



📢 转载信息
原文作者:Stefano Buliani
今天,我们发布了一个新的开源示例聊天机器人,它展示了如何使用自动化推理检查(Automated Reasoning checks)的反馈来迭代生成的内容、提出澄清问题,并证明答案的正确性。
该聊天机器人的实现还生成了一个审计日志,其中包含对答案有效性的数学上可验证的解释,以及一个用户界面,向开发人员展示幕后发生的迭代重写过程。自动化推理检查使用逻辑推理来自动证明一个陈述是正确的。与大型语言模型(LLM)不同,自动化推理工具不是在猜测或预测准确性。相反,它们依赖于数学证明来验证是否符合策略。本文将深入探讨自动化推理检查重写聊天机器人的实现架构。
使用自动化推理检查提高准确性和透明度
LLM 有时会生成听起来很有说服力但包含事实错误的响应——这种现象被称为“幻觉”。自动化推理检查可以验证用户的提问和 LLM 生成的答案,根据编码在自动化推理策略中的基础事实知识,提供有关模糊陈述、过于宽泛的断言和事实错误声明的重写反馈。
一个使用自动化推理检查来迭代其答案的聊天机器人,在向用户呈现之前,有助于提高准确性,因为它能够做出明确回答用户是非题的精确陈述,不留模糊空间;并且有助于提高透明度,因为它能够提供数学上可验证的证明来说明其陈述为何正确,从而使生成式 AI 应用在受监管环境中也具有可审计性和可解释性。
了解了这些好处后,让我们深入探讨如何在自己的应用程序中实现它。
聊天机器人参考实现
该聊天机器人是一个 Flask 应用程序,它暴露了用于提交问题和检查答案状态的 API。为了展示系统的内部工作原理,这些 API 还允许您检索有关每次迭代的状态、来自自动化推理检查的反馈以及发送给 LLM 的重写提示的信息。
您可以使用前端 NodeJS 应用程序从 Amazon Bedrock 配置 LLM 以生成答案,选择自动化推理策略进行验证,并设置更正答案的最大迭代次数。在用户界面中选择一个聊天线程会打开右侧的调试面板,其中显示了内容的每一次迭代和验证输出。
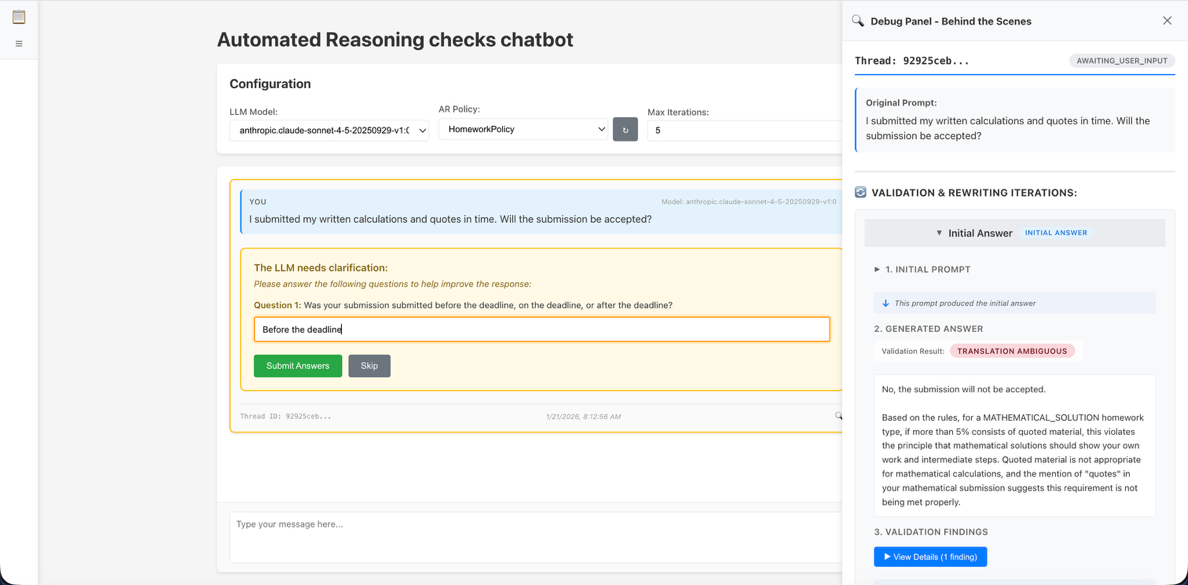
图 1 – 带调试面板的聊天界面
一旦自动化推理检查确认响应有效,就会显示该有效性的可验证解释。
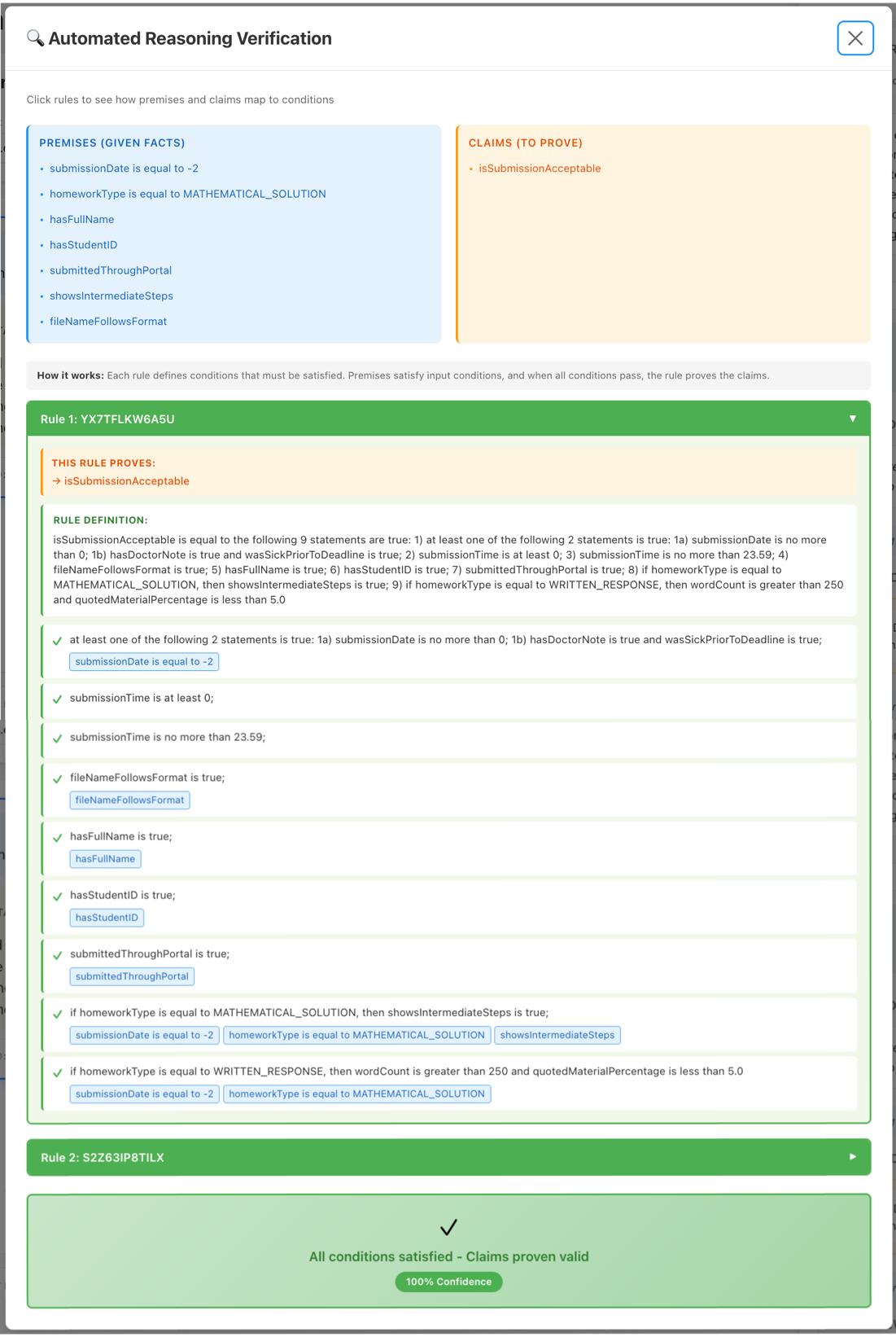
图 2 – 自动化推理检查有效性证明
迭代重写循环的工作原理
该开源参考实现通过根据自动化推理检查的反馈进行迭代和重写响应,自动帮助改进聊天机器人的答案。当被要求验证聊天机器人问答(Q&A)时,自动化推理检查会返回一个发现列表。每个发现代表在输入问答中识别出的一个独立逻辑陈述。例如,对于问答:“S3 存储的费用是多少?在 US East (N. Virginia),S3 对前 50Tb 的费用是 $0.023/GB;在 Asia Pacific (Sydney),S3 对前 50Tb 的费用是 $0.025/GB”,自动化推理检查将生成两个发现,一个验证 us-east-1 的价格是 $0.023,另一个验证 ap-southeast-2 的价格。
在解析问答的发现时,自动化推理检查会将输入分解为一个事实前提列表和针对这些前提提出的声明。前提可以是用户问题中的一个事实陈述,如“我是一名位于弗吉尼亚的 S3 用户”,也可以是答案中列出的一个假设,如“对于发送到 us-east-1 的请求…”。声明代表正在验证的陈述。在我们前一段的 S3 定价示例中,区域(Region)将是一个前提,而价格点(price point)将是一个声明。
每个发现都包含一个验证结果(VALID、INVALID、SATISFIABLE、TRANSLATION_AMBIGUOUS、IMPOSSIBLE)以及重写答案以使其变为 VALID 所需的反馈。反馈根据验证结果而变化。例如,模糊的发现包含输入的两种解释,可满足的发现包含两种情况,表明声明在某些情况下可能为真,在其他情况下可能为假。您可以在我们的 API 文档中查看可能的发现类型。
有了这些背景知识,我们可以深入了解参考实现的工作原理:
初始响应和验证
当用户通过 UI 提交问题时,应用程序首先调用配置的 Bedrock LLM 来生成答案,然后调用 ApplyGuardrail API 来验证问答。
使用 ApplyGuardrail 响应中自动化推理检查的输出,应用程序进入一个循环,在其中每次迭代都会检查自动化推理检查的反馈,执行一个动作(例如,要求 LLM 根据反馈重写答案),然后再次调用 ApplyGuardrail 来验证更新后的内容。
重写循环(系统的核心)
在初始验证之后,系统使用自动化推理检查的输出来决定下一步。首先,它根据优先级对发现进行排序——优先处理最重要的:TRANSLATION_AMBIGUOUS、IMPOSSIBLE、INVALID、SATISFIABLE、VALID。然后,它选择优先级最高的发现,并使用以下逻辑对其进行处理。由于 VALID 位于优先列表的末尾,系统只有在解决了其他发现之后才会接受为 VALID。
- 对于
TRANSLATION_AMBIGUOUS发现,自动化推理检查返回输入文本的两种解释。对于SATISFIABLE发现,自动化推理检查返回两种情况,证明和证否了这些声明。利用这些反馈,应用程序会要求 LLM 决定是尝试重写答案以澄清歧义,还是向用户提出后续问题以收集更多信息。例如,SATISFIABLE反馈可能说明 $0.023 的价格仅在区域为 US East (N. Virginia) 时有效。LLM 可以利用此信息来询问应用程序所在的区域。当 LLM 决定提出后续问题时,循环会暂停,等待用户回答问题,然后 LLM 根据澄清内容重新生成答案,循环重新开始。 - 对于
IMPOSSIBLE发现,自动化推理检查会返回与其前提(输入内容中接受的事实)相矛盾的规则列表。利用这些反馈,应用程序会要求 LLM 重写答案,以避免逻辑不一致。 - 对于
INVALID发现,自动化推理检查会返回基于前提和策略规则使声明无效的自动化推理策略中的规则。利用这些反馈,应用程序会要求 LLM 重写其答案,使其与规则保持一致。 - 对于
VALID发现,应用程序退出循环并将答案返回给用户。
在每次答案重写之后,系统都会将问答发送到 ApplyGuardrail API 进行验证;循环的下一次迭代从该调用的反馈开始。每次迭代都会将发现和提示与完整上下文存储在线程数据结构中,从而创建了系统如何得出最终答案的审计跟踪。
开始使用自动化推理检查重写聊天机器人
要试用我们的参考实现,第一步是创建一个自动化推理策略:
- 在 AWS 管理控制台中,导航到美国或欧洲支持的区域中的 Amazon Bedrock。
- 从左侧导航中,在 Build 类别下打开 Automated Reasoning 页面。
- 使用 Create policy 按钮的下拉菜单,选择 Create sample policy。
- 输入策略的名称,然后在页面底部选择 Create policy。
创建策略后,您可以继续下载并运行参考实现:
- 克隆 Amazon Bedrock Samples 仓库。
- 按照 README 文件中的说明安装依赖项、构建前端并启动应用程序。
- 使用您喜欢的浏览器导航到 http://localhost8080 并开始测试。
后端实现细节
如果您计划将此实现改编用于生产环境,本节将介绍后端架构中的关键组件。您可以在仓库的 backend 目录(backend)中找到这些组件。
- ThreadManager(线程管理器):协调对话生命周期管理。它处理对话线程的创建、检索和状态跟踪,在整个重写过程中维护正确的状态。ThreadManager 使用锁实现线程安全操作,以帮助防止多个操作同时尝试修改同一对话时发生的竞争条件。它还会跟踪等待用户输入的线程,并能识别超出可配置超时限制的陈旧线程。
- ThreadProcessor(线程处理器):使用状态机模式来处理重写循环,以实现清晰、可维护的控制流。处理器管理
GENERATE_INITIAL、VALIDATE、CHECK_QUESTIONS、HANDLE_RESULT和REWRITING_LOOP等阶段之间的状态转换,使对话在每个阶段正确推进。 - ValidationService(验证服务):与 Amazon Bedrock Guardrails 集成。该服务接收每个 LLM 生成的响应,并使用
ApplyGuardrailAPI 提交验证。它处理与 AWS 的通信,为瞬态故障管理带有指数退避的重试逻辑,并将验证结果解析为结构化发现。 - LLMResponseParser(LLM 响应解析器):在重写循环期间解释 LLM 的意图。当系统要求 LLM 修复无效响应时,模型必须决定是尝试重写(
REWRITE)、提出澄清问题(ASK_QUESTIONS),还是由于前提矛盾而宣布任务不可能(IMPOSSIBLE)。解析器会检查 LLM 响应中的特定标记,如 “DECISION:”、“ANSWER:” 和 “QUESTION:”,从自然语言输出中提取结构化信息。它能优雅地处理 Markdown 格式,并对问题数量(最多 5 个)进行限制。 - AuditLogger(审计日志记录器):将结构化 JSON 日志写入专用的审计日志文件,记录两种关键事件类型:当响应通过验证时记录
VALID_RESPONSE,当系统用完设定的重试次数时记录MAX_ITERATIONS_REACHED。每个审计条目捕获时间戳、线程 ID、提示、响应、模型 ID 和验证发现。日志记录器还会从澄清迭代中提取并记录问答交换,包括用户是否回答了或跳过了这些问题。
这些组件共同构成了一个强大的基础,用于构建可信赖的 AI 应用程序,这些应用将大型语言模型的灵活性与数学验证的严谨性结合起来。
有关在生产环境中实现自动化推理检查的详细指南:
- 研讨会: 使用自动化推理检查实现生成式 AI 可靠性
- 技术博客: 使用 Amazon Bedrock 自动化推理检查最大限度地减少生成式 AI 幻觉
- 用例博客: 使用 Amazon Bedrock Guardrails 的自动化推理检查,为金融服务工作流程构建可验证的可解释性
- 文档: Amazon Bedrock Guardrails 用户指南
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区