



📢 转载信息
原文作者:Mark Hoover and Ankit Mathur
用户可以在数据环境中(如 Snowflake)使用 Snowpark 库进行机器学习 (ML) 数据实验。然而,由于难以维护一个中央存储库来监控实验元数据、参数、超参数、模型、结果和其他相关信息,跨不同环境跟踪这些实验具有挑战性。在本文中,我们演示了如何集成 Amazon SageMaker 托管的 MLflow 作为中央存储库来记录这些实验,并提供一个统一的系统来监控它们的进度。
Amazon SageMaker 托管的 MLflow 提供了用于实验跟踪、模型打包和模型注册的完全托管服务。SageMaker 模型注册表简化了模型版本控制和部署,有助于开发到生产的无缝过渡。此外,与 Amazon S3、AWS Glue 和 SageMaker 特征存储的集成增强了数据管理和模型可追溯性。将 MLflow 与 SageMaker 结合使用的主要好处是,它允许组织标准化 ML 工作流程、改进协作,并通过更安全、更具可扩展性的基础设施加速人工智能 (AI)/ML 的采用。在本文中,我们将展示如何将 Amazon SageMaker 托管的 MLflow 与 Snowflake 集成。
Snowpark 允许使用 Python、Scala 或 Java 来创建自定义数据管道,以便在将训练数据存储在 Snowflake 中时进行高效的数据操作和准备。用户可以在 Snowpark 中进行实验,并在 Amazon SageMaker 托管的 MLflow 中跟踪它们。 这种集成允许数据科学家在 Snowflake 中运行转换和特征工程,并利用 SageMaker 中的托管基础设施进行训练和部署,从而促进更无缝的工作流程编排和更安全的数据处理。
解决方案概述
该集成利用了 Snowpark for Python,这是一个客户端库,允许 Python 代码通过诸如 SageMaker 的 Jupyter notebook 等 Python 内核与 Snowflake 进行交互。一个工作流程可能包括在 Snowflake 中进行数据准备,以及在 Snowpark 中进行特征工程和模型训练。然后,Amazon SageMaker 托管的 MLflow 可用于与 SageMaker 功能集成的实验跟踪和模型注册。
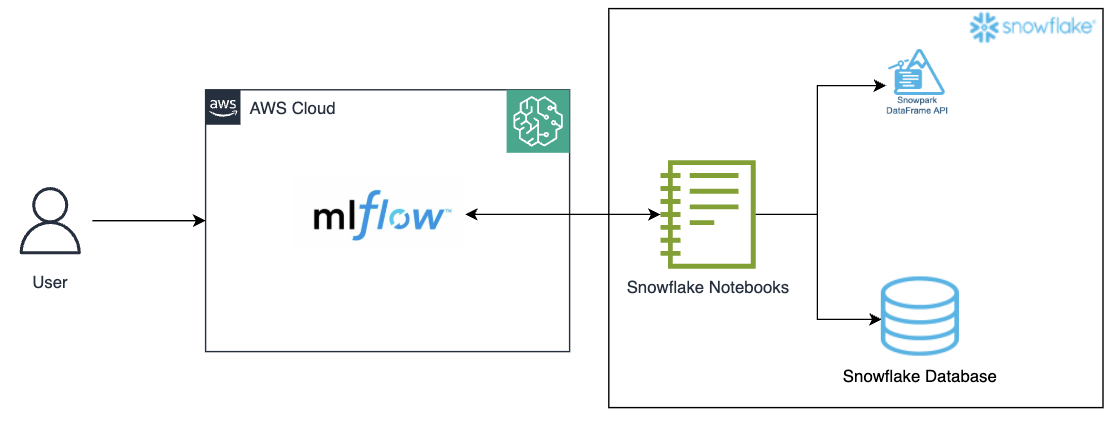
图 1:架构图
使用 MLflow Tracking 捕获关键细节
MLflow Tracking 在 SageMaker、Snowpark 和 Snowflake 的集成中非常重要,它提供了一个集中环境来记录和管理整个机器学习生命周期。随着 Snowpark 处理来自 Snowflake 的数据并训练模型,MLflow Tracking 可用于捕获关键细节,包括模型参数、超参数、指标和制品。这使得数据科学家能够监控实验、比较不同模型版本并验证可重现性。借助 MLflow 的版本控制和日志记录功能,团队可以无缝地将结果追溯到所使用的特定数据集和转换,从而更轻松地随着时间的推移跟踪模型的性能并维护透明高效的 ML 工作流程。
这种方法提供了几项好处。它允许在 SageMaker 中实现可扩展且托管的 MLflow 跟踪器,同时利用 Snowpark 在 Snowflake 环境中进行模型推理的处理能力,从而创建一个统一的数据系统。工作流程保留在 Snowflake 环境内,这增强了数据安全性和治理。此外,这种设置通过利用 Snowflake 的弹性计算能力进行推理,而无需维护单独的基础设施进行模型服务,从而有助于降低成本。
先决条件
在建立 Amazon SageMaker MLflow 之前,请创建/配置以下资源并确认对上述资源的访问权限:
- 一个 Snowflake 账户
- 一个 S3 存储桶,用于在 MLflow 中跟踪实验
- 一个 Amazon SageMaker Studio 账户
- 一个 AWS 身份和访问管理 (IAM) 角色,它是 AWS 账户中的 Amazon SageMaker 域执行角色。
- 一个拥有权限访问上述 S3 存储桶的新用户;请遵循这些步骤。
- 通过 AWS 管理控制台 和 AWS 命令行界面 (AWS CLI) 确认对 AWS 账户的访问权限。 AWS 身份和访问管理 (IAM) 用户必须具有权限来执行必要的 AWS 服务调用并管理本文中提到的 AWS 资源。在授予 IAM 用户权限时,遵循 最小权限原则。
- 按照这些步骤配置对上述 Amazon S3 存储桶的访问权限。
- 按照这些步骤为 Snowflake Notebooks 设置外部访问。
从 Snowflake 调用 SageMaker 的 MLflow Tracking Server 的步骤
我们现在建立 Snowflake 环境并将其连接到我们之前设置的 Amazon SageMaker MLflow Tracking Server。
- 按照这些步骤在Amazon SageMaker Studio中创建 Amazon SageMaker 托管的 MLflow Tracking Server。
- 以管理员身份登录 Snowflake。
- 在Snowflake中创建一个新的 Notebook
- Projects > Notebooks > +Notebook
- 将角色更改为非管理员角色
- 指定一个名称,选择一个数据库 (DB)、模式、仓库,并选择“在容器上运行”

- Notebook 设置 > 外部访问 > 切换开启以允许所有集成
- 安装库
!pip install sagemaker-mlflow
- 通过替换以下代码中的 arn 值来运行 MLflow 代码:
import mlflow import boto3 import logging sts = boto3.client("sts") assumed = sts.assume_role( RoleArn="<AWS-ROLE-ARN>", RoleSessionName="sf-session" ) creds = assumed["Credentials"] arn = "<ml-flow-arn>" try: mlflow.set_tracking_uri(arn) mlflow.set_experiment("Default") with mlflow.start_run(): mlflow.log_param("test_size", 0.2) mlflow.log_param("random_state", 42) mlflow.log_param("model_type", "LinearRegression") except Exception as e: logging.error(f"Failed to set tracking URI: {e}")

图 3:安装 sagemaker-mlflow 库

图 4:配置 MLflow 并进行实验。
成功运行后,可以在 Amazon SageMaker 上跟踪实验:
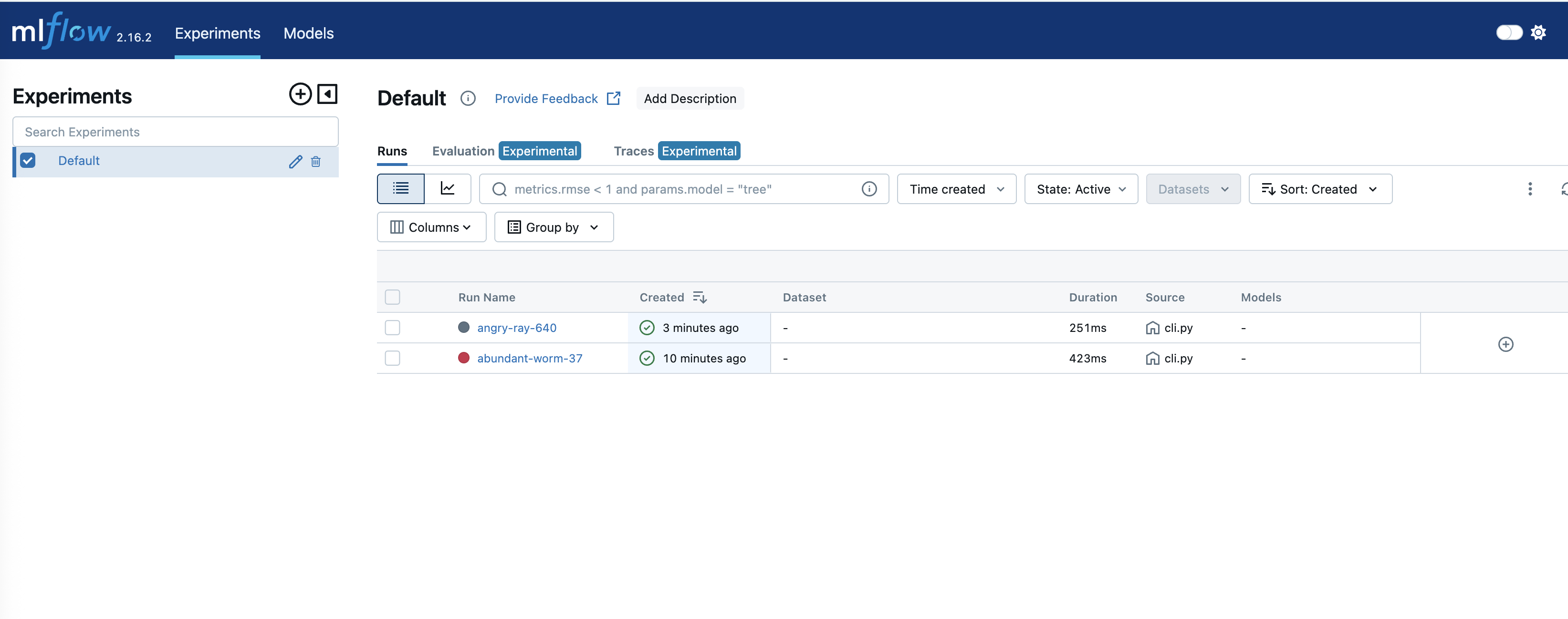
图 5:在 SageMaker MLflow 中跟踪实验
要深入了解实验详情,请单击相应的“运行名称:”
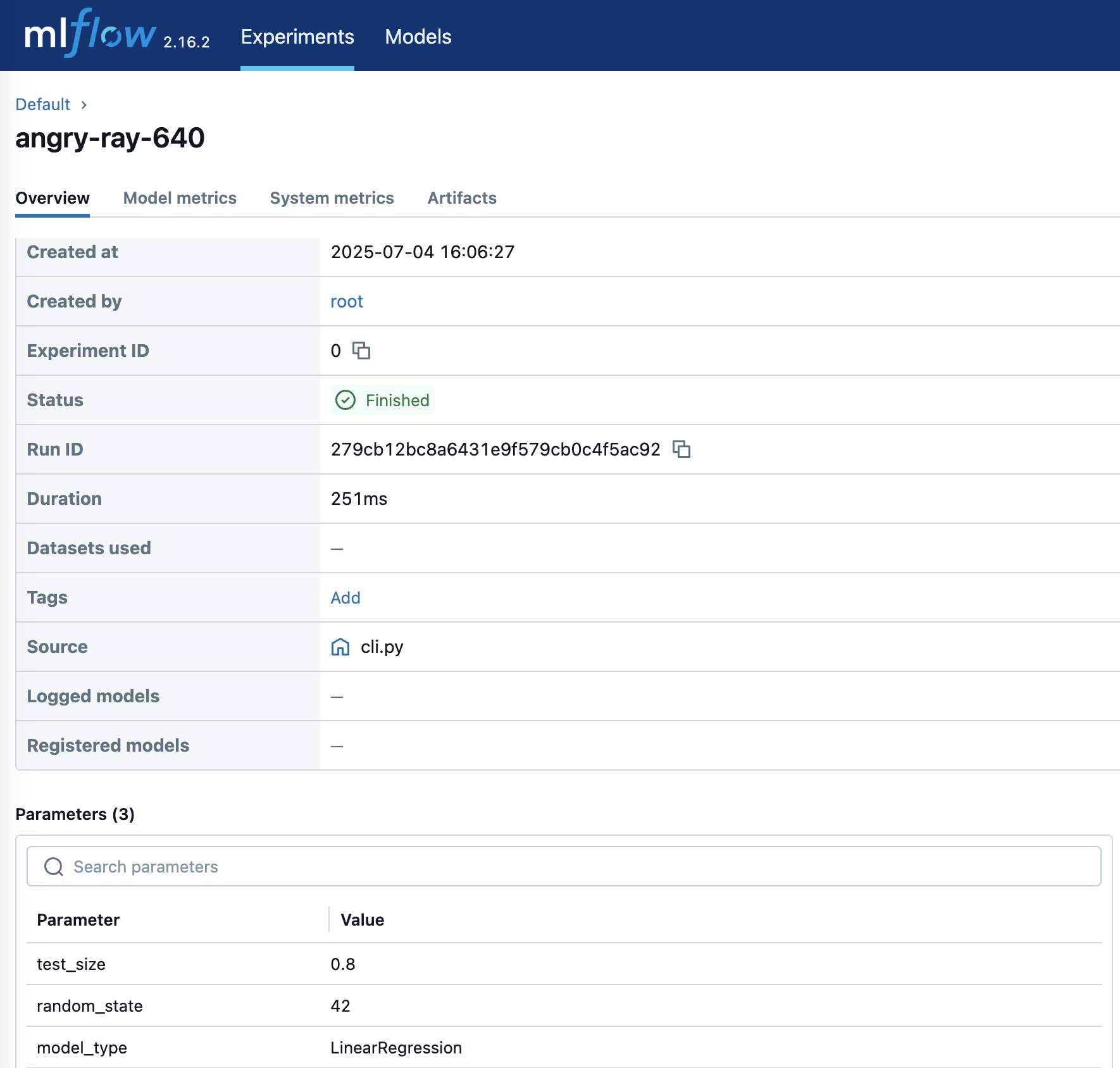
图 6:体验详细的实验洞察
清理
请遵循以下步骤清理我们在本文中配置的资源,以帮助避免持续的成本。
- 通过遵循这些步骤删除 SageMaker Studio 账户,这将同时删除 MLflow 跟踪服务器
- 删除 S3 存储桶及其内容
- 删除 Snowflake Notebook
- 确认 Amazon SageMaker 账户已删除
结论
在本文中,我们探讨了 Amazon SageMaker 托管的 MLflow 如何为管理机器学习生命周期提供全面的解决方案。与 Snowflake 通过 Snowpark 的集成进一步增强了此解决方案,有助于实现无缝的数据处理和模型部署工作流程。
要开始使用,请按照上面提供的分步说明在 Amazon SageMaker Studio 中设置 MLflow Tracking Server 并将其与 Snowflake 集成。请记住,通过实施适当的 IAM 角色和权限并妥善保护所有凭据,遵循 AWS 安全最佳实践。
本文中的代码示例和说明可作为起点——它们可以根据特定的用例和要求进行调整,同时保持安全性和可扩展性的最佳实践。
关于作者
 Ankit Mathur 是 AWS 的解决方案架构师,专注于现代数据平台、AI 驱动分析和 AWS-合作伙伴集成。他帮助客户和合作伙伴设计安全、可扩展的架构,以实现可衡量的业务成果。
Ankit Mathur 是 AWS 的解决方案架构师,专注于现代数据平台、AI 驱动分析和 AWS-合作伙伴集成。他帮助客户和合作伙伴设计安全、可扩展的架构,以实现可衡量的业务成果。
 Mark Hoover 是 AWS 的高级解决方案架构师,致力于帮助客户在云中构建他们的想法。他与许多企业客户合作,将复杂的业务战略转化为推动长期增长的创新解决方案。
Mark Hoover 是 AWS 的高级解决方案架构师,致力于帮助客户在云中构建他们的想法。他与许多企业客户合作,将复杂的业务战略转化为推动长期增长的创新解决方案。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区