



📢 转载信息
原文链接:https://machinelearningmastery.com/3-feature-engineering-techniques-for-unstructured-text-data/
原文作者:Shittu Olumide
在本文中,您将学习将原始文本转换为机器学习模型可用的数值特征的实用方法,这些方法涵盖了从统计计数到语义和上下文嵌入的各种技术。
我们将涵盖的主题包括:
- 为什么 TF-IDF 仍然是一个强大的统计基线以及如何实现它。
- 平均化的 GloVe 词嵌入如何捕获超越关键词的含义。
- 基于 Transformer 的嵌入如何提供上下文感知的表示。
让我们直接进入正题。
非结构化文本数据的3种特征工程技术
图片来源:编辑
引言
机器学习模型有一个根本性的局限性,这常常让自然语言处理(NLP)的新手感到沮丧:它们无法阅读。如果你将一封原始电子邮件、一条客户评论或一份法律合同输入到逻辑回归或神经网络中,处理过程会立即失败。算法是作用于方程的数学函数,它们需要数值输入才能工作。它们不懂单词,它们懂的是向量。
文本的特征工程是一个至关重要的过程,它弥合了这种差距。它是将人类语言的定性细微差别转化为机器可以处理的定量数字列表的行为。这个转换层通常是模型成功的决定性因素。一个复杂的算法如果输入了工程设计不佳的特征,其性能会比一个简单算法输入了丰富、具有代表性的特征还要差。
该领域在过去几十年中经历了巨大的演变。它已经从将文档视为一组不相关词汇的简单计数机制,发展到能够根据周围词汇理解词汇上下文的复杂深度学习架构。
本文涵盖了解决此问题的三种不同方法,从 TF-IDF 的统计基础,到 GloVe 向量的语义平均,最后到 Transformer 提供的最先进的上下文嵌入。
1. 统计基础:TF-IDF 向量化
将文本转换为数字的最直接方法是计数。这是几十年来一直以来的标准。你可以简单地计算一个词在文档中出现的次数,这种技术被称为 词袋模型 (bag of words)。然而,原始计数有一个明显的缺陷。在几乎所有的英语文本中,最常见的词是语法上必需但语义上为空的冠词和介词,如“the”、“is”、“and”或“of”。如果你只依赖原始计数,这些常见词将主导你的数据,淹没了真正赋予文档意义的罕见、特定的词汇。
为了解决这个问题,我们使用 词频-逆文档频率 (term frequency–inverse document frequency, TF-IDF)。这项技术不仅根据词在特定文档中出现的频率来衡量词的权重,还衡量词在整个数据集中出现的稀有程度。这是一种旨在惩罚常见词并奖励独特词的统计平衡术。
第一部分,词频 (TF),衡量一个术语在文档中出现的频率。第二部分,逆文档频率 (IDF),衡量一个术语的重要性。IDF 分数是通过计算总文档数除以包含特定术语的文档数(然后取对数)来计算的。
如果单词“data”出现在你数据集的每个文档中,那么它的 IDF 分数将接近于零,实际上将其排除在外。相反,如果单词“hallucination”只出现在一个文档中,它的 IDF 分数就会非常高。当你将 TF 乘以 IDF 时,结果是一个特征向量,它准确地突出了特定文档相对于其他文档的独特性。
实现与代码解释
我们可以使用 scikit-learn 的 TfidfVectorizer 高效地实现这一点。在这个例子中,我们采用了一个包含三句话的小型语料库,并将其转换为一个数字矩阵。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
# 1. Define a small corpus of text
documents = [
"The quick brown fox jumps.",
"The quick brown fox runs fast.",
"The slow brown dog sleeps."
]
# 2. Initialize the Vectorizer
# We limit the features to the top 100 words to keep the vector size manageable
vectorizer = TfidfVectorizer(max_features=100)
# 3. Fit and Transform the documents
tfidf_matrix = vectorizer.fit_transform(documents)
# 4. View the result as a DataFrame for clarity
feature_names = vectorizer.get_feature_names_out()
df_tfidf = pd.DataFrame(tfidf_matrix.toarray(), columns=feature_names)
print(df_tfidf)
|
代码首先导入必要的 TfidfVectorizer 类。我们定义了一个字符串列表作为原始数据。当我们调用 fit_transform 时,向量化器首先学习整个列表的词汇表(“fit”步骤),然后根据该词汇表将每个文档转换为一个向量。
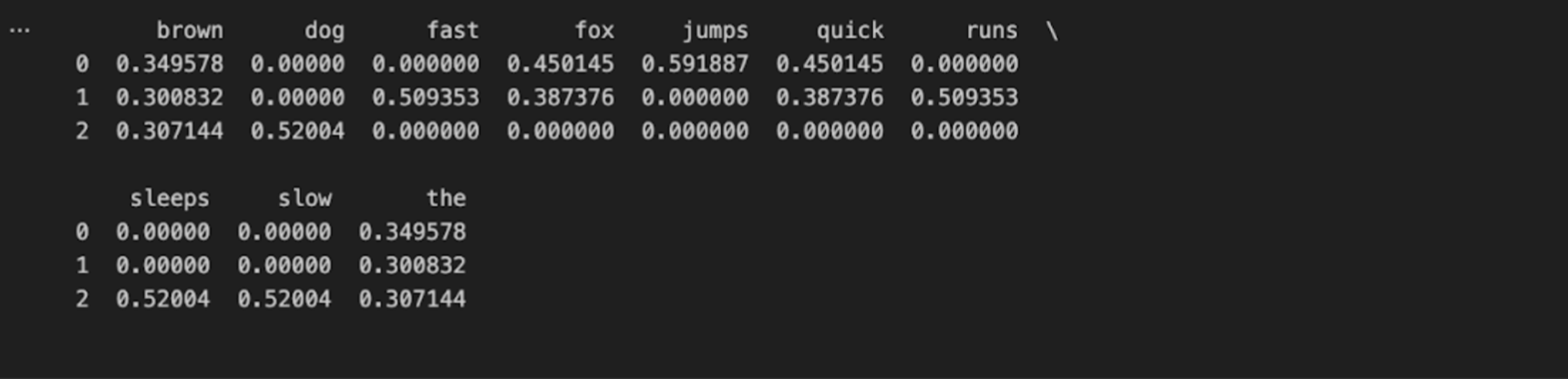
输出是一个 Pandas DataFrame,其中每行代表一个句子,每列代表数据中发现的一个唯一单词。
2. 捕获含义:平均词嵌入(GloVe)
虽然 TF-IDF 在关键词匹配方面很强大,但它缺乏语义理解能力。它将“good”和“excellent”视为完全不相关的数学特征,因为它们的拼写不同。它不知道它们的意思几乎相同。为了解决这个问题,我们转向 词嵌入 (word embeddings)。
词嵌入是一种将单词映射到实数向量的技术。其核心思想是,含义相似的词应该具有相似的数学表示。在这个向量空间中,“king”和“queen”之间的向量距离大约与“man”和“woman”之间的距离相似。
最流行的预训练嵌入集之一是 GloVe(用于词表示的全局向量),由斯坦福大学的研究人员开发。您可以在斯坦福 GloVe 项目页面 上找到他们的研究和数据集。这些向量是在 Common Crawl 和维基百科数据上数十亿个单词上训练出来的。该模型通过观察词汇如何共同出现(共现)来确定它们的语义关系。
要将其用于特征工程,我们面临一个小障碍。GloVe 为单个单词提供了向量,但我们的数据通常由句子或段落组成。一种常见且有效的表示整个句子的方法是计算其所包含的词汇向量的 平均值。如果你有一个包含十个词的句子,你查找每个词的向量并将它们平均在一起。结果是一个单一的向量,代表了整个句子的“平均含义”。
实现与代码解释
对于这个例子,我们将假设您已经从上面斯坦福的链接下载了一个 GloVe 文件(例如 glove.6B.50d.txt)。下面的代码将这些向量加载到内存中,并对一个示例句子进行平均化处理。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
import numpy as np
# 1. Load the GloVe embeddings into a dictionary
# This assumes you have the glove.6B.50d.txt file locally
embeddings_index = {}
with open('glove.6B.50d.txt', encoding='utf-8') as f:
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
print(f"Loaded {len(embeddings_index)} word vectors.")
# 2. Define a function to vectorize a sentence
def get_average_word2vec(tokens, vector_dict, generate_missing=False, k=50):
if len(tokens) < 1:
return np.zeros(k)
# Extract the vector for each word if it exists in our dictionary
feature_vec = np.zeros((k,), dtype="float32")
count = 0
for word in tokens:
if word in vector_dict:
feature_vec = np.add(feature_vec, vector_dict[word])
count += 1
if count == 0:
return feature_vec
# Divide the sum by the count to get the average
feature_vec = np.divide(feature_vec, count)
return feature_vec
# 3. Apply to a new sentence
sentence = "artificial intelligence is fascinating"
# Simple tokenization by splitting on space
tokens = sentence.lower().split()
sentence_vector = get_average_word2vec(tokens, embeddings_index)
print(f"The vector has a shape of: {sentence_vector.shape}")
print(sentence_vector[:5]) # Print first 5 numbers
|
代码首先构建一个字典,其中键是英语单词,值是代表其 GloVe 向量的相应 NumPy 数组。get_average_word2vec 函数遍历输入句子中的单词。它检查该词是否存在于我们的 GloVe 字典中;如果存在,它会将该词的向量加到一个运行总数中。
最后,它将总和除以找到的单词数。此操作将可变长度的句子压缩成固定长度的向量(在此例中为 50 维)。这个数值表示捕获了句子的语义主题。一句关于“dogs”的句子将具有与一句关于“puppies”的句子非常接近的数学平均值,即使它们没有共享任何共同的词汇,这对 TF-IDF 来说是一个巨大的进步。
3. 上下文智能:基于 Transformer 的嵌入
上述的平均化方法代表了巨大的飞跃,但它引入了一个新问题:它忽略了顺序和上下文。当你平均向量时,“The dog bit the man”(狗咬了人)和“The man bit the dog”(人咬了狗)会产生完全相同的向量,因为它们包含完全相同的词汇。此外,无论你是在“河岸”(river bank)还是在访问“金融银行”(financial bank),单词“bank”都具有相同的静态 GloVe 向量。
为了解决这个问题,我们使用 Transformer,特别是像 BERT(Bidirectional Encoder Representations from Transformers,用于 Transformer 的双向编码器表示) 这样的模型。Transformer 不是从左到右顺序读取文本;它们使用一种称为“自注意力 (self-attention)”的机制一次性读取整个序列。这使得模型能够理解一个词的含义是由它周围的词定义的。
当我们使用 Transformer 进行特征工程时,我们不一定是从头开始训练模型。相反,我们将预训练模型用作特征提取器。我们将文本输入到模型中,并从最后一个隐藏层提取输出。具体来说,像 BERT 这样的模型会在每个句子前添加一个特殊的标记,称为 [CLS](分类)标记。该特定标记在通过这些层后的向量表示被设计用来保存对整个序列的聚合理解。
这目前被认为是文本表示的黄金标准。你可以阅读关于这种架构的开创性论文——“Attention Is All You Need”,或者探索 Hugging Face Transformers 库的文档,该库使这些模型对 Python 开发人员来说变得易于获取。
实现与代码解释
我们将使用 Hugging Face 的 transformers 库和 PyTorch 来提取这些特征。请注意,此方法的计算量比前两种方法更大。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
from transformers import BertTokenizer, BertModel
import torch
# 1. Initialize the Tokenizer and the Model
# We use 'bert-base-uncased', a smaller, efficient version of BERT
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 2. Preprocess the text
text = "The bank of the river is muddy."
# return_tensors='pt' tells it to return PyTorch tensors
inputs = tokenizer(text, return_tensors="pt")
# 3. Pass the input through the model
# We use 'no_grad()' because we are only extracting features, not training
with torch.no_grad():
outputs = model(**inputs)
# 4. Extract the features
# 'last_hidden_state' contains vectors for all words
# We usually want the [CLS] token, which is at index 0
cls_embedding = outputs.last_hidden_state[:, 0, :]
print(f"Vector shape: {cls_embedding.shape}")
print(cls_embedding[0][:5])
|
在此代码块中,我们首先加载 BertTokenizer 和 BertModel。分词器将文本分解成模型可识别的片段。然后我们将这些标记传递给模型。torch.no_grad() 上下文管理器用于告诉 PyTorch 我们不需要计算梯度,这可以节省内存和计算资源,因为我们只进行推理(提取),而不是训练。
outputs 变量包含神经网络最后一层的激活值。我们对该张量进行切片以获取 [:, 0, :]。这个特定的切片定位序列中的第一个标记,即前面提到的 [CLS] 标记。这个单一的向量(对于 BERT Base 通常是 768 个数字长)包含句子深层次的、上下文感知的表示。与 GloVe 平均值不同,该向量“知道”此句子中的“bank”指的是河流,因为它在处理过程中“关注”了“river”和“muddy”这些词。
结论
我们已经遍历了从简单到复杂的文本特征工程的领域。我们从 TF-IDF 开始,这是一种在关键词匹配方面表现出色的统计方法,对于简单的文档检索或垃圾邮件过滤仍然非常有效。我们转向了 GloVe 等平均词嵌入,它引入了语义含义,使模型能够理解同义词和类比。最后,我们研究了基于 Transformer 的嵌入,它们提供了支撑当今最先进人工智能应用的深度、上下文感知的表示。
这三种技术之间没有单一的“最佳”技术;只有最适合您约束的技术。TF-IDF 速度快、可解释性强,不需要繁重的硬件。Transformer 提供了最高的准确性,但需要大量的计算能力和内存。作为一名数据科学家或工程师,您的职责是在这些权衡之间取得平衡,以便为您的特定问题构建最有效的解决方案。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区