



📢 转载信息
原文作者:Nick Biso, Madhunika Reddy Mikkili, and Maria Masood
生成式 AI 的一项关键发展是 AI 驱动的视频生成。在 AI 出现之前,创建动态视频内容需要大量的资源、技术专长和大量的体力劳动。如今,AI 模型可以从简单的输入生成视频,但组织仍然面临结果不可预测等挑战。本文介绍了视频检索增强生成(V-RAG),一种有助于改进视频内容创作的方法。通过将检索增强生成与先进的视频 AI 模型相结合,V-RAG 提供了一种高效、可靠的 AI 视频生成解决方案。
视频生成
AI 视频生成代表了数字内容创作的变革性前沿,它能够自动化生成动态视觉叙事,而无需传统的拍摄或动画过程。通过使用深度学习架构,这些系统可以合成逼真或风格化的视频序列。与需要摄像机、演员和大量后期制作的传统视频制作不同,AI 生成通过分析海量训练数据集中的模式来完全通过计算过程来创建内容,从而呈现连贯的视觉故事。个人和组织可以利用这项技术,以最少的技术专长来制作视觉内容,从而减少了传统所需的(时间、资源和专业技能)。随着这些模型的不断发展,它们有望从根本上重塑视觉故事的构思、制作和共享方式,涵盖从娱乐、营销到教育和通信的各个行业。
文本到视频生成
文本到视频生成通过叙事性或主题性文本提示来创建动态视频内容。这项技术解释文本描述,并将其转换为遵循指定叙事的连贯视觉序列。虽然文本提示有效地指导了整体主题和故事情节,但有时在精确捕捉高度具体的视觉细节方面可能不足。文本到视频作为 AI 视频创作的基础,用户可以仅基于描述性语言生成内容。
视频生成定制
仅凭文本提示在视频生成方面能达到的效果是有限的。当仅依赖文本描述时,存在固有的控制限制,因为模型可能会忽略您提示中的关键部分,或者以与您意图不同的方式进行解释。某些视觉概念很难仅用文字来解释,此外,您还受到模型令牌限制的约束,该限制限制了您指令的详细程度。这就是进一步定制变得无价的地方。用户可以使用强大的定制工具来指定文本无法有效传达的众多参数,例如风格、情绪和复杂的视觉美学。这些控件通过提供影响输出的直接机制,有助于克服文本提示的局限性。没有这些功能,创作者只能寄希望于模型正确解释他们的意图,而不是主动指导创意过程。定制弥合了模糊生成和精确视觉控制之间的差距,使得 AI 视频工具对于专业应用真正有用。
模型微调
微调可将预训练的视频生成模型适应于特定的领域、风格或用例。此过程使组织能够创建专业的视频生成器,无论它们是生成具有一致品牌形象的产品演示、生成医学教育内容,还是以独特的艺术风格制作视频,都能表现出色。微调通常涉及对现有模型进行进一步训练,使用精心策划的数据集来表示目标领域,使模型能够学习专业应用所需的独特视觉模式、运动和风格元素。然而,微调视频生成模型带来了重大挑战。根本障碍始于数据采集,因为适合训练的高质量视频数据既昂贵又难以获得。组织需要特定格式的、多样化的、标记良好的视频素材,涵盖特定用例,同时满足技术质量标准。计算需求巨大,构成了主要的入门障碍。一次微调运行可能需要多台高端 GPU 持续运行,而为了引入新功能而进行的重新训练会随着每一次迭代而增加成本。即使拥有完美的数据和无限的计算资源,由于视频元素(如连贯性、物理准确性、光照一致性和对象持久性)的相互关联性,成功仍然不确定。一个领域的改进常常导致其他领域意外退化,从而产生了复杂且难以简单解决的优化挑战。
图像到视频
图像到视频生成通过提供额外的视觉控制来补充基于文本的方法。通过使用输入图像作为参考,用户可以确保生成的视频中准确地表示颜色、样式和其他对象属性等特定细节。例如,如果用户想在视频中展示一个红色的手提包,提供该手提包的图像可以保证文本描述本身无法实现的视觉保真度。该技术通过条件约束来保持一致性并提高提示的遵循度,同时能够在更广泛的叙事背景中实现动态运动和集成。图像到视频生成不需要任何微调。
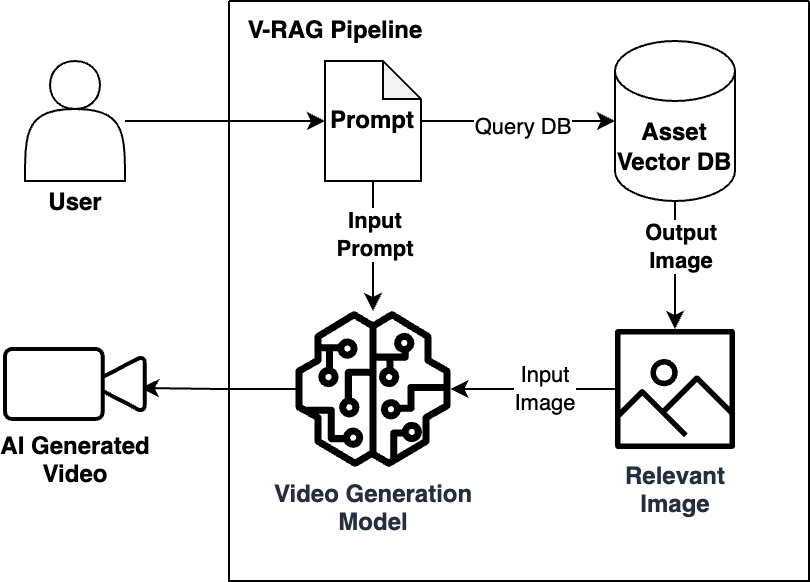
V-RAG:视频生成定制的有效方法
视频检索增强生成 (V-RAG) 在图像到视频技术的基础上,扩展了视频定制功能。传统的图像到视频是将单个参考图像转换为运动,而 V-RAG 通过检索并整合来自数据库的相关图像来输入视频生成,从而扩展了此功能。此方法提供了多项功能,而无需进行任何模型训练或重新训练。组织可以将他们的图像集合摄取到向量数据库中,对其进行查询,然后将其输出馈送到现有的视频生成模型,并立即开始生成定制内容。
V-RAG 的效率在于它只需要静态图像,而静态图像通常比视频训练数据更容易获得。这些图像可以即时添加到向量数据库中,使其在下一次生成任务中立即可用,而无需计算延迟。通过此过程生成的每个视频都与其源图像保持清晰的可追溯性,从而创建了一个可审计的路径,增强了验证和调试功能。该系统将视频输出基于特定的参考图像,旨在帮助降低幻觉风险并管理计算成本。组织可以为不同的部门或用例维护独立的视觉知识库,从而简化合规性,因为所有源材料在进入系统之前都可以进行彻底审查。
V-RAG 的逻辑图
V-RAG 不断发展的特性
V-RAG 代表的不是一种固定的技术,而是一个不断发展的框架,随着 AI 能力的进步,它将不断扩展。虽然目前的实现主要使用图像数据库,但基本的检索增强方法是独立于模式的。随着多模态 AI 模型的发展,V-RAG 系统将在生成过程中自然地整合音频样本、视频片段和 3D 模型作为参考点。未来的迭代可能会支持合成完整的视听体验,根据检索到的音频模式生成具有完美同步语音、逼真环境声音和自定义配乐的视频。这种灵活性使 V-RAG 成为一种基础范例,而不是一种特定的实现,使其能够随着更广泛的 AI 进步而适应,同时保持其可追溯性、效率和减少幻觉的核心优势。最终的愿景甚至超越了视听内容,可能包括互动元素,创建一个全面的多模态生成系统,在保持基于可靠参考材料的基础上,能够产生引人入胜的输出。
V-RAG 的关键优势
使用 V-RAG 检索的图像生成视频具有显著的优势,例如提高准确性、相关性和上下文理解能力。这种方法将生成的内��基于特定的知识库,以帮助指导视频创作。这可以减少幻觉,并确保视频与图像源的信息一致,这对于教育、纪录片或解释性视频格式尤其有用。使用 V-RAG 从图像生成的关键优势包括:
- 事实准确性 – 确保生成的视频内容基于真实信息,减少不准确或误导性视觉的可能性。
- 上下文相关性 – 检索与给定主题或查询高度相关的图像,从而实现更连贯和集中的视频叙事。
- 动态内容生成 – 通过根据用户输入或不断变化的需求动态选择和组装图像来实现灵活的视频创建。
- 减少开发时间 – 利用预先存在的知识库,缩短为视频创作收集和策划视觉素材所需的时间。
- 个性化内容 – 根据个人用户的需求定制视频,生成旨在相关且引人入胜的内容。
- 可扩展性 – 通过将更多图像摄取到向量数据库中来实现可扩展性。
V-RAG 的实际应用
V-RAG 的实际应用非常广泛且多样。在教育领域,V-RAG 可以通过从主题知识库中提取相关图像来自动创建教学视频。对于个性化内容,V-RAG 可以根据用户的特定兴趣检索图像,从而为用户量身定制视频内容。对于营销而言,V-RAG 可以通过提取与特定人口统计数据或产品功能相符的图像来创建有针对性的视频广告。
结论
随着 AI 技术的不断发展,V-RAG 的灵活框架使其能够整合新的模式和功能,从高级音频集成到交互式元素。AWS 的实现展示了组织如何通过现有的云服务开始使用这项技术,从而使更广泛的用户能够访问 AI 视频生成。展望未来,V-RAG 对视频内容创作的影响可能会远远超出其在教育和营销等领域的当前应用。随着技术的成熟,它有可能使视频制作更加便捷,同时支持质量、准确性和定制化。这种方法为 AI 驱动的视频生成提供了一条充满希望的途径,使组织能够创建引人注目的视觉内容。
参考文献
致谢
特别感谢 Vishwa Gupta、Shuai Cao 和 Seif 的贡献。
关于作者

Nick Biso
Nick Biso 是 AWS 专业服务部门的机器学习工程师。他使用数据科学和工程技术解决复杂的组织和技术挑战。此外,他还构建和部署 AWS 云上的 AI/ML 模型。他对旅行和多元文化体验的热爱也体现在他的职业热情中。

Madhunika Mikkili
Madhunika Mikkili 是 AWS 的数据和机器学习工程师。她热衷于帮助客户利用数据分析和机器学习实现他们的目标。

Maria Masood
Maria Masood 专注于智能体 AI、强化微调和多轮智能体训练。她拥有机器学习专业知识,涵盖大型语言模型定制、奖励建模和为 AI 智能体构建端到端训练管道。作为一名骨子里热爱可持续性的人,Maria 喜欢园艺和制作拿铁咖啡。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区