



📢 转载信息
原文作者:Ahmed Raafat and Kiranpreet Chawla
随着组织扩展其生成式AI的实施,平衡质量、成本和延迟这一关键挑战变得日益复杂。由于推理成本占大型语言模型(LLM)运营支出的70%到90%,而冗长的提示策略会使Token量膨胀3到5倍,组织正在积极寻求更高效的模型交互方法。传统的提示方法虽然有效,但通常会产生不必要的开销,影响成本效率和响应时间。
本文探讨了草稿链 (Chain-of-Draft, CoD),这是一种在Zoom AI Research论文Chain of Draft: Thinking Faster by Writing Less中介绍的创新提示技术,它彻底改变了模型处理推理任务的方式。虽然思维链 (Chain-of-Thought, CoT) 提示一直是增强模型推理的首选方法,但CoD提供了一种更高效的替代方案,它模仿了人类解决问题的方式——使用简洁、高信号的思维步骤,而不是冗长的解释。
我们使用Amazon Bedrock和AWS Lambda,演示了CoD的实际实现,该实现可以带来显著的效率提升:Token使用量最多可减少75%,延迟降低超过78%,同时保持与传统CoT方法相当的准确性水平。通过详细的示例、代码片段和性能指标,我们展示了如何在AWS环境中部署CoD并衡量其对AI实施的影响。这种方法不仅优化了成本,还通过更快的响应时间提升了整体用户体验。
理解思维链提示
思维链 (Chain-of-Thought, CoT) 提示是一种引导大型语言模型逐步解决问题,而不是直接跳到答案的技术。这种方法在处理复杂的任务(如逻辑谜题、数学问题和常识推理场景)时特别有效。通过模仿人类解决问题的方式,CoT帮助模型将复杂问题分解为可管理的步骤,从而提高准确性和透明度。
CoT提示示例:
问题:有5个苹果,你吃了2个,还剩多少个苹果?
CoT回答:从5个苹果开始。我吃了2个苹果。从5中减去2。5 – 2 = 3个苹果剩余。
然而,如上例所示,这种方法在生产环境中存在一些缺点。CoT响应的冗长性会导致Token使用量增加和成本升高。生成详细解释所需的处理时间延长会导致延迟增加,在某些情况下使其不太适合实时应用。此外,详细的输出会使下游处理和与其他系统的集成变得复杂。
介绍草稿链提示
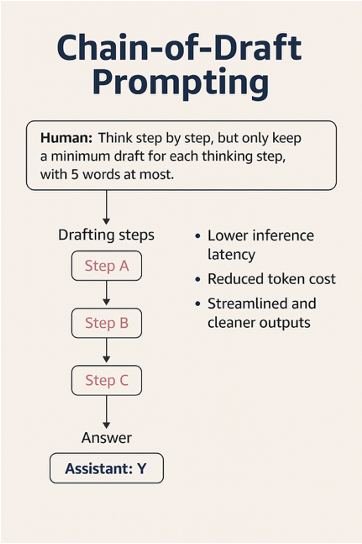
草稿链 (Chain-of-Draft, CoD) 是一种新颖的提示技术,旨在通过限制每个推理步骤中使用的词数来减少冗长性,仅关注进展所需的基本计算或转换,同时显著减少Token使用量和推理延迟。CoD的灵感来源于人类如何通过简短的笔记而不是冗长的解释来解决问题——鼓励LLM生成紧凑、高信号的推理步骤。
CoD的关键创新在于其约束:每个推理步骤限制为五个词或更少。这一限制迫使模型专注于必要的逻辑组件,同时最大限度地减少不必要的冗余。例如,在解决数学文字题时,CoD不会生成解释每一步的完整句子,而是生成简洁的数值运算和关键逻辑标记。
考虑以下示例:
问题:Jason有20个棒棒糖。他给了Denny一些棒棒糖。现在Jason剩下12个棒棒糖。Jason给了Denny多少个棒棒糖?
CoT响应可能包含几句话来解释推理过程,例如,“Jason有20个棒棒糖。他给了Denny一些,现在剩下12个。所以他送出了8个。”
相比之下,CoD响应可能只是简单地陈述:“开始:20,结束:12,20 – 12 = 8。”
这种极简主义方法实现了相同的逻辑推理,但使用的Token量却少得多。
为什么CoD有效
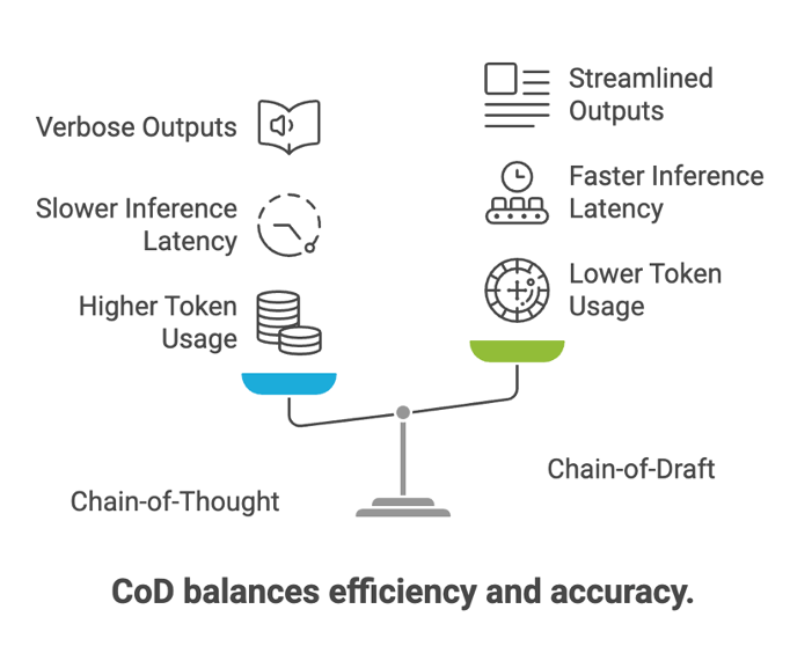
CoD背后的关键思想是大多数推理链都存在高度冗余。通过将步骤提炼到其语义核心,CoD帮助模型专注于任务的逻辑结构,而不是语言流畅性。这导致了更短的输出带来的更低的推理延迟,更少的生成内容带来的更低的Token成本,以及更清晰的输出,便于下游解析或自动化。
这种极简主义的实现并没有牺牲准确性。事实上,根据原始Zoom AI论文,CoD在GSM8K上的准确率达到了91.4%(CoT为95.3%),同时将输出Token减少了高达92.1%,并将延迟在测试的几款模型中缩短了近一半。”
在底层,CoD技术使用自然语言提示指示模型“一步一步思考”,同时明确限制每个推理步骤的长度:“只为每个思考步骤保留一个最小的草稿,最多5个词。”
研究人员发现,像GPT-4、Claude和Cohere Command R+这样的模型在这些约束下表现尤为出色,尤其是在使用少量样本示例来演示简洁推理模式时。
CoD在常识推理任务中的表现
除了算术任务,CoD在常识推理任务中也表现出色。在原始Zoom AI论文中,作者使用big-bench基准测试(特别是侧重于日期理解和体育理解任务)对CoD进行了评估。评估中使用了与算术评估中相同的系统提示,以保持跨实验的一致性。结果显示,CoD不仅显著减少了Token生成和延迟,而且在某些情况下,其准确性超过了CoT——尤其是在不需要冗长输出时。
一个值得注意的发现是,在一个关于体育理解任务的大型语言模型上:CoT产生了冗长、啰嗦的响应,平均输出Token为172.5个,而CoD将其减少到31.3个Token,实现了约82%的减少。有趣的是,准确性略有提高,这表明在词语更少的情况下,CoD可能更有效。
以下是来自原始论文的快照,显示了对两个LLM的评估结果:
| 模型 | 提示 | 准确率 | Token | 延迟 |
| LLM-1 | 标准 | 72.60% | 5.2 | 0.6s |
| 思维链 | 90.20% | 75.7 | 1.7s | |
| 草稿链 | 88.10% | 30.2 | 1.3s | |
| LLM-2 | 标准 | 84.30% | 5.2 | 1.0s |
| 思维链 | 87% | 172.5 | 3.2s | |
| 草稿链 | 89.70% | 31.3 | 1.4s |
表 1. 日期理解评估结果。(草稿链:通过少写实现更快思考)
这些结果进一步验证了CoD在现实世界的推理场景中的价值,表明模型可以用更少、更智能的Token有效地进行推理。这对生产应用的影响是明确的:更快的响应和更低的成本,而无需牺牲质量。
在下一节中,我们将展示如何使用Amazon Bedrock和AWS Lambda实现此提示策略,以及CoD在真实世界条件下与基础模型上的CoT相比的表现。
在AWS上进行实施和评估
为了评估CoD提示技术的效率,我们在Amazon Bedrock中进行测试,并使用LLM解决“红、蓝、绿球”谜题。
谜题:你有三个盒子。每个盒子包含三个球,但球的颜色可以是红色、蓝色或绿色。盒子1标签为“仅限红球”。盒子2标签为“仅限蓝球”。盒子3标签为“红蓝球”。所有标签都是错误的。任务是:在只从一个盒子中取出一个球并观察其颜色后,推断出所有三个盒子的内容。
我们选择这个谜题是因为解决它需要可衡量的Token数量,因为问题需要分解为多个逻辑步骤,每个步骤都需要LLM处理和保留信息。LLM需要处理“if-then”语句并考虑导致逻辑推理的不同可能性。最后,LLM还需要在整个推理过程中保持谜题的上下文,并理解颜色、标签和球之间的符号和关系。
先决条件
要在Amazon Bedrock中测试和比较提示技术,请验证您是否具备以下先决条件:
- 具有创建和执行Lambda函数的权限的AWS账户
- 在AWS区域(例如us-east-1)中启用了Amazon Bedrock访问,并为模型(例如Model-1和Model-2)启用了模型访问;选择任何您喜欢的模型
- 用于Lambda函数执行的AWS IAM角色
- 调用Amazon Bedrock模型的权限(bedrock:Converse)
- 向Amazon CloudWatch中放入自定义指标的权限(cloudwatch:PutMetricData)
- (可选)用于日志记录的CloudWatch Logs权限
- 必要的Python库(boto3),包含在Python 3.9或更高版本的AWS Lambda运行时环境中
使用Amazon Bedrock Converse API进行评估
我们首先创建一个Python Lambda函数,旨在通过Amazon Bedrock与模型交互以解决该谜题。此AWS Lambda函数使用Amazon Bedrock Converse API,它提供了一个统一、一致的接口来与各种基础模型进行交互。Converse API简化了向模型发送会话消息并接收其回复的过程,支持多轮对话和高级功能,同时管理AWS身份验证和基础设施。Lambda函数初始化Amazon Bedrock运行时和CloudWatch的客户端,并将一个静态谜题提示作为用户消息发送给Converse API,检索响应文本,并计算输入和输出的延迟和Token使用情况。这些指标发布到CloudWatch,并记录相关日志。最后,函数返回模型的答案以及输入/输出Token计数。错误被记录并以适当的HTTP错误代码返回。
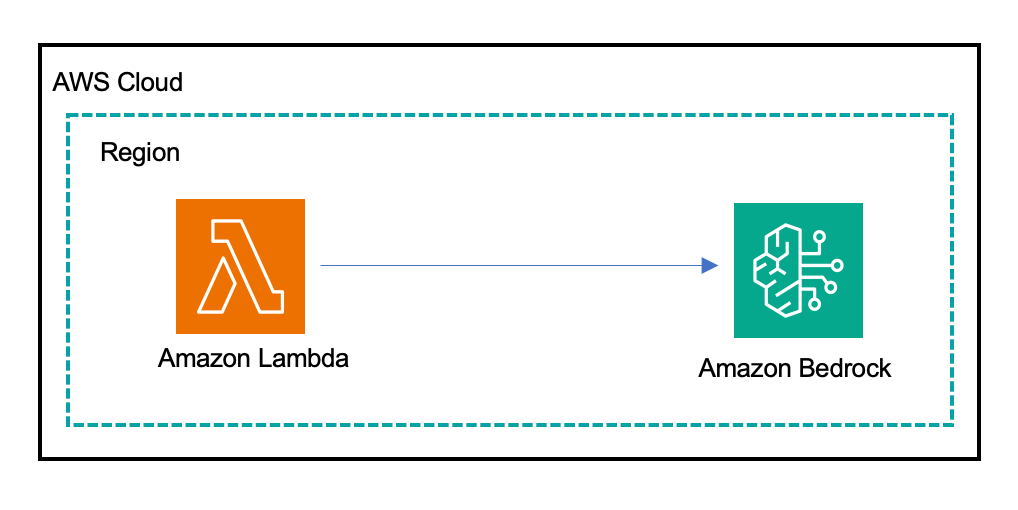
Lambda 函数
import json
import boto3
import time
import logging
from botocore.exceptions import ClientError
logger = logging.getLogger()
logger.setLevel(logging.INFO)
bedrock = boto3.client('bedrock-runtime', region_name='us-east-1')
cloudwatch = boto3.client('cloudwatch')
MODEL_ID = "model1-id" # Replace with actual Model 1 ID
PROMPT = (
"You have three boxes. Each box contains three balls, but the balls can be red, blue, or green. "
"Box 1 is labeled as 'Red Balls Only'. Box 2 is labeled 'Blue Balls Only'. "
"Box 3 is labeled 'Red and Blue Balls Only'. The labels on the boxes are all incorrect. "
"The Task: You must determine the contents of each box, knowing that all labels are incorrect. "
"You can only take a single ball from one box and observe its color. "
"Then you must deduce the contents of all three boxes. "
"Think step by step to answer the question, but only keep a minimum draft for each thinking step, with 5 words at most. "
"Return the answer at the end of the response after separator ###."
)
def lambda_handler(event, context):
conversation = [{"role": "user", "content": [{"text": PROMPT}]}]
start_time = time.time()
try:
response = bedrock.converse(
modelId=MODEL_ID,
messages=conversation,
inferenceConfig={"maxTokens": 2000, "temperature": 0.7}
)
response_text = response["output"]["message"]["content"][0]["text"]
latency = time.time() - start_time
input_tokens = len(PROMPT.split())
output_tokens = len(response_text.split())
cloudwatch.put_metric_data(
Namespace='ChainOfDraft',
MetricData=[
{"MetricName": "Latency", "Value": latency, "Unit": "Seconds"},
{"MetricName": "TokensUsed", "Value": input_tokens + output_tokens, "Unit": "Count"},
]
)
logger.info({
"request_id": context.aws_request_id,
"latency_seconds": round(latency, 2),
"total_tokens": input_tokens + output_tokens
})
return {
"statuscode": 200,
"body": json.dumps({
"response": response_text,
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"metrics": {
"latency_seconds": round(latency, 2),
"total_tokens": input_tokens + output_tokens,
},
}),
}
except ClientError as e:
logger.error(f"AWS service error: {e}")
return {"statuscode": 500, "body": json.dumps("Service error occurred")}
except Exception as e:
logger.error(f"Unexpected error: {e}")
return {"statusCode": 500, "body": json.dumps(f"Internal error occurred: {e}")}
如果您使用的是模型2,请将上述代码中的MODEL_ID更改为模型2的ID。其余代码保持不变。
测试
以下是用于测试Lambda函数的三个提示:更改Lambda函数中的PROMPT即可测试提示技术。
标准提示:
“你有三个盒子。每个盒子包含三个球,但球的颜色可以是红色、蓝色或绿色。盒子1标签为“仅限红球”。盒子2标签为“仅限蓝球”。盒子3标签为“红蓝球”。所有标签都是错误的。任务:在只从一个盒子中取出一个球并观察其颜色后,你必须推断出所有三个盒子的内容。直接回答问题。不要返回任何前言解释或推理。”
思维链提示:
“你有三个盒子。每个盒子包含三个球,但球的颜色可以是红色、蓝色或绿色。盒子1标签为“仅限红球”。盒子2标签为“仅限蓝球”。盒子3标签为“红蓝球”。所有标签都是错误的。任务:在只从一个盒子中取出一个球并观察其颜色后,你必须推断出所有三个盒子的内容。逐步思考以回答问题。在分隔符后返回响应的答案。”
草稿链提示:
“你有三个盒子。每个盒子包含三个球,但球的颜色可以是红色、蓝色或绿色。盒子1标签为“仅限红球”。盒子2标签为“仅限蓝球”。盒子3标签为“红蓝球”。所有标签都是错误的。任务:在只从一个盒子中取出一个球并观察其颜色后,你必须推断出所有三个盒子的内容。逐步思考以回答问题,但只为每个思考步骤保留一个最小的草稿,最多5个词。在分隔符后返回响应的答案。”
结果
使用上述提示对两个模型测试Lambda函数后,结果如下:
| 模型 | 提示技术 | 输入Token | 输出Token | 总Token数 | Token削减
COD vs. COT |
延迟(秒) | 延迟减少
COD vs. COT |
| Model-1 | 标准提示 | 102 | 23 | 125 | 0.8 | ||
| 思维链 | 109 | 241 | 350 | 3.28 | |||
| 草稿链 | 123 | 93 | 216 | ((350-216)/350) × 100 = 39% reduction | 1.58 | ((3.28-1.58)/3.28) × 100 = 52% reduction | |
| Model-2 | 标准提示 | 102 | 17 | 119 | 0.6 | ||
| 思维链 | 109 | 492 | 601 | 3.81 | |||
| 草稿链 | 123 | 19 | 142 | ((601-142)/601) × 100 = 76% reduction | 0.79 | ((3.81-0.79)/3.81) × 100 = 79% reduction |
表 2:使用标准提示、CoD提示和CoT提示在两个模型上进行测试的结果
比较显示,在两个模型上,草稿链 (CoD) 的效率远高于思维链 (CoT)。对于Model-1,CoD将总Token使用量从350减少到216(减少39%),并将延迟从3.28秒减少到1.58秒(减少52%)。对于Model-2,收益甚至更大,COD将Token从601减少到142(减少76%),延迟从3.81秒减少到0.79秒(减少79%)。总体而言,与CoT相比,CoD在速度和Token效率方面都带来了显著改进,尤其是在Model-2上取得了强劲的结果。
何时应避免使用CoD
尽管CoD提示在效率和性能方面具有引人注目的优势,但它并非普遍适用。在某些情况下,传统的CoT甚至更冗长的推理可能更有效或更合适。根据我们的实验和原始研究的发现,以下是一些关键考虑因素:
- 零样本或仅提示用例:CoD在与强大的少样本示例配对使用时效果最佳。在零样本场景中——即没有提供推理模式时——模型通常难以自行采用这种极简的草稿风格。这可能导致准确性降低或推理步骤不完整。
- 需要高可解释性的任务:对于法律或医疗文件审查、审计跟踪或受监管环境等用例,冗长的推理可能是必不可少的。在这种情况下,CoT更透明、分步的解释提供了更好的可追溯性和信任度。
- 小型语言模型:CoD在参数少于30亿的模型上表现不佳。这些模型缺乏有效执行CoD风格提示所需的指令遵循保真度和推理能力。在这些情况下,CoT可能会产生更好的结果。
- 创意或开放式任务:受益于阐述的任务——如写作、构思或面向用户的对话——如果过于浓缩可能会失去价值。CoD最适合结构化推理、逻辑和确定性任务,在这些任务中,简洁性可以提高性能。
简而言之,当目标是以最小的开销实现高效推理时,CoD表现出色——但仔细的提示设计、模型选择和任务契合度是成功的关键。
结论和关键要点
对于寻求优化生成式AI实施的组织而言,CoD提示是一种高效的技术。通过鼓励语言模型以简洁、集中的步骤进行推理,CoD在性能和资源利用率方面都实现了显着的改进。我们使用Amazon Bedrock和AWS Lambda的实现表明,与传统的CoT提示相比,在各种基础模型和复杂推理任务中保持相当的准确性,CoD在Token使用量和延迟改善方面带来了显著优势。随着AI的不断发展,CoD代表着迈向更高效、更具性能的语言模型的重要一步。它对于注重速度和Token效率的结构化推理任务尤其有价值,但它并非一刀切的解决方案。我们鼓励实践者在自己的AI工作流程中探索CoD,利用其在降低成本、提高响应时间并增强可扩展性方面的潜力。AI的未来在于更智能、更高效的推理方法,而CoD提示正处于这场变革的前沿。
要了解有关提示工程和CoD技术的更多信息,请参阅以下资源:
关于作者
 Ahmed Raafat是AWS的高级经理,领导英国和爱尔兰的AI/ML专家团队,拥有超过20年的技术经验,致力于通过AI和云技术帮助大公司实现转型。作为值得信赖的C级高管顾问和思想领袖,他指导组织进行AI战略和采用,帮助他们利用新兴技术实现创新和增长。
Ahmed Raafat是AWS的高级经理,领导英国和爱尔兰的AI/ML专家团队,拥有超过20年的技术经验,致力于通过AI和云技术帮助大公司实现转型。作为值得信赖的C级高管顾问和思想领袖,他指导组织进行AI战略和采用,帮助他们利用新兴技术实现创新和增长。
 Kiranpreet Chawla是亚马逊云计算服务(AWS)的解决方案架构师,利用超过15年的多样化技术经验推动云和AI转型。Kiranpreet的专业知识涵盖从云现代化到AI/ML实施,使她能够为各个行业的客户提供全面指导。
Kiranpreet Chawla是亚马逊云计算服务(AWS)的解决方案架构师,利用超过15年的多样化技术经验推动云和AI转型。Kiranpreet的专业知识涵盖从云现代化到AI/ML实施,使她能够为各个行业的客户提供全面指导。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区