



📢 转载信息
原文链接:https://www.ithome.com/0/888/677.htm
原文作者:故渊
IT之家 10 月 11 日消息,科技媒体 Tom's Hardware 昨日(10 月 10 日)发布博文,报道称分析机构 SemiAnalysis 近日发布了一款名为 InferenceMax 的开源 AI 基准测试套件,专注于衡量在真实 AI 推理(模型实际运行)场景下,由驱动、内核、框架等组成的整个软件堆栈的综合效率。
IT之家援引博文介绍,人工智能领域的焦点几乎完全集中在芯片交易和 GPU 等硬件发展上,现有的基准测试也大多只关注硬件性能,因此 InferenceMax 希望提供一个开源且厂商中立的 AI 基准测试套件。该项目以滚动发布的方式,每晚更新测试结果,从而能够动态追踪软件更新对性能的持续影响。
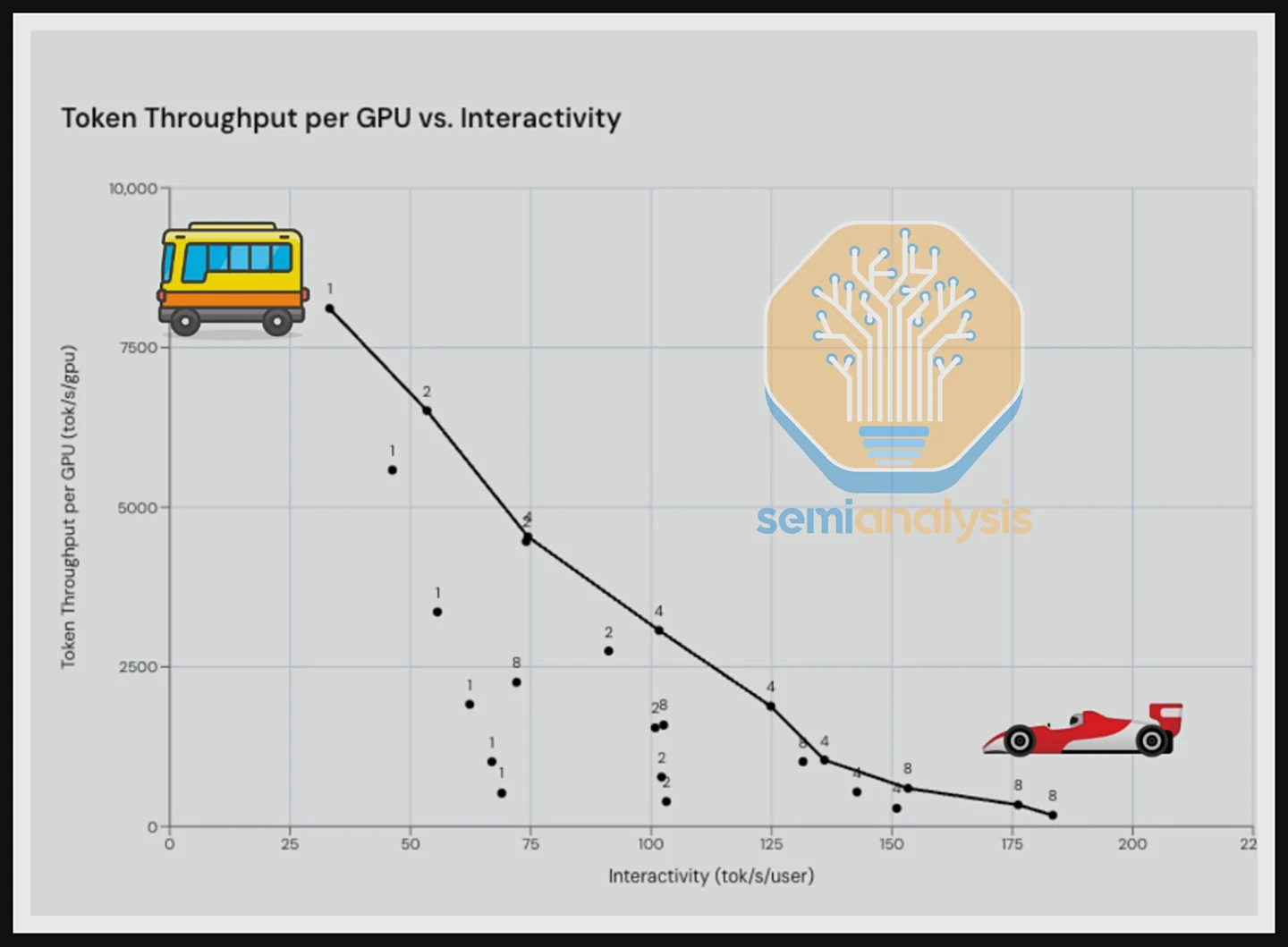
告别唯速度论:InferenceMax 构建AI推理新标尺
InferenceMax 引入了两个相互制约的关键性能指标。其一是“吞吐量”,指在单位时间内处理更多并发请求的能力,这有利于最大化 GPU 利用率;其二是“交互性”,指为单个用户提供更快响应速度的能力,例如在聊天机器人场景中。
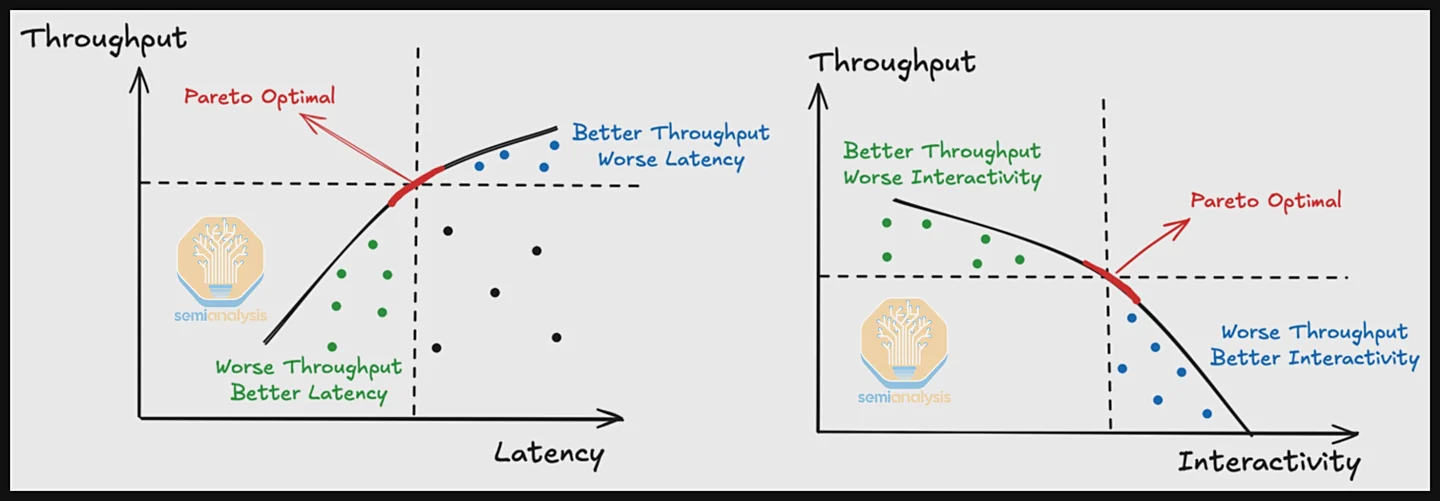
成本效益成为终极考量
在两者之间取得理想平衡(即帕累托前沿曲线上的最佳点)至关重要。最终,对于服务提供商而言,衡量投资回报的终极标准是“总拥有成本”(TCO),即处理每百万 token 所需花费的美元。InferenceMax 致力于估算不同硬件采购或租赁方案下的 TCO,为用户提供最具经济效益的选择依据。
InferenceMax 的初步测试提供了一些颠覆性的见解。例如,尽管英伟达的 B200 在原始速度上遥遥领先,但在综合考量 TCO 后,AMD 的 MI335X 在特定场景下展现出了极强的竞争力,这表明,最快的芯片不一定是最经济高效的选择。
同时,测试也暴露了 AMD 在 FP4(4 位浮点格式)内核方面尚有改进空间,目前依赖该数学格式的场景仍由英伟达芯片主导。这些发现凸显了单纯比较硬件参数的局限性,软件优化与成本效益正成为评估 AI 性能的关键。
两大巨头深度协作与反馈
InferenceMax 的开发过程得到了英伟达、AMD 及多家云服务商的深度协作。这种合作不仅帮助项目获取了真实的硬件与软件配置方案,还意外地发现了两大巨头软件堆栈中的多个错误。
例如,项目组协助 AMD 修复了其 ROCm 软件中的问题,并建议 AMD 提供更优的默认配置以简化性能调优。对于英伟达,测试则暴露了其新款 Blackwell 驱动在快速启停实例时存在初始化相关的障碍。
高层表态:共推行业透明度
英伟达首席执行官黄仁勋表示:
在长上下文推理的推动下,推理需求呈指数级增长。NVIDIA Grace Blackwell NVL72 正是为这个充满思考力的 AI 新时代而生。NVIDIA 通过持续的硬件和软件创新来满足这一需求,从而赋能 AI 的未来发展。
通过频繁的基准测试,InferenceMax 让业界能够清晰地了解 LLM 推理在实际工作负载下的性能。结果显而易见:搭载 TRT-LLM 和 Dynamo 的 Grace Blackwell NVL72 可提供无与伦比的单位成本和单位兆瓦性能,为全球生产力最高、成本效益最高的 AI 工厂提供支持。
AMD 首席执行官苏姿丰表示:
开放式协作正在推动人工智能创新的新时代。开源 InferenceMax 基准测试为社区提供透明的每日结果,从而激发信任并加速进步。
它凸显了我们的 AMD Instinct MI300、MI325X 和 MI355X GPU 在不同工作负载下具有竞争力的 TCO 性能,彰显了我们平台的强大实力以及我们致力于让开发人员实时了解软件进度的承诺。
IT之家附上参考地址
广告声明:文内含有的对外跳转链接(包括不限于超链接、二维码、口令等形式),用于传递更多信息,节省甄选时间,结果仅供参考,IT之家所有文章均包含本声明。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,小白也可以简单操作。
青云聚合API官网https://api.qingyuntop.top
支持全球最新300+模型:https://api.qingyuntop.top/pricing
详细的调用教程及文档:https://api.qingyuntop.top/about
评论区