



📢 转载信息
原文作者:Alexander Arzhanov, Ilya Isaev, and Roy Allela
Amazon Simple Storage Service (Amazon S3) 是一种高弹性服务,可自动适应应用程序需求,提供现代机器学习工作负载所需的高吞吐性能。像 Amazon S3 Connector for PyTorch 和 Mountpoint for Amazon S3 这样的高性能客户端连接器,提供了原生的 S3 集成,无需直接处理 S3 REST API 即可集成到训练流水线中。
在本文中,我们将介绍用于优化直接从 Amazon S3 通用存储桶读取数据的机器学习训练工作负载的实用技巧和建议。尽管如此,本文讨论的许多数据加载优化技术也广泛适用于不同的存储结构。
为了验证这些建议,我们对一个具有代表性的计算机视觉 (CV) 训练工作负载进行了基准测试——具体来说是一个包含数万个小型 JPEG 文件的图像分类任务。我们评估了从 S3 存储桶的多种数据访问模式,并比较了不同 S3 客户端的性能,包括 Amazon S3 Connector for PyTorch 和 Mountpoint for Amazon S3。
我们的研究结果表明,将数据集整合到适当大小的数据分片中(通常在 100 MB 到 1 GB 范围内),并结合顺序访问模式,可以显著提高吞吐量。在多轮次训练场景中,缓存频繁访问的训练数据进一步提高了效率。最后,在评估的 S3 客户端中,Amazon S3 Connector for PyTorch 一贯实现了最高的吞吐量,优于其他常用的 S3 数据访问方法。
机器学习训练流水线中的性能瓶颈
虽然 GPU 在加速机器学习计算中起着至关重要的作用,但训练是一个多方面、相互依赖的复杂过程——其中任何一个阶段都可能成为瓶颈。下图说明了一个典型的端到端训练流水线并指出了这些阶段发生的位置。尽管训练算法、模型架构、实现细节和硬件等因素都很重要,但将训练工作负载视为包含以下四个重复出现的高层步骤的流水线是很有帮助的:
- 将训练样本从持久性存储读取到内存中。
- 在内存中预处理训练样本,包括解码、转换和增强等步骤。
- 基于跨 GPU 计算和同步的梯度更新模型参数。
- 为了实现容错,定期保存训练检查点,以便在发生故障时可以从最近的状态恢复训练。

任何机器学习训练流水线的有效吞吐量都受到其最慢步骤的限制。虽然我们最终关心的是步骤 3——模型更新的实际计算,但基于云的机器学习工作负载可能会面临独特的挑战。在计算和存储资源在设计上通常是解耦的云环境中,数据输入流水线(步骤 1-2)经常成为关键瓶颈。检查点(步骤 4)也可能影响整体训练效率,但我们将在本文中不讨论这一点。
如果 GPU 需要等待数据进行处理,即使是最先进的 GPU 也无法加速训练。当发生数据饥饿时,对更强大的计算硬件的额外投资会带来边际效益递减——这在生产环境中是一种昂贵的低效率。要实现最大的 GPU 利用率,需要对数据流水线进行周密优化,以确保持续不断地提供可供 GPU 使用的训练样本。
数据加载的挑战
影响 Amazon S3 数据加载性能的最重要因素之一是训练期间数据访问的模式。特别是,顺序读取和随机读取之间的区别在决定总体吞吐量和延迟方面起着作用。了解这些访问模式如何与 Amazon S3 的底层特性相互作用,是设计高效输入流水线的关键。
Amazon S3 上的机器学习工作负载中的顺序读取和随机读取
从 Amazon S3 读取数据可以与具有机械执行器的传统硬盘驱动器 (HDD) 的行为进行比较。如下所示的插图,当数据块连续存在时,HDD 会按顺序读取数据块,从而使执行器臂的移动最小化。相比之下,随机读取需要执行器臂跳到磁盘表面的不同位置以访问分散的数据块,这由于执行器臂的物理重新定位而引入了延迟。

当在 Amazon S3 上访问数据时,情况与 HDD 示例有些相似。确切地说,每次 S3 请求在实际数据传输开始之前都会产生一个“首字节时间”(TTFB) 开销。此开销包括几个组成部分:建立连接、网络往返延迟、S3 的内部操作(如定位数据和在磁盘上访问数据)以及客户端响应处理。虽然数据传输时间本身会随着正在检索的数据量而扩展,但 S3 GET 请求的 TTFB 开销基本上是固定的,与数据对象的大小无关,如下图所示。
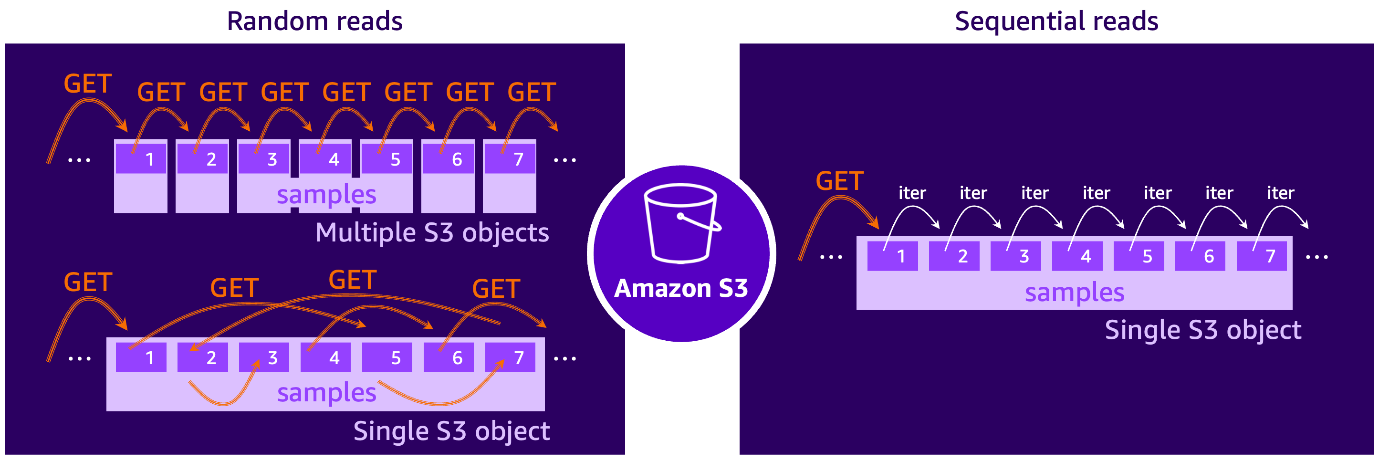
遵循讨论机器学习工作负载时的 HDD 类比,我们可以说,当我们遇到的数据访问模式是随机读取模式时,例如,数据集由存储在 S3 上的大量小文件组成,每个文件包含单个训练样本。或者,当训练脚本使用例如字节范围 S3 GET 请求从较大的文件分片的不同部分获取样本时,也会发生随机 S3 访问。这就像不断来回跳场景一样观看 YouTube 视频。
相反,当数据集组织成大型文件分片时(每个分片包含许多训练样本),并且可以一个接一个地按顺序迭代这些样本时,就会出现顺序读取模式。在这种情况下,单个 S3 GET 请求可以检索多个样本,从而实现比随机读取场景高得多的数据吞吐量。这种方法还简化了数据预取,因为可以预期下一个批次的样本,并将其获取并缓冲到内存中,使其立即可供 GPU 使用。
吞吐量影响分析:计算机视觉案例研究
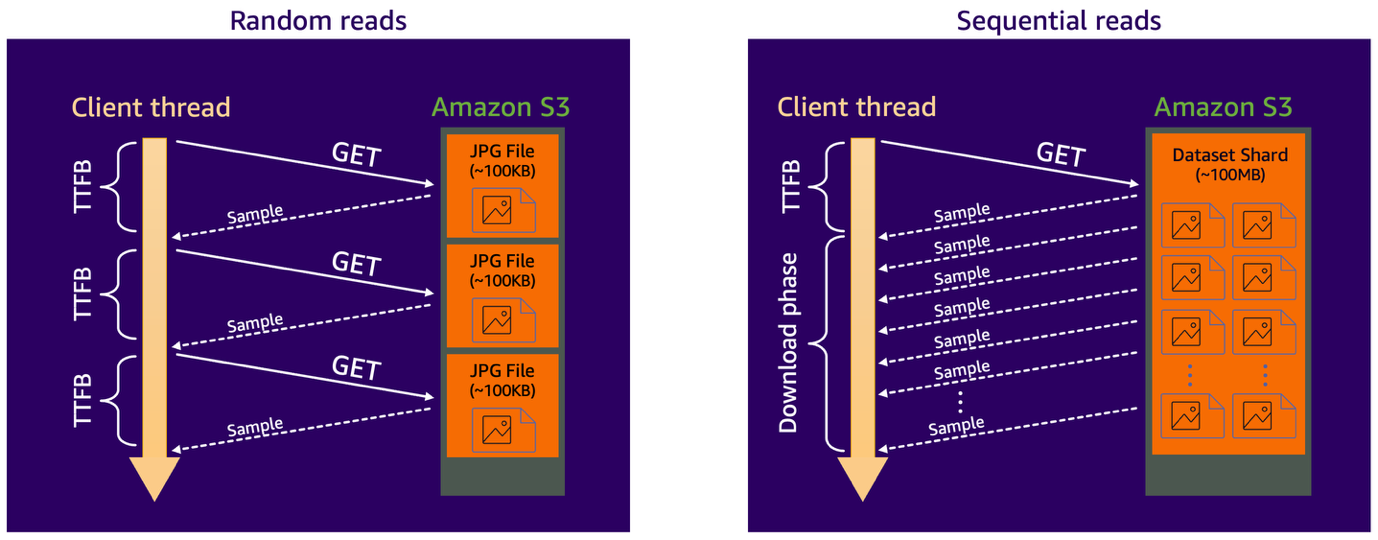
为了更好地理解不同的数据访问模式如何影响性能,让我们看一个计算机视觉任务中的两种场景,其中数据集包含许多相对较小的图像文件(每个约 100 KB)。在第一种场景中,数据集按原样存储在 Amazon S3 Standard 存储类别中,训练脚本按需检索每张图像。这会产生随机读取访问模式,其中每个训练样本都需要自己的 S3 GET 请求。由于 S3 Standard 的 TTFB 延迟约为数十毫秒,而小文件的实际下载时间相比之下很短,因此数据加载器的性能会受到延迟限制。换句话说,客户端线程大部分时间都在空闲等待数据到达。
在第二种场景中,数据集在存储到 S3 之前被整合到更大的文件分片中(例如,每个约 100 MB)。现在,数据加载器使用单个 S3 GET 请求顺序读取多个训练样本。这会将工作负载转变为带宽限制,消除了每个样本的 TTFB 影响,并允许在下载阶段对连续样本进行有效流式传输。
从 Amazon S3 进行数据加载的优化技术
在了解了 S3 上的机器学习工作负载的随机和顺序数据访问模式之后,让我们来了解一下如何在实践中优化数据摄取流水线的方法。
使用为 S3 优化的高性能文件客户端
鉴于可用的选项众多,选择高性能的 S3 文件客户端可能具有挑战性。为了解决这个问题,AWS 在 2023 年为 S3 推出了两个原生的开源客户端:Mountpoint for Amazon S3 和 Amazon S3 Connector for PyTorch。这两个客户端都构建在 AWS Common Runtime (CRT) 之上,CRT 是一组高度优化的 C 语言基础组件,包括一个原生 S3 客户端,该客户端实现了最佳性能优化,例如请求并行化、超时、重试和连接重用,以便客户能够以最少的精力实现最大的 S3 吞吐量。
Mountpoint for Amazon S3 是一个开源文件客户端,可用于将 S3 存储桶挂载到计算实例上,并将其作为本地文件系统访问,而无需修改现有代码。这使其非常适合各种工作负载,包括机器学习训练。
对于 Kubernetes 环境,Mountpoint for Amazon S3 Container Storage Interface (CSI) Driver 通过将 S3 存储桶呈现为存储卷来扩展此功能,允许容器通过熟悉的文件系统接口访问 S3 对象。随着 Mountpoint for Amazon S3 CSI v2 的最新发布,该驱动程序还引入了跨 Pod 的共享缓存,因此分布式机器学习工作负载可以重用本地缓存的数据——从而提高性能和资源效率。CSI 驱动程序与任何基于 Kubernetes 的应用程序兼容,可以与 Amazon Elastic Kubernetes Service (Amazon EKS) 集成,在 EKS 中,它可作为托管加载项提供,以简化安装和生命周期管理。
Amazon S3 Connector for PyTorch 提供了与训练流水线紧密集成的 PyTorch 原生组件。这种集成支持对训练数据的高吞吐量访问,并直接向 Amazon S3 进行高效的检查点写入。它在读取训练数据或写入模型检查点时自动应用性能优化。
该连接器同时支持用于随机访问的映射式数据集和用于流式顺序访问的可迭代式数据集,使其适用于各种机器学习训练模式。它还包括一个内置的检查点接口,允许直接从 S3 保存和加载检查点,而无需依赖本地存储。安装很轻量级(例如,使用 pip),并且该连接器不需要额外的文件系统客户端或复杂的系统设置——只需要对训练代码进行最少的更改,如 GitHub 所示。
分片数据集并使用顺序读取模式
优化从 S3 加载数据的有效策略是将数据集序列化为更少、更大的文件分片,每个分片包含许多训练样本,并使用数据加载器按顺序读取这些样本。在我们的 S3 微基准测试中,介于 100 MB–1 GB 之间的分片大小通常能提供出色的吞吐量。但是,理想的大小可能因您的工作负载而异。较小的分片可以改善预取缓冲区中的准随机采样行为,而较大的分片通常能提供更好的原始吞吐量。
分片的常见文件格式包括 tar(PyTorch 中常通过 WebDataset 等库使用)和 TFRecord(在 TensorFlow 中与 tf.data 一起使用)。尽管如此,分片数据并不能保证顺序读取。如果您的数据加载器随机访问分片内的样本——这在 Parquet 或 HDF5 等格式中很常见——顺序访问的优势可能会丧失。为了充分发挥性能优势,我们建议您设计数据加载器,以便在每个分片内按顺序读取样本。
训练样本的并行化、预取和缓存
优化机器学习流水线的数据摄取和预处理阶段对于最大化训练吞吐量至关重要,特别是在随机数据访问模式不可避免时。并行化、预取和缓存等技术在最小化 I/O 瓶颈和保持 GPU 完全利用方面起着核心作用。
并行化是提高数据加载流水线吞吐量的最有效方法之一,特别是由于数据解码和预处理通常是“完美并行”的,这意味着它们可以分解成许多可以同时运行而无需通信的独立过程。您可以使用 TensorFlow (tf.data) 和 PyTorch (原生 DataLoader) 等框架来调整其工作程序池(CPU 线程或进程)的大小,以并行化数据摄取。
对于顺序访问模式,一个好的经验法则是将工作线程数与可用 CPU 核心数相匹配。然而,在具有高 CPU 核心数(例如,超过 20 个)的实例上,使用稍小的池可以提高效率。
相比之下,对于随机访问模式,特别是当直接从 S3 读取时,大于 CPU 核心数的池大小已被证明对我们的基准测试有利。例如,在具有 8 个 vCPU 的 EC2 实例上,将 PyTorch 的 num_workers 设置增加到 64 或更高版本显著提高了数据吞吐量。
话虽如此,增加并行性并非万能药。过度并行化会使 CPU 和内存资源不堪重负,从而将瓶颈从 I/O 转移到预处理。重要的是根据您的特定工作负载进行基准测试,以找到适当的平衡。
预取通过将数据加载与 GPU 计算分离来补充并行化。使用生产者-消费者模式,预取允许异步准备数据并将其缓冲到内存中,以便在 GPU 需要时,下一个批次已准备就绪。良好大小的预取缓冲区和适当调整的工作程序池大小有助于分摊 I/O 和预处理延迟,从而提高整体训练吞吐量。
缓存对于具有随机访问模式的多轮次训练工作负载特别有效,在这些工作负载中,相同的样本数据会被多次读取。像 Mountpoint for Amazon S3 这样的工具提供了内置的缓存机制,将数据集对象存储在本地实例存储(例如,NVMe 磁盘)、EBS 卷或内存中。通过消除重复的 S3 GET 请求,缓存提高了训练速度和成本效益。
由于输入数据集在训练期间通常保持静态,我们建议配置 Mountpoint 使用无限的元数据 TTL(通过设置 --metadata-ttl indefinite,请参阅 Mountpoint for S3 文档),以减少 S3 请求开销。此外,在我们的基准测试中,我们还启用了数据缓存到 NVMe,允许 Mountpoint 将对象存储在本地。缓存会自动通过逐出最近最少使用的文件来管理空间,默认情况下至少保持 5% 的可用空间(可配置)。要充分利用缓存,请确保您的实例具有足够的磁盘空间来容纳频繁访问的数据。
性能案例研究:从 Amazon S3 Standard 进行数据加载
为了验证前面讨论的最佳实践,我们进行了一系列基准测试,模拟了在随机和顺序数据访问模式下真实的计算机视觉 (CV) 训练工作负载。虽然确切的结果可能因您的具体用例而异,但性能趋势和见解广泛适用于机器学习训练流水线。
基准设置
所有基准测试均在配备 NVIDIA A10G GPU 和 32 个 vCPU 的 Amazon Elastic Compute Cloud (Amazon EC2) g5.8xlarge 实例上执行。基准工作负载使用 google/vit-base-patch16-224-in21k 后端 ViT 模型进行图像分类任务,在 10 GB 数据集上进行训练,该数据集包含 100,000 张合成 JPEG 图像(每张约 115 KB)。训练脚本使用以下 S3 客户端之一按需从 Amazon S3 Standard 流式传输数据集:
- 基于 fsspec 的数据加载器 – TorchData DataPipes 的实现,基于 fsspec,fsspec 是云对象存储的流行开源接口。尽管 TorchData 在 v0.10 中弃用了 DataPipes,但 fsspec 仍然广泛用于从 S3 进行机器学习数据访问。
- Mountpoint for Amazon S3(无数据缓存) – AWS 开发的高吞吐量开源文件客户端。在此配置中,启用了元数据缓存,但训练样本在多个 epoch 之间未在本地缓存。
- Mountpoint for Amazon S3(数据缓存) – 与前一个客户端相同,但启用了本地磁盘缓存,用于存储频繁访问的样本。
- S3 Connector for PyTorch – AWS 维护的高性能开源 S3 接口,与 PyTorch 的数据集 API 紧密集成。
每个基准测试配置都在训练期间按需流式传输数据集,没有预先进行本地下载或预处理。
基准目标
基准测试旨在探究:
- 调整数据加载器中并行化设置的影响。
- 使用 Mountpoint for Amazon S3 进行本地磁盘缓存的性能影响。
- 采用顺序读取模式带来的吞吐量提升。
- 数据集分片大小与持续数据加载性能之间的关系。
对于这两种访问模式,预处理阶段包括 JPEG 解码和调整大小为 224×224×3,然后批处理为 128 个小批量。这种轻量级的设置有助于我们保持真实的端到端流水线,同时最大限度地减少 CPU 限制的开销。
可重现性和最佳实践
要在您自己的环境中重现类似的基准测试,我们提供了一个 专用的基准测试工具,它支持各种 S3 数据加载配置。
为获得一致且有意义的结果:
- 为每个 S3 客户端使用相同的 EC2 实例类型。
- 将每个测试数据集放在单独的 S3 存储桶中,以隔离流量并避免跨客户端干扰。
- 在与 S3 存储桶相同的 AWS 区域中运行实验,以最大限度地减少延迟和网络变化。
通过遵循这些最佳实践,您可以在自己的工作负载中获得干净的测量结果,并可靠地比较不同的数据加载策略。
随机访问的单轮次基准测试
为了评估从 Amazon S3 流式传输数据集时调整并行化的影响,我们运行了一个单轮次基准测试(对训练数据集进行一次完整扫描),以避免潜在的操作系统级缓存的干扰。
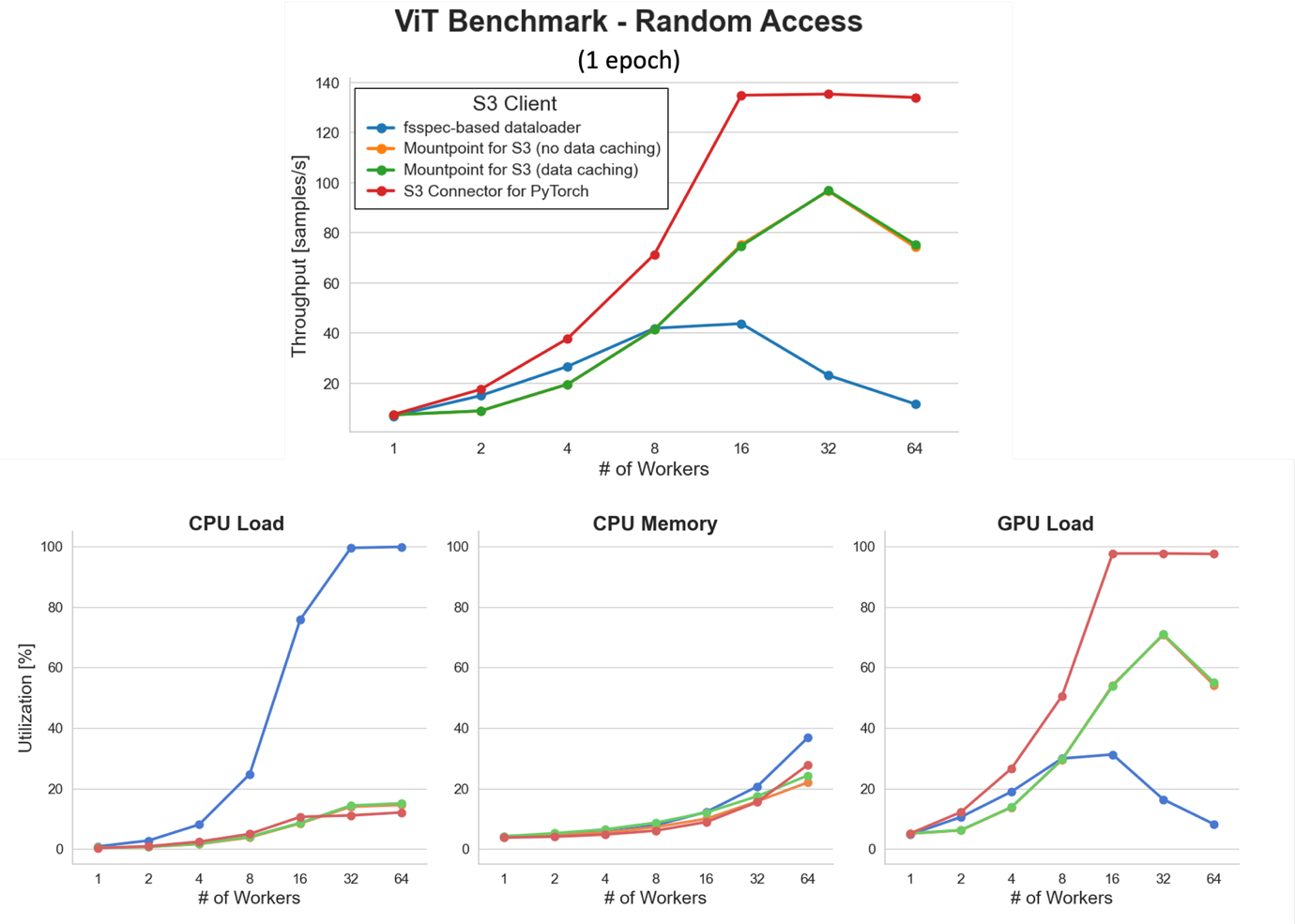
在较低的工作程序数量下,所有 S3 客户端都表现出数据摄取瓶颈,限制了总体吞吐量。随着并行化程度的增加,吞吐量显著提高。值得注意的是,S3 Connector for PyTorch 在 16 个以上的工作程序下达到了接近 GPU 饱和的状态(约 138 样本/秒)。
然而,工作程序池的大规模扩展会增加 CPU 和内存压力。这在基于 fsspec 的数据加载器中尤为明显,它在 32 个工作程序时达到约 100% 的 CPU 利用率,导致 CPU 限制的瓶颈,从而降低了 GPU 利用率并减少了总体样本吞吐量。相比之下,S3 Connector for PyTorch 在负载下保持了更好的效率,凸显了使用高性能 S3 客户端的重要性。
Mountpoint for Amazon S3(有或没有数据缓存)在此单轮次基准测试中实现了几乎相同的性能——正如预期的那样,因为每个样本只读取一次,缓存没有任何优势。我们将在接下来的多轮次场景中重新讨论缓存的好处。
随机访问的多轮次基准测试
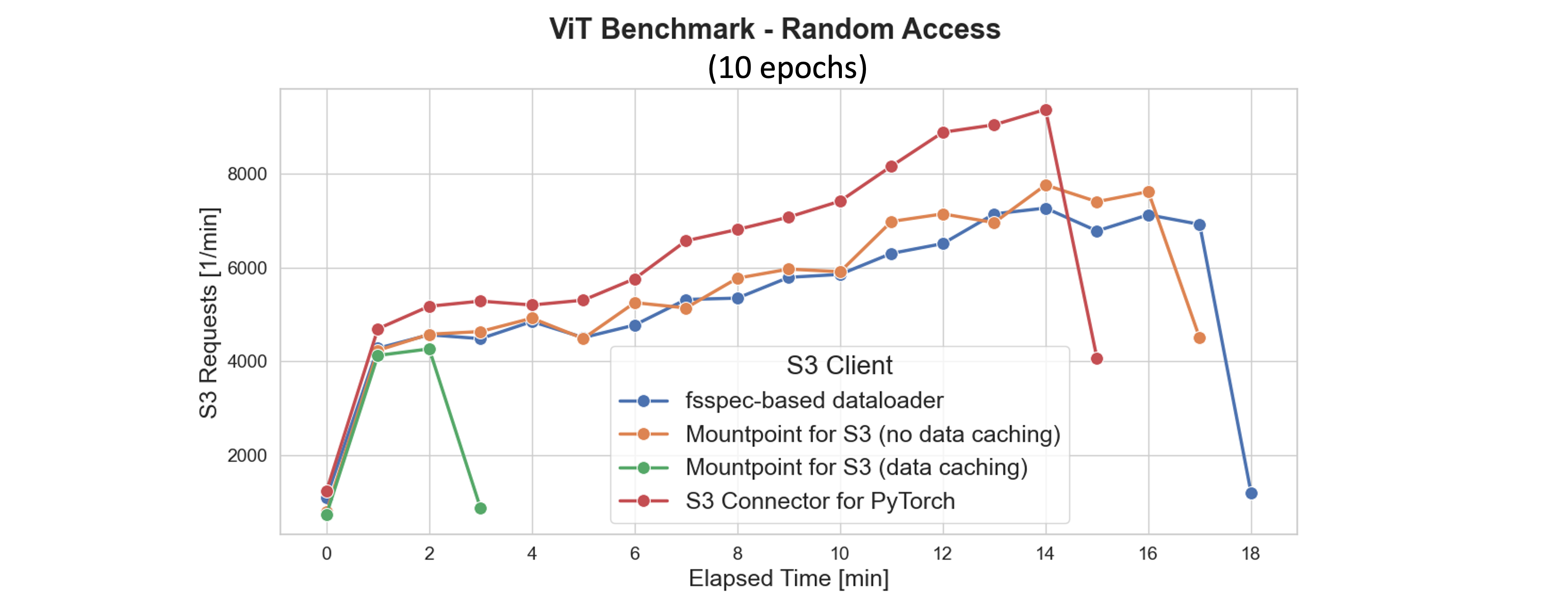
Mountpoint for Amazon S3 的缓存功能通过将频繁访问的 S3 对象存储在本地存储上来显著提高训练性能,从而减少了跨轮次的检索延迟和请求成本。在我们的基准测试中,在第一轮次期间访问的数据集文件会在本地缓存。从第二轮次开始,整个数据集都从磁盘提供——即使数据加载器工作程序池为 16 个,也能完全饱和 GPU 并最大化吞吐量。
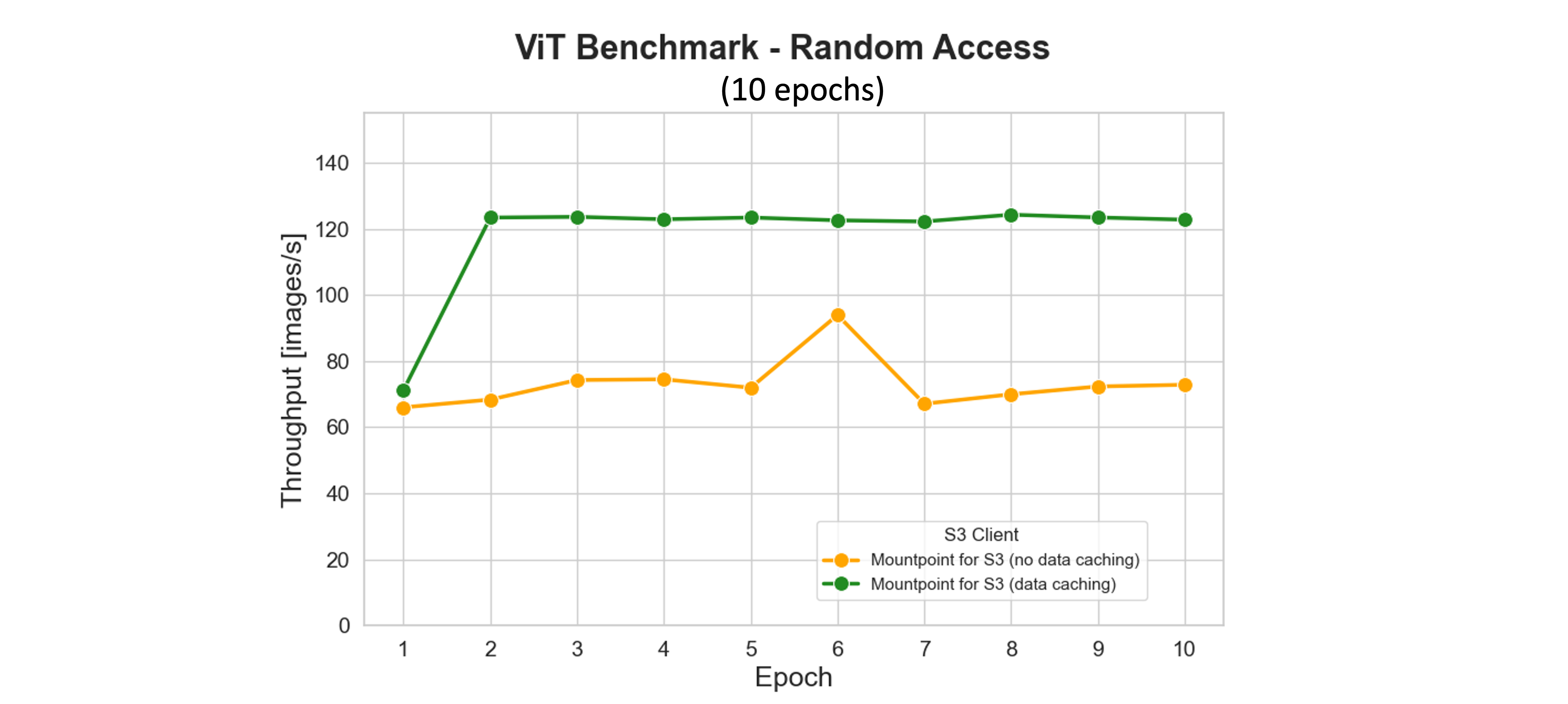
如下所示的图中,缓存不仅加速了训练,还最大限度地减少了网络流量和 S3 请求量。到第一轮次结束时(大约在 2 分钟标记处),Mountpoint 会停止向 S3 发出进一步的 GET、LIST 和 HEAD 请求。相比之下,没有缓存的 S3 客户端会为每个轮次持续重新下载相同的数据,从而产生更高的延迟和运营成本。
顺序访问的单轮次基准测试
为了验证顺序数据访问的优势,我们使用与之前相同的设置(8 个数据加载器工作程序)重新运行了基准测试,但切换到了 tar 格式的序列化数据集,分片大小范围为 4 MB–256 MB。
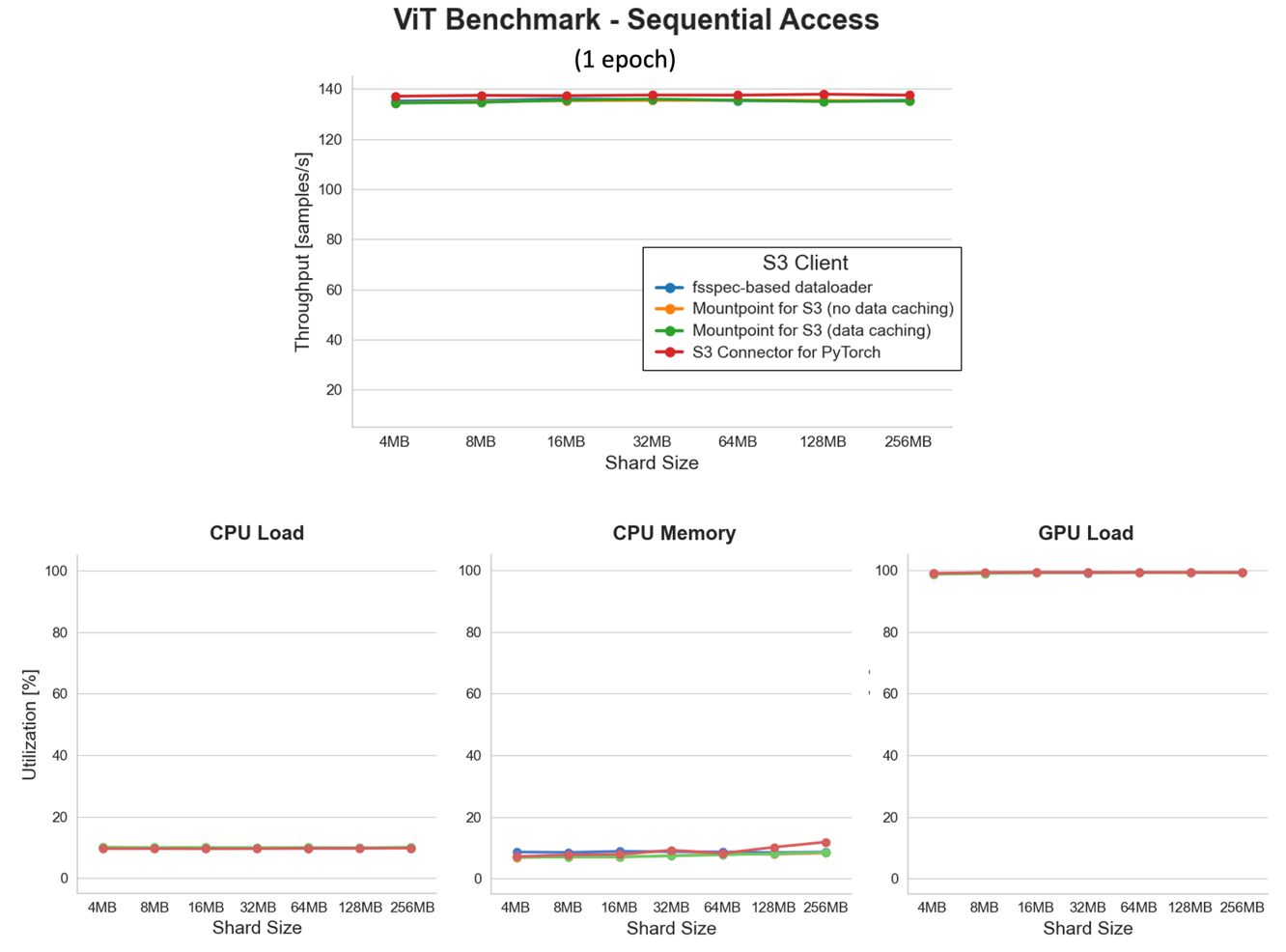
乍一看,这次基准测试的结果可能看起来平平无奇——所有折线图都是平坦的。但请等一下,这不就是最精彩的部分吗?GPU 负载持续平稳在约 100% 的利用率,这意味着我们跨所有文件分片大小完全饱和了 GPU。将这一点与持续的低 CPU 使用率结合起来,您就取得了相当了不起的成就!
顺序访问的权益基准测试
前一个基准测试的结果提出了一个有趣的问题:在这种顺序访问设置中,我们可以实现的理论最大吞吐量是多少?为了找出答案,我们运行了一个权益基准测试,完全消除了 GPU 限制的模型训练阶段,只在 CPU 上保留读取和预处理阶段。以下图表显示了工作程序池大小为 8 时的结果。
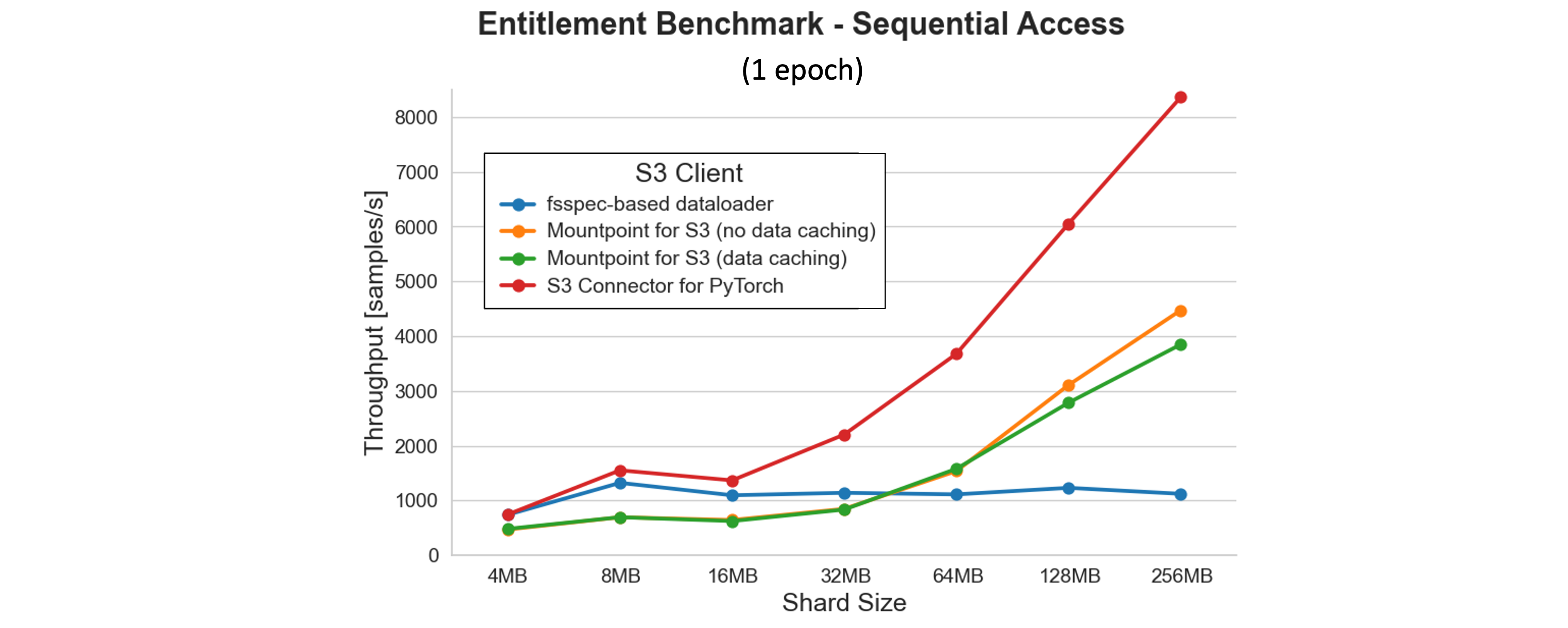
结果表明,除了基于 fsspec 的数据加载器外,吞吐量随着所有客户端分片大小的增加而提高。S3 Connector for PyTorch 提供了最高的性能,在测试的最大分片大小下达到了每秒 8,000 多个样本... [内容被截断]
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区