



📢 转载信息
原文作者:Aditya Singh, Andrew Browning, Anthony Doolan, Chiheb Boussema, Jeff Burke, Jerome Ronquillo, Lakshmi Dasari, and Naisha Agarwal
本文由来自UCLA的Andrew Browning、Anthony Doolan、Jerome Ronquillo、Jeff Burke、Chiheb Boussema和Naisha Agarwal与我们合作撰写。
加州大学洛杉矶分校(UCLA)拥有16位诺贝尔奖得主,并连续8年被评为美国排名第一的公立大学。UCLA的高级研究计算办公室(OARC)是研究企业的技术拓展合作伙伴,提供智力和技术专长,将研究变为现实。UCLA媒体与表演研究与工程中心(REMAP)找到了OARC,希望构建一套AI微服务,以支持音乐剧《Xanadu》的沉浸式制作。
REMAP与UCLA戏剧系的Ray Bolger音乐剧专业合作制作的《Xanadu》,被设计为一种沉浸式、参与性的表演。在此期间,观众通过使用手机手势在13 x 9英尺的LED屏幕(称为“神龛”)上绘制图像,与舞台上的媒体进行协作创作。这些屏幕由4Wall Entertainment提供,并通过Mo-Sys StarTrackers进行位置跟踪。绘制的图像随后通过AWS微服务进行推理,结果媒体被重新投射回神龛,作为AI生成的2D图像和3D网格,出现在演出的数字场景中(使用Unreal Engine,由Boxx提供硬件支持)。OARC成功为7场演出以及排练和试演设计并实施了解决方案。演出于2025年5月15日至5月23日期间进行,总共有约500名观众参与,演出中最多有65名观众同时共同创作媒体。
在本文中,我们将回顾OARC和REMAP在性能限制和设计选择方面的工作,包括AWS的无服务器基础设施、AWS托管服务以及生成式AI服务如何支持我们解决方案的快速设计和部署。我们还将介绍我们对Amazon SageMaker AI的使用,以及它如何在沉浸式现场体验中可靠地应用。我们将概述所使用的模型,并描述它们如何促成观众共同创作的媒体。我们还将回顾在排练和演出期间控制成本的机制。最后,我们将分享经验教训以及我们计划在项目第二阶段进行的改进。
解决方案概述
OARC的解决方案旨在实现在现场演出期间的近实时(NRT)推理,其高层要求包括:
- 微服务对每场演出都有严格的最低并发要求,需要支持80部移动电话用户(容纳65名观众和12名表演者)
- 从手机草图到媒体呈现的平均往返时间(MRTT)必须低于2分钟,以便在演出进行时即可准备好,提供最佳的观众体验
- AWS GPU资源在排练和演出期间必须具备容错能力和高可用性,无法接受降级运行
- 需要一个“人在回路”(Human-in-the-loop)的仪表板,以便在需要人工干预时提供对基础设施资源的手动控制
- 架构必须足够灵活,能够处理演出到演出的修改,因为开发人员会不断发现解决问题的新方法
考虑到上述限制,我们设计了采用无服务器优先架构方法的系统来处理大部分工作负载。我们将HuggingFace模型部署在Amazon SageMaker AI上,并使用了Amazon Bedrock中可用的模型,创建了一个综合的推理管道,利用了这两个服务的灵活性和优势。Amazon Bedrock提供了对基础模型(如Anthropic Claude、Amazon Nova、Stable Diffusion)的简化和托管访问,而Amazon SageMaker AI则为来自HuggingFace的开源模型提供了完整的机器学习生命周期控制。
下图展示了手机草图创建与OARC AWS微服务之间交互的高层视图。
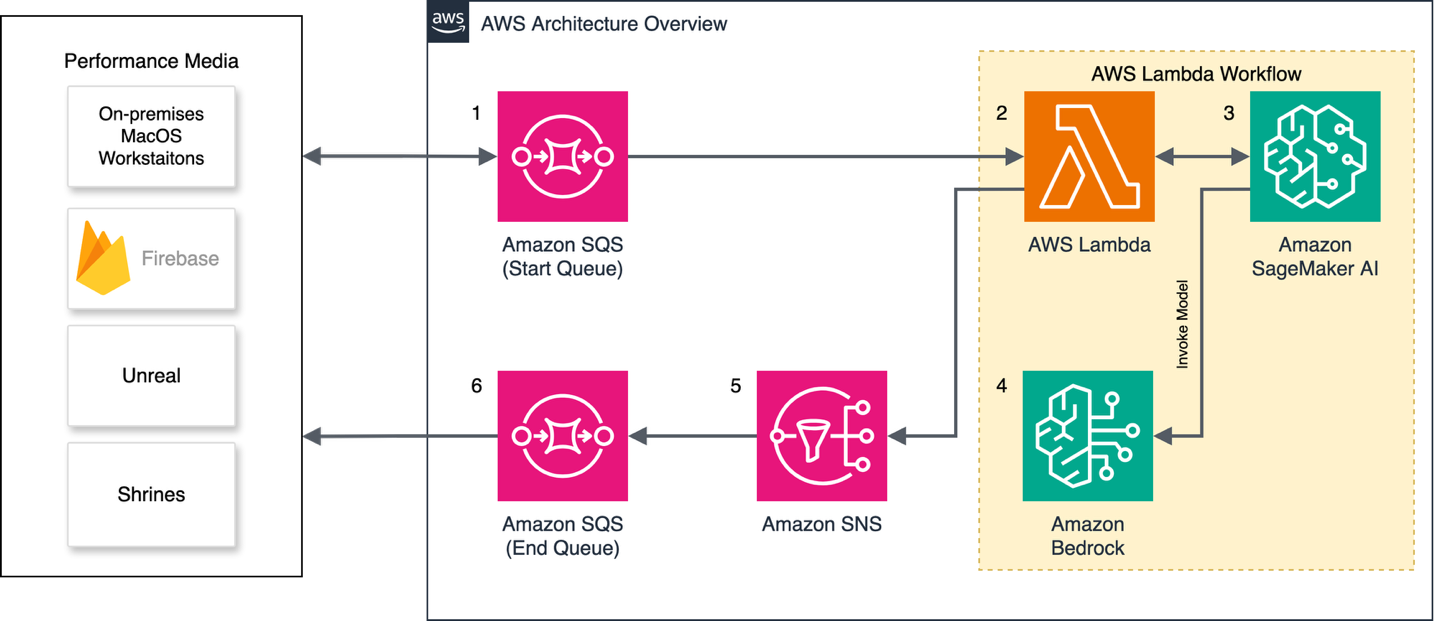
解决方案流程详解
OARC微服务应用程序设计采用了无服务器优先的方法,为事件驱动架构奠定了基础。用户草图通过低延迟的Firebase编排层传递给微服务,工作流通过一系列处理步骤进行协调,将用户草图转换为2D图像和3D网格。图左侧的几台本地MacOS工作站负责启动工作流、监控作业完成情况、执行“人在回路”审查,并将完成的资产发送回演出媒体服务器。
消息管道
传入的观众草图和元数据消息通过Amazon SQS从本地MacOS工作站发送,并由一个AWS Lambda辅助函数根据草图所需的推理处理类型(例如,2D图像、3D网格),将其分类到不同的子队列中。这种排序机制使应用程序能够精确控制其处理速率,从而确保繁忙的管道不会阻塞使用开放资源的其它管道中的新消息。
消息处理
第二个更复杂的Lambda函数监听来自已排序子队列的消息,并提供准备用户草图以进行推理的逻辑。该函数负责验证、错误/成功消息传递、并发处理以及预推理和后推理步骤的编排。这种设计采用了模块化方法,允许开发人员快速集成新功能,同时最大限度地减少合并冲突。由于存在“人在回路”的审查,我们没有对图像进行自动后处理。我们可以放心地相信,在将图像发送到神龛之前,所有问题都会被发现。未来,我们计划使用Amazon Bedrock中的护栏和其他对象检测方法,以及“人在回路”审查,来验证从SageMaker AI端点返回的资产。
我们的处理步骤需要大型Python依赖项,包括PyTorch。这些依赖项最大可扩展到5GB,对于Lambda层来说太大了。我们使用Amazon EFS来托管依赖项在一个单独的卷中,该卷在运行时挂载到Lambda函数。依赖项的大小增加了服务启动所需的时间,但在初始实例化后,后续的消息处理就非常高效了。启动期间增加的延迟是Lambda冷启动和延迟改进建议的理想应用场景。然而,由于这需要在项目后期对我们的开发流程进行一些调整,所以我们没有实施。
推理请求由24个SageMaker AI端点处理,其中8个端点负责处理这三个管道。我们使用Amazon EC2 G6实例系列来托管模型,使用了8个g6.12xlarge实例和16个g6.4xlarge实例。每个管道都包含一个特定的自定义工作流,以满足制作的特定请求类型。每个SageMaker AI端点都利用了内部加载的模型和托管在Amazon Bedrock上的大型LLM来完成每个请求(完整的工作流在接下来的AI工作流部分有详细介绍)。平均处理时间(从Amazon SageMaker AI作业启动到生成资产返回给AWS Lambda)在g6.4xlarge实例上约为40-60秒,在g6.12xlarge实例上约为20-30秒。
推理完成后,Lambda函数将消息发送到一个Amazon SNS主题,该主题负责发送成功电子邮件、发布到Amazon SQS,并更新一个Amazon DynamoDB表以供未来分析。本地MacOS工作站轮询最终队列以检索新完成的资产。
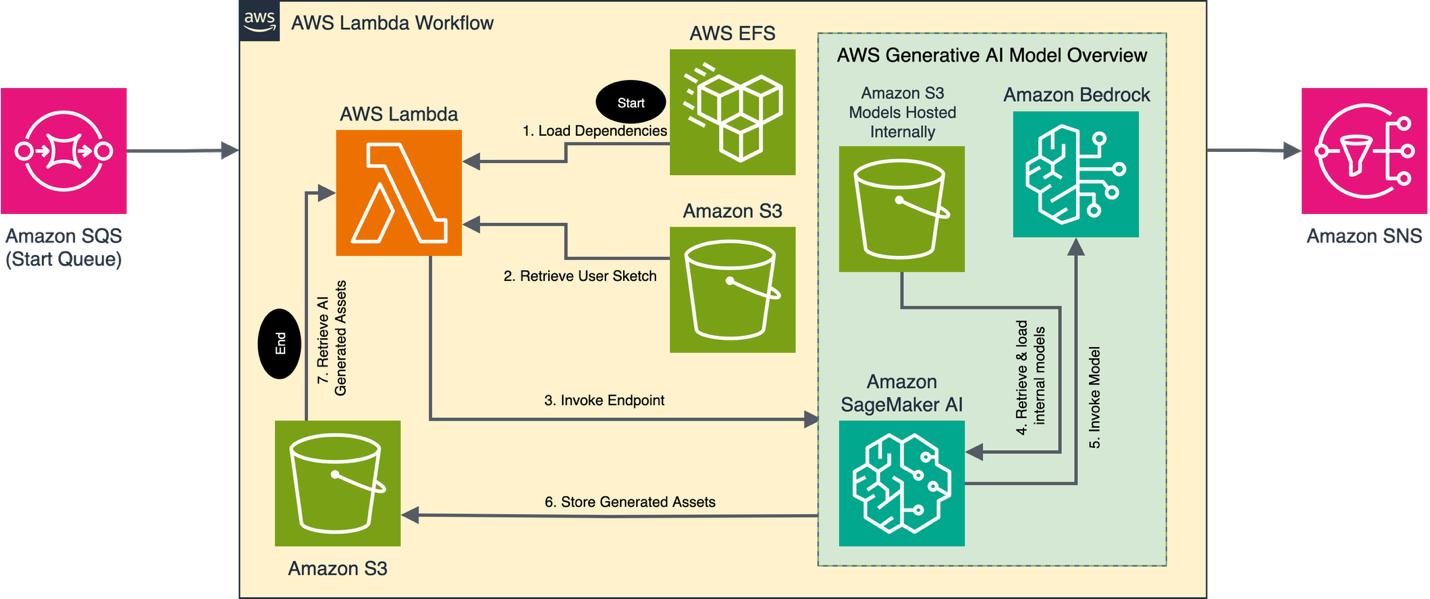
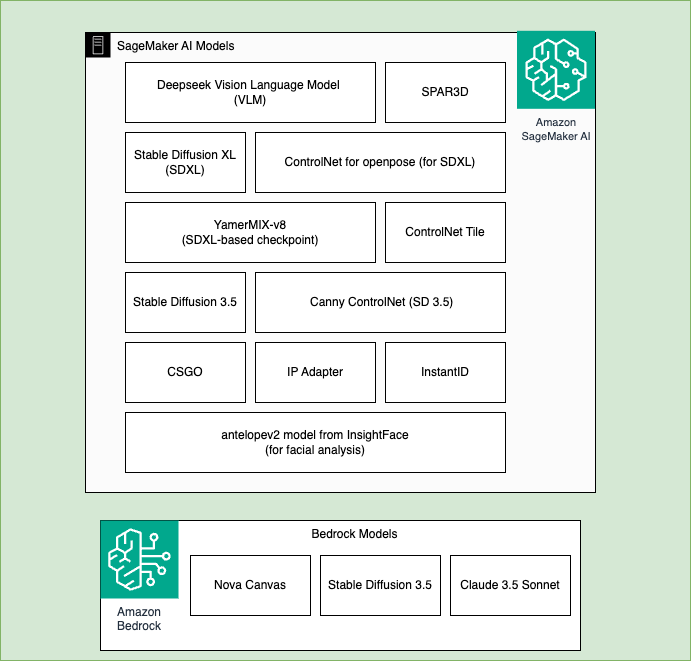
下图说明了Amazon SageMaker AI和Amazon Bedrock在我们的解决方案中使用的模型。Amazon SageMaker AI的模型包括:DeepSeek VLM、SDXL、Stable Diffusion 3.5、SPAR3D、ControlNet for openpose、Yamix-8、ControlNet Tile、ControlNet for canny edges、CSGO、IP Adapter、来自InsightFace的antelopev2模型。Amazon Bedrock使用的模型包括:Nova Canvas、Stable Diffusion 3.5和Claude 3.5 Sonnet。
AI工作流
该解决方案利用AWS进行三个独立的推理周期,称为模块。每个模块都有一个定制的AI工作流,利用一小组大中小型AI模型,生成用于演示的2D图像和3D网格对象。每个模块都从一个观众提示开始,要求参与者绘制一个特定任务的草图,例如创建背景、渲染3D对象的2D表示,或为缪斯(muses)设置自定义姿势和服装。AI工作流根据每个模块的要求处理这些图像。
每个模块首先生成用户草图的文本表示以及任何伴随的预先设计好的参考图像。为了实现这一点,我们使用了部署在Amazon SageMaker AI端点上的DeepSeek VLM或通过Amazon Bedrock使用的Anthropic的Claude 3.5 Sonnet模型。预先设计的图像包括各种戏剧性姿势、设计师服装以及旨在引导模型输出的辅助资产。接下来,这些描述、用户草图和补充资产被提供给本地扩散模型,并与ControlNet或类似框架配对,以生成所需的图像。在两个模块中,生成了较低分辨率的图像以减少推理时间。这些低质量图像被传入Amazon Bedrock中的Nova Canvas或Stable Diffusion 3.5,以快速生成更高质量的图像,具体取决于模块。例如,使用Nova Canvas时,我们使用IMAGE_VARIATION任务类型从DeepSeek VLM创建的低分辨率背景草图中生成了一个2048 x 512像素的图像。这种方法分担了一部分推理工作负载,使我们能够在不牺牲质量或速度的情况下运行更小的Amazon SageMaker AI实例类型。
然后工作流继续执行特定于每种输出类型的最终处理例程。对于背景图像,一个演员被叠加在图像底部边缘附近的变动位置。自定义姿势被转换为纹理对象,而对象草图通过图像到3D模型转换为3D网格对象。最后,Amazon SageMaker AI将图像资产存储在Amazon S3存储桶中,主AWS Lambda函数可以从中检索这些资产。
下图是其中一个模块使用和生成的资产示例。用户草图在左侧,演员照片在顶部,参考背景图像在底部,AI生成的图像在右侧。

持续部署和管理
代码到Lambda函数的部署由AWS CodeBuild处理。该作业负责监听GitHub上的拉取请求合并、更新EFS中的Python依赖项,并将更新部署到主Lambda函数。这种代码部署策略支持跨开发、暂存和生产环境的一致且可靠的更新,并消除了手动代码部署和更新的需要,从而降低了相关风险。
SageMaker AI端点通过一个定制的Web界面进行管理,该界面允许管理员部署“已知良好”的端点配置,从而实现快速的基础设施部署、快速重新部署和简单的关机。仪表板还包含有关Amazon SQS中运行的作业和Amazon CloudWatch Logs的指标,以便工作人员可以清除管道中的消息。
经验教训与改进
在完成了演出并通过事后诸葛亮进行反思后,我们对未来的迭代有一些建议和考虑。我们建议使用AWS CloudFormation或类似工具来减少对应用程序所用服务的手动部署和更新。许多开发人员遵循开发、暂存、生产管道来进行修改和增强,因此,与手动部署相比,自动化服务的配置将减少人为错误。
通过采用模块化、无服务器、事件驱动的方法,我们创建了一个可靠且易于维护的云架构。通过使用AWS托管服务,开发人员和管理员可以将精力集中在系统设计上,而不是系统维护上。总的来说,我们发现AWS托管服务表现出色,并提供了一种开发复杂技术架构的方法,以支持高风险环境中的实时图像推理。
该项目的性质创造了一个独特的用例。我们需要一种方法来处理突然涌入的大量推理请求。这种请求激增仅持续15分钟,因此我们需要创建一个既可靠又短暂的解决方案。我们评估了Amazon EC2和Amazon SageMaker AI作为按需部署20多个实例的主要选项。为了决定最佳系统,我们评估了以下几点:按需请求的可靠性、维护负担、复杂性、部署和负载平衡。Amazon EC2完全有能力满足这些要求,但是获取必要的按需实例很具有挑战性,并且维护如此多的主机带来了过度的维护负担。Amazon SageMaker AI满足了我们的所有标准,配置简单,部署可靠且简单,并具有集成的负载均衡服务。最终,我们选择将大部分模型托管在SageMaker AI上,并由Amazon Bedrock提供对Nova Canvas、Stable Diffusion 3.5和Claude 3.5 Sonnet等模型的托管无服务器访问。 Amazon EKS是另一种可能满足我们要求。它非常适合快速部署和无缝扩展,但我们认为Amazon SageMaker AI是该项目的正确选择,因为它配置速度快。
虽然SageMaker AI证明了对现场演出中实时推理的可靠支持,但它也占据了我们项目成本的最大份额——约占总云支出的40%。在排练和开发期间,我们观察到空闲或未使用的SageMaker AI端点可能是成本升级的主要来源。为减轻这种情况,我们使用Amazon EventBridge调度器和AWS Lambda实施了一个夜间自动化关机流程。这个简单的自动化步骤阻止了资源意外运行,帮助我们在不牺牲性能的情况下保持成本的可预测性。我们也在为第二阶段研究其他降本策略。
结论
通过有意识地选择使用AWS生成式AI服务和AWS托管服务来支持REMAP对音乐剧《Xanadu》的沉浸式制作,我们证明了利用AWS支持新颖、动态的娱乐形式是可能的。
我们展示了无服务器事件驱动架构是构建此类服务的快速且低成本的方法,并展示了Amazon Bedrock和Amazon SageMaker AI如何协同工作,以利用所有可用的生成式AI模型。我们描述了消息管道及其内部的消息处理过程。我们讨论了使用的生成式AI模型及其功能和实现。最后,我们展示了在该系统上继续开发沉浸式音乐剧的潜力。
《Xanadu》剧本:Douglas Carter Beane。音乐与歌词:Jeff Lynne & John Farrar。导演:Mira Winick & Corey Wright。
关于作者
 Andrew Browning 是加州大学洛杉矶分校(UCLA)高级研究计算办公室的研究数据和网络平台经理。他对AI在先进制造、医疗和牙科自我护理以及沉浸式性能领域的应用很感兴趣。他还热衷于创建可重用的PaaS应用程序来解决这些领域的常见问题。
Andrew Browning 是加州大学洛杉矶分校(UCLA)高级研究计算办公室的研究数据和网络平台经理。他对AI在先进制造、医疗和牙科自我护理以及沉浸式性能领域的应用很感兴趣。他还热衷于创建可重用的PaaS应用程序来解决这些领域的常见问题。
 Anthony Doolan 是OARC,UCLA研究数据和网络平台 | 基础设施支持服务的应用程序程序员和视听专家。Anthony Doolan是UCLA高级研究计算办公室的全栈Web开发人员和视听专家。他开发和维护本地和基于云的全栈Web应用程序,并提供视听系统集成和编程专业知识。
Anthony Doolan 是OARC,UCLA研究数据和网络平台 | 基础设施支持服务的应用程序程序员和视听专家。Anthony Doolan是UCLA高级研究计算办公室的全栈Web开发人员和视听专家。他开发和维护本地和基于云的全栈Web应用程序,并提供视听系统集成和编程专业知识。
 Jerome Ronquillo 是OARC,UCLA研究数据和网络平台的Web开发人员和云架构师。他专注于设计和实施将创新与实际应用相结合的可扩展、云原生解决方案。
Jerome Ronquillo 是OARC,UCLA研究数据和网络平台的Web开发人员和云架构师。他专注于设计和实施将创新与实际应用相结合的可扩展、云原生解决方案。
 Lakshmi Dasari Lakshmi是支持洛杉矶公共部门高等教育客户的高级解决方案架构师。她拥有丰富的企业IT架构、工程和管理经验,现在通过迁移和现代化路径帮助AWS客户实现云价值。在她之前担任AWS合作伙伴解决方案架构师的职位时,她通过AWS SI和ISV合作伙伴加速了客户的AWS采用。她热衷于技术中的包容性,并积极参与招聘和指导,以促进工作场所的人才多样性。
Lakshmi Dasari Lakshmi是支持洛杉矶公共部门高等教育客户的高级解决方案架构师。她拥有丰富的企业IT架构、工程和管理经验,现在通过迁移和现代化路径帮助AWS客户实现云价值。在她之前担任AWS合作伙伴解决方案架构师的职位时,她通过AWS SI和ISV合作伙伴加速了客户的AWS采用。她热衷于技术中的包容性,并积极参与招聘和指导,以促进工作场所的人才多样性。
 Aditya Singh Aditya Singh是AWS的AI/ML专家解决方案架构师,专注于帮助高等教育机构和州/地方政府组织利用尖端的生成式AI和机器学习系统加速其AI采用之旅。他专注于生成式AI应用、自然语言处理和MLOps,以解决教育和公共部门的独特挑战。
Aditya Singh Aditya Singh是AWS的AI/ML专家解决方案架构师,专注于帮助高等教育机构和州/地方政府组织利用尖端的生成式AI和机器学习系统加速其AI采用之旅。他专注于生成式AI应用、自然语言处理和MLOps,以解决教育和公共部门的独特挑战。
 Jeff Burke 是UCLA戏剧、电影和电视学院的教授兼系主任,以及研究与创意技术副院长,他在那里共同指导媒体与表演工程研究中心(REMAP)。Burke的研究和创意工作探索了新兴技术与创意表达的交叉点。他目前是国家科学基金会资助的“创新、文化与创意”项目的首席研究员,旨在探索全国范围内创意和技术部门交叉领域的创新机会。他与全校学生合作开发和制作了《Xanadu》。
Jeff Burke 是UCLA戏剧、电影和电视学院的教授兼系主任,以及研究与创意技术副院长,他在那里共同指导媒体与表演工程研究中心(REMAP)。Burke的研究和创意工作探索了新兴技术与创意表达的交叉点。他目前是国家科学基金会资助的“创新、文化与创意”项目的首席研究员,旨在探索全国范围内创意和技术部门交叉领域的创新机会。他与全校学生合作开发和制作了《Xanadu》。
 Chiheb Boussema 是UCLA REMAP的应用AI科学家,他为创意应用开发AI解决方案。他目前的研究兴趣包括扩散模型的扩展性和边缘部署、动画的运动控制与合成,以及记忆和人机交互建模与控制。
Chiheb Boussema 是UCLA REMAP的应用AI科学家,他为创意应用开发AI解决方案。他目前的研究兴趣包括扩散模型的扩展性和边缘部署、动画的运动控制与合成,以及记忆和人机交互建模与控制。
 Naisha Agarwal 是UCLA计算机科学专业的一名即将升入大四的学生。她是《Xanadu》的生成式AI联合负责人,负责设计为节目中各种观众互动提供动力的生成式AI工作流,融合了她对技术和艺术的热情。她曾在微软研究院实习,从事设计用户创作的沉浸式体验、用虚拟世界增强物理空间的工作。她还曾在Kumo实习,开发了一个后来部署在Snowflake上的自定义AI聊天机器人。此外,她还在KDD会议上发表了一篇关于推荐系统的论文。她热衷于利用计算机科学解决现实世界的问题。
Naisha Agarwal 是UCLA计算机科学专业的一名即将升入大四的学生。她是《Xanadu》的生成式AI联合负责人,负责设计为节目中各种观众互动提供动力的生成式AI工作流,融合了她对技术和艺术的热情。她曾在微软研究院实习,从事设计用户创作的沉浸式体验、用虚拟世界增强物理空间的工作。她还曾在Kumo实习,开发了一个后来部署在Snowflake上的自定义AI聊天机器人。此外,她还在KDD会议上发表了一篇关于推荐系统的论文。她热衷于利用计算机科学解决现实世界的问题。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区