



📢 转载信息
原文链接:https://www.ithome.com/0/901/858.htm
原文作者:故渊
IT之家 12 月 2 日消息,科技媒体 Tom's Hardware 今天(12 月 2 日)发布博文,报道称英伟达在最新论文中,详述名为 TiDAR 的新型 AI 解码方法,巧妙融合了自回归(Autoregressive)与扩散(Diffusion)两种模型机制,利用 GPU 的“空闲槽位”加速文本生成。
自回归(Autoregressive)是一种生成方式,AI 必须根据上一个字才能猜出下一个字,像接龙一样,只能按顺序一个接一个生成。
扩散(Diffusion)常用于 AI 绘画的技术,通过逐步去除噪点来生成内容,在 TiDAR 中,它被用来一次性“猜”出好几个可能的词,供后续筛选。
IT之家援引博文介绍,当前的语言模型通常一次生成一个 Token(词元),这种逐个生成的机制导致了极高的计算成本和延迟。
TiDAR 的核心理念在于利用模型推理过程中未被使用的“空闲槽位”,在不牺牲生成质量的前提下,通过单步生成多个 Token 来大幅提升响应速度并降低 GPU 运行时长。
在技术原理方面,TiDAR 创新性地训练单个 Transformer 模型同时执行两项任务:标准的自回归“下一词预测”和基于扩散的“并行起草”。
不同于以往依赖独立草稿模型的投机解码(Speculative Decoding),TiDAR 通过结构化的注意力掩码(Attention Mask)将输入分为三个区域:前缀区、验证区和起草区。
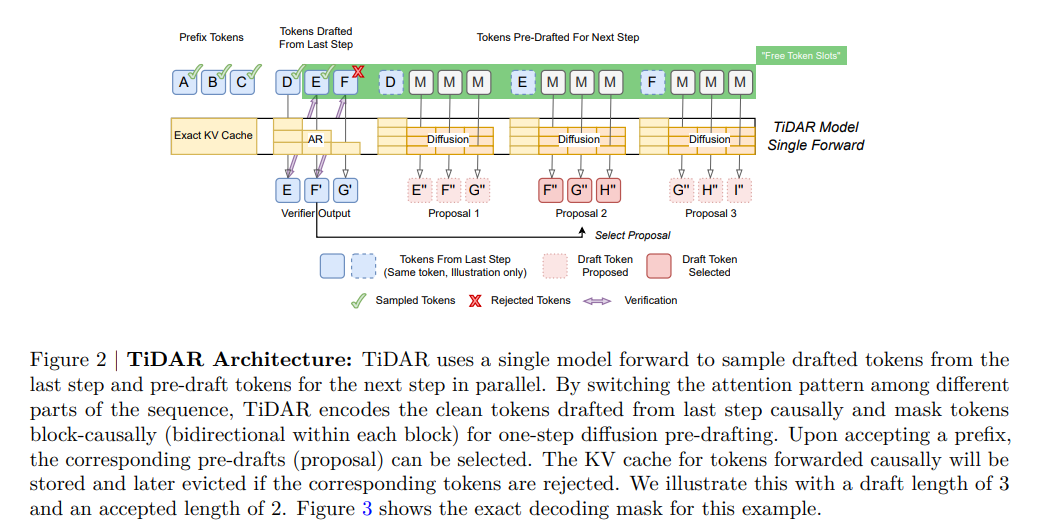
投机解码是一种加速技术,先用一个小模型快速草拟一段话,再由大模型进行检查和修正。TiDAR 试图在同一个模型内完成这两步。
这种设计让模型在利用扩散头并行起草新 Token 的同时,还能通过自回归头验证这些草稿,最关键的是,它确保了 KV 缓存(KV Cache)的结构有效性,解决了早期扩散解码器面临的部署难题。

研究团队基于 Qwen 系列模型进行了测试。在 HumanEval 和 GSM8K 等基准测试中,TiDAR 的准确率与基准模型持平甚至略有提升。
在速度方面,15 亿参数版本的 TiDAR 模型实现了 4.71 倍的吞吐量增长;而 80 亿参数版本的表现更为抢眼,吞吐量达到了 Qwen3-8B 基准的 5.91 倍。这表明在当前测试规模下,TiDAR 能有效利用 GPU 的显存带宽,在不增加额外显存搬运的情况下生成更多 Token。
该媒体指出尽管实验数据亮眼,TiDAR 目前仍面临规模扩展的挑战。论文中的测试仅限于 80 亿参数以下的中小模型,且未涉及定制化的内核级优化(如 fused kernels),仅使用了标准的 PyTorch 环境。
随着模型参数量和上下文窗口的扩大,计算密度可能会饱和,从而压缩“多 Token 扩展”的成本优势。研究人员表示,未来将在更大规模的模型上进行验证,以确定该技术是否能成为云端大规模 AI 部署的实用替代方案。
参考
广告声明:文内含有的对外跳转链接(包括不限于超链接、二维码、口令等形式),用于传递更多信息,节省甄选时间,结果仅供参考,IT之家所有文章均包含本声明。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区