



📢 转载信息
原文链接:https://blogs.nvidia.com/blog/2026-ces-special-presentation/
原文作者:Brian Caulfield
英伟达创始人兼CEO黄仁勋今日在拉斯维加斯的CES上发表主题演讲,宣布AI正在扩展到每个领域和每台设备。
黄仁勋表示:“加速计算和人工智能已经从根本上重塑了计算。这意味着过去十年中价值约10万亿美元的计算领域,正在以这种新的计算方式实现现代化。”
黄仁勋推出了Rubin,这是英伟达首个全面投入生产的超大规模协同设计的AI平台,并介绍了用于自动驾驶开发的开源推理模型系列Alpamayo,这是将AI推向各个领域的广泛举措的一部分。
黄仁勋表示,通过Rubin,英伟达旨在“将AI推向下一个前沿”,同时将生成Token的成本降低到前一个平台的约十分之一,使得大规模AI的部署更具经济性。
黄仁勋还强调了英伟达开源模型在各个领域的作用,这些模型在英伟达超级计算机上进行训练,形成了一个全球智能生态系统,供开发人员和企业在此基础上构建。
“每隔六个月就会出现一个新模型,而且这些模型正变得越来越智能,”黄仁勋说。“因此,你可以看到下载量呈爆炸式增长。”
在在线新闻资料包中查找来自CES的所有英伟达新闻。
智能的新引擎:Rubin平台
黄仁勋向观众介绍了以先驱美国天文学家Vera Rubin命名的下一代计算平台,并宣布NVIDIA Rubin平台——创纪录的NVIDIA Blackwell架构的继任者,也是该公司首个超大规模协同设计的六芯片AI平台——现已全面投产。

从数据中心向外构建,Rubin平台组件包括:
- 具有50 PetaFLOPS NVFP4推理能力的Rubin GPU
- 专为数据移动和代理处理设计的Vera CPU
- NVLink 6 扩展网络
- Spectrum-X 以太网光子学扩展网络
- ConnectX-9 SuperNICs
- BlueField-4 DPU
黄仁勋解释说,超大规模协同设计——即所有这些组件一起设计——至关重要,因为要将AI扩展到“吉咖规模”,需要在芯片、托盘、机架、网络、存储和软件之间实现紧密集成式的创新,以消除瓶颈,并大幅降低训练和推理的成本。
他还介绍了AI原生存储——NVIDIA推理上下文内存存储平台,这是一个AI原生的KV缓存层,可通过实现5倍的每秒Token量、5倍的每TCO美元性能以及5倍的能效,来增强长上下文推理能力。
将所有这些整合在一起,Rubin平台有望显著加速AI创新,并以十分之一的成本提供AI Token。“AI模型的训练速度越快,你就能越快地将下一个前沿技术推向世界,”黄仁勋说。“这关乎你的上市时间。这关乎技术领先地位。”
面向所有人的开源模型

英伟达的开源模型——在其自有超级计算机上训练而成——正在推动医疗、气候科学、机器人、具身智能和自动驾驶领域的突破。
“现在,在这个平台之上,英伟达是一个前沿AI模型构建者,我们以一种非常特殊的方式构建它。我们完全以开放的方式构建,以便能够让每家公司、每个行业、每个国家都能参与到这场AI革命中来。”
该产品组合涵盖六个领域——用于医疗的Clara、用于气候科学的Earth-2、用于推理和多模态AI的Nemotron、用于机器人和仿真的Cosmos、用于具身智能的GR00T(见Hugging Face)以及用于自动驾驶的Alpamayo——为跨行业的创新奠定了基础。
“这些模型对全世界开放,”黄仁勋说,强调了英伟达作为前沿AI构建者的地位,其世界级的模型在排行榜上名列前茅。“你可以创建模型、评估它、设置护栏并部署它。”
AI在每张桌面上:RTX、DGX Spark和个人代理
黄仁勋强调,AI的未来不仅关乎超级计算机,也关乎个人化。
黄仁勋展示了一个演示,其中一个个性化的AI代理在NVIDIA DGX Spark桌面超级计算机上本地运行,并通过使用Hugging Face模型的Reachy Mini机器人实现具身化——展示了开源模型、模型路由和本地执行如何将代理转变为响应迅速的物理协作者。
黄仁勋说:“最神奇的是,这在现在看来是完全微不足道的,但在几年前,这本是不可能实现的,绝对是不可想象的。”
黄仁勋表示,全球领先的企业正在整合NVIDIA AI来为其产品提供支持,他列举了包括Palantir、ServiceNow、Snowflake、CodeRabbit、CrowdStrike、NetApp和Semantec在内的公司。
“无论是在Palantir、ServiceNow还是Snowflake,以及我们正在与之合作的许多其他公司中,代理系统就是界面。”
在CES上,英伟达还宣布DGX Spark为大型模型提供了高达2.6倍的性能,并新增了对Lightricks LTX-2和FLUX图像模型的支持,以及即将推出的NVIDIA AI Enterprise可用性。
物理AI

通过英伟达用于训练、推理和边缘计算的技术,AI现在已经扎根于物理世界。
这些系统可以在与真实世界交互之前,在虚拟世界中使用合成数据进行训练。
黄仁勋展示了使用视频、机器人数据和仿真进行训练的NVIDIA Cosmos开源世界基础模型。Cosmos能够:
- 从单张图像生成逼真的视频
- 合成多摄像头驾驶场景
- 根据场景提示对边缘案例环境进行建模
- 执行物理推理和轨迹预测
- 驱动交互式的闭环仿真
为推进这一故事,黄仁勋发布了Alpamayo——一个开源的推理视觉语言动作模型(VLA)、仿真蓝图和数据集组合,旨在实现L4级自动驾驶能力。这包括:
- Alpamayo R1 — 首个用于自动驾驶的开源推理VLA模型
- AlpaSim — 用于高保真度自动驾驶汽车(AV)测试的完全开放的仿真蓝图
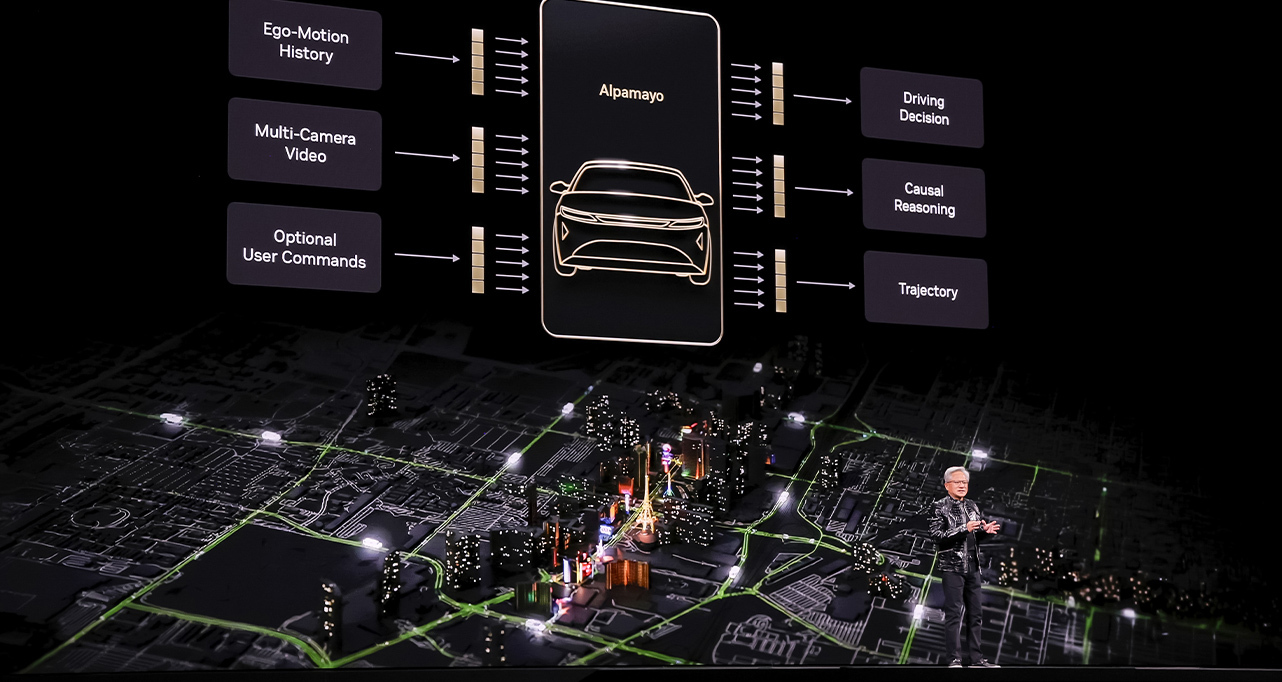
“它不仅接收传感器输入并激活方向盘、刹车和加速,它还会对即将采取的行动进行推理,”黄仁勋说,并播放了一段视频,展示了一辆汽车在繁忙的旧金山交通中平稳导航。
黄仁勋宣布,首款基于NVIDIA DRIVE全栈自动驾驶平台构建并搭载Alpamayo的乘用车——全新梅赛德斯-奔驰CLA——即将上路,AI定义的驾驶功能将于今年在美国推出,该车型最近还获得了EuroNCAP五星安全评级。
黄仁勋还强调了DRIVE Hyperion日益增长的势头,这是一个被全球领先的汽车制造商、供应商和机器人出租车提供商所采用的开源、模块化、L4级就绪平台。

黄仁勋说:“我们的愿景是,总有一天,每一辆汽车、每一辆卡车都将是自动驾驶的,我们正在为实现这一未来而努力。”
随后,黄仁勋请来了两台发出哔哔声、跳跃的小型机器人,向大家解释英伟达的全栈方法如何推动一个全球物理AI生态系统。
黄仁勋播放了一段视频,展示了机器人在照片级逼真的仿真世界中如何使用NVIDIA Isaac Sim和Isaac Lab进行训练,然后重点介绍了合作伙伴在物理AI方面的努力,包括Synopsis、Cadence、波士顿动力(Boston Dynamics)和Franka等。
他还宣布与西门子(Siemens)扩大合作,并展示了一个蒙太奇片段,说明英伟达的全栈技术如何与西门子的工业软件集成,从而实现从设计、仿真到生产的物理AI。
黄仁勋说:“这些制造工厂将本质上成为巨大的机器人。”
共同构建未来
黄仁勋解释说,英伟达现在构建整个系统,是因为需要一个完全优化和集成的堆栈才能实现AI突破。
“我们的工作是创建整个堆栈,以便你们所有人都能为全世界创造出色的应用程序,”他说。
观看完整演示回放:
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区