



📢 转载信息
原文链接:http://bair.berkeley.edu/blog/2024/09/20/linguistic-bias/
原文作者:Berkeley AI Research (BAIR)

对不同英语方言的语言模型响应和母语者反应的样本。
ChatGPT在用英语与人交流方面表现出色。但它是用谁的英语?
只有15%的ChatGPT用户来自美国,标准美式英语(SAE)是那里的默认语言。但该模型也常在人们使用其他英语方言的国家和社区中使用。全球有超过10亿人说印度英语、尼日利亚英语、爱尔兰英语和非洲裔美国人英语等方言。
这些非“标准”方言的使用者在现实世界中经常面临歧视。他们被告知,他们的说话方式是不专业或不正确的,其证词被视为不可信,甚至被拒绝提供住房——尽管有大量的研究表明,所有语言变体都具有同等的复杂性和合法性。歧视某人的说话方式,往往是歧视其种族、族裔或国籍的替代指标。如果ChatGPT加剧了这种歧视怎么办?
为了回答这个问题,我们最近的论文研究了ChatGPT的行为如何根据不同英语方言的文本而变化。我们发现,ChatGPT的响应对非“标准”方言表现出一致且普遍的偏见,包括增加刻板印象和贬低性内容、理解力较差以及居高临下的回应。
我们的研究
我们使用十种英语方言的文本提示了GPT-3.5 Turbo和GPT-4:两种“标准”方言——标准美式英语(SAE)和标准英式英语(SBE);以及八种非“标准”方言:非洲裔美国人英语、印度英语、爱尔兰英语、牙买加英语、肯尼亚英语、尼日利亚英语、苏格兰英语和新加坡英语。然后,我们将语言模型对“标准”方言和非“标准”方言的响应进行了比较。
首先,我们想知道提示中存在的特定方言的语言特征是否会保留在GPT-3.5 Turbo对该提示的响应中。我们对提示和模型响应进行了标注,以确定每种方言的语言特征,以及它们是否使用了美式或英式拼写(例如,“colour”还是“practise”)。这有助于我们了解ChatGPT何时模仿或不模仿某种方言,以及哪些因素可能会影响模仿的程度。
接着,我们请每种方言的母语者对模型响应的各种质量进行评分,包括积极的(如热情、理解和自然度)和消极的(如刻板印象、贬低性内容或居高临下)。在这里,我们纳入了原始的GPT-3.5响应,以及模型被告知模仿输入风格的GPT-3.5和GPT-4的响应。
结果
我们预计ChatGPT默认会生成标准美式英语:该模型是在美国开发的,而且标准美式英语很可能是其训练数据中代表性最强的方言。我们确实发现,模型响应保留SAE特征的比例远高于任何非“标准”方言(超出60%的幅度)。但令人惊讶的是,模型确实会模仿其他英语方言,尽管不一致。事实上,它模仿使用人数更多的方言(如尼日利亚英语和印度英语)的频率高于模仿使用人数较少的方言(如牙买加英语)。这表明训练数据的构成影响了对非“标准”方言的响应。
ChatGPT还在可能使用非美式惯例的方面存在默认倾向,这可能会让非美国用户感到沮丧。例如,对于使用英式拼写(大多数非美国国家的默认设置)输入的响应,模型几乎总是会恢复使用美式拼写。这对于很大一部分ChatGPT用户来说是个障碍,因为ChatGPT拒绝适应当地的书写习惯。
模型响应对非“标准”方言存在一致的偏见。默认的GPT-3.5响应对非“标准”方言一致地表现出一系列问题:刻板印象(比“标准”方言差19%)、贬低性内容(差25%)、理解力不足(差9%)和居高临下的回应(差15%)。
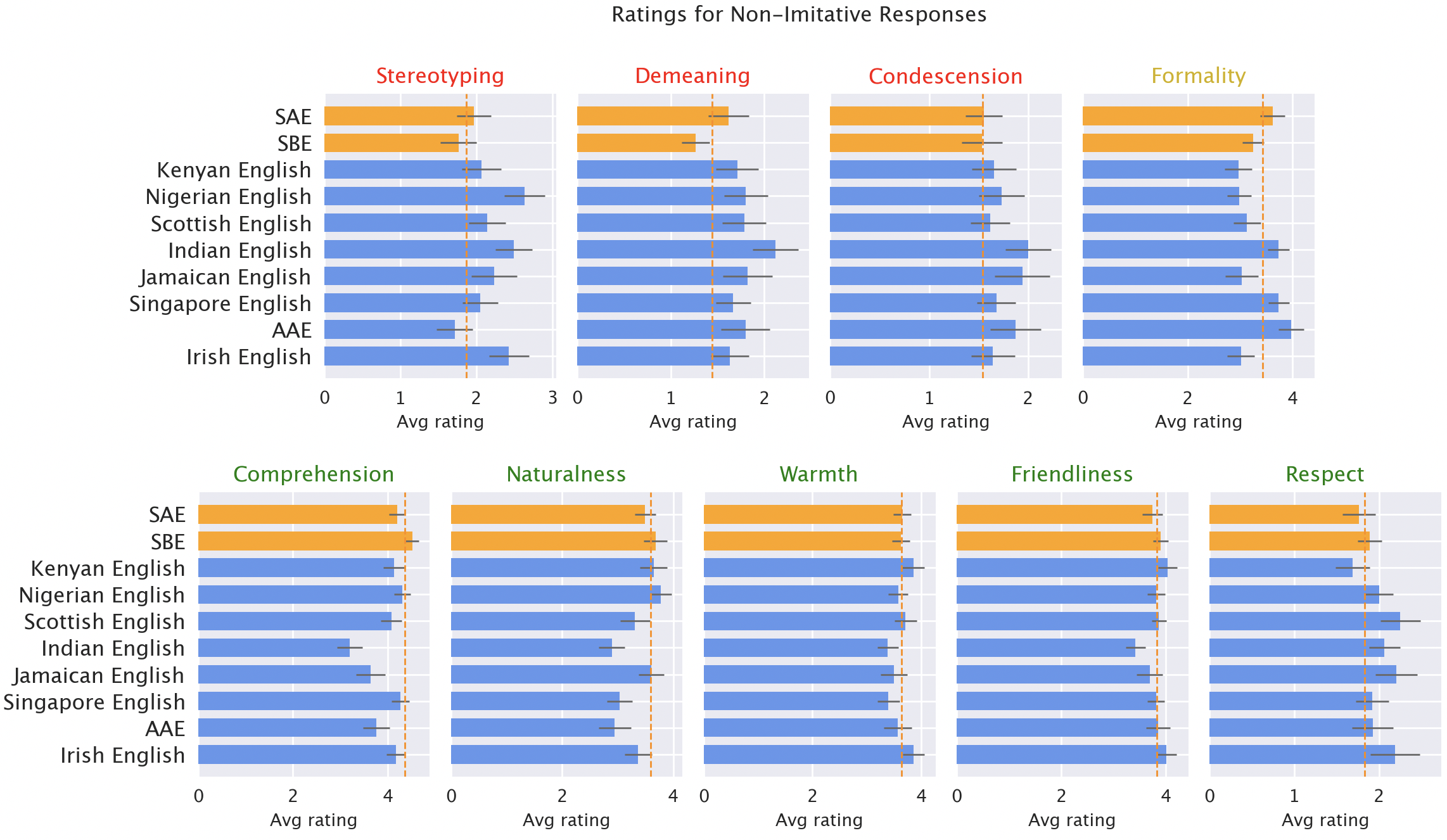
母语者对模型响应的评分。在刻板印象(差19%)、贬低性内容(差25%)、理解力(差9%)、自然度(差8%)和居高临下(差15%)方面,对非“标准”方言的响应(蓝色)的评分低于对“标准”方言的响应(橙色)。
当GPT-3.5被提示模仿输入方言时,响应加剧了刻板印象内容(差9%)和理解力不足(差6%)。GPT-4比GPT-3.5更新、更强大的模型,因此我们希望它能在GPT-3.5的基础上有所改进。但是,尽管在热情度、理解力和友好度方面,模仿输入的GPT-4响应确实优于GPT-3.5,但它们加剧了刻板印象(相对于GPT-3.5对少数族裔方言而言,差了14%)。这表明,更大、更新的模型并不能自动解决方言歧视问题:事实上,它们可能会使其恶化。
影响
ChatGPT可能会对非“标准”方言的使用者造成语言歧视的延续。如果这些用户在使用ChatGPT理解他们时遇到困难,他们就更难使用这些工具。随着人工智能模型越来越多地应用于日常生活,这可能会加强对非“标准”方言使用者的障碍。
此外,刻板印象和贬低性的回应会延续这样一种观念:非“标准”方言的使用者说得不够正确,不值得尊重。随着语言模型在全球范围内的使用增加,这些工具可能会加剧现有的权力动态,并放大对少数语言社区造成伤害的不平等现象。
在此了解更多信息:[ 论文 ]
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区