



📢 转载信息
原文链接:http://bair.berkeley.edu/blog/2025/03/25/rl-av-smoothing/
原文作者:BAIR Blog
我们成功将100辆由强化学习 (RL) 控制的车辆投入到繁忙的高速公路早高峰中,旨在平滑交通拥堵并降低所有人的燃料消耗。我们的目标是解决令人沮丧的“走走停停”波(stop-and-go waves),这些波动通常没有明确的成因,却会导致严重的交通拥堵和能源浪费。
幽灵堵车的挑战

如果您经常开车,一定经历过这种莫名其妙的交通迟滞。这种波动源于驾驶行为的小幅度波动,并在交通流中被放大。由于人类驾驶员的反应时间存在延迟,往往会产生比前车更剧烈的刹车动作,这种效应会像多米诺骨牌一样向后传播,最终导致交通停滞,增加油耗和排放。
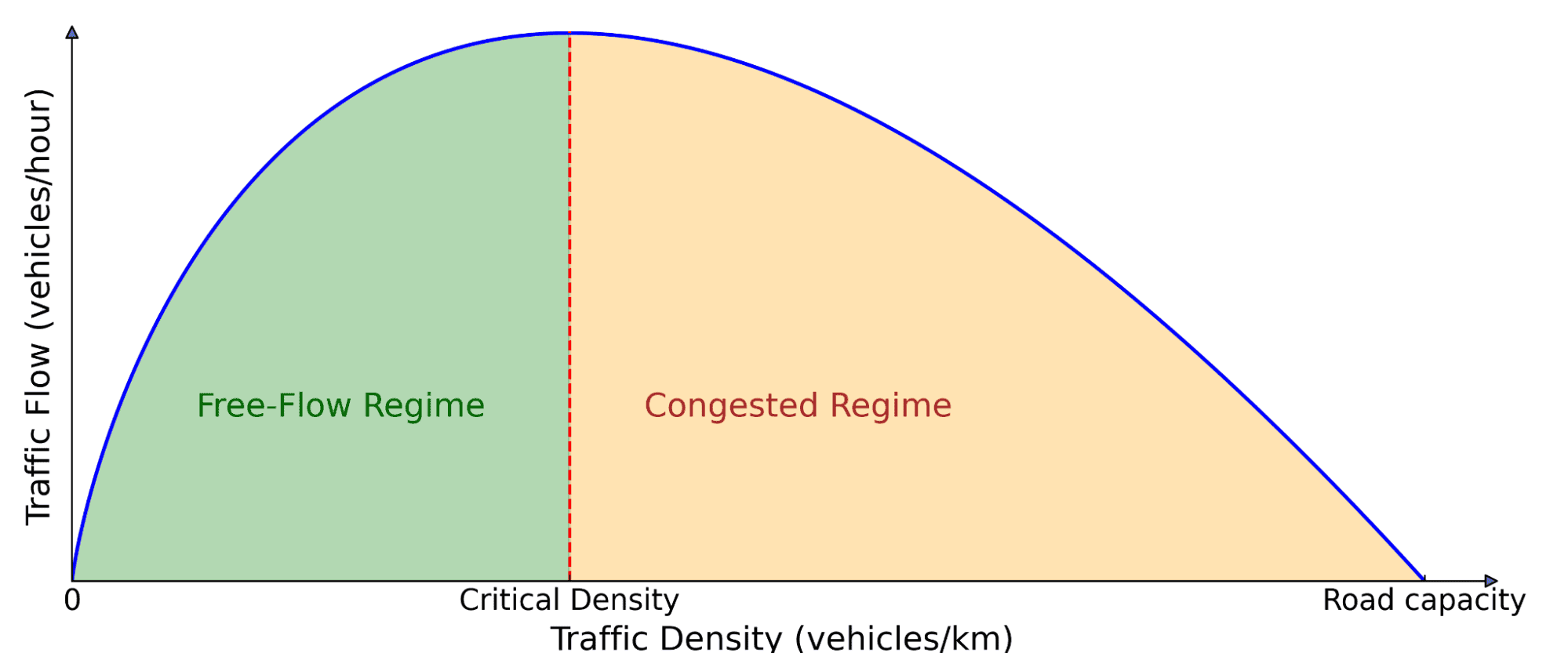
利用强化学习平滑交通波
我们利用强化学习(RL)通过与交通环境的交互学习优化策略,以抑制波动的传播。我们基于田纳西州 Nashville 的 I-24 高速公路实验数据构建了数据驱动的模拟环境,让 RL 代理在其中学习如何平滑交通流。关键优势在于,这些控制器仅需感知自身及前车的速度和距离,因此无需昂贵的外部基础设施即可在现代量产车上部署。
奖励设计
为了平衡波平滑、燃油效率、安全性和驾驶舒适度,我们设计了精密的奖励函数。如果过度强调燃油效率,RL 可能学会为了节能而在高速公路上停车;因此,我们引入了动态间距阈值,确保在节能的同时兼顾交通安全和人类驾驶习惯。
100辆车的大规模实测:从模拟到公路
基于模拟实验的成功,我们发起了名为“MegaVanderTest”的实测项目,将训练好的模型部署在100辆真实车辆上。实验证明,当公路上拥有少于 5% 的此类智控车辆时,即可显著改善周围车辆的驾驶效率,实现 15% 到 20% 的能源节省。
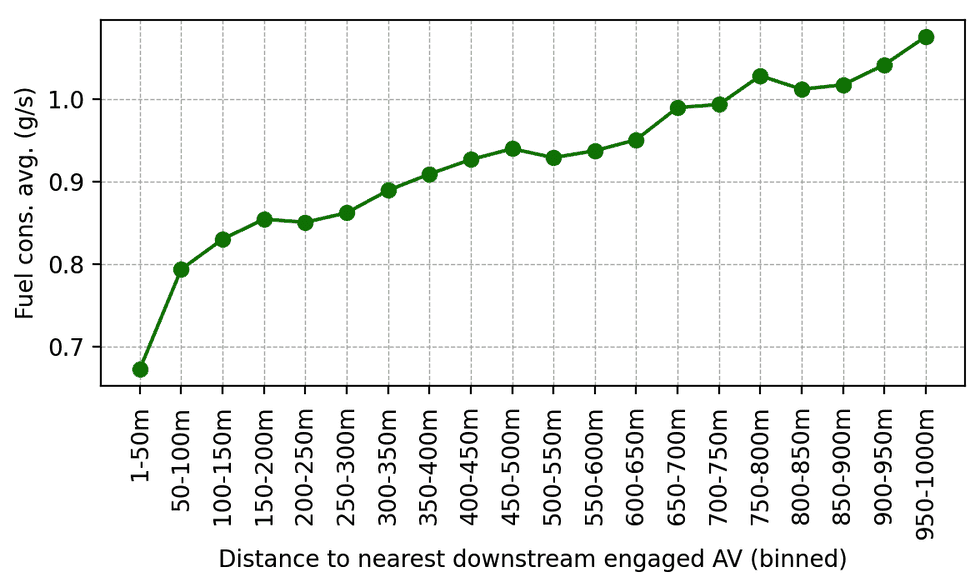
本次实验展示了去中心化控制在实际道路中的可行性。未来,我们将继续探索更快的仿真技术以及 5G 通信下的多智能体协作,以进一步消除交通拥堵,实现更绿色的出行。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区