



📢 转载信息
原文作者:Jiarong Jiang, Akarsha Sehwag, Mani Khanuja, Peng Shi, Ruo Cheng, and Anil Gurrala
如今,大多数智能体仅基于当前交互中可见的信息进行操作:它们可以获取事实和知识,但无法记住它们之前是如何解决类似问题的,或者为什么某些方法有效或失败。这在它们与时间一起学习和改进的能力上造成了重大差距。Amazon Bedrock AgentCore 的剧集记忆(Episodic Memory)通过捕获并呈现经验级别的知识来解决这一限制。虽然语义记忆(semantic memory)可以帮助智能体记住它所知道的内容,但剧集记忆记录了它是如何到达那里的:目标、推理步骤、操作、结果和反思。通过将每次交互转换为一个结构化的剧集(episode),您可以使智能体能够回忆知识、解释并应用先前的推理。这有助于智能体跨会话进行适应,避免重复错误,并随着时间的推移演化其规划。
Amazon Bedrock AgentCore Memory 是一项全托管服务,通过短期记忆和长期智能记忆功能,帮助开发人员创建具有上下文感知的 AI 智能体。要了解更多信息,请参阅Amazon Bedrock AgentCore Memory:构建具有上下文感知的智能体和构建更智能的 AI 智能体:AgentCore 长期记忆深度解析。
在本文中,我们将引导您完成构建 AgentCore 剧集记忆策略的完整架构,讨论反思模块(reflection module),并分享证明智能体任务成功率显著提高的引人注目的基准测试。
设计智能体剧集记忆的关键挑战
剧集记忆使智能体能够保留并推理其自身的经验。然而,设计这样一个系统需要解决几个关键挑战,以确保经验保持连贯性、可评估性和可重用性:
- 保持时间与因果连贯性 – 剧集需要保存推理步骤、操作和结果的顺序和因果流程,以便智能体能够理解其决策是如何演变的。
- 检测和分割多个目标 – 会话通常涉及重叠或转移的目标。剧集记忆必须识别和分离它们,以避免混合不相关的推理轨迹。
- 从经验中学习 – 每个剧集都应根据成功或失败进行评估。然后,反思应将相似的过去剧集进行比较,以识别可概括的模式和原则,使智能体能够将这些见解应用于新目标,而不是重放先前的轨迹。
在下一节中,我们将描述如何构建 AgentCore 剧集记忆策略,涵盖其提取、存储、检索和反思管道,以及这些组件如何协同工作,帮助将经验转化为适应性智能。
AgentCore 剧集记忆的工作原理
当您的智能体应用程序将对话事件发送到 AgentCore Memory 时,原始交互会通过智能化的提取和反思过程,转化为丰富的剧集记忆记录。下图说明了这种剧集记忆策略的工作原理,以及简单的智能体对话如何转变为有意义的、具有反思性的记忆,从而影响未来的交互。

下图说明了相同架构的详细数据流,提供了更详细的说明。
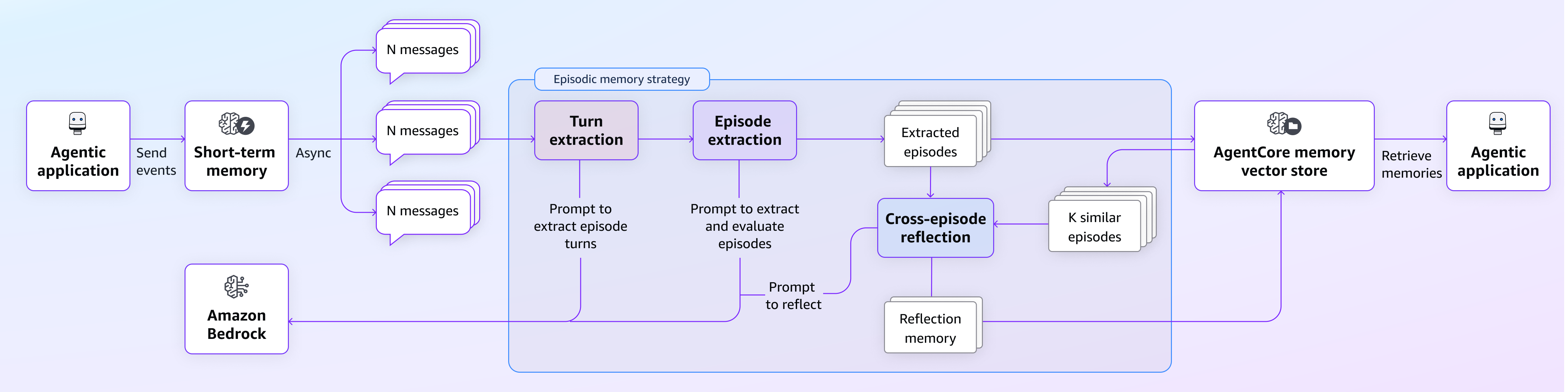
上述图表说明了剧集记忆策略的不同步骤。前两个步骤(标记为粉色和紫色)被归类为剧集提取模块的两个阶段方法,它们具有不同但互补的目的。第三个步骤(标记为蓝色)是反思模块,它帮助智能体从过去的经验中学习。在接下来的部分中,我们将详细讨论这些步骤。
剧集提取模块
剧集提取模块是剧集策略的基础步骤,它将原始的用户-智能体交互数据转化为结构化的、有意义的剧集。我们采用了两阶段方法,旨在捕获每次交互的粒度步骤机制(称为“轮次提取”)和更广泛的剧集级别知识以创建连贯的叙事(称为“剧集提取”)。打个比方,这就像在会议中做笔记(轮次级别)和在会议结束时撰写会议摘要(剧集级别)。这两个阶段都很有价值,但在从经验中学习时服务于不同的目的。
在剧集提取的第一阶段,系统会执行轮次级别的处理,以了解什么做得对或错。在这里,用户和智能体之间的单个交换单元,称为“对话轮次(conversational turns)”,被识别、分割并转化为以下维度的结构化摘要:
- 轮次情景 (Turn situation) – 对助手在本轮中响应的情况和背景的简要描述。这包括即时背景、可能跨越多轮的用户的总体目标,以及为当前交流提供信息的前次交互中的相关历史记录。
- 轮次意图 (Turn intent) – 助手在本轮中的具体目的和主要目标,本质上回答“助手此刻试图完成什么?”
- 轮次操作 (Turn action) – 交互期间执行的具体步骤的详细记录,记录使用了哪些特定工具、向每个工具提供了什么输入参数或参数,以及助手如何将意图转化为可执行的操作。
- 轮次思考 (Turn thought) – 助手决策背后的推理,解释工具选择和方法的“为什么”。
- 轮次评估 (Turn assessment) – 对助手是否成功实现其本轮声明目标的诚实评估,对所选方法和执行的操作的有效性提供即时反馈。
- 目标评估 (Goal assessment) – 关于跨整个对话的用户总体目标似乎是否得到满足或正在接近完成的更广泛视角,超越单个轮次来评估整体成功情况。
在处理和构建单个轮次之后,系统会进入剧集提取阶段,即当用户完成其目标(由大型语言模型检测到)或交互结束时。这有助于捕获完整的用户旅程,因为用户的目标通常跨越多个轮次,仅凭单个轮次数据无法传达总体目标是否实现或整体策略是什么样的。在此阶段,按顺序相关的轮次被综合成连贯的剧集记忆,捕获完整的用户旅程,从初始请求到最终解决:
- 剧集情景 (Episode situation) – 促使用户需要帮助的更广泛背景。
- 剧集意图 (Episode intent) – 对用户最终想要完成的事情的清晰阐述。
- 成功评估 (Success evaluation) – 对对话是否实现了每个剧集的预期目的的明确评估。
- 评估依据 (Evaluation justification) – 对成功或失败评估的具体推理,以证明特定对话时刻对用户目标的进展或偏离。
- 剧集见解 (Episode insights) – 捕获已被证明有效的方法,并识别当前剧集中应避免的陷阱。
反思模块
反思模块突出了 Amazon Bedrock AgentCore 剧集记忆从过去经验中学习并生成见解以帮助未来改进的能力。正是在这里,单个剧集学习演变为可概括的知识,可以指导跨各种场景的智能体。
反思模块通过跨剧集反思运行,根据用户意图检索过去相似的成功剧集,并跨多个剧集进行反思以获得更具概括性的见解。当处理新剧集时,系统执行以下操作:
- 使用用户意图作为语义键,系统从向量存储中识别历史上成功且相关的剧集,这些剧集具有相似的目标、上下文或问题域。
- 系统分析主要剧集和相关剧集中的模式,寻找可在不同上下文中一致奏效的方法的可转移见解。
- 审查现有的反思知识,并通过新的见解进行增强,或通过跨剧集分析发现的全新模式进行扩展。
在流程结束时,每个反思记忆记录包含以下信息:
- 用例 (Use case) – 见解适用时和适用地点,包括相关的用户目标和触发条件。
- 提示(见解) (Hints (insights)) – 关于工具选择策略、有效方法和应避免的陷阱的可操作指导。
- 置信度评分 (Confidence scoring) – 一个分数(0.1–1.0),表示见解在不同场景中泛化的程度。
剧集为智能体提供了关于如何以前解决类似问题的具体示例。这些案例研究展示了使用的特定工具、应用的推理和实现的结果,包括成功和失败。这创建了一个学习框架,智能体可以遵循经过验证的策略并避免记录在案的错误。
反思记忆从多个剧集中提取模式,以提供战略见解。它们不提供单个案例,而是揭示哪些工具最有效、哪些决策方法最成功,以及哪些因素驱动结果。这些提炼出的原则为智能体在复杂场景中导航提供了更高级别的指导。
自定义覆盖配置
尽管内置的记忆策略涵盖了常见用例,但许多领域需要量身定制的记忆处理方法。该系统支持通过自定义提示覆盖内置策略,从而扩展内置逻辑,帮助团队根据其特定要求调整记忆处理。您可以实施以下自定义覆盖配置:
- 自定义提示 (Custom prompts) – 这些提示侧重于标准和逻辑,而不是输出格式,并帮助开发人员定义以下内容:
- 提取标准 – 提取或过滤哪些信息。
- 整合规则 – 如何整合相关记忆。
- 冲突解决 – 如何处理矛盾信息。
- 见解生成 – 如何综合跨剧集反思。
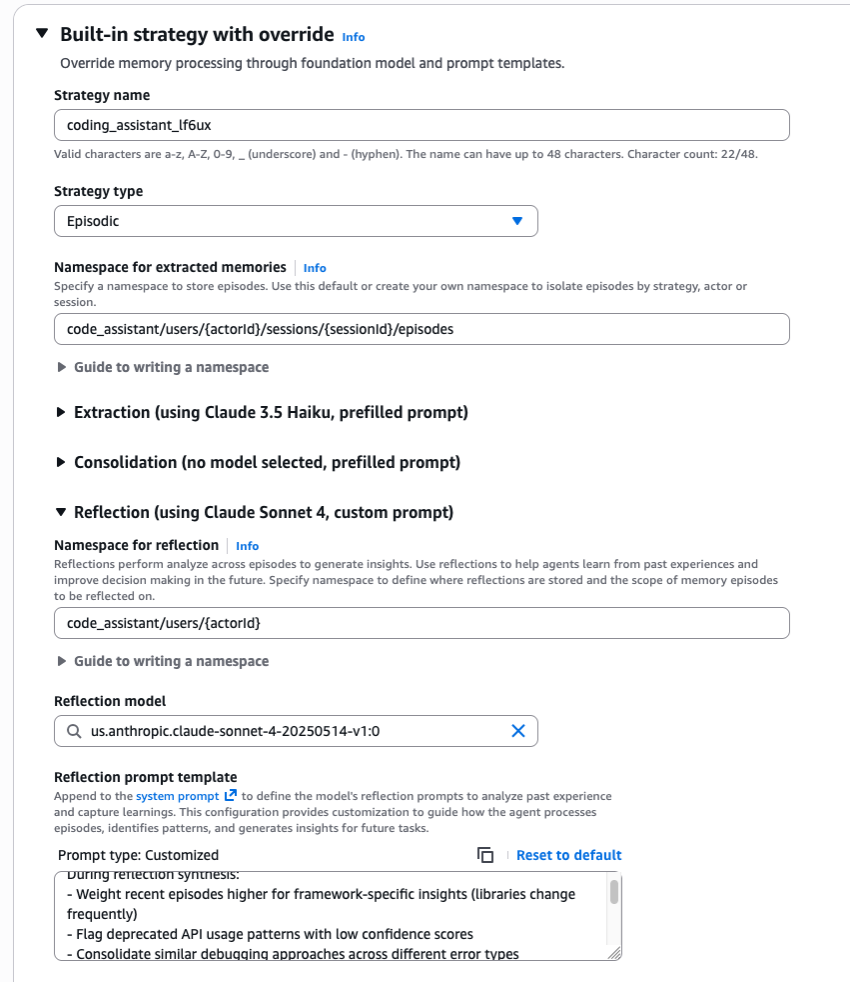
- 自定义模型 (Custom model): AgentCore Memory 支持为记忆提取、整合和反思操作选择自定义模型。这种灵活性有助于开发人员根据其特定要求平衡准确性和延迟。您可以在创建
_memory_resource_时将其作为策略覆盖通过 API 定义,或通过 Amazon Bedrock AgentCore 控制台定义(如以下屏幕截图所示)。 - 命名空间 (Namespaces): 命名空间为剧集和反思提供分层组织,支持在不同粒度级别访问智能体的经验,并提供无缝的自然逻辑分组。例如,要为旅行应用程序设计命名空间,剧集可以存储在
travel_booking/users/userABC/episodes下,反思可以位于travel_booking/users/userABC。请注意,反思的命名空间必须是剧集命名空间的子路径。
性能评估
我们根据零售和航空领域的真实目标完成基准测试(从τ2-bench中抽取样本)评估了 Amazon Bedrock AgentCore 剧集记忆。这些基准测试包含模拟智能体需要帮助用户实现特定目标的实际客户服务场景的任务。
我们比较了实验中的三种不同设置:
- 对于基线(baseline),我们运行了没有与记忆组件交互的智能体(使用 Anthropic 的 Claude 3.7 构建)。
- 对于记忆增强的智能体,我们探索了使用记忆的两种方法:
- 上下文学习示例 (In-context learning examples) – 第一种方法使用提取的剧集作为上下文学习示例。具体来说,我们构建了一个名为
retrieve_exemplars的工具(附录中的工具定义),智能体可以通过发出查询(例如,“如何获得退款?”)来使用该工具,以从剧集存储库中获取分步说明。当智能体遇到类似问题时,检索到的剧集将被添加到上下文中以指导智能体采取下一步操作。 - 反思即指导 (Reflection-as-guidance) – 我们探索的第二种方法是反思即指导。具体来说,我们构建了一个名为
retrieve_reflections的工具(附录中的工具定义),智能体可以使用它来访问过去经验中的更广泛见解。与retrieve_exemplars类似,智能体可以通过生成查询来检索反思作为上下文,从而获得关于策略和方法的见解,而不是具体的逐步操作。
- 上下文学习示例 (In-context learning examples) – 第一种方法使用提取的剧集作为上下文学习示例。具体来说,我们构建了一个名为
我们使用了以下评估方法:
- 基线智能体首先处理一组历史客户交互,这些交互成为记忆提取的来源。
- 然后,智能体接收来自 τ2-bench 的新用户查询。
- 每个查询并行尝试四次。
- 为了评估,我们测量了这四次尝试中的通过率(pass rate)指标。Pass^k 衡量在四次尝试中至少成功 k 次的任务百分比:
- Pass^1:至少成功一次(衡量能力)
- Pass^2:至少成功两次(衡量可靠性)
- Pass^3:至少成功三次(衡量一致性)
下表中的结果显示了两个领域和多个尝试中的明显改进。
| 系统 | Agent 使用的记忆类型 | 零售 | 航空 | ||||
|---|---|---|---|---|---|---|---|
| Pass^1 | Pass^2 | Pass^3 | Pass^1 | Pass^2 | Pass^3 | ||
| 基线 | 无记忆 | 65.80% | 49.70% | 42.10% | 47% | 33.30% | 24% |
| 记忆增强的智能体 | 剧集作为 ICL 示例 | 69.30% | 53.80% | 43.40% | 55.00% | 46.70% | 43.00% |
| 跨剧集反思记忆 | 77.20% | 64.30% | 55.70% | 58% | 46% | 41% | |
记忆增强的智能体在所有领域和一致性级别上始终优于基线。至关重要的是,这些结果表明不同的记忆检索策略最适合不同的任务特征。跨剧集反思将 Pass^1 相比基线提高了 +11.4%,将 Pass^3 提高了 +13.6%,这表明在处理具有不同交互模式的开放式客户服务场景时,通用战略见解特别有价值。相比之下,航空领域——其特点是复杂、基于规则的策略和多步骤程序——从将剧集作为示例中受益更多,该方法实现了最高的 Pass^3(43.0% 对反思的 41.0%)。这表明具体的循序渐进的示例有助于智能体可靠地完成结构化工作流程。在更高的一致性阈值(Pass^3)下,相对改进最为明显,此时记忆有助于智能体避免导致间歇性失败的错误。
使用剧集记忆的最佳实践
有效剧集记忆的关键在于知道何时使用它以及哪种类型适合您的情况。在这一部分中,我们将讨论我们所学到的最有效的方法。
何时使用剧集记忆
当您将正确的记忆类型与当前需求相匹配时,剧集记忆能提供最大的价值。它非常适合复杂、多步骤的任务,在这些任务中,上下文和过去的经验至关重要,例如调试代码、规划旅行和分析数据。对于重复性工作流程,从过去的尝试中学习可以极大地改善结果,以及对于领域特定问题,积累的专业知识可以发挥重要作用,它也特别有价值。
然而,剧集记忆并非总是正确的选择。对于简单的、一次性的问题,如天气查询或基本事实,这些不需要推理或上下文,您可以跳过它。简单的客户服务对话、基本的问答或随意的聊天不需要剧集记忆添加的高级功能。剧集记忆的真正好处是随着时间的推移观察到的。对于短期任务,会话摘要提供了足够的信息。但是,对于复杂任务和重复性工作流程,剧集记忆有助于智能体建立在过去的经验之上并持续改进其性能。
选择剧集与反思
当您面临相似的特定问题并需要清晰的指导时,剧集效果最好。如果您正在调试一个无法渲染的 React 组件,剧集可以向您展示之前如何修复类似问题的具体方法,包括使用的具体工具、思考过程和结果。当一般性建议不够时,它们提供了完整的解决路径。
当您需要跨更广泛的上下文获得战略指导而不是具体的逐步解决方案时,反思记忆效果最好。当您面临一种新类型的问题并需要理解一般原则时,请使用反思,例如“数据可视化任务最有效的方法是什么?”或“哪种调试策略通常最适合 API 集成问题?”反思在您做出关于工具选择和遵循哪种方法的高层决策,或理解为什么某些模式会持续成功或失败时,尤其有价值。
在开始任务之前,请查看反思以获取策略指导,查看相似剧集以获取解决方案模式,并查找先前尝试中记录的高置信度错误。在任务期间,当遇到障碍时查看剧集,利用反思见解进行工具选择,并考虑您当前的情况与过去示例有何不同。
结论
剧集记忆填补了当前智能体能力中的一个关键空白。通过存储完整的推理路径并从结果中学习,智能体可以避免重复错误并建立在成功的策略之上。
剧集记忆与总结记忆(summarization memory)、语义记忆(semantic memory)和偏好记忆(preference memory)一起,完善了 Amazon Bedrock AgentCore 的记忆框架。每者都有特定的用途:总结记忆管理上下文长度,语义记忆存储事实,偏好记忆处理个性化,而剧集记忆捕获经验。这种组合有助于为智能体提供结构化知识和实践经验,以便更有效地处理复杂任务。
要了解有关剧集记忆的更多信息,请参阅剧集记忆策略、如何最好地检索剧集以提高智能体性能以及AgentCore 记忆 GitHub 示例。
附录
在本节中,我们讨论了用于记忆增强智能体的两种使用记忆的方法。
剧集示例
以下是使用提取的剧集作为上下文学习示例的示例:
** 背景 **
A customer (Jane Doe) contacted customer service expressing frustration about a recent flight delay that disrupted their travel plans and wanted to discuss compensation or resolution options for the inconvenience they experienced. ** 目标 **
The user's primary goal was to obtain compensation or some form of resolution for a flight delay they experienced, seeking acknowledgment of the disruption and appropriate remediation from the airline. --- ### 步骤 1: **思考 (Thought):**
The assistant chose to gather information systematically rather than making assumptions, as flight delay investigations require specific reservation and flight details. This approach facilitates accurate assistance and demonstrates professionalism by acknowledging the customer's frustration while taking concrete steps to help resolve the issue. **操作 (Action):**
The assistant responded conversationally without using any tools, asking the user to provide their user ID to access reservation details. --- 步骤 1 结束 --- ... ** 剧集反思 (Episode Reflection ):**
The conversation demonstrates an excellent systematic approach to flight modifications: starting with reservation verification, then identifying confirmation, followed by comprehensive flight searches, and finally processing changes with proper authorization. The assistant effectively used appropriate tools in a logical sequence - get_reservation_details for verification, get_user_details for identity/payment info, search_direct_flight for options, and update tools for processing changes. Key strengths included transparent pricing calculations, proactive mention of insurance benefits, clear presentation of options, and proper handling of policy constraints (explaining why mixed cabin classes aren't allowed). The assistant effectively leveraged user benefits (Gold status for free bags) and maintained security protocols throughout. This methodical approach made sure user needs were addressed while following proper procedures for reservation modifications.反思示例
以下是反思记忆的示例,可用于智能体指导:
**标题 (Title):** 在存在政策限制的情况下积极搜索替代方案 **用例 (Use Cases):**
This applies when customers request flight modifications or changes that are blocked by airline policies (such as basic economy no-change rules, fare class restrictions, or booking timing limitations). Rather than simply declining the request, this pattern involves immediately searching for alternative solutions to help customers achieve their underlying goals. It's particularly valuable for emergency situations, budget-conscious travelers, or when customers have specific timing needs that their current reservations don't accommodate. **提示 (Hints):**
When policy restrictions prevent the requested modification, immediately pivot to solution-finding rather than just explaining limitations. Use search_direct_flight to find alternative options that could meet the customer's needs, even if it requires separate bookings or different approaches. Present both the policy constraint explanation AND viable alternatives in the same response to maintain momentum toward resolution. Consider the customer's underlying goal (getting home earlier, changing dates, etc.) and search for flights that accomplish this objective. When presenting alternatives, organize options clearly by date and price, highlight budget-friendly choices, and explain the trade-offs between keeping existing reservations versus canceling and rebooking. This approach transforms policy limitations into problem-solving opportunities and maintains customer satisfaction even when the original request cannot be fulfilled.工具定义
以下是 retrieve_exemplars 的工具定义:
def retrieve_exemplars(task: str) -> str: """ Retrieve example processes to help solve the given task. Args: task: The task to solve that requires example processes. Returns: str: The example processes to help solve the given task. """以下是 retrieve_reflections 的工具定义:
def retrieve_reflections(task: str, k: int = 5) -> str: """ Retrieve synthesized reflection knowledge from past agent experiences by matching against knowledge titles and use cases. Each knowledge entry contains: (1) a descriptive title, (2) specific use cases describing the types of goals where this knowledge applies and when to apply it, and (3) actionable hints including best practices from successful episodes and common pitfalls to avoid from failed episodes. Use this to get strategic guidance for similar tasks. Args: task: The current task or goal you are trying to accomplish. This will be matched against knowledge titles and use cases to find relevant reflection knowledge. Describe your task clearly to get the most relevant matches. k: Number of reflection knowledge entries to retrieve. Default is 5. Returns: str: The synthesized reflection knowledge from past agent experiences. """关于作者
 Jiarong Jiang 是 AWS 的首席应用科学家,致力于推动检索增强生成(RAG)和智能体记忆系统方面的创新,以提高企业级智能体的准确性和智能性... [内容被截断]
Jiarong Jiang 是 AWS 的首席应用科学家,致力于推动检索增强生成(RAG)和智能体记忆系统方面的创新,以提高企业级智能体的准确性和智能性... [内容被截断]
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区