



📢 转载信息
原文作者:Bala Priya C

构建更优良的LLM应用所需的分块技术
图片作者提供
引言
每个检索信息的大型语言模型(LLM)应用都面临一个简单的问题:你如何将一份50页的文档分解成模型能够实际使用的片段?因此,当你在构建检索增强生成(RAG)应用时,在你的向量数据库检索任何内容和LLM生成回复之前,你的文档需要被分割成块(chunks)。
你分割文档块的方式决定了你的系统可以检索到什么信息,以及它能多准确地回答查询。这个预处理步骤通常被视为次要的实现细节,但它实际上决定了你的RAG系统是成功还是失败。
原因很简单:检索操作是在块级别而不是文档级别进行的。适当的分块可以提高检索准确性、减少幻觉,并确保LLM接收到有针对性、相关性强的上下文。糟糕的分块会级联影响你的整个系统,导致检索机制无法修复的失败。
本文将介绍必要的分块策略,并解释何时使用每种方法。
为什么分块很重要
嵌入模型和LLM具有有限的上下文窗口。文档通常会超出这些限制。分块通过将长文档分解成更小的片段来解决这个问题,但这引入了一个重要的权衡:块必须足够小以便高效检索,同时又足够大以保持语义连贯性。
向量搜索操作基于块级别的嵌入。当块混合了多个主题时,它们的嵌入代表了这些概念的平均值,使得精确检索变得困难。如果块太小,它们缺乏足够的上下文供LLM生成有用的回复。
挑战在于找到一个中间地带,使得块在语义上是集中的,但在上下文上是完整的。现在让我们来看看你可以尝试的实际分块技术。
1. 固定大小分块 (Fixed-Size Chunking)
固定大小分块根据预定的令牌或字符数来分割文本。这种实现的开销很小:
- 选择一个块大小(通常为512或1024个令牌)。
- 添加重叠(通常为10%–20%)。
- 分割文档。
该方法完全忽略了文档结构。文本在任意点分割,不考虑语义边界,常常中断在句子或段落中间。重叠有助于在边界处保留上下文,但没有解决结构盲目分割这个核心问题。
尽管存在局限性,固定大小分块提供了一个可靠的基线。它快速、确定性强,并且对于没有强大结构元素的文档来说效果尚可。
何时使用:基线实现、简单文档、快速原型设计。
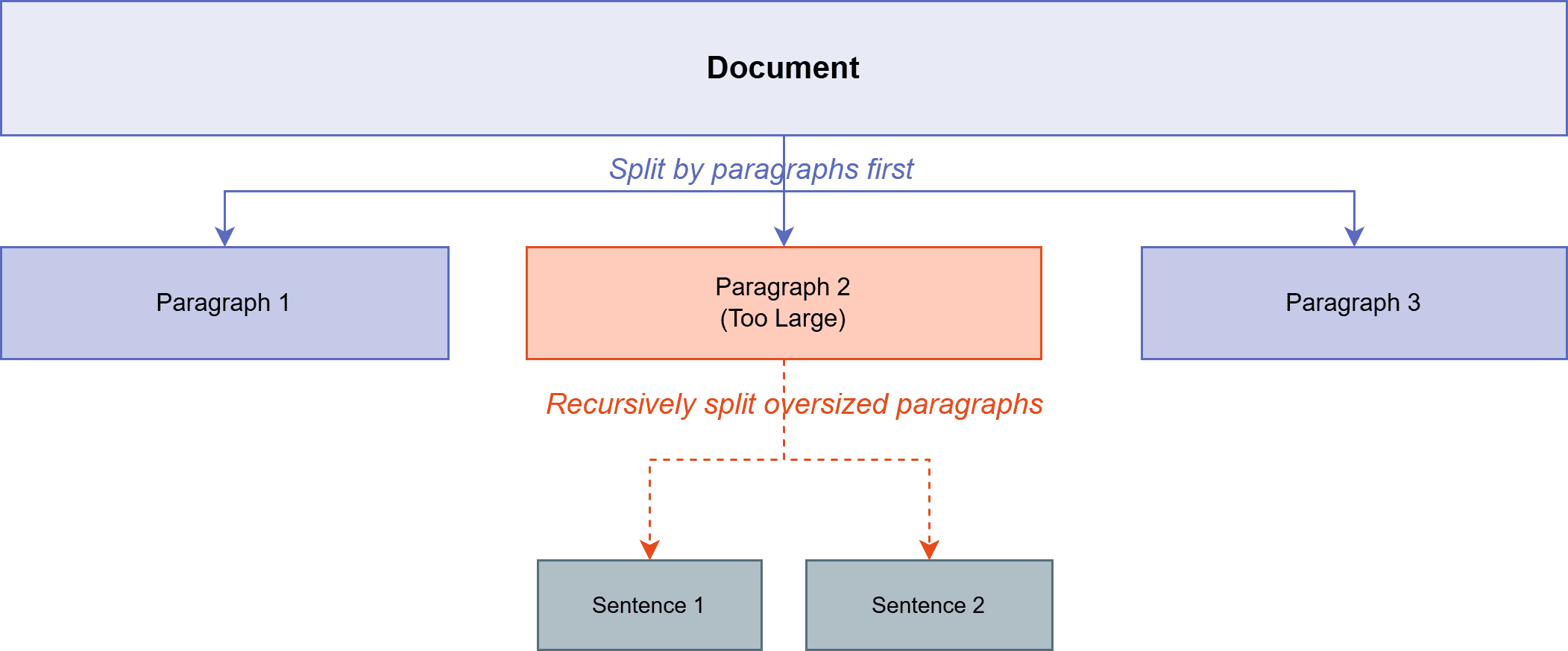
2. 递归分块 (Recursive Chunking)
递归分块通过尊重自然文本边界来改进固定大小方法。它尝试使用渐进更精细的分隔符进行分割——首先是段落断点,然后是句子,然后是单词——直到块符合目标大小。
递归分块
图片作者提供
该算法试图将语义相关的内容保留在一起。如果按段落断点分割产生的块在大小限制内,它就会停止。如果段落太大,它只会对超大块递归应用句子级别的分割。
这比任意的字符分割保留了更多的文档原始结构。块倾向于与自然的思考边界对齐,从而提高了检索相关性和生成质量。
何时使用:通用应用、文章和报告等非结构化文本。
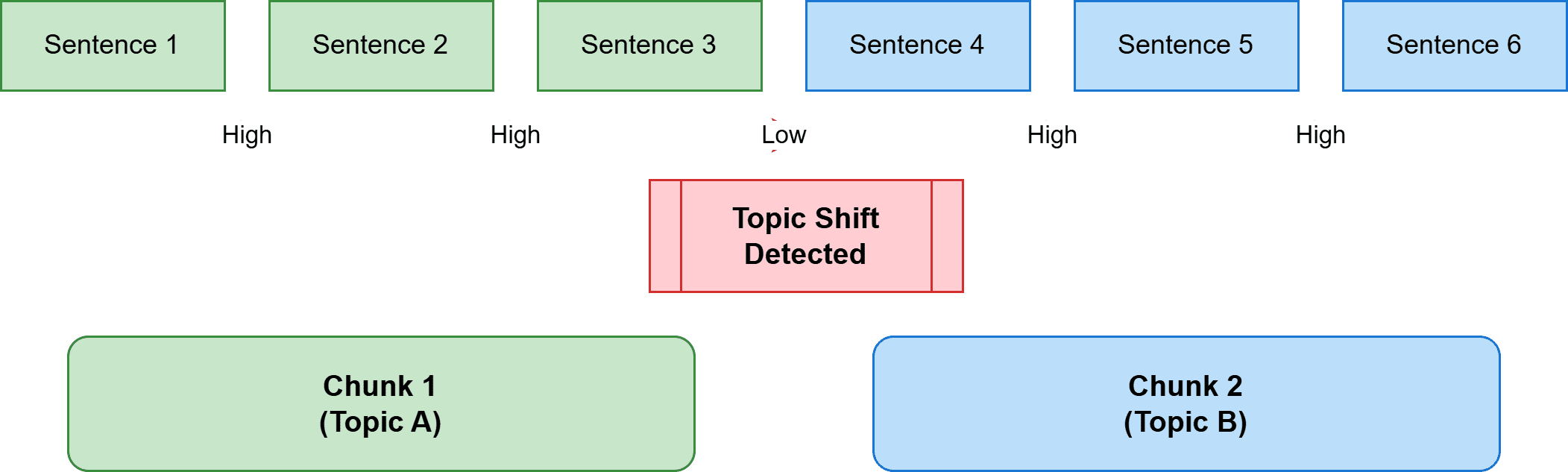
3. 语义分块 (Semantic Chunking)
语义分块不依赖于字符或结构,而是使用含义来确定边界。该过程会嵌入单个句子,比较它们的语义相似度,并识别主题发生转移的点。
语义分块
图片作者提供
实现涉及计算每个句子的嵌入,测量连续句子嵌入之间的距离,并在距离超过某个阈值时进行分割。这创建了内容围绕单一主题或概念保持连贯性的块。
计算成本更高。但结果是语义连贯的块,通常能提高复杂文档的检索质量。
何时使用:密集型的学术论文、主题不可预测地变化的技术文档。
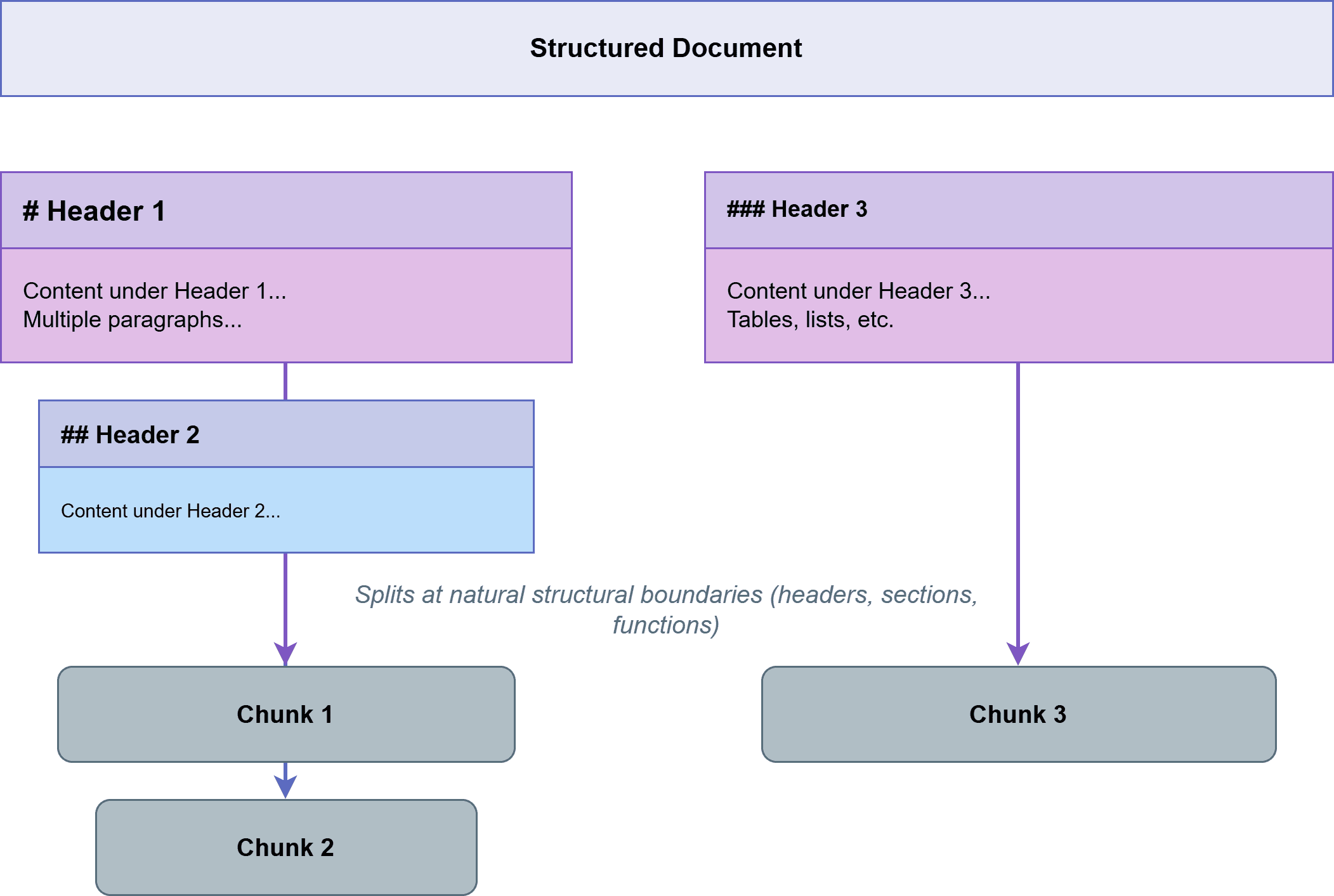
4. 基于文档分块 (Document-Based Chunking)
具有明确结构的文档——Markdown标题、HTML标签、代码函数定义——包含天然的分割点。基于文档的分块利用这些结构元素。
对于Markdown,按标题级别分割。对于HTML,按语义标签如<section>或<article>分割。对于代码,按函数或类边界分割。生成的块与文档的逻辑组织对齐,而逻辑组织通常与语义组织相关联。以下是基于文档分块的一个示例:
基于文档的分块
图片作者提供
LangChain 和 LlamaIndex 等库为各种格式提供了专门的分割器,处理了解析的复杂性,让你专注于块大小参数。
何时使用:具有清晰分层元素的结构化文档。
5. 延迟分块 (Late Chunking)
延迟分块颠倒了典型的“先嵌入后分块”的顺序。首先,使用长上下文模型嵌入整个文档。然后分割文档,并通过平均来自完整文档嵌入中相关令牌级别的嵌入来推导出块嵌入。
这保留了全局上下文。每个块的嵌入不仅反映了其自身的内容,还反映了其与整个文档的关系。对早期概念的引用、共享术语和文档级主题仍然编码在嵌入中。
该方法要求能够处理整个文档的长上下文嵌入模型,限制了其在合理大小文档中的适用性。
何时使用:具有显著交叉引用的技术文档、具有内部依赖性的法律文本。
6. 自适应分块 (Adaptive Chunking)
自适应分块根据内容特征动态调整块参数。信息密集的区域接收较小的块以保持粒度。稀疏、背景性的区域接收较大的块以保持连贯性。
自适应分块
图片作者提供
实现通常使用启发式方法或轻量级模型来评估内容密度并相应调整块大小。
何时使用:信息密度高度可变的文档。
7. 分层分块 (Hierarchical Chunking)
分层分块创建了多个粒度级别。大的父块捕获广泛的主题,而较小的子块包含具体细节。在查询时,先检索粗粒度的块,然后在相关的父块中深入查询细粒度的块。
这使得可以使用相同的分块语料库来进行高级查询(“本文档涵盖了什么?”)和特定查询(“精确的配置语法是什么?”)。实现需要维护块级别之间的关系并在检索过程中遍历它们。
何时使用:大型技术手册、教科书、综合性文档。
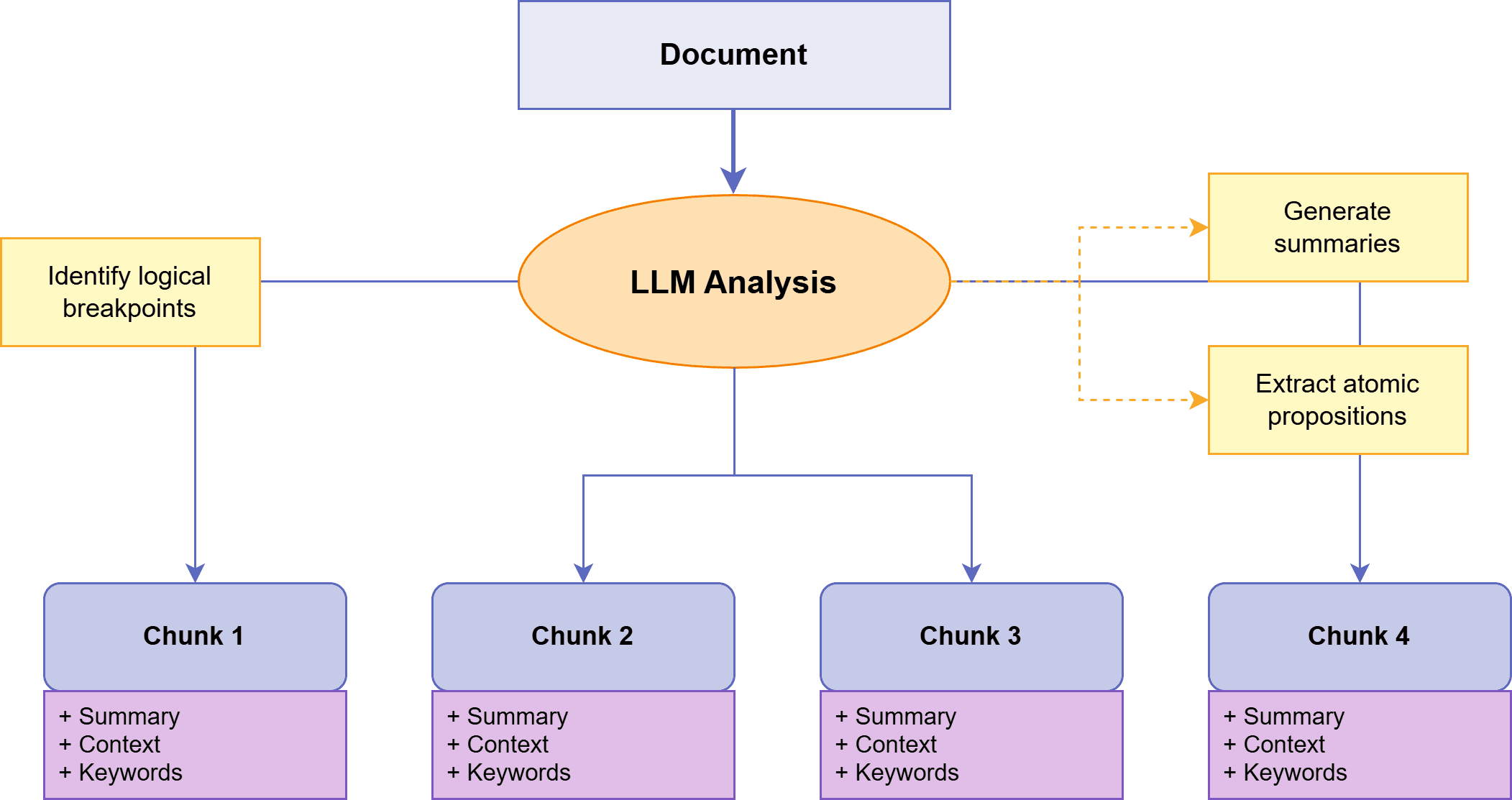
8. 基于LLM的分块 (LLM-Based Chunking)
在基于LLM的分块中,我们使用LLM来确定块边界,将分块推向智能化的领域。LLM分析文档并根据语义理解决定如何分割它,而不是依赖规则或嵌入。
基于LLM的分块
图片作者提供
方法包括将文本分解为原子命题、为部分生成摘要或识别逻辑断点。LLM还可以用元数据或上下文描述来丰富块,以改进检索。
这种方法成本较高——需要对每个文档进行LLM调用——但能产生高度连贯的块。对于检索质量证明其成本高昂的高风险应用,基于LLM的分块通常优于更简单的方法。
何时使用:检索质量比处理成本更重要的应用。
9. 代理式分块 (Agentic Chunking)
代理式分块将基于LLM的方法扩展,让一个代理分析每个文档并动态选择适当的分块策略。代理会考虑文档结构、内容密度和格式,以便在固定大小、递归、语义或其他方法之间为每个文档选择。
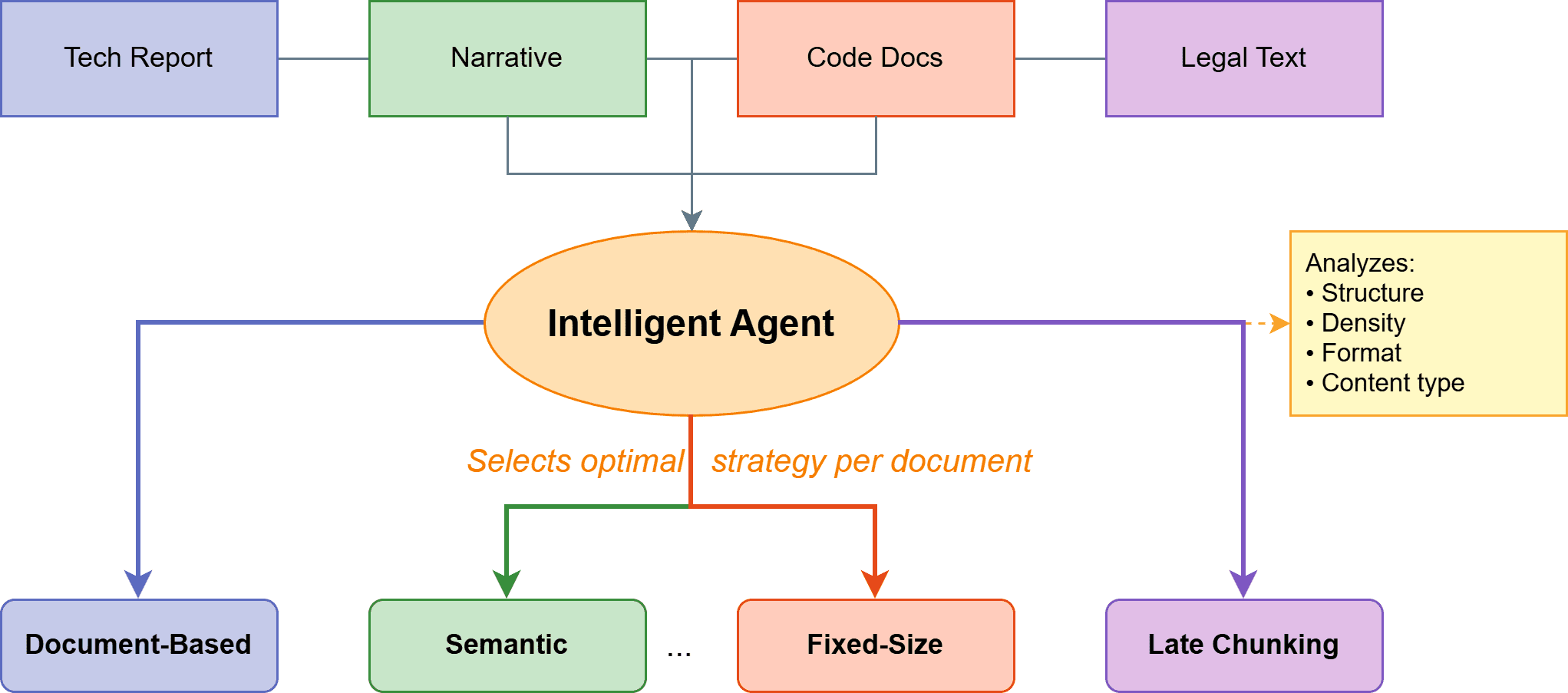
代理式分块
图片作者提供
这可以处理单一策略表现不佳的异构文档集合。代理可能会对结构化报告使用基于文档的分块,而对同一语料库中的叙事内容使用语义分块。
权衡是复杂性和成本。在分块开始之前,每个文档都需要进行代理分析。
何时使用:最佳策略显著不同的多样化文档集合。
结论
分块决定了你的检索系统能找到什么信息,以及你的LLM接收到什么上下文用于生成。现在你了解了不同的分块技术,如何为你的应用选择一个分块策略?你可以根据文档特性进行选择:
- 简短、独立的文档(FAQ、产品描述):无需分块
- 结构化文档(Markdown、HTML、代码):基于文档分块
- 非结构化文本(文章、报告):如果固定大小分块效果不佳,尝试递归或分层分块
- 复杂、高价值文档:语义分块、自适应分块或基于LLM的分块
- 异构集合:代理式分块
还要考虑你的嵌入模型的上下文窗口和典型的查询模式。如果用户提出具体的事实性问题,倾向于选择较小的块以提高精度。如果查询需要理解更广泛的背景,则使用较大的块。
更重要的是,要建立指标并进行测试。跟踪不同分块策略下的检索精度、答案准确性和用户满意度。使用具有已知正确答案的代表性查询。衡量是否检索到了正确的块,以及LLM是否从这些块中生成了准确的响应。
LangChain 和 LlamaIndex 等框架为大多数策略提供了预构建的分割器。对于自定义方法,直接实现逻辑以保持控制并最大限度地减少依赖。祝你分块顺利!
参考文献与进一步学习
- 使用Langchain和LlamaIndex进行分块技术
- 改进RAG性能的分块策略 | Weaviate
- Avi Chawla的5种RAG分块策略
- 为准确的AI响应寻找最佳分块策略 | NVIDIA技术博客
- 语义分块——实现更好RAG的3种方法
- LLM应用的分块策略 | Pinecone
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区