



📢 转载信息
原文链接:https://aws.amazon.com/blogs/machine-learning/amazon-bedrock-agentcore-observability-with-langfuse/
原文作者:Richa Gupta, Ishan Singh, Marc Klingen, Madhu Samhitha Vangara, and Yanyan Zhang
人工智能(AI)智能体的兴起标志着软件开发以及应用程序如何做出决策和与用户交互方式的转变。传统系统遵循可预测的路径,而AI智能体则进行复杂的推理,而这种推理过程对外部是隐藏的。这种“不可见性”给组织带来了挑战:如何信任那些看不见的东西?这就是智能体可观测性(agent observability)发挥作用的地方,它为智能体应用的性能、交互和任务执行提供了深入的洞察力。
在本文中,我们将解释如何将Langfuse可观测性与Amazon Bedrock AgentCore集成,以获得对AI智能体性能的深度可见性,更快地调试问题并优化成本。我们将通过一个使用部署在AgentCore Runtime上的Strands智能体的完整实施案例,并提供分步代码示例。
Amazon Bedrock AgentCore 是一个全面的智能体平台,可以安全、大规模地部署和运行能力强大的AI智能体。它为动态智能体工作负载提供了专门构建的基础设施、增强智能体的强大工具以及现实世界部署的基本控制。AgentCore 由全托管服务组成,可以一起或独立使用。这些服务与任何框架(包括CrewAI、LangGraph、LlamaIndex和Strands Agents)以及Amazon Bedrock内外的任何基础模型协同工作,提供了灵活性和可靠性。AgentCore以标准化的OpenTelemetry (OTEL)兼容格式发出遥测数据,从而可以轻松地与现有的监控和可观测性堆栈集成。它提供了对智能体工作流程中每一步的详细可视化,使用户能够检查智能体的执行路径、审计中间输出,并调试性能瓶颈和故障。
Langfuse 追踪的工作原理
Langfuse 使用 OpenTelemetry 来追踪和监控部署在 Amazon Bedrock AgentCore 上的智能体。OpenTelemetry 是一个云原生计算基金会 (CNCF) 项目,它提供了一套规范、API 和库,定义了从应用程序收集分布式追踪和指标的标准方法。用户现在可以跟踪跨不同处理阶段的性能指标,包括令牌使用量、延迟和执行持续时间。系统会创建分层的追踪结构,捕获流式和非流式响应,并提供详细的操作属性和错误状态。
通过 /api/public/otel 端点,Langfuse 作为 OpenTelemetry 后端运行,使用生成式AI惯例将追踪映射到其数据模型。这对于利用工具链和智能体的复杂大型语言模型 (LLM) 应用程序特别有价值,因为嵌套的追踪有助于开发人员快速识别和解决问题。这种集成支持系统化的调试、性能监控和审计追踪维护,使团队能够更轻松地在 Amazon Bedrock AgentCore 上构建和维护可靠的AI应用程序。
除了智能体可观测性之外,Langfuse 还提供了一套集成的工具,涵盖了整个LLM应用程序开发生命周期。这包括运行自动化的 llm-as-a-judge 评估器(在线/离线)、组织用于根本原因分析和评估器对齐的数据标注、追踪实验(本地和在 CI 中)、在 Playground 中以交互方式迭代提示词,以及使用提示词管理在 UI 中对其进行版本控制。
解决方案概述
本文展示了如何在启用了 Langfuse 可观测性的情况下将 Strands 智能体部署到 Amazon Bedrock AgentCore Runtime 上。该实施使用 Anthropic Claude 模型通过 Amazon Bedrock。遥测数据通过 OTEL 导出器从 Strands 智能体流向 Langfuse 进行监控和调试。要使用 Langfuse,请在 AgentCore 运行时部署中将 disable_otel=True 设置为 True。这将关闭 AgentCore 默认的可观测性功能。
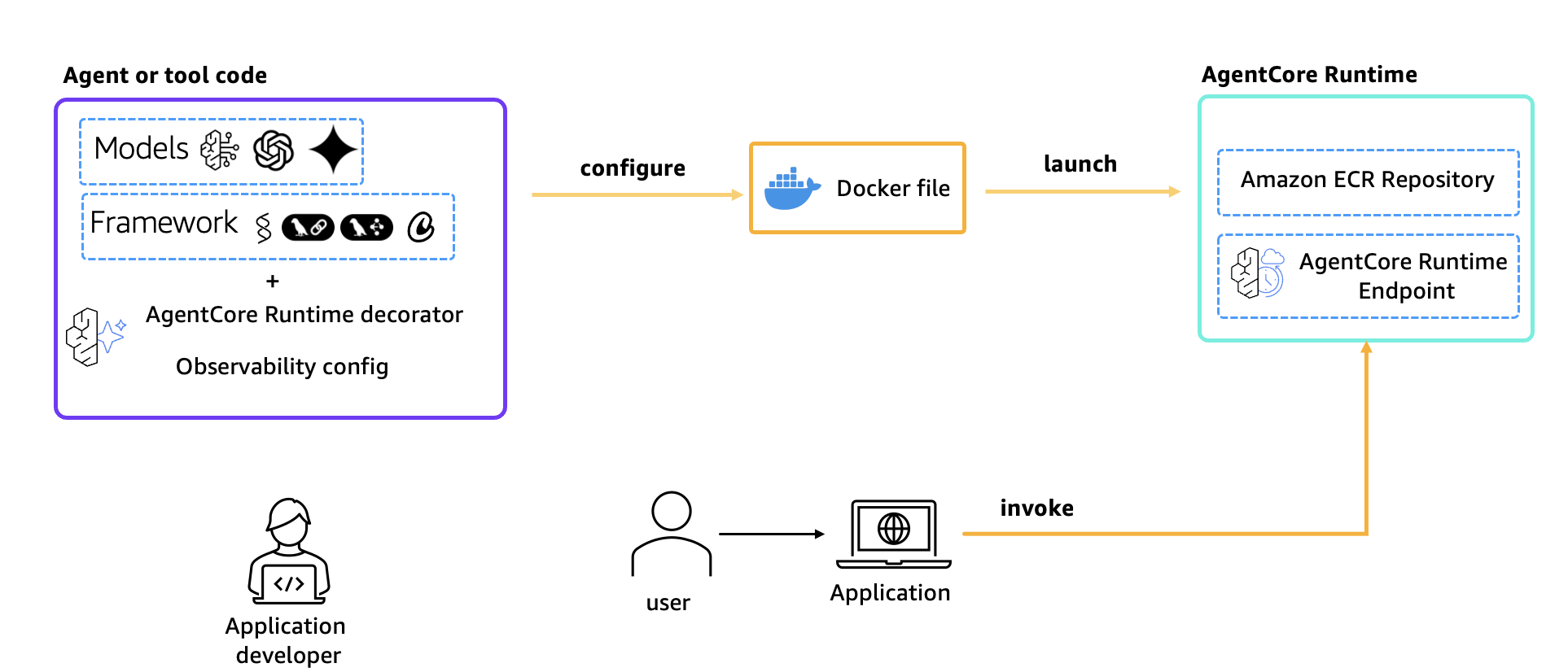
图 1:架构概览
解决方案中使用的关键组件包括:
- Strands Agents:用于构建支持内置遥测功能的 LLM 驱动智能体的 Python 框架
- Amazon Bedrock AgentCore Runtime:用于在 Amazon Web Services (AWS) 上托管和扩展智能体的托管运行时服务
- Langfuse:一个开源的可观测性和评估平台,用于 LLM 应用程序,通过 OTEL 接收追踪数据
- OpenTelemetry:用于收集和导出遥测数据的行业标准协议
技术实施指南
现在我们已经了解了 Langfuse 追踪的工作原理,我们可以继续介绍如何将其与 Amazon Bedrock AgentCore 实施。
先决条件
- 一个 AWS 账户
- 在使用 Amazon Bedrock 之前,请确认所有 AWS 凭证都已正确配置。可以使用 AWS CLI 或设置环境变量来配置它们。对于此笔记本,我们假设凭证已配置完毕。
- Amazon Bedrock 中 Anthropic Claude 3.7 模型的模型访问权限(在 us-west-2 区域)
- Amazon Bedrock AgentCore 权限
- Python 3.10+
- 本地安装的 Docker
- 一个 Langfuse 账户,用于创建 Langfuse API 密钥。
- 用户需要在 Langfuse Cloud 注册,创建一个项目,并获取 API 密钥
- 或者,您可以使用 Terraform 模块在您自己的 AWS 账户中自托管 Langfuse。
演练
以下步骤将指导您如何使用 Langfuse 从使用 Strands SDK 在 AgentCore 运行时创建的智能体中收集追踪数据。用户还可以参考 Github 上的此笔记本 以立即开始使用。
克隆此 Github 仓库:
git clone https://github.com/awslabs/amazon-bedrock-agentcore-samples.git克隆仓库后,请访问 Amazon Bedrock AgentCore 示例目录,找到笔记本 runtime_with_strands_and_langfuse.ipynb 并开始运行每个单元格。
第 1 步:我们的 Strands 智能体的 Python 依赖项和要求包
执行以下单元格以安装定义在 requirements.txt 文件中的依赖项。
!pip install --force-reinstall -U -r requirements.txt –quiet第 2 步:智能体实现
智能体文件 (strands_claude.py) 实现了一个具有网络搜索功能的旅行智能体。
%%writefile strands_claude.py import os import logging from bedrock_agentcore.runtime import BedrockAgentCoreApp from strands import Agent, tool from strands.models import BedrockModel from strands.telemetry import StrandsTelemetry from ddgs import DDGS logging.basicConfig(level=logging.ERROR, format="[%(levelname)s] %(message)s") logger = logging.getLogger(__name__) logger.setLevel(os.getenv("AGENT_RUNTIME_LOG_LEVEL", "INFO").upper()) @tool def web_search(query: str) -> str: """ Search the web for information using DuckDuckGo. Args: query: The search query Returns: A string containing the search results """ try: ddgs = DDGS() results = ddgs.text(query, max_results=5) formatted_results = [] for i, result in enumerate(results, 1): formatted_results.append( f"{i}. {result.get('title', 'No title')}\n" f" {result.get('body', 'No summary')}\n" f" Source: {result.get('href', 'No URL')}\n" ) return "\n".join(formatted_results) if formatted_results else "No results found." except Exception as e: return f"Error searching the web: {str(e)}" # Function to initialize Bedrock model def get_bedrock_model(): region = os.getenv("AWS_DEFAULT_REGION", "us-west-2") model_id = os.getenv("BEDROCK_MODEL_ID", "us.anthropic.claude-3-7-sonnet-20250219-v1:0") bedrock_model = BedrockModel( model_id=model_id, region_name=region, temperature=0.0, max_tokens=1024 ) return bedrock_model # Initialize the Bedrock model bedrock_model = get_bedrock_model() # Define the agent's system prompt system_prompt = """You are an experienced travel agent specializing in personalized travel recommendations with access to real-time web information. Your role is to find dream destinations matching user preferences using web search for current information. You should provide comprehensive recommendations with current information, brief descriptions, and practical travel details.""" app = BedrockAgentCoreApp() def initialize_agent(): """Initialize the agent with proper telemetry configuration.""" # Initialize Strands telemetry with 3P configuration strands_telemetry = StrandsTelemetry() strands_telemetry.setup_otlp_exporter() # Create and cache the agent agent = Agent( model=bedrock_model, system_prompt=system_prompt, tools=[web_search] ) return agent @app.entrypoint def strands_agent_bedrock(payload, context=None): """ Invoke the agent with a payload """ user_input = payload.get("prompt") logger.info("[%s] User input: %s", context.session_id, user_input) # Initialize agent with proper configuration agent = initialize_agent() response = agent(user_input) return response.message['content'][0]['text'] if __name__ == "__main__": app.run()第 3 步:配置 AgentCore 运行时部署
接下来,使用我们的入门工具包,使用入口点、我们创建的执行角色和 requirements 文件来配置 AgentCore 运行时部署。此外,配置入门套件以在启动时自动创建Amazon Elastic Container Registry (ECR) 存储库。
在配置步骤中,将根据应用程序代码生成 docker 文件。当使用 bedrock_agentcore_starter_toolkit 配置智能体时,它默认配置 AgentCore 可观测性。因此,要使用 Langfuse,用户应通过在以下代码块中所示的配置标志将 OTEL 设置为“True”来禁用 OTEL。
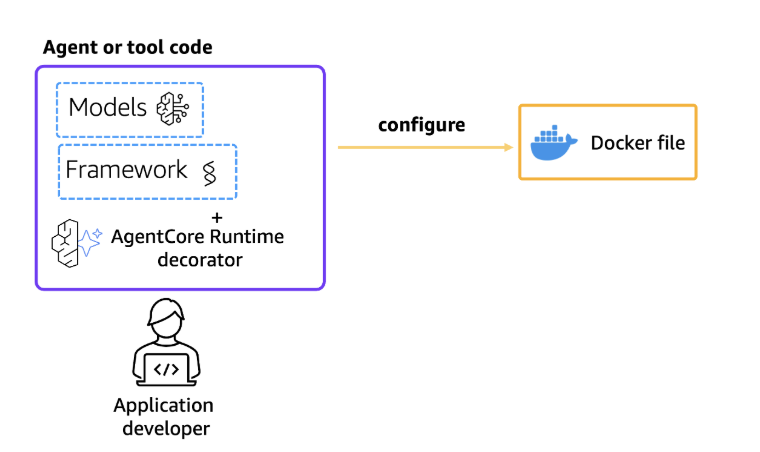
图 2:配置 AgentCore 运行时
from bedrock_agentcore_starter_toolkit import Runtime from boto3.session import Session boto_session = Session() region = boto_session.region_name agentcore_runtime = Runtime() agent_name = "strands_langfuse_observability" response = agentcore_runtime.configure( entrypoint="strands_claude.py", auto_create_execution_role=True, auto_create_ecr=True, requirements_file="requirements.txt", region=region, agent_name=agent_name, disable_otel=True, ) response第 4 步:部署到 AgentCore 运行时
现在已经生成了 docker 文件,将智能体启动到 AgentCore 运行时以创建 Amazon ECR 存储库和 AgentCore 运行时。
现在,在 AWS Systems Manager Parameter Store 中配置 Langfuse 密钥、公钥和 OTEL 端点,该服务提供安全的分层存储,用于配置数据管理和密钥管理。
import base64 # Langfuse configuration otel_endpoint = "https://us.cloud.langfuse.com/api/public/otel" langfuse_secret_key = "<Enter your Langfuse secret key>" #For production key should be securely stored langfuse_public_key = "<Enter your Langfuse public key" #For production key should be securely stored langfuse_auth_token = base64.b64encode(f"{langfuse_public_key}:{langfuse_secret_key}".encode()).decode() otel_auth_header = f"Authorization=Basic {langfuse_auth_token}" launch_result = agentcore_runtime.launch( env_vars={ "BEDROCK_MODEL_ID": "us.anthropic.claude-3-7-sonnet-20250219-v1:0", # Example model ID "OTEL_EXPORTER_OTLP_ENDPOINT": otel_endpoint, # Use Langfuse OTEL endpoint "OTEL_EXPORTER_OTLP_HEADERS": otel_auth_header, # Add Langfuse OTEL auth header "DISABLE_ADOT_OBSERVABILITY": "true", } ) launch_result下表描述了所使用的各种配置参数。
| 参数 | 描述 | 默认值 |
|---|---|---|
langfuse_public_key |
OTEL 端点的 API 密钥 | 环境变量 |
langfuse_secret_key |
OTEL 端点的密钥 | 环境变量 |
OTEL_EXPORTER_OTLP_ENDPOINT |
追踪端点 | https://cloud.langfuse.com/api/public/otel/v1/traces |
OTEL_EXPORTER_OTLP_HEADERS |
身份验证类型 | Basic |
DISABLE_ADOT_OBSERVABILITY |
Open Telemetry (ADOT) 的 AWS 分发版。此实现禁用 Agent Core 的默认可观测性,转而使用 Langfuse。 | True |
BEDROCK_MODEL_ID |
AWS Bedrock 模型 ID | us. anthropic.claude-3-7-sonnet-20250219-v1:0 |
第 5 步:检查部署状态
在调用之前,请等待运行时就绪:
import time status_response = agentcore_runtime.status() status = status_response.endpoint['status'] end_status = ['READY', 'CREATE_FAILED', 'DELETE_FAILED', 'UPDATE_FAILED'] while status not in end_status: time.sleep(10) status_response = agentcore_runtime.status() status = status_response.endpoint['status'] print(status) status成功的部署会显示智能体运行时的“就绪”状态。
第 6 步:调用 AgentCore 运行时
最后,使用有效载荷调用我们的 AgentCore 运行时。
invoke_response = agentcore_runtime.invoke({"prompt": "I'm planning a weekend trip to london. What are the must-visit places and local food I should try?"})AgentCore 运行时被调用后,用户应该能够在 Langfuse 仪表板中看到 Langfuse 追踪。
第 7 步:在 Langfuse 中查看追踪
运行智能体后,请访问 Langfuse 项目以查看详细的追踪。追踪内容包括:
- 智能体调用详情
- 工具调用(网络搜索)
- 带有延迟和令牌使用量的模型交互
- 请求/响应有效载荷
追踪和层次结构
Langfuse 捕获从用户请求到单个模型调用的所有交互。每个追踪都捕获完整的执行路径,包括 API 调用、函数调用和模型响应,从而形成一个全面的智能体活动时间线。追踪的嵌套结构使开发人员能够深入研究特定的交互,并在执行链的任何级别识别性能瓶颈或错误模式。为了进一步增强可观测性功能,Langfuse 提供了可以在智能体工作流程中实现的标记机制。
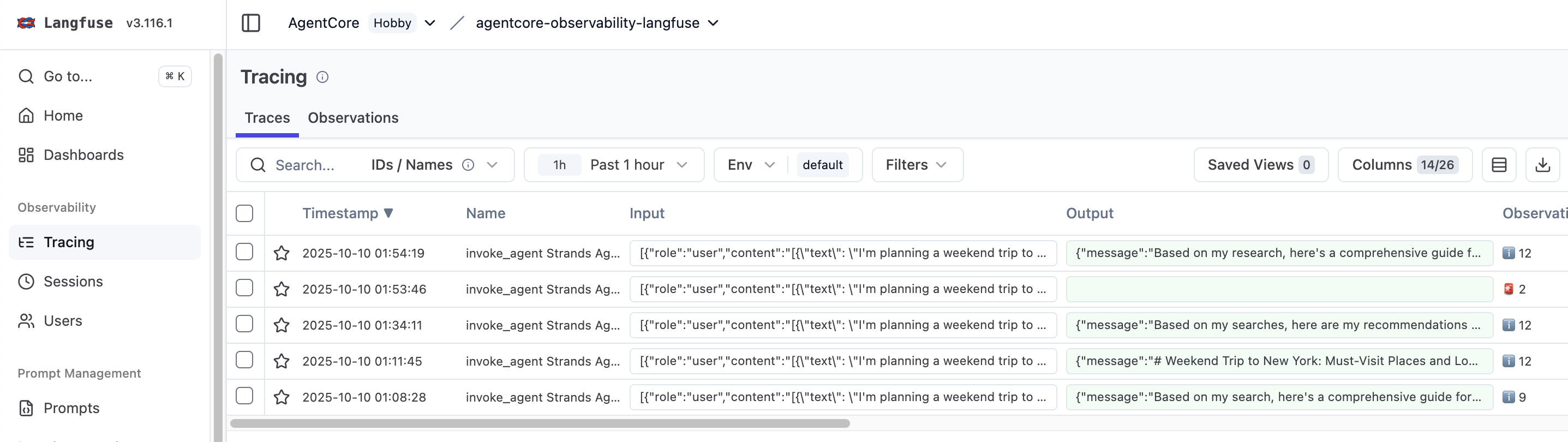
图 3:Langfuse 中的追踪
将分层追踪与战略性标记相结合,可以洞察智能体操作,从而实现数据驱动的优化和卓越的用户体验。如以下图像所示,开发人员可以深入了解其智能体执行流程中每个操作的确切时间。在前面的示例中,完整请求耗时 26.57 秒,其中对事件循环周期、工具调用和其他组件进行了单独的细分。利用此时间信息来查找性能瓶颈并减少响应时间。例如,某些 LLM 操作可能比预期的花费更长的时间,或者可能存在并行化特定操作以减少整体延迟的机会。通过利用这些见解,用户可以做出数据驱动的决策,以增强智能体的性能并提供更好的客户体验。
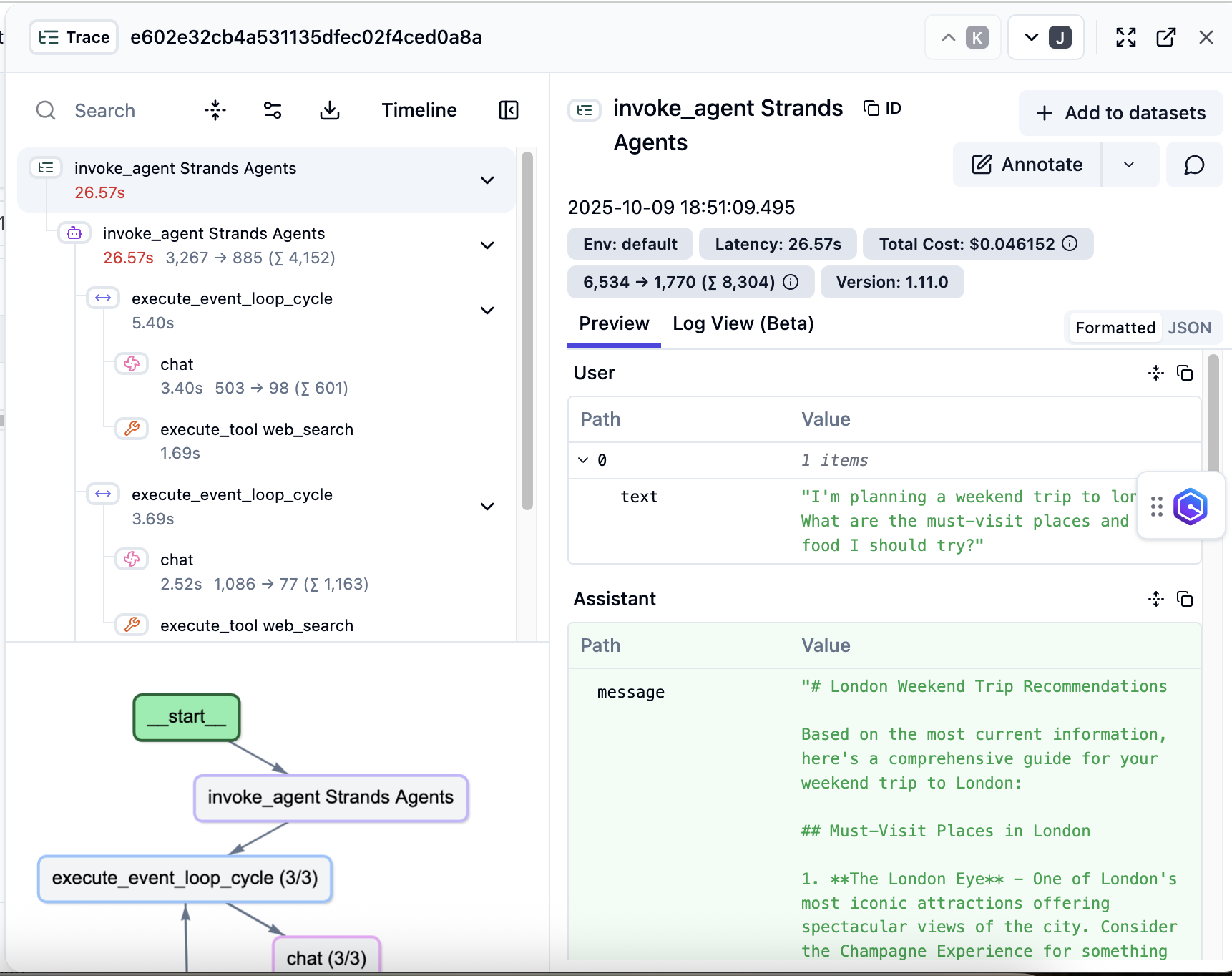
图 4:详细追踪层次结构
Langfuse 仪表板
Langfuse 仪表板提供三种不同的监控仪表板,包括成本、延迟和使用情况管理。
图 5:Langfuse 仪表板
成本监控
成本监控有助于跟踪聚合级别和单个请求级别的费用,以控制 AI 基础设施支出。该平台按模型、用户和函数调用提供详细的成本细分,使团队能够识别成本较高的操作并优化其实施。这种细粒度的成本可见性有助于在保持预算约束的同时,就模型选择、提示工程和资源分配做出数据驱动的决策。仪表板成本数据仅供估算;实际费用应通过官方账单进行核实。
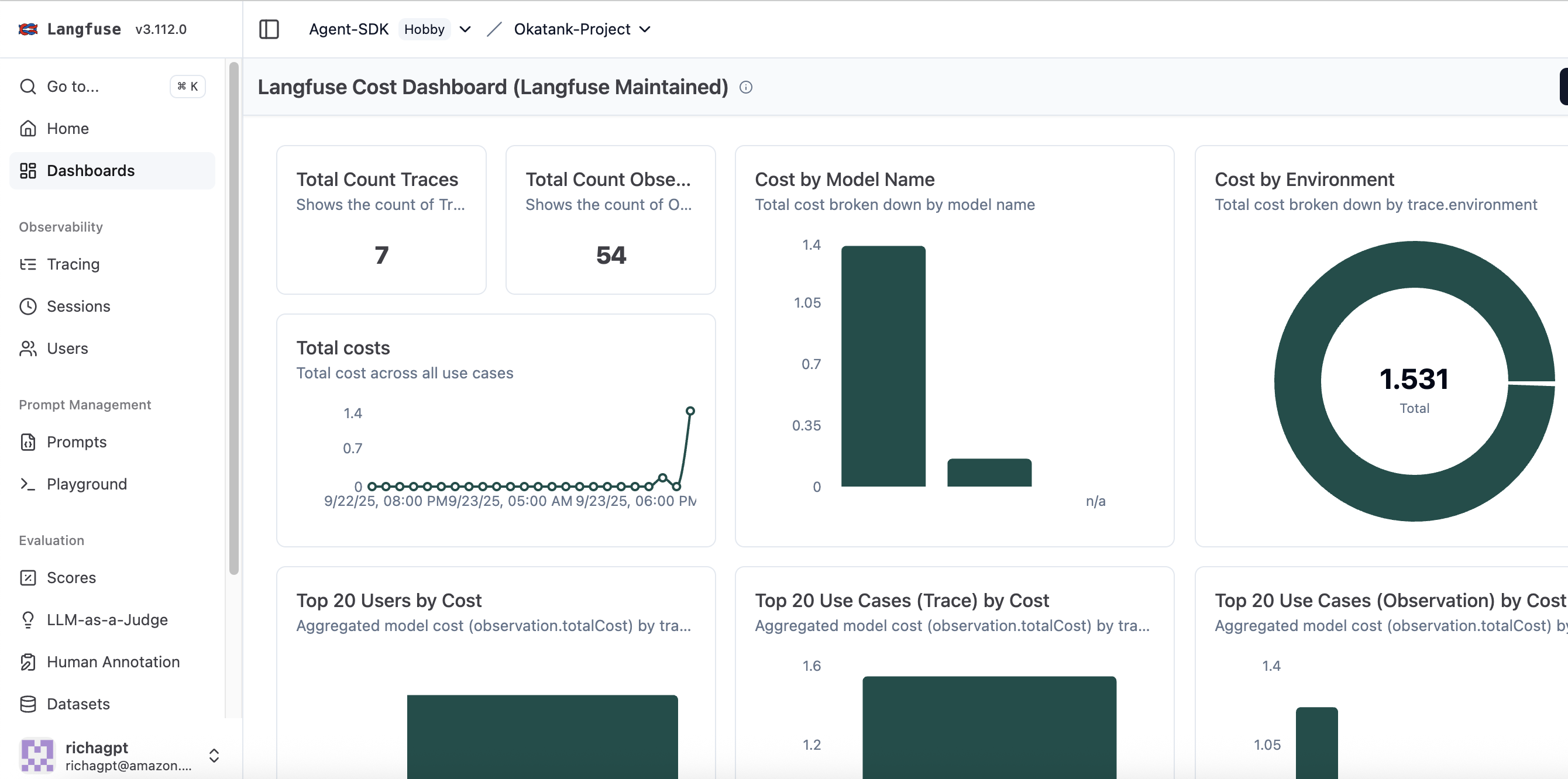
图 6:成本仪表板
Langfuse 延迟仪表板
可以跨追踪和生成情况来监控延迟指标以进行性能优化。仪表板默认显示以下指标,您可以根据需要创建自定义图表和仪表板:
- 按级别(观察结果)的 P95 延迟
- 按用例的 P95 延迟
- 按用户 ID 的最大延迟(追踪)
- 按提示名称的首个令牌平均时间(观察结果)
- 按模型的首个令牌 P95 时间
- 按模型的 P95 延迟
- 按模型的平均每秒输出令牌数
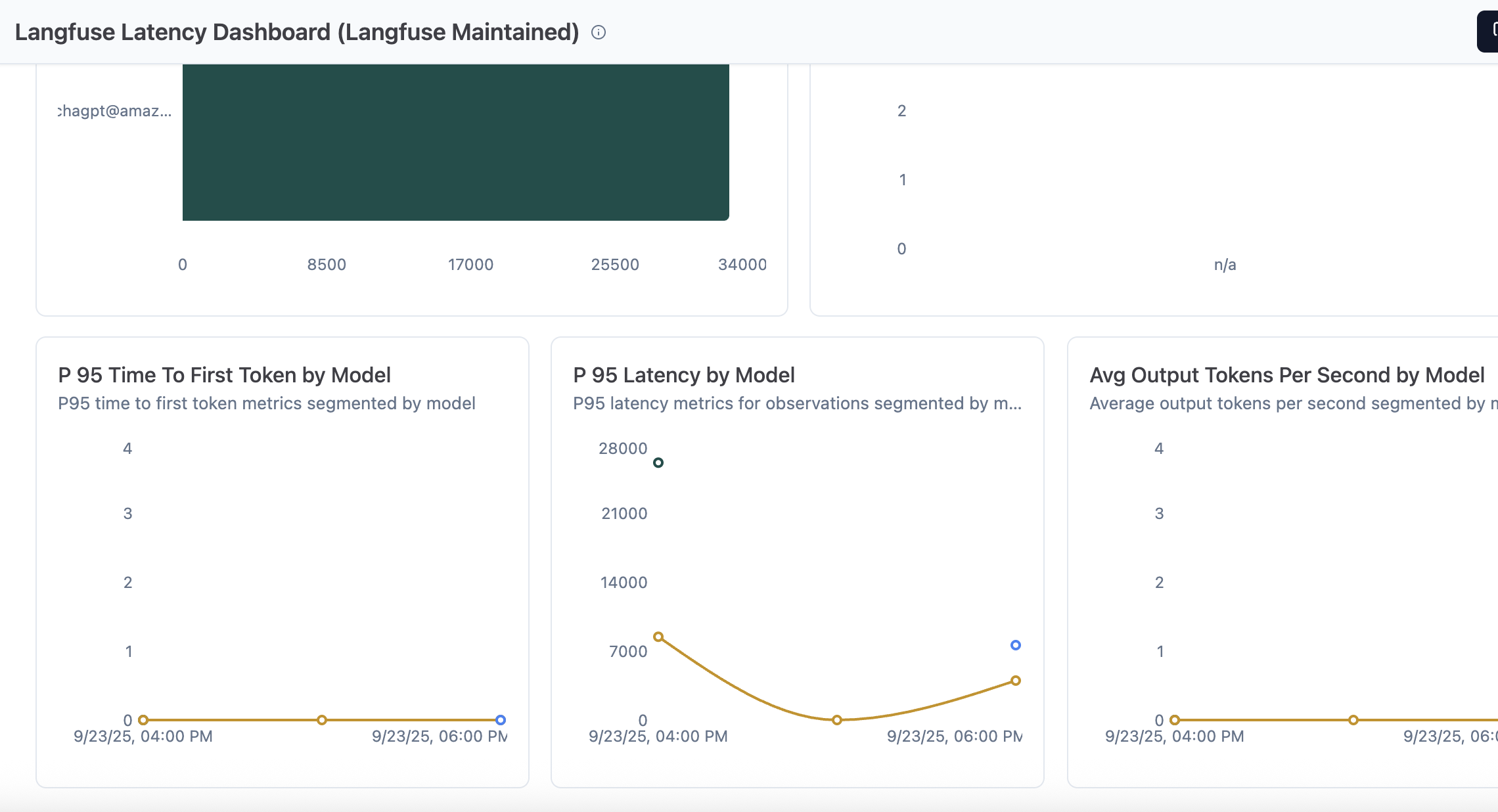
图 7:延迟仪表板
Langfuse 使用情况管理
此仪表板显示跨追踪、观察结果和分数的指标,以管理资源分配。
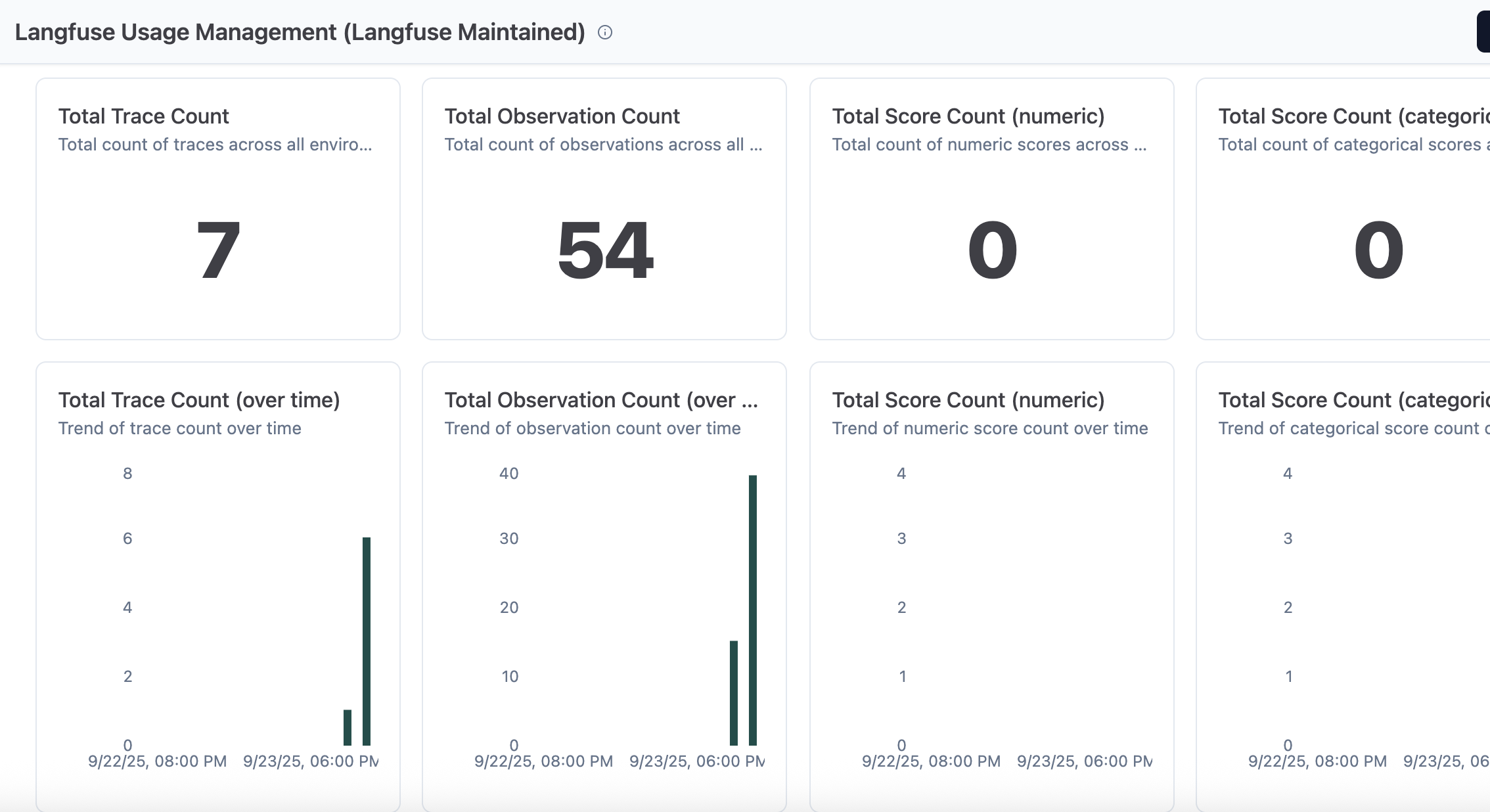
图 8:使用情况管理仪表板
结论
本文演示了如何将 Langfuse 与 AgentCore 集成,以实现 AI 智能体的全面可观测性。用户现在可以跨工作流程跟踪性能、调试交互和优化成本。我们预计未来会有更多的 Langfuse 可观测性功能和集成选项,以帮助扩展 AI 应用程序。
立即开始将 Langfuse 与 AgentCore 实施,以获得对智能体性能的更深入见解、跟踪对话流程并优化 AI 应用程序。有关更多信息,请访问以下资源:
- Amazon Bedrock AgentCore 常见问题
- Amazon Bedrock AgentCore 集成
- 跳过基础设施烦恼:使用 Bedrock AgentCore 在几分钟内部署生产级多智能体系统
关于作者
 Richa Gupta 是亚马逊云计算 (AWS) 的高级解决方案架构师,专注于 AI/ML、生成式 AI 和智能体 AI。她热衷于帮助客户进行 AI 转型之旅,架构端到端解决方案,从概念验证到生产部署,并推动业务收入。在她的专业追求之外,Richa 喜欢制作拿铁艺术,并且是一位冒险爱好者。
Richa Gupta 是亚马逊云计算 (AWS) 的高级解决方案架构师,专注于 AI/ML、生成式 AI 和智能体 AI。她热衷于帮助客户进行 AI 转型之旅,架构端到端解决方案,从概念验证到生产部署,并推动业务收入。在她的专业追求之外,Richa 喜欢制作拿铁艺术,并且是一位冒险爱好者。
 Ishan Singh 是亚马逊云计算 (AWS) 的高级生成式 AI 数据科学家,他与客户合作架构创新和负责任的生成式 AI 解决方案。凭借在 AI 和机器学习方面的深厚专业知识,Ishan 领导大规模生产级生成式 AI 解决方案的开发,重点关注评估和可观测性。在工作之余,他喜欢打排球、探索当地的自行车道,并与他的妻子、孩子和狗 Beau 共度时光。
Ishan Singh 是亚马逊云计算 (AWS) 的高级生成式 AI 数据科学家,他与客户合作架构创新和负责任的生成式 AI 解决方案。凭借在 AI 和机器学习方面的深厚专业知识,Ishan 领导大规模生产级生成式 AI 解决方案的开发,重点关注评估和可观测性。在工作之余,他喜欢打排球、探索当地的自行车道,并与他的妻子、孩子和狗 Beau 共度时光。
 Yanyan Zhang 是亚马逊云计算 (AWS) 的高级生成式 AI 数据科学家,她作为生成式 AI 专家致力于前沿的 AI/ML 技术,帮助客户利用生成式 AI 实现预期成果。Yanyan 以电气工程博士学位毕业于德克萨斯 A&M 大学。工作之余,她喜欢旅行、锻炼和探索新事物。
Yanyan Zhang 是亚马逊云计算 (AWS) 的高级生成式 AI 数据科学家,她作为生成式 AI 专家致力于前沿的 AI/ML 技术,帮助客户利用生成式 AI 实现预期成果。Yanyan 以电气工程博士学位毕业于德克萨斯 A&M 大学。工作之余,她喜欢旅行、锻炼和探索新事物。
 Madhu Samhitha 是亚马逊云计算 (AWS) 的专家解决方案架构师,专注于帮助客户实施生成式 AI 解决方案。她将自己对大型语言模型的知识与战略创新相结合,以提供业务价值。她拥有马萨诸塞大学阿默斯特分校的计算机科学硕士学位,并在各个行业工作过。在技术角色之外,Madhu 是一位受过古典舞训练的舞者、艺术爱好者,喜欢探索国家公园。
Madhu Samhitha 是亚马逊云计算 (AWS) 的专家解决方案架构师,专注于帮助客户实施生成式 AI 解决方案。她将自己对大型语言模型的知识与战略创新相结合,以提供业务价值。她拥有马萨诸塞大学阿默斯特分校的计算机科学硕士学位,并在各个行业工作过。在技术角色之外,Madhu 是一位受过古典舞训练的舞者、艺术爱好者,喜欢探索国家公园。
 Marc Klingen 是开源 LLM 工程平台 Langfuse 的联合创始人兼首席执行官。在 2023 年与联合创始人一起构建 LLM 智能体之后,Marc 和团队意识到需要新的工具才能将智能体投入生产并可靠地扩展它们。有了 Langfuse,他们构建了领先的开源 LLM 工程平台(可观测性、评估、提示词管理),拥有超过 18,000 个 GitHub star、每月 14.8M+ SDK 安装量和 6M+ Docker 拉取量。Langfuse 被 Khan Academy、Samsara、Twilio 和 Merck 等顶级工程团队使用。
Marc Klingen 是开源 LLM 工程平台 Langfuse 的联合创始人兼首席执行官。在 2023 年与联合创始人一起构建 LLM 智能体之后,Marc 和团队意识到需要新的工具才能将智能体投入生产并可靠地扩展它们。有了 Langfuse,他们构建了领先的开源 LLM 工程平台(可观测性、评估、提示词管理),拥有超过 18,000 个 GitHub star、每月 14.8M+ SDK 安装量和 6M+ Docker 拉取量。Langfuse 被 Khan Academy、Samsara、Twilio 和 Merck 等顶级工程团队使用。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区