Hugging Face CLI(使用
pip install -U "huggingface_hub[cli]"安装)
下载和准备模型文件
要使用启用快速传输的 Hugging Face Hub 库下载 GPT-OSS 模型,请使用以下代码:
import os
os.environ['HF_HUB_ENABLE_HF_TRANSFER'] = '1'
from huggingface_hub import snapshot_download local_dir = snapshot_download(
repo_id="Tonic/med-gpt-oss-20b",
local_dir="./med-gpt-oss-20b",
)print(f"Download complete! Model saved to: {local_dir}")下载完成后(40 GB 需要 10-20 分钟),请验证 model.safetensors.index.json 文件的结构。如有需要,请编辑它以确保存在 metadata 字段(它可以是空的):
{
"metadata": {},
"weight_map": {
"lm_head.weight": "model-00009-of-00009.safetensors",
...
}
} ec2-user@ip-XYZ ~/gptoss/med-gpt-oss-20b ls -lah
total 39G
drwxr-xr-x. 3 ec2-user ec2-user 16K Nov 10 19:38 .
drwxr-xr-x. 3 ec2-user ec2-user 44 Nov 10 21:31 ..
drwxr-xr-x. 3 ec2-user ec2-user 25 Nov 10 18:57 .cache
-rw-r--r--. 1 ec2-user ec2-user 17K Nov 10 18:57 chat_template.jinja
-rw-r--r--. 1 ec2-user ec2-user 1.6K Nov 10 18:57 config.json
-rw-r--r--. 1 ec2-user ec2-user 160 Nov 10 18:57 generation_config.json
-rw-r--r--. 1 ec2-user ec2-user 1.6K Nov 10 18:57 .gitattributes
-rw-r--r--. 1 ec2-user ec2-user 4.2G Nov 10 18:57 model-00001-of-00009.safetensors
-rw-r--r--. 1 ec2-user ec2-user 4.6G Nov 10 18:57 model-00002-of-00009.safetensors
-rw-r--r--. 1 ec2-user ec2-user 4.6G Nov 10 18:57 model-00003-of-00009.safetensors
-rw-r--r--. 1 ec2-user ec2-user 4.6G Nov 10 18:57 model-00004-of-00009.safetensors
-rw-r--r--. 1 ec2-user ec2-user 4.6G Nov 10 18:57 model-00005-of-00009.safetensors
-rw-r--r--. 1 ec2-user ec2-user 4.6G Nov 10 18:57 model-00006-of-00009.safetensors
-rw-r--r--. 1 ec2-user ec2-user 4.6G Nov 10 18:57 model-00007-of-00009.safetensors
-rw-r--r--. 1 ec2-user ec2-user 4.6G Nov 10 18:57 model-00008-of-00009.safetensors
-rw-r--r--. 1 ec2-user ec2-user 2.6G Nov 10 18:57 model-00009-of-00009.safetensors
-rw-r--r--. 1 ec2-user ec2-user 33K Nov 10 19:38 model.safetensors.index.json
-rw-r--r--. 1 ec2-user ec2-user 5.4K Nov 10 18:57 README.md
-rw-r--r--. 1 ec2-user ec2-user 440 Nov 10 18:57 special_tokens_map.json
-rw-r--r--. 1 ec2-user ec2-user 4.2K Nov 10 18:57 tokenizer_config.json
-rw-r--r--. 1 ec2-user ec2-user 27M Nov 10 18:57 tokenizer.json将模型文件上传到 Amazon S3
在导入模型之前,必须将模型文件存储在 Amazon Bedrock 可以访问的 S3 存储桶中。请完成以下步骤:
- 在 Amazon S3 控制台中,在导航窗格中选择 Buckets(存储桶)。
- 创建新存储桶或打开现有存储桶。
- 上传模型文件。
或者,使用 AWS CLI 将文件上传到目标 Amazon Bedrock 区域的 S3 存储桶中:
aws s3 sync ./med-gpt-oss-20b/ s3://amzn-s3-demo-bucket/med-gpt-oss-20b/40 GB 的上传通常需要 5-10 分钟才能完成。验证文件是否已上传:
aws s3 ls s3://amzn-s3-demo-bucket/med-gpt-oss-20b/ --human-readable下面的屏幕截图显示了 S3 存储桶中文件的示例。

记下您的 S3 URI(例如,s3://amzn-s3-demo-bucket/med-gpt-oss-20b/),以供导入作业使用。
输出文件使用 S3 存储桶的加密配置进行加密。这些文件根据您设置 S3 存储桶的方式,使用 SSE-S3 服务器端加密或 AWS Key Management Service (AWS KMS) SSE-KMS 加密进行加密。
使用 Amazon Bedrock Custom Import 导入模型
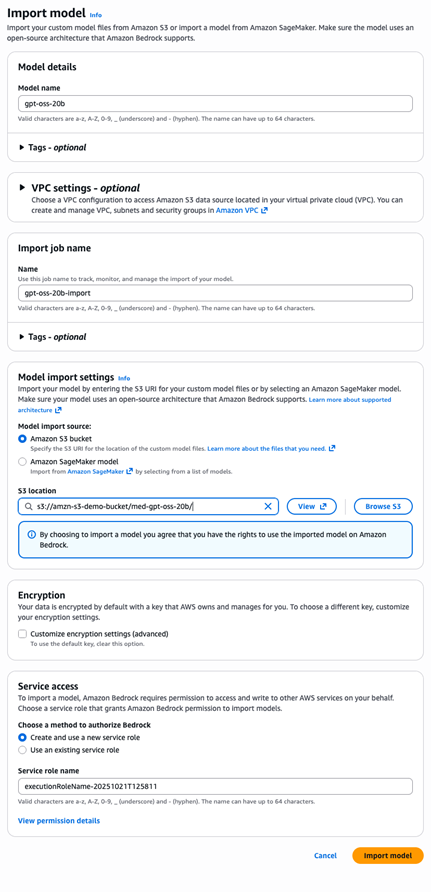
模型文件上传到 Amazon S3 后,您可以将其导入 Amazon Bedrock,以便进行处理并可用于推理。请完成以下步骤:
- 在 Amazon Bedrock 控制台中,在导航窗格中选择 Imported models(已导入模型)。
- 选择 Import model(导入模型)。
- 对于 Model name(模型名称),输入
gpt-oss-20b。 - 对于 Model import source(模型导入源),选择 Amazon S3 bucket(Amazon S3 存储桶)。
- 对于 S3 location(S3 位置),输入
s3://amzn-s3-demo-bucket/med-gpt-oss-20b/。 - 对于 Service access(服务访问),选择 Create and use a new service role(创建并使用新的服务角色)。Amazon Bedrock 控制台会自动生成一个具有正确信任关系和 Amazon S3 读取权限的角色。
- 选择 Import model(导入模型)以启动导入作业。
要使用 AWS CLI,请使用以下代码:
aws bedrock create-model-import-job \
--job-name "gpt-oss-20b-import-$(date +%Y%m%d-%H%M%S)" \
--imported-model-name "gpt-oss-20b" \
--role-arn "arn:aws:iam::YOUR-ACCOUNT-ID:role/YOUR-ROLE-NAME" \
--model-data-source "s3DataSource={s3Uri=s3://amzn-s3-demo-bucket/med-gpt-oss-20b/}"对于 20B 参数模型,模型导入通常需要 10-15 分钟才能完成。您可以在 Amazon Bedrock 控制台或使用 AWS CLI 监控进度。完成后,记下您的 importedModelArn,您将使用它来调用模型。
使用兼容 OpenAI 的 API 调用模型
模型导入完成后,您可以使用熟悉的 OpenAI 聊天补全 API 格式对其进行测试,以验证其是否按预期工作:
- 创建一个名为
test-request.json的文件,其中包含以下内容:
{
"messages": [
{
"role": "system",
"content": "You are a helpful AI assistant."
},
{
"role": "user",
"content": "What are the common symptoms of Type 2 Diabetes?"
}
],
"max_tokens": 500,
"temperature": 0.7
}- 使用 AWS CLI 将请求发送到您的导入模型端点:
aws bedrock-runtime invoke-model \
--model-id "arn:aws:bedrock:us-east-1:YOUR-ACCOUNT-ID:imported-model/MODEL-ID" \
--body file://test-request.json \
--cli-binary-format raw-in-base64-out \
response.json
cat response.json | jq '.'响应以标准的 OpenAI 格式返回:
{
"id": "chatcmpl-f06adcc78daa49ce9dd2c58f616bad0c",
"object": "chat.completion",
"created": 1762807959,
"model": "YOUR-ACCOUNT-ID-MODEL-ID",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Type 2 Diabetes often presents with a range of symptoms...",
"refusal": null,
"function_call": null,
"tool_calls": []
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 98,
"completion_tokens": 499,
"total_tokens": 597
}
}响应结构与 OpenAI 的格式完全匹配——choices 包含响应,usage 提供 token 计数,finish_reason 指示完成状态。现有的 OpenAI 响应解析代码无需修改即可工作。
该模型的一个强大优势是其透明性。reasoning_content 字段为我们提供了模型在生成最终响应之前内部推理过程的信息。这种透明度是闭源 API 所不具备的。
清理
完成后,清理资源以避免不必要的费用:
aws bedrock delete-imported-model --model-identifier "arn:aws:bedrock:us-east-1:ACCOUNT:imported-model/MODEL-ID" aws s3 rm s3://amzn-s3-demo-bucket/med-gpt-oss-20b/ --recursive如果您不再需要 IAM 角色,请使用 IAM 控制台将其删除。
从 OpenAI 迁移到 Amazon Bedrock
从 OpenAI 迁移所需的代码更改极少——只有调用方法发生变化,而消息结构保持不变。
对于 OpenAI,使用以下代码:
import openai
response = openai.ChatCompletion.create(model="....", messages=[...])对于 Amazon Bedrock,使用以下代码:
import boto3, json
bedrock = boto3.client('bedrock-runtime')
response = bedrock.invoke_model(
modelId='arn:aws:bedrock:us-east-1:ACCOUNT:imported-model/MODEL-ID',
body=json.dumps({"messages": [...]})
)迁移很直接,您将获得可预测的成本、更好的数据隐私以及根据您的特定需求微调模型的可能性。
最佳实践
请考虑以下最佳实践:
- 文件验证 – 上传前,请验证
model.safetensors.index.json具有正确的元数据结构,引用的 safetensors 文件存在,并且分词器受支持。本地验证可以节省导入重试时间。 - 安全性 – 在 Amazon Bedrock 控制台上,使用最小权限自动创建 IAM 角色。对于多个模型,使用单独的 S3 前缀来保持隔离。
- 版本控制 – 使用描述性的 S3 路径(
gpt-oss-20b-v1.0/)或带日期的导入作业名称来跟踪部署。
定价
导入 Amazon Bedrock 的自定义模型运行推理时会产生费用。更多详细信息,请参阅 计算运行自定义模型的成本和 Amazon Bedrock 定价。
结论
在本文中,我们展示了如何使用自定义模型导入在 Amazon Bedrock 上部署 GPT-OSS 模型,同时保持完整的 OpenAI API 兼容性。您现在可以以最少的代码更改将现有应用程序迁移到 AWS,并获得企业级优势,包括完全的模型控制、微调能力、可预测的定价和增强的数据隐私。
准备开始了吗?以下是您的后续步骤:
- 选择您的模型大小 – 从 20B 模型开始以获得更快响应,或针对复杂的推理任务使用 120B 变体
- 设置您的环境 – 确保您拥有所需的 AWS 权限和 S3 存储桶访问权限
- 尝试 Amazon Bedrock 控制台 – 使用 Amazon Bedrock 控制台导入您的第一个 GPT-OSS 模型
- 探索高级功能 – 在基本设置正常工作后,考虑使用您专有数据进行微调
Amazon Bedrock 自定义模型导入在多个区域可用,并将在短期内扩展到更多区域。请参阅 Amazon Bedrock 中按 AWS 区域划分的功能支持以获取最新更新。GPT-OSS 模型最初将在美国东部 1 区(弗吉尼亚北部)区域提供。
有任何问题或反馈?请通过 AWS re:Post 联系 Amazon Bedrock 团队——我们很乐意听取您的体验。
作者简介
 Prashant Patel 是 AWS Bedrock 的高级软件开发工程师。他热衷于为企业应用程序扩展大型语言模型。在加入 AWS 之前,他曾在 IBM 从事在 Kubernetes 上生产化大规模 AI/ML 工作负载的工作。Prashant 拥有纽约大学坦登工程学院的硕士学位。在工作之余,他喜欢旅行和逗他的狗。
Prashant Patel 是 AWS Bedrock 的高级软件开发工程师。他热衷于为企业应用程序扩展大型语言模型。在加入 AWS 之前,他曾在 IBM 从事在 Kubernetes 上生产化大规模 AI/ML 工作负载的工作。Prashant 拥有纽约大学坦登工程学院的硕士学位。在工作之余,他喜欢旅行和逗他的狗。
 Ainesh Sootha 是 AWS 的软件开发工程师。他热衷于为企业应用程序进行性能优化和扩展大型语言模型。在加入 AWS Bedrock 之前,他曾从事亚马逊的 Just Walk Out 技术的身份验证系统工作。Ainesh 拥有普渡大学计算机工程学士学位。在工作之余,他喜欢弹吉他和读书。
Ainesh Sootha 是 AWS 的软件开发工程师。他热衷于为企业应用程序进行性能优化和扩展大型语言模型。在加入 AWS Bedrock 之前,他曾从事亚马逊的 Just Walk Out 技术的身份验证系统工作。Ainesh 拥有普渡大学计算机工程学士学位。在工作之余,他喜欢弹吉他和读书。
 Sandeep Akhouri 是一位经验丰富的产品和上市 (GTM) 领导者,在产品管理、工程和上市方面拥有超过 20 年的经验。在他目前的职位之前,Sandeep 负责领导产品管理,在领先的技术公司(包括 Splunk、KX Systems、Hazelcast 和 Software AG)构建 AI/ML 产品。他对代理 AI、模型定制以及利用生成式 AI 推动现实世界的影响充满热情。
Sandeep Akhouri 是一位经验丰富的产品和上市 (GTM) 领导者,在产品管理、工程和上市方面拥有超过 20 年的经验。在他目前的职位之前,Sandeep 负责领导产品管理,在领先的技术公司(包括 Splunk、KX Systems、Hazelcast 和 Software AG)构建 AI/ML 产品。他对代理 AI、模型定制以及利用生成式 AI 推动现实世界的影响充满热情。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区