



📢 转载信息
原文作者:Rizwan Mushtaq, Fan Zhang, Hector Lopez, and Meena Menon
本文由 Palo Alto Networks 的高级首席工程师/架构师 Fan Zhang 撰写。
Palo Alto Networks 的设备安全团队希望检测潜在生产问题的早期预警信号,以便为主题专家 (SME) 争取更多时间来应对这些新出现的问题。他们面临的主要挑战是,对每天超过 2 亿条服务和应用程序日志进行被动处理,导致对这些关键问题的响应延迟,使他们面临潜在的服务降级的风险。
为应对这一挑战,他们与 AWS 生成式 AI 创新中心 (GenAIIC) 合作,开发了一个由 Amazon Bedrock 驱动的自动化日志分类流水线。该解决方案在检测生产问题方面实现了 95% 的准确率,同时将事件响应时间减少了 83%。
在本文中,我们将探讨如何使用 Amazon Bedrock 构建一个可扩展且经济高效的日志分析系统,将反应式的日志监控转变为主动的问题检测。我们将讨论 Amazon Bedrock 如何通过 Anthropic 的 Claude Haiku 模型和 Amazon Titan 文本嵌入协同工作,自动对日志数据进行分类和分析。我们将探讨这种自动化流水线如何检测关键问题,审视解决方案架构,并分享已带来可衡量运营改进的实施见解。
Palo Alto Networks 提供 云交付安全服务 (CDSS) 来应对设备安全风险。其解决方案利用机器学习和自动发现技术,提供对连接设备的可见性,并执行 零信任原则。面临类似日志分析挑战的团队可以在此实现中找到实用的见解。
解决方案概述
Palo Alto Networks 的自动化日志分类系统帮助其设备安全团队提前检测并应对潜在的服务故障。该解决方案每天处理超过 2 亿条服务和应用程序日志,在问题升级为影响客户的服务中断之前自动识别关键问题。
该系统使用 Amazon Bedrock 配合 Anthropic 的 Claude Haiku 模型来理解日志模式并分类严重程度,而 Amazon Titan 文本嵌入则支持智能相似性匹配。 Amazon Aurora 提供了一个缓存层,使得实时处理海量日志成为可能。该解决方案与 Palo Alto Networks 现有的基础架构无缝集成,帮助设备安全团队专注于防止中断,而不是管理复杂的日志分析流程。
Palo Alto Networks 与 AWS GenAIIC 合作构建了一个具备以下能力的解决方案:
- 智能去重和缓存 – 该系统通过智能识别同一代码事件的重复日志条目来扩展规模。系统不是对每条日志单独使用大型语言模型 (LLM) 进行分类,而是首先通过精确匹配识别重复项,然后使用重叠相似性,最后仅在未找到先前匹配时才采用语义相似性。这种方法以经济高效的方式将 2 亿条每日日志减少了 99% 以上,只留下代表唯一事件的日志。缓存层通过减少冗余的 LLM 调用,支持实时处理。
- 唯一日志的上下文检索 – 对于唯一日志,使用 Amazon Bedrock 的 Anthropic Claude Haiku 模型对每条日志的严重程度进行分类。该模型处理传入的日志以及相关的已标记历史示例。这些示例在推理时通过向量相似性搜索动态检索。随着时间的推移,会添加已标记的示例,为 LLM 的分类提供丰富的上下文。这种上下文感知的处理方法提高了 Palo Alto Networks 内部日志和系统的准确性,并能应对传统基于规则的系统难以处理的不断变化的日志模式。
- 使用 Amazon Bedrock 进行分类 – 该解决方案提供结构化预测,包括严重程度分类(优先级 1 (P1)、优先级 2 (P2)、优先级 3 (P3))以及对每个决策的详细推理。这种全面的输出有助于 Palo Alto Networks 的 SME 快速确定响应优先级并采取预防措施,避免潜在的服务中断。
- 与现有流水线集成以执行操作 – 结果与他们现有的 FluentD 和 Kafka 流水线集成,数据流向 Amazon Simple Storage Service (Amazon S3) 和 Amazon Redshift 以供进一步分析和报告。
下图(图 1)说明了三阶段流水线如何在平衡规模、准确性和成本效益的同时处理 Palo Alto Networks 每日 2 亿的日志量。该架构包含以下关键组件:
- 数据摄取层 – FluentD 和 Kafka 流水线以及传入日志
- 处理流水线 – 由以下阶段组成:
- 阶段 1:智能缓存和去重 – 使用 Aurora 进行精确匹配,使用 Amazon Titan 文本嵌入进行语义匹配
- 阶段 2:上下文检索 – 使用 Amazon Titan 文本嵌入来启用历史标记示例,以及向量相似性搜索
- 阶段 3:分类 – 使用 Anthropic 的 Claude Haiku 模型进行严重程度分类 (P1/P2/P3)
- 输出层 – Aurora、Amazon S3、Amazon Redshift 和 SME 审查界面
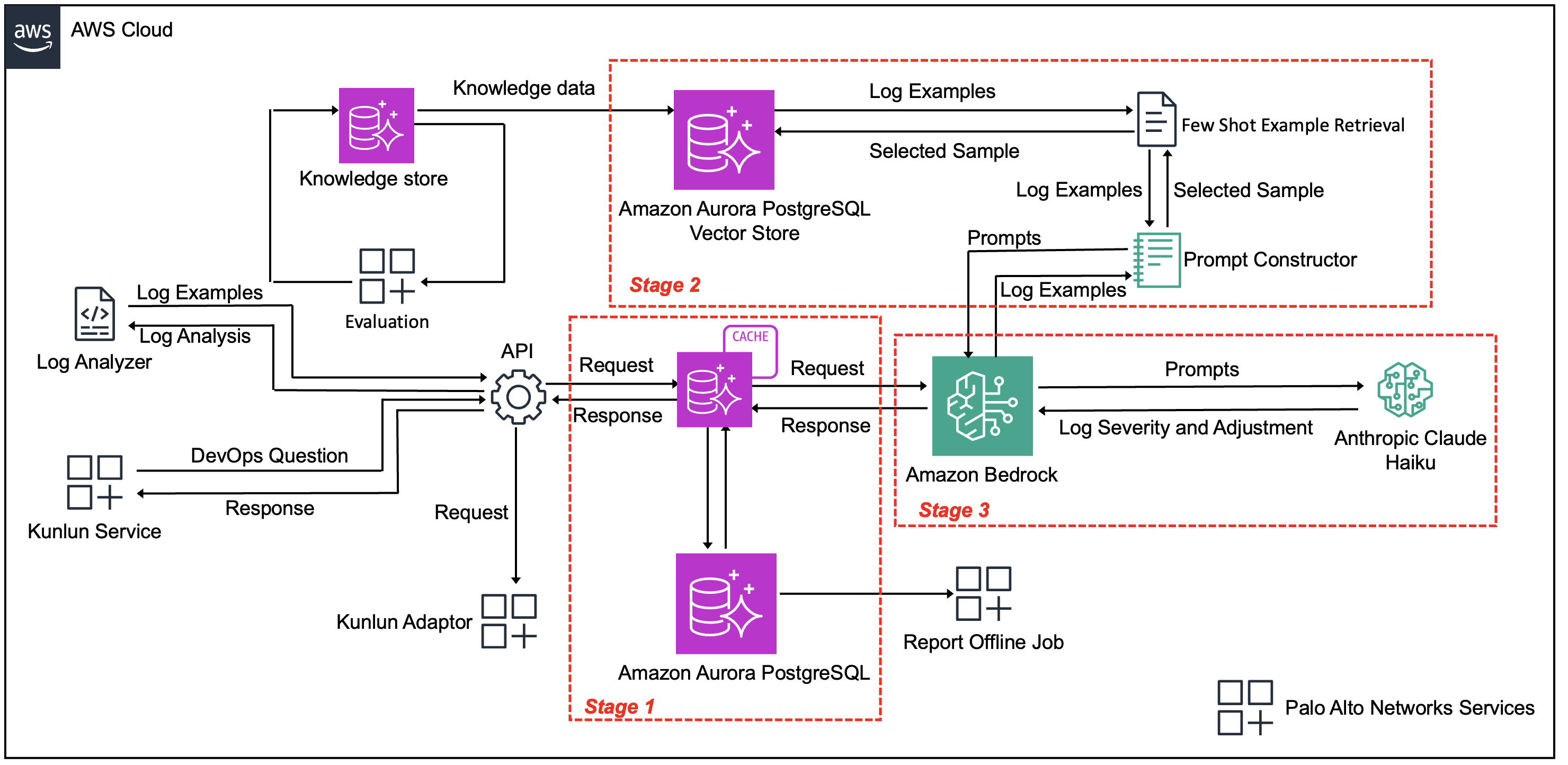
图 1:自动化日志分类系统架构
处理工作流程经过以下阶段:
- 阶段 1:智能缓存和去重 – 来自 Palo Alto Networks 的 FluentD 和 Kafka 流水线的传入日志立即通过基于 Aurora 的缓存层进行处理。系统首先应用精确匹配,然后退回到重叠相似性,如果未找到先前匹配,则最终使用 Amazon Titan 文本嵌入进行语义相似性匹配。在测试期间,这种方法发现超过 99% 的日志对应于重复事件,尽管它们包含不同的时间戳、日志级别和措辞。缓存系统减少了缓存结果的响应时间,并减少了不必要的 LLM 处理。
- 阶段 2:唯一日志的上下文检索 – 剩余不到 1% 的真正唯一的日志需要分类。对于这些条目,系统使用 Amazon Titan 文本嵌入从 Palo Alto Networks 的标记数据集中识别最相关的历史示例。与使用静态示例不同,这种动态检索确保每条日志都获得适合其上下文的分类指导。
- 阶段 3:使用 Amazon Bedrock 进行分类 – 唯一的日志及其选定的示例由 Amazon Bedrock 使用 Anthropic 的 Claude Haiku 模型进行处理。该模型分析日志内容以及相关的历史示例,以生成严重程度分类 (P1、P2、P3) 和详细说明。结果存储在 Aurora 和缓存中,并集成到 Palo Alto Networks 现有的数据流水线中,供 SME 审查和操作。
该架构使得以经济高效的方式处理海量日志成为可能,同时对关键的 P1 严重程度检测保持 95% 的准确率。该系统使用精心设计的提示,这些提示将领域专业知识与动态选择的示例结合起来:
system_prompt = """ <Task> You are an expert log analysis system responsible for classifying production system logs based on severity. Your analysis helps engineering teams prioritize their response to system issues and maintain service reliability. </Task> <Severity_Definitions> P1 (Critical): Requires immediate action - system-wide outages, repeated application crashes P2 (High): Warrants attention during business hours - performance issues, partial service disruption P3 (Low): Can be addressed when resources available - minor bugs, authorization failures, intermittent network issues </Severity_Definitions> <Examples> <log_snippet> 2024-08-17 01:15:00.00 [warn] failed (104: Connection reset by peer) while reading response header from upstream </log_snippet> severity: P3 category: Category A <log_snippet> 2024-08-18 17:40:00.00 <warn> Error: Request failed with status code 500 at settle </log_snippet> severity: P2 category: Category B </Examples> <Target_Log> Log: {incoming_log_snippet} Location: {system_location} </Target_Log>""" Provide severity classification (P1/P2/P3) and detailed reasoning.实施见解
Palo Alto Networks 解决方案的核心价值在于将一个看似无法解决的挑战变得可以管理:人工智能帮助他们的团队高效地分析每日 2 亿的日志量,而系统的动态适应性使其有可能通过添加更多标记示例将解决方案扩展到未来。Palo Alto Networks 成功实施其自动化日志分类系统,产生了可以帮助构建生产规模 AI 解决方案的组织的关键见解:
- 持续学习系统提供复合价值 – Palo Alto Networks 的系统设计使其能够随着 SME 验证分类和标记新示例而自动改进。每个经验证的分类都成为动态少样本检索数据集的一部分,提高了未来类似日志的准确性,同时提高了缓存命中率。这种方法产生了一个循环,其中操作使用增强了系统性能并降低了成本。
- 智能缓存支持生产规模的 AI – 多层缓存架构通过缓存命中处理了 99% 以上的日志,将昂贵的每日志 LLM 操作转变为能够处理每日 2 亿日志量的经济高效的系统。这种基础使得在企业规模上进行 AI 处理在经济上可行,同时保持响应时间。
- 自适应系统无需代码更改即可处理不断变化的需求 – 该解决方案无需系统修改即可适应新的日志类别和模式。当需要提高新日志类型的性能时,SME 可以标记其他示例,动态少样本检索会自动将这些知识纳入未来的分类中。这种适应性使系统能够随业务需求一起扩展。
- 可解释的分类带来运营信心 – 应对关键警报的 SME 需要对 AI 建议充满信心,尤其是在 P1 严重程度分类方面。通过在每个分类旁边提供详细的推理,Palo Alto Networks 使 SME 能够快速验证决策并采取适当的行动。清晰的解释将 AI 输出从预测转变为可操作的情报。
这些见解表明,为持续学习和可解释性而设计的 AI 系统如何成为越来越有价值的运营资产。
结论
Palo Alto Networks 的自动化日志分类系统证明了由 AWS 驱动的生成式 AI 如何帮助运营团队实时管理海量数据。在本文中,我们探讨了结合 Amazon Bedrock、Amazon Titan 文本嵌入和 Aurora 的架构如何通过智能缓存和动态少样本学习处理每日 2 亿的日志,从而以 95% 的准确率主动检测关键问题。Palo Alto Networks 的自动化日志分类系统带来了切实的运营改进:
- P1 严重程度日志的 95% 准确率,90% 召回率 – 关键警报准确且可操作,最大限度地减少误报,同时捕获 10 个紧急问题中的 9 个,其余警报由现有监控系统捕获
- 调试时间减少 83% – SME 花费更少时间进行例行日志分析,而将更多时间用于战略改进
- 超过 99% 的缓存命中率 – 智能缓存层通过亚秒级的响应,以经济高效的方式处理每日 2000 万的日志量
- 主动问题检测 – 系统在问题影响客户之前识别潜在问题,防止了先前中断服务的长达数周的停机时间
- 持续改进 – 每个 SME 的验证都会自动改进未来的分类并提高缓存效率,从而降低成本
对于评估日志分析和运营监控中 AI 方案的组织而言,Palo Alto Networks 的实施提供了一个构建可带来运营效率和成本降低可衡量改进的生产规模系统的蓝图。要构建您自己的生成式 AI 解决方案,请探索 Amazon Bedrock 以获得对基础模型的托管访问权限。如需额外指导,请查看 AWS 机器学习资源,并在 AWS 人工智能博客中浏览实施示例。
Palo Alto Networks 与 AWS GenAIIC 之间的合作展示了周到的 AI 实施如何将反应式操作转变为提供持续业务价值的主动、可扩展的系统。
要开始使用 Amazon Bedrock,请参阅 使用 Amazon Bedrock 构建生成式 AI 解决方案。
作者简介

Rizwan Mushtaq
Rizwan 是 AWS 的首席解决方案架构师。他帮助客户使用 AWS 服务设计创新、有弹性且经济高效的解决方案。他拥有威奇托州立大学的电气工程硕士学位。

Hector Lopez
Hector Lopez 博士是 AWS 生成式 AI 创新中心的应用科学家,专注于在各种行业应用中交付可投入生产的生成式 AI 解决方案和概念验证。他的专业知识涵盖生命科学和物理科学领域的传统机器学习和数据科学。Hector 采用第一性原理方法来解决客户问题,从核心业务需求出发,帮助组织理解和利用生成式 AI 工具实现有意义的业务转型。

Meena Menon
Meena Menon 是 AWS 的高级客户成功经理,在交付企业客户成果和数字化转型方面拥有超过 20 年的经验。在 AWS,她与 Palo Alto Networks、Proofpoint、New Relic 和 Splunk 等战略性 ISV 合作,加速云现代化和迁移。

Fan Zhang
Fan 是 Palo Alto Networks 的高级首席工程师/架构师,负责领导物联网安全团队的基础设施和数据流水线,以及其生成式 AI 基础设施。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区