



📢 转载信息
原文链接:https://blogs.nvidia.com/blog/mlperf-training-benchmark-blackwell-ultra/
原文作者:Dave Salvator
在 AI 推理的时代,训练更智能、能力更强的模型对于扩展智能至关重要。要提供满足这一新时代需求的大规模性能,需要在 GPU、CPU、NIC、扩展(scale-up)和横向扩展(scale-out)网络、系统架构,以及海量的软件和算法等方面取得突破。
在 MLPerf 训练 v5.1(一个长期运行的、用于测试 AI 训练性能的行业标准系列的最新一轮测试)中,英伟达横扫了全部七项测试,在大型语言模型(LLM)、图像生成、推荐系统、计算机视觉和图神经网络的训练速度方面均名列前茅。
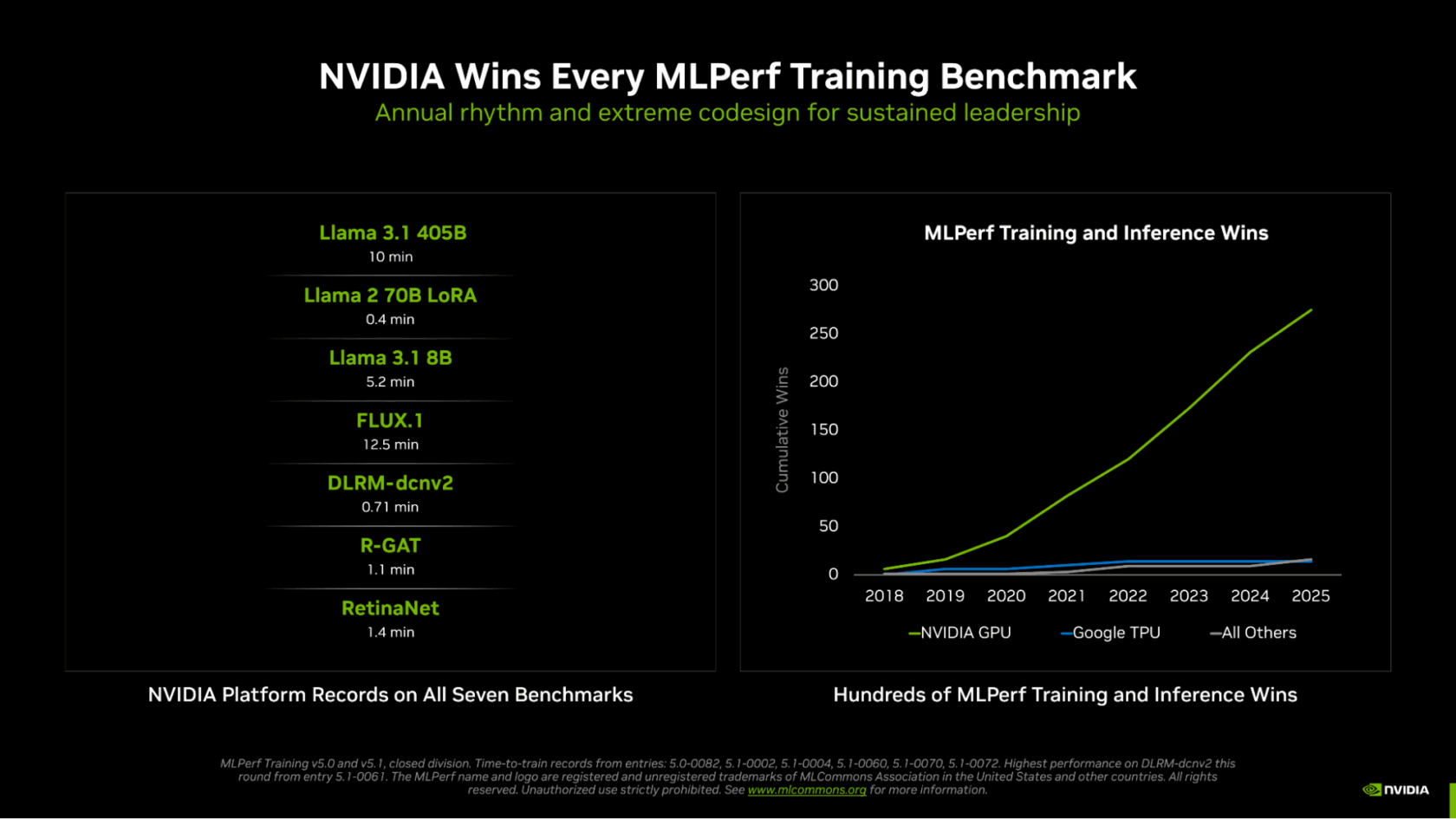
英伟达也是唯一一个提交了所有测试结果的平台,突显了 NVIDIA GPU 丰富的可编程性,以及其 CUDA 软件堆栈的成熟度和通用性。
NVIDIA Blackwell Ultra 加倍发力
由 NVIDIA Blackwell Ultra GPU 架构驱动的 GB300 NVL72 机架级系统,在本轮 MLPerf 训练中首次亮相,此前它在最近一轮的 MLPerf 推理测试中取得了创纪录的表现。
与上一代 Hopper 架构相比,基于 Blackwell Ultra 的 GB300 NVL72 在使用相同数量的 GPU 时,在 Llama 3.1 405B 预训练中的性能提高了 4 倍以上,在 Llama 2 70B LoRA 微调中的性能提高了近 5 倍。
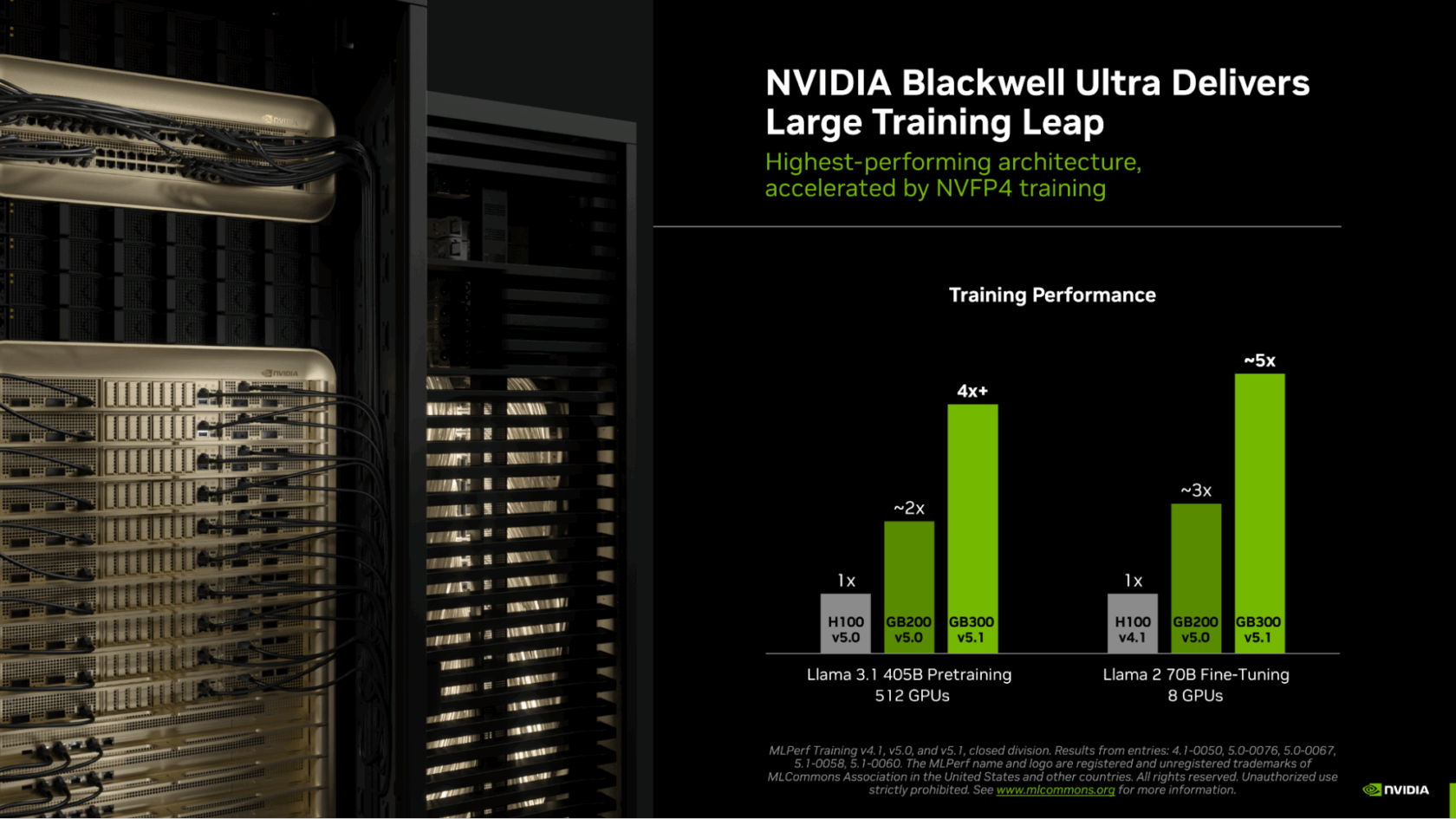
这些性能提升得益于 Blackwell Ultra 的架构改进——包括提供 15 PetaFLOPS NVFP4 AI 计算能力的新 Tensor Core、两倍的注意力层计算能力以及 279GB 的 HBM3e 内存——以及利用该架构巨大 NVFP4 计算性能的新训练方法。
连接多个 GB300 NVL72 系统的 NVIDIA Quantum-X800 InfiniBand 平台——业界首个端到端 800 Gb/s 扩展网络平台——也在 MLPerf 中首次亮相,其横向扩展网络带宽比上一代翻了一番。
性能释放:NVFP4 加速 LLM 训练
本轮出色成绩的关键在于使用了 NVFP4 精度进行计算——这是 MLPerf 训练历史上的首次。
提高计算性能的一种方法是构建一个能够对用更少比特表示的数据执行计算的架构,然后以更快的速率执行这些计算。然而,较低的精度意味着每次计算中可用的信息更少。这意味着在训练过程中使用低精度计算需要仔细的设计决策,以保持结果的准确性。
英伟达团队在堆栈的每一层都进行了创新,以便在 LLM 训练中采用 FP4 精度。NVIDIA Blackwell GPU 可以两倍于 FP8 的速率执行 FP4 计算——包括 NVIDIA 设计的 NVFP4 格式以及其他 FP4 变体。Blackwell Ultra 将这一速率提升至 3 倍,使 GPU 能够提供显著更高的 AI 计算性能。
迄今为止,英伟达是唯一一个提交了使用 FP4 精度进行计算的 MLPerf 训练结果,同时满足基准测试严格准确性要求的平台。
NVIDIA Blackwell 迈向新高度
英伟达创造了新的 Llama 3.1 405B 训练时间纪录,仅需 10 分钟,这得益于 5000 多块 Blackwell GPU 的高效协同工作。这次提交比上一轮提交的最佳 Blackwell 结果快了 2.7 倍,这得益于扩展到两倍以上的 GPU 数量,以及使用 NVFP4 精度显著提高了每块 Blackwell GPU 的有效性能。
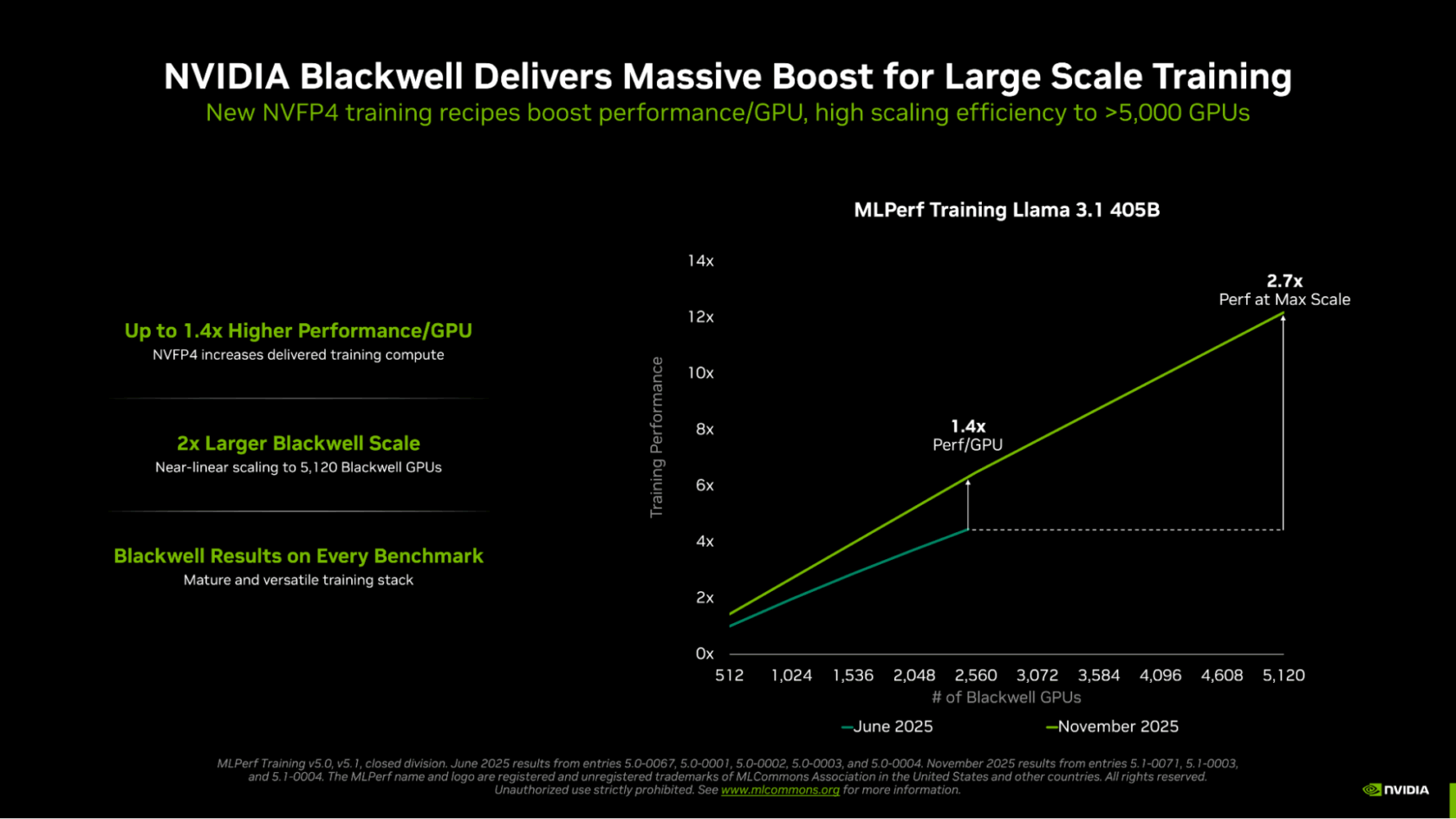
为了说明每 GPU 的性能提升,英伟达在本轮提交了使用 2,560 块 Blackwell GPU 的结果,训练时间为 18.79 分钟——比上次提交使用的 2,496 块 GPU 快了 45%。
新基准,新纪录
英伟达也在本轮新增的两个基准测试中创造了性能纪录:Llama 3.1 8B 和 FLUX.1。
Llama 3.1 8B 是一款紧凑但功能强大的 LLM,它取代了长期运行的 BERT-large 模型,为基准测试套件增加了一个现代化的、较小的 LLM。英伟达使用多达 512 块 Blackwell Ultra GPU 提交了结果,将标准设定为 5.2 分钟完成训练。
此外,FLUX.1——一种最先进的图像生成模型——取代了 Stable Diffusion v2,并且只有 NVIDIA 平台提交了该基准测试的结果。英伟达使用 1,152 块 Blackwell GPU 提交了结果,将训练时间纪录设定为 12.5 分钟。
英伟达继续保持在现有的图神经网络、目标检测和推荐系统测试中的领先地位。
广泛而深入的合作伙伴生态系统
英伟达生态系统在本轮测试中积极参与,包括 ASUSTeK、Dell Technologies、Giga Computing、Hewlett Packard Enterprise、Krai、Lambda、Lenovo、Nebius、Quanta Cloud Technology、Supermicro、佛罗里达大学和 Wiwynn 在内的 15 个组织都提交了出色的结果。
英伟达以一年为周期进行创新,在预训练、后训练和推理方面推动显著且快速的性能提升——为达到新的智能水平铺平道路,并加速 AI 的普及。
欲了解更多 NVIDIA 性能数据,请访问 数据中心深度学习产品性能中心和 性能探索器页面。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区