



📢 转载信息
原文作者:Amit Modi and Sandeep Raveesh-Babu
构建定制的基础模型需要协调开发生命周期中的多个资产,例如数据资产、计算基础设施、模型架构和框架、血缘关系以及生产部署。数据科学家创建和完善训练数据集,开发自定义评估器以评估模型质量和安全性,并迭代微调配置以优化性能。随着这些工作流在团队和环境中扩展,跟踪是哪个特定的数据集版本、评估器配置和超参数产生了每个模型变得很困难。团队通常依赖于笔记本或电子表格中的手动文档记录,这使得重现成功的实验或理解生产模型的血缘关系变得困难。
在具有多个用于开发、暂存和生产的 AWS 账户的企业环境中,这种挑战会加剧。随着模型在部署管道中迁移,保持对其训练数据、评估标准和配置的可见性需要大量的协调。如果没有自动化跟踪,团队将失去将部署的模型追溯到其来源或在实验中一致共享资产的能力。Amazon SageMaker AI 支持跟踪和管理生成式 AI 开发中使用的资产。借助 Amazon SageMaker AI,您可以注册和版本化模型、数据集和自定义评估器,然后在微调、评估和部署生成式 AI 模型时自动捕获关系和血缘关系。这减少了手动跟踪的开销,并提供了关于模型如何创建的完整可见性,从基础模型到生产部署。
在这篇博文中,我们将探讨帮助组织跟踪和管理模型开发和部署生命周期的新功能和核心概念。我们将向您展示这些功能的配置方式,以实现从数据集上传和版本控制到模型微调、评估和无缝端点部署的自动端到端血缘关系。
跨实验管理数据集版本
随着您完善模型的训练数据,您通常会创建数据集的多个版本。随着数据的演变,您可以注册数据集并创建新版本,每个版本都会被独立跟踪。当您在 SageMaker AI 中注册数据集时,您需要提供 S3 位置和描述数据集的元数据。当您改进数据时——无论是添加更多示例、提高质量还是调整以适应特定用例——您都可以为同一数据集创建新版本。如下面的图像所示,每个版本都维护其自己的元数据和 S3 位置,因此您可以随着时间的推移跟踪训练数据的演变。
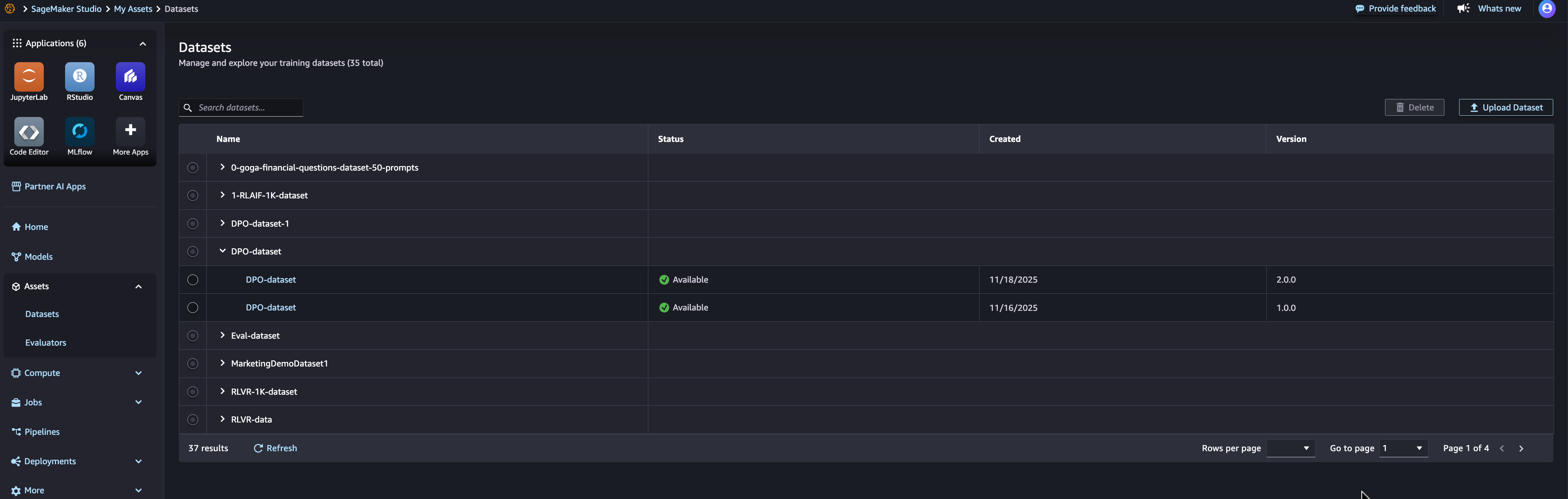
当您将数据集用于微调时,Amazon SageMaker AI 会自动将特定的数据集版本与生成的模型相关联。这支持在用不同数据集版本训练的模型之间进行比较,并帮助您了解哪些数据改进带来了更好的性能。您还可以跨多个实验重用相同的数据集版本,以确保在测试不同超参数或微调技术时保持一致性。
创建可重用的自定义评估器
评估自定义模型通常需要特定于领域的质量、安全或性能标准。自定义评估器由接收输入数据并返回包括分数和验证状态在内的评估结果的 Lambda 函数代码组成。您可以为各种目的定义评估器——检查响应质量、评估安全性和毒性、验证输出格式或测量任务特定准确性。您可以使用实现评估逻辑的 AWS Lambda 函数来跟踪自定义评估器,然后跨模型和数据集版本化和重用这些评估器,如下面的图像所示。
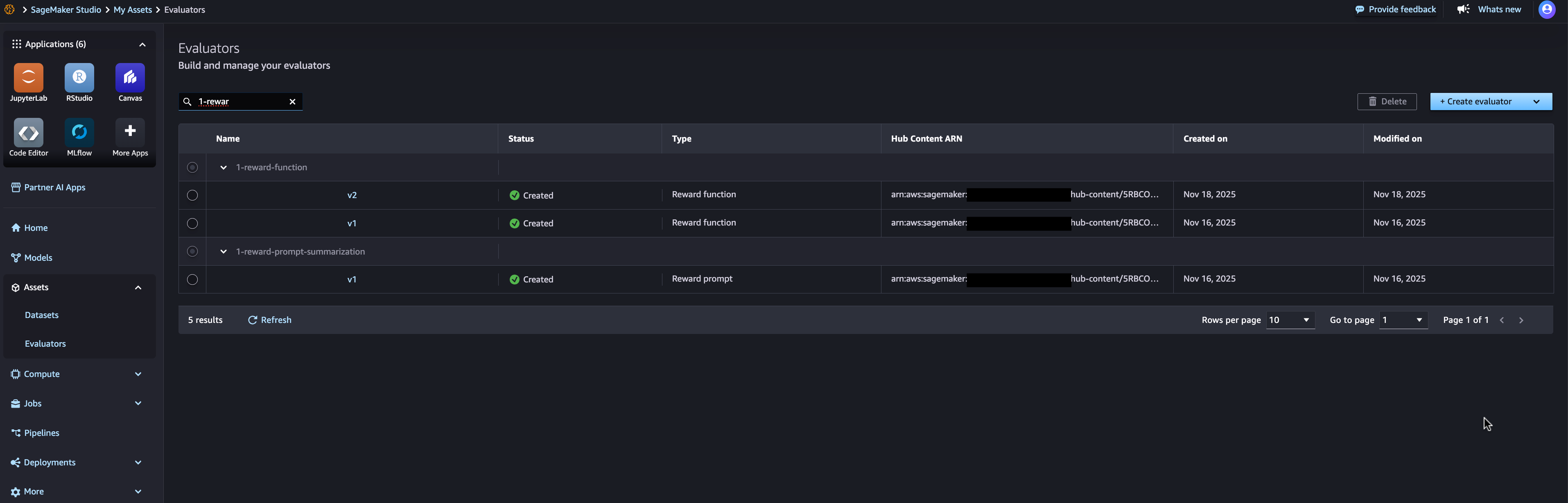
贯穿开发生命周期的自动血缘关系跟踪
SageMaker AI 的血缘关系跟踪功能会在您构建和评估模型时自动捕获资产之间的关系。当您创建微调作业时,Amazon SageMaker AI 会将训练作业与输入数据集、基础模型和输出模型相关联。当您运行评估作业时,它会将评估与被评估的模型和使用的评估器连接起来。这种自动血缘关系捕获意味着您无需手动记录每个实验中使用了哪些资产。您可以查看模型的完整血缘关系,其中显示了其基础模型、带有特定版本的训练数据集、超参数、评估结果和部署位置,如下面的图像所示。
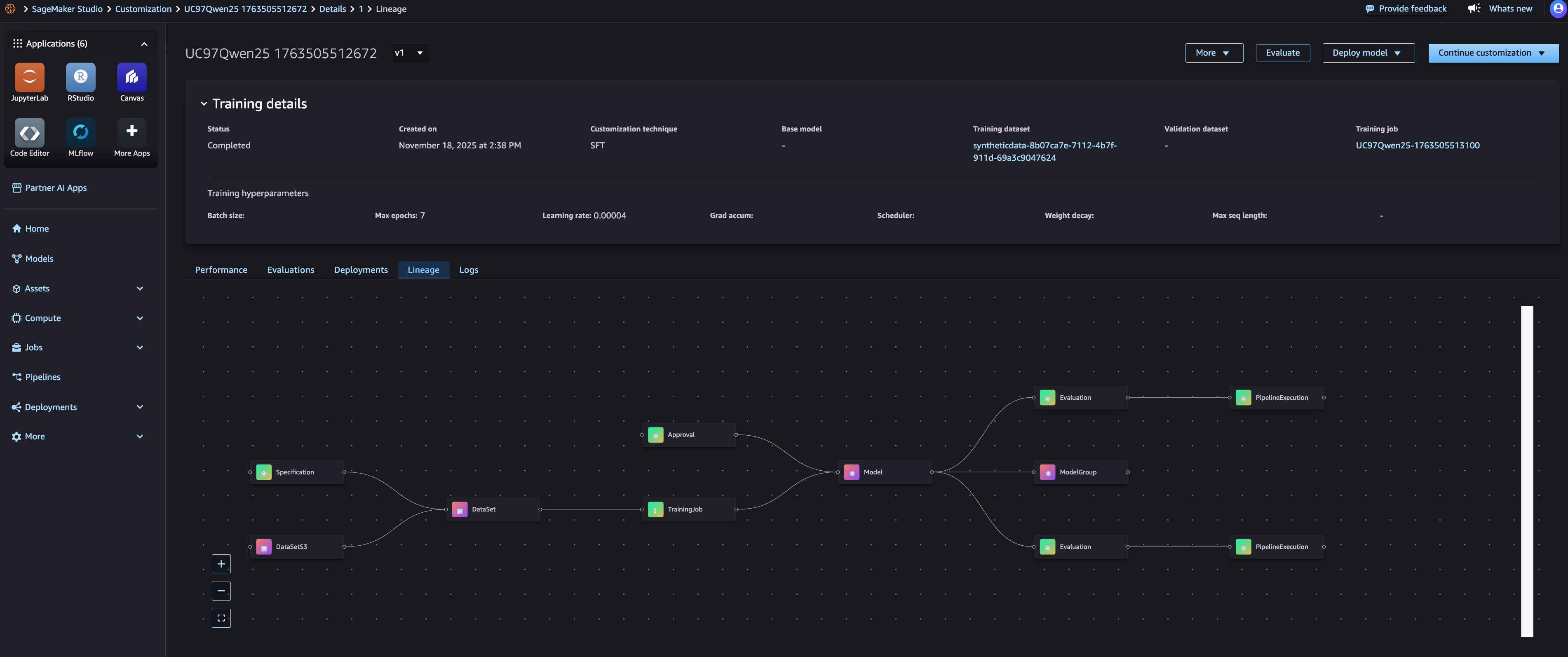
通过血缘关系视图,您可以将任何已部署的模型追溯到其起源。例如,如果您需要了解生产模型为何以某种方式运行,您可以确切地看到使用了哪些训练数据、微调配置和评估标准。这对于治理、可重现性和调试目的尤其有价值。您还可以使用血缘关系信息来重现实验。通过识别用于成功模型的确切数据集版本、评估器版本和配置,您可以自信地使用相同的输入来重建训练过程。
与 MLflow 集成以进行实验跟踪
Amazon SageMaker AI 的模型定制功能默认与 SageMaker AI MLflow 应用程序集成,从而在模型训练作业和 MLflow 实验之间实现自动链接。当您运行模型定制作业时,所有必要的 MLflow 操作都会为您自动执行——默认的 SageMaker AI MLflow 应用程序会自动使用,为您选择一个 MLflow 实验,并为您记录所有指标、参数和工件。从 SageMaker AI Studio 的模型页面,您将能够看到源自 MLflow 的指标(如下面的图像所示),并进一步在相关的 MLflow 实验中查看完整指标。
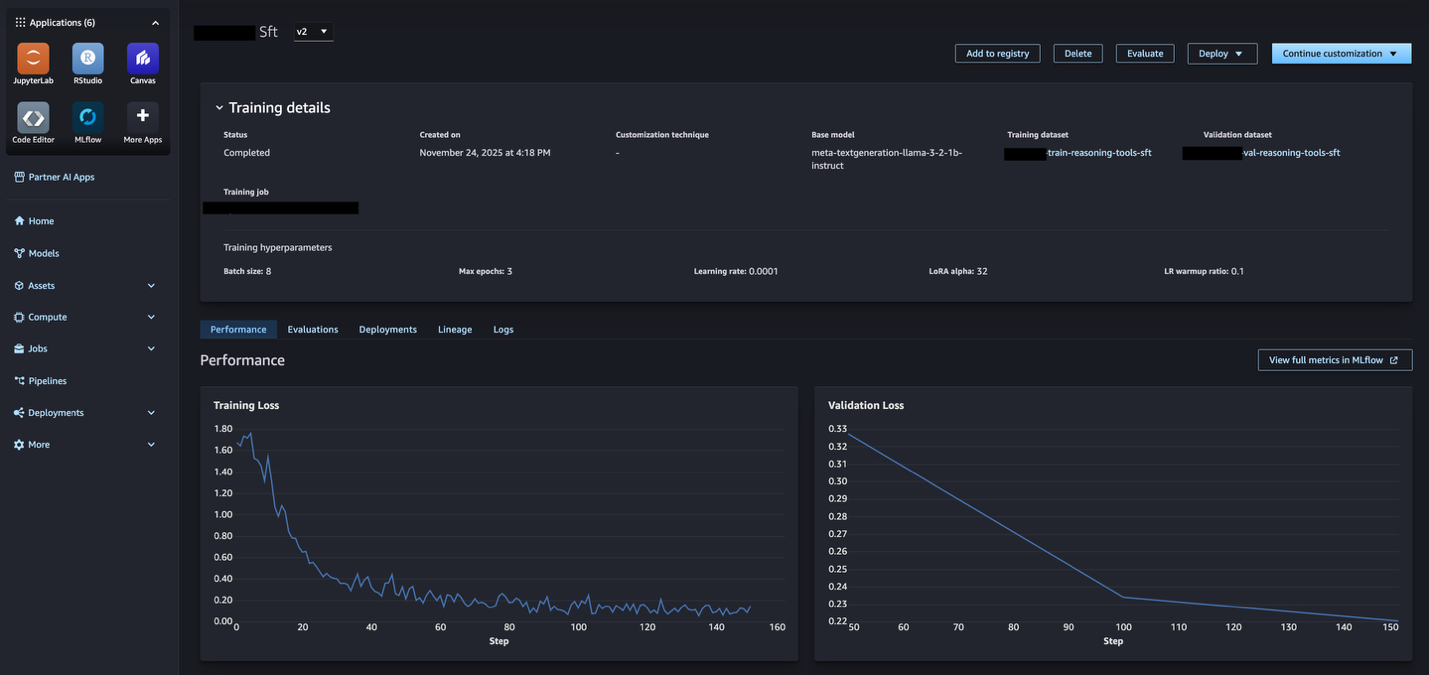
通过 MLflow 集成,比较多个模型候选变得非常简单。您可以使用 MLflow 可视化跨实验的性能指标,确定性能最佳的模型,然后使用血缘关系来了解哪些特定的数据集和评估器产生了该结果。这有助于您根据定量指标和资产来源,就推广到生产中的模型做出明智的决定。
开始使用跟踪和管理生成式 AI 资产
通过整合这些各种模型定制资产和流程——数据集版本控制、评估器跟踪、模型性能、模型部署——您可以将分散的模型资产转化为具有自动端到端血缘关系的可跟踪、可重现且可投入生产的工作流。此功能现已在受支持的 AWS 区域中提供。您可以通过 Amazon SageMaker AI Studio 和 SageMaker python SDK 访问此功能。
开始操作:
- 打开 Amazon SageMaker AI Studio 并导航到 Models 部分。
- 定制 JumpStart 基础模型以创建模型。
- 导航到 Assets 部分以管理数据集和评估器。
- 通过提供 S3 位置和元数据来注册您的第一个数据集。
- 使用现有的 Lambda 函数创建自定义评估器或创建一个新的。
- 在微调作业中使用已注册的数据集——血缘关系会自动捕获。
- 查看模型的血缘关系以查看完整的关系。
欲了解更多信息,请访问 Amazon SageMaker AI 文档。
关于作者
 Amit Modi 是 AWS SageMaker AI MLOps、ML 治理和推理的产品负责人。凭借十多年的 B2B 经验,他构建了推动创新并为全球客户带来价值的可扩展产品和团队。
Amit Modi 是 AWS SageMaker AI MLOps、ML 治理和推理的产品负责人。凭借十多年的 B2B 经验,他构建了推动创新并为全球客户带来价值的可扩展产品和团队。
 Sandeep Raveesh 是 AWS 的 GenAI 专家解决方案架构师。他通过模型训练、像 Agent 这样的 GenAI 应用以及扩展 GenAI 用例来引导客户完成其 AIOps 之旅。他还专注于上市战略,帮助 AWS 构建和调整产品,以解决生成式 AI 领域中的行业挑战。 您可以在 LinkedIn 上与 Sandeep 联系,了解有关 GenAI 解决方案的信息。
Sandeep Raveesh 是 AWS 的 GenAI 专家解决方案架构师。他通过模型训练、像 Agent 这样的 GenAI 应用以及扩展 GenAI 用例来引导客户完成其 AIOps 之旅。他还专注于上市战略,帮助 AWS 构建和调整产品,以解决生成式 AI 领域中的行业挑战。 您可以在 LinkedIn 上与 Sandeep 联系,了解有关 GenAI 解决方案的信息。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区