



管理大型照片集对组织和个人来说都带来了严峻的挑战。传统方法依赖于手动标记、基本元数据和基于文件夹的组织方式,当处理数千张包含多个人物和复杂关系的照片时,这些方法变得不切实际。智能照片搜索系统通过结合计算机视觉、图数据库和自然语言处理来解决这些挑战,革新了我们发现和组织视觉内容的方式。这些系统不仅能捕捉照片中“谁”和“什么”,还能捕捉使其有意义的复杂关系和上下文,从而支持自然语言查询和语义发现。
在本文中,我们将向您展示如何使用 AWS Cloud Development Kit (AWS CDK) 构建一个全面的照片搜索系统,该系统集成了 Amazon Rekognition 进行人脸和对象检测,Amazon Neptune 进行关系映射,以及 Amazon Bedrock 进行人工智能驱动的字幕生成。我们演示了这些服务如何协同工作,以创建一个能够理解自然语言查询的系统,例如“查找所有祖父母和孙辈在生日派对上的照片”或“显示家人公路旅行时的照片”。
关键优势在于能够在扩展以处理数千张照片和复杂的家庭或组织结构的同时,对特定人物、对象或关系进行个性化和定制化的搜索焦点。我们的方法展示了将 Amazon Neptune 图数据库功能与 Amazon AI 服务集成,可以实现理解上下文和关系的自然语言照片搜索,从而超越简单的元数据标记,实现智能照片发现。我们通过一个完整的无服务器实现来展示这一点,您可以根据自己的特定用例进行部署和定制。
解决方案概述
本节概述了智能照片搜索系统的技术架构和工作流程。如下图所示,该解决方案使用无服务器 AWS 服务来创建一个可扩展、经济高效的系统,该系统会自动处理照片并支持自然语言搜索。
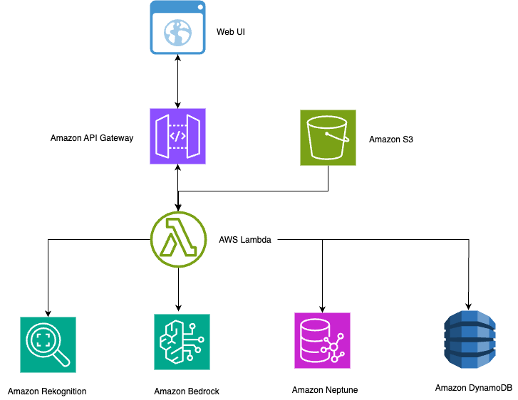
该无服务器架构可有效扩展以支持多种用例:
- 企业 – 员工表彰和活动文档记录
- 医疗保健 – 具有关系跟踪功能的 HIPAA 合规照片管理
- 教育 – 跨部门的学生和教职员工照片整理
- 活动 – 专业的摄影服务,带有自动标记和客户交付
该架构结合了多项 AWS 服务,以创建一个具有上下文感知的照片搜索系统:
- Amazon API Gateway 用于 REST API 端点和 Web 界面集成
- Amazon Bedrock 结合 Anthropic 的 Claude 3.5 Sonnet,用于人工智能驱动的上下文图像字幕生成
- Amazon DynamoDB 用于快速元数据存储和检索
- AWS Lambda 用于跨解决方案组件的无服务器计算编排
- Amazon Neptune 用于将复杂关系存储为图数据库
- Amazon Rekognition 用于人脸检测、识别和对象标记
- Amazon Simple Storage Service (Amazon S3) 用于可扩展的照片存储和触发处理工作流
系统遵循简化的工作流程:
- 图像上传到 S3 存储桶,自动触发 Lambda。
faces/前缀下的参考照片被处理以构建识别模型。- 新照片触发 Amazon Rekognition 进行人脸检测和对象标记。
- Neptune 存储人、对象和上下文之间的连接。
- Amazon Bedrock 利用检测到的人脸和关系创建上下文描述。
- DynamoDB 存储具有快速检索能力的元数据。
- 自然语言查询遍历 Neptune 图以获得智能结果。
完整的源代码可在 GitHub 上获取。
先决条件
在实施此解决方案之前,请确保您具备以下条件:
- 一个拥有 Amazon S3、Lambda、Amazon Rekognition、Neptune、Amazon Bedrock 和 DynamoDB 适当权限的 AWS 账户
- 已配置好程序化访问的 AWS 命令行界面 (AWS CLI) v2.15.0 或更高版本
- 已安装 AWS CDK v2.92.0 或更高版本 (
npm install -g aws-cdk) - Python 3.11 或更高版本及 pip 包管理器
- 用于 AWS CDK 操作的 Node.js 18.x 或更高版本
- 对无服务器架构和图数据库的基本了解
- 在您的 AWS 区域中可以访问 Anthropic 的 Claude 3.5 Sonnet on Amazon Bedrock
部署解决方案
从 GitHub 仓库下载完整的源代码。更详细的设置和部署说明可在 README 中找到。
该项目组织在几个关键目录中,这些目录分离了关注点并实现了模块化开发:
smart-photo-caption-and-search/ ├── lambda/ │ ├── face_indexer.py # 在 Rekognition 中索引参考人脸 │ ├── faces_handler.py # 通过 API 列出已索引的人脸 │ ├── image_processor.py # 主要处理流程 │ ├── search_handler.py # 处理搜索查询 │ ├── style_caption.py # 生成样式化的字幕 │ ├── relationships_handler_neptune.py # 管理 Neptune 关系 │ ├── label_relationships.py # 查询标签层级 │ └── neptune_search.py # Neptune 关系解析 ├── lambda_layer/ # Pillow 图像处理层 ├── neptune_layer/ # Gremlin Python Neptune 层 ├── ui/ │ └── demo.html # 带有 Cognito 身份验证的 Web 界面 ├── app.py # CDK 应用程序入口点 ├── image_name_cap_stack_neptune.py # 启用了 Neptune 的 CDK 堆栈 └── requirements_neptune.txt # Python 依赖项该解决方案使用以下关键 Lambda 函数:
- image_processor.py – 核心处理,包含人脸识别、标签检测和关系丰富的字幕生成
- search_handler.py – 利用多步关系遍历处理自然语言查询
- relationships_handler_neptune.py – 配置驱动的关系管理和图连接
- label_relationships.py – 分层标签查询、对象-人员关联和语义发现
要部署解决方案,请完成以下步骤:
- 运行以下命令安装依赖项:
pip install -r requirements_neptune.txt
- 对于首次设置,请运行以下命令引导 AWS CDK:
cdk bootstrap
- 运行以下命令配置 AWS 资源:
cdk deploy
- 在 Web UI 中设置 Amazon Cognito 用户池凭证。
- 上传参考照片以建立识别基线。
- 使用 API 或 Web UI 创建示例家庭关系。
系统通过无服务器管道自动处理人脸识别、标签检测、关系解析和 AI 字幕生成,从而支持“带有汽车的人的母亲”等自然语言查询,这些查询由 Neptune 图遍历提供支持。
关键特性和用例
在本节中,我们将讨论此解决方案的关键特性和用例。
自动化人脸识别和标记
借助 Amazon Rekognition,您可以自动识别参考照片中的个体,无需手动标记。每人上传几张清晰的图片,系统就能在整个收藏集中识别他们,无论光照或角度如何。这种自动化将标记时间从几周缩短到几小时,支持公司目录、合规性档案和活动管理工作流。
实现关系感知的搜索
通过使用 Neptune,解决方案可以理解照片中谁出现了以及他们是如何关联的。您可以运行自然语言查询,如“莎拉的经理”或“妈妈和她的孩子们”,系统会遍历多跳关系以返回相关的图像。这种语义搜索用直观、上下文感知的发现取代了手动文件夹排序。
自动理解对象和上下文
Amazon Rekognition 检测对象、场景和活动,Neptune 将它们与人员和关系联系起来。这使得复杂的查询成为可能,例如“带有公司车辆的高管”或“教室里的老师”。标签层级是动态生成的,并适应于不同领域——如医疗保健或教育——而无需手动配置。
使用 Amazon Bedrock 生成上下文感知的字幕
使用 Amazon Bedrock,系统会生成有意义的、与关系相关的字幕,例如“莎拉和她的经理讨论季度结果”,而不是通用的字幕。字幕的语气可以进行调整(例如,合规性用客观、营销用叙事、执行摘要用简洁),从而增强可搜索性和沟通效果。
提供直观的 Web 体验
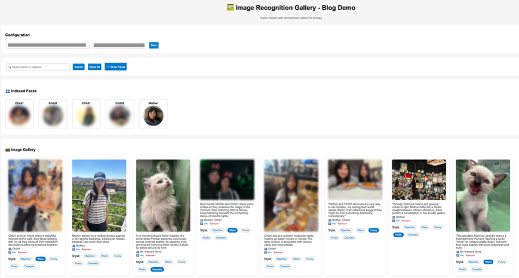
通过 Web UI,用户可以使用自然语言搜索照片、查看 AI 生成的字幕并动态调整语气。例如,查询“母亲和孩子们”或“户外活动”会立即返回相关的、带字幕的结果。这种统一的体验支持企业工作流和个人收藏。
以下屏幕截图展示了如何使用 Web UI 进行智能照片搜索和字幕样式设置。
利用标签层级扩展图关系
Neptune 能够扩展以模拟组织或数据集中数千种关系和标签层级。关系在图像处理过程中自动生成,支持快速的语义发现,同时在数据增长时保持性能和灵活性。
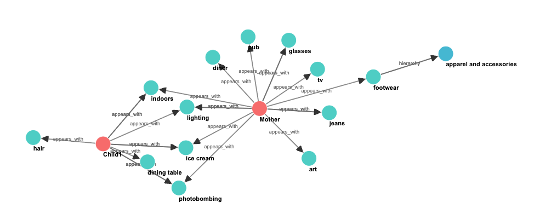
下图展示了一个示例人员关系图(配置驱动)。
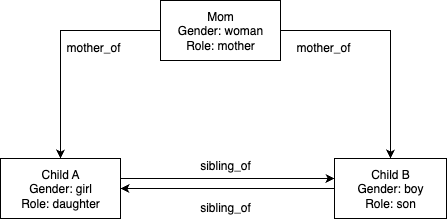
人员关系通过传递给 initialize_relationship_data() 函数的 JSON 数据结构进行配置。这种配置驱动的方法支持无限的用例,无需代码修改——您只需在配置对象中定义人员和关系即可。
下图展示了一个示例标签层级图(由 Amazon Rekognition 自动生成)。
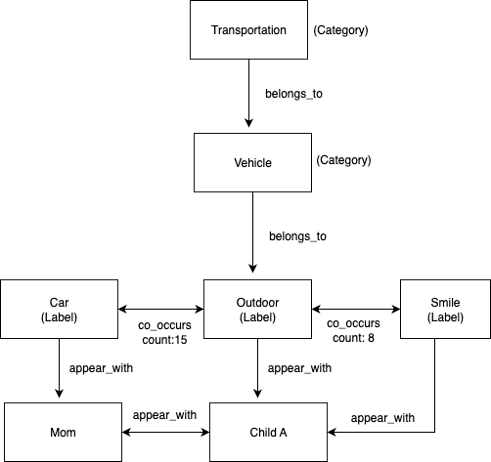
标签层级和共同出现模式在图像处理过程中自动生成。Amazon Rekognition 提供类别分类,创建 belongs_to 关系,而 appears_with 和 co_occurs_with 关系则在处理图像时动态构建。
以下屏幕截图展示了完整图的一个子集,演示了多层关系类型。
数据库生成方法
关系图通过 initialize_relationship_data() 函数使用灵活的配置驱动方法。这减轻了硬编码的需求并支持无限的用例:
# 通用配置结构 config = { "people": [ {"name": "alice", "gender": "woman", "role": "mother"}, {"name": "jane", "gender": "girl", "role": "daughter"} ], "relationships": [ {"from": "alice", "to": "jane", "type": "parent_of", "subtype": "mother_of"}, {"from": "jane", "to": "david", "type": "sibling_of", "bidirectional": True} ] } # 通用关系创建 for rel in relationships_data: g.V().has('name', rel["from"]).addE(rel["type"]).to( __.V().has('name', rel["to"]) ).property('type', rel["subtype"]).next() # 业务示例 - 只需更改配置 business_config = { "people": [{"name": "sarah", "role": "manager"}], "relationships": [{"from": "sarah", "to": "john", "type": "manages", "subtype": "manager_of"}] }标签关系数据库是通过 store_labels_in_neptune() 函数在图像处理过程中自动创建的:
# Rekognition 提供带有类别的标签 response = rekognition.detect_labels( Image={'Bytes': image_bytes}, MaxLabels=20, MinConfidence=70 ) # 提取标签和类别 for label in response.get('Labels', []): label_data = { 'name': label['Name'], # 例如,“汽车” 'categories': [cat['Name'] for cat in label.get('Categories', [])] # 例如,[“车辆”,“交通”] } # 在 Neptune 中自动创建层级结构 for category in categories: # 创建 belongs_to 关系 (Car -> Vehicle -> Transportation) g.V().has('name', label_name).addE('belongs_to').to( __.V().has('name', category_name) ).property('type', 'hierarchy').next() # 创建 appears_with 关系 (Person -> Car) g.V().has('name', person_name).addE('appears_with').to( __.V().has('name', label_name) ).property('confidence', confidence).next()有了这些功能,您就可以管理具有复杂关系查询的大型照片集,通过语义上下文发现照片,并通过标签共同出现模式查找主题收藏。
性能和可扩展性考虑
请考虑以下性能和可扩展性因素:
- 处理批量上传 – 该系统能高效处理大型照片集,从小型家庭相册到包含数千张图像的企业档案。内置的智能功能可管理 API 速率限制,即使在高峰上传期间也能确保可靠的处理。
- 成本优化 – 无服务器架构确保您只为实际使用付费,这对于小型团队和大型企业都具有成本效益。作为参考,处理 1,000 张图片通常花费约 $15–$25(包括 Amazon Rekognition 人脸检测、Amazon Bedrock 字幕生成和 Lambda 函数执行),Neptune 集群的月费为 $100–$150,与处理量无关。Amazon S3 上的存储成本保持在每 1,000 张图片低于 $1 的低水平。
- 扩展性能 – Neptune 图数据库方法可以有效地从小型家庭结构扩展到具有数千个人的企业级网络。该系统在关系查询中保持快速响应时间,并通过自动重试逻辑和进度跟踪支持大型照片集的批量处理。
安全性和隐私
此解决方案实施了全面的安全措施,以保护敏感的图像和人脸识别数据。该系统使用 AWS Key Management Service (AWS KMS) 管理的密钥,使用 AES-256 加密对静态数据进行加密,并使用 TLS 1.2 或更高版本保护传输中的数据。Neptune 和 Lambda 函数在虚拟私有云 (VPC) 子网内运行,与直接互联网访问隔离,API Gateway 提供了唯一的公共端点,并带有 CORS 策略和速率限制。访问控制遵循最小权限原则,使用 AWS Identity and Access Management (IAM) 策略,这些策略只授予所需的最低权限:Lambda 函数只能访问特定的 S3 存储桶和 DynamoDB 表,而 Neptune 访问则限制于授权的数据库操作。图像和人脸识别数据保留在您的 AWS 账户中,绝不会共享给 AWS 服务之外的任何地方。您可以配置 Amazon S3 生命周期策略以自动管理数据保留,并且 AWS CloudTrail 提供数据访问和 API 调用的完整审计日志,用于合规性监控,并通过额外的 Amazon GuardDuty 监控来支持 GDPR 和 HIPAA 要求,以实现威胁检测。
清理
为避免产生后续费用,请完成以下步骤删除您创建的资源:
- 从 S3 存储桶中删除图像:
aws s3 rm s3://YOUR_BUCKET_NAME –recursive
- 删除 Neptune 集群(此命令还会自动删除 Lambda 函数):
cdk destroy
- 移除 Amazon Rekognition 人脸集合:
aws rekognition delete-collection --collection-id face-collection
结论
此解决方案展示了 Amazon Rekognition、Amazon Neptune 和 Amazon Bedrock 如何协同工作,以实现理解视觉内容和上下文的智能照片搜索。它构建在一个完全无服务器的架构之上,结合了计算机视觉、图模型和自然语言理解,以提供可扩展的、类人的人工发现体验。通过将照片集转变为人员、对象和瞬间的知识图谱,它重新定义了用户与视觉数据的交互方式——使搜索更具语义性、关系性和意义性。最终,它体现了 AWS AI 和图技术在启用安全、上下文感知的照片理解方面的可靠性和可信赖性。
要了解更多信息,请参阅以下资源:
评论区