



📢 转载信息
原文链接:https://www.kdnuggets.com/building-practical-mlops-for-a-personal-ml-project
原文作者:Nate Rosidi

作者供图
# 引言
您可能已经完成了相当多的数据科学和机器学习项目。
这些项目非常适合磨练技能,展示您所知道和学到的知识。但事实是:它们往往未能达到现实世界中、生产级别数据科学应有的水平。
在本文中,我们将以一个项目——美国职业薪资分析——为例,将其转变为一个可供实际使用的项目。
为此,我们将介绍一个简单但可靠的机器学习运维(MLOps)设置,涵盖从版本控制到部署的一切内容。
这对早期职业数据工作者、自由职业者、作品集构建者,或者任何希望其工作看起来像是来自专业设置的人来说都很有价值,即使它最初并非如此。
在本文中,我们将超越Notebook项目:我们将设置MLOps结构,学习如何设置可复现的管道、模型件、一个简单的本地应用程序编程接口(API)、日志记录,最后是如何生成有用的文档。
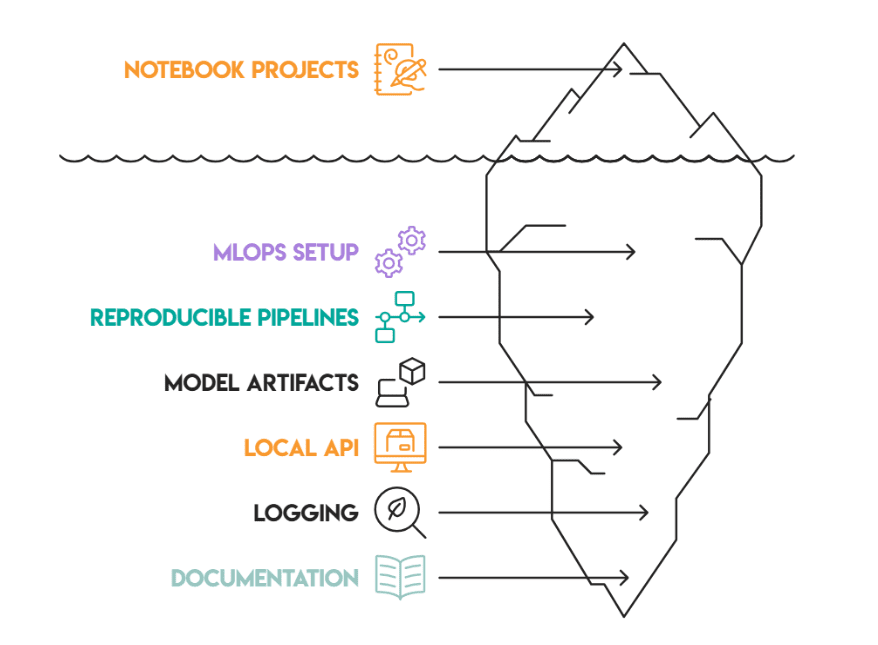
作者供图
# 理解任务和数据集
该项目的场景涉及一个全国性的美国数据集,其中包含美国所有50个州和地区的年度职业薪资和就业数据。数据详细说明了就业总量、平均薪资、职业组、薪资百分位数以及地理标识符。

您的主要目标是:
- 比较不同州和职业类别的薪资差异
- 运行统计检验(T检验、Z检验、F检验)
- 建立回归模型以理解就业与薪资之间的关系
- 可视化薪资分布和职业趋势
数据集的一些关键列:
OCC_TITLE— 职业名称TOT_EMP— 就业总量A_MEAN— 年平均薪资PRIM_STATE— 州缩写O_GROUP— 职业类别(主要、总计、详细)
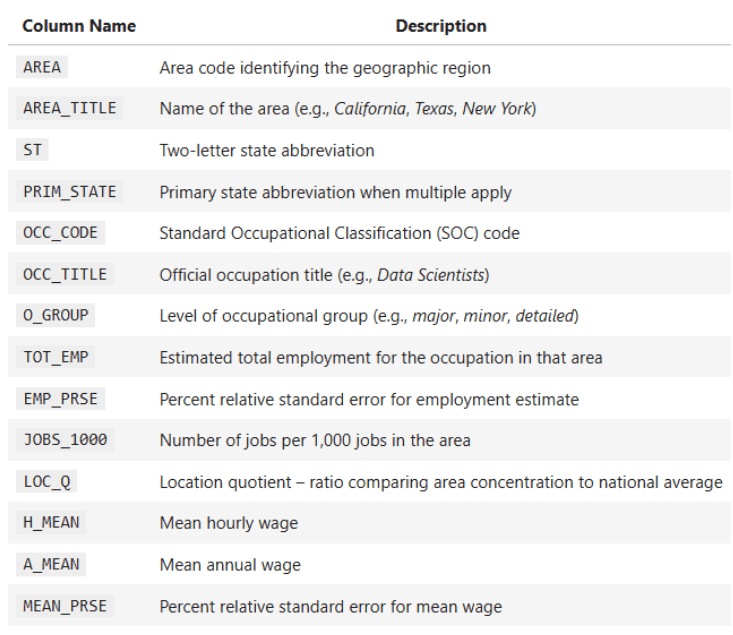
您的任务是提供关于薪资差异、工作分布和统计关系的可靠见解,但挑战不止于此。
挑战还在于以一种可重用、可复现且干净的方式构建项目结构。这是当今所有数据科学家都需要的非常重要的技能。
# 从版本控制开始
不要跳过基础知识。即使是小项目也应该拥有干净的结构和适当的版本控制。以下是一个直观且对审查者友好的文件夹设置:

一些最佳实践:
- 保持原始数据不变(Immutable)。您无需触碰它,只需复制即可进行处理。
- 如果您的数据集变得庞大而笨重,请考虑使用Git LFS。
- 将
src/中的每个脚本都集中于一件事。您的未来自己会感谢您的。 - 频繁提交,并使用清晰的提交信息,例如:
feat: add T-test comparison between management and production wages(feat: 添加管理层与生产层薪资的T检验对比)。
即使有这种简单的结构,您也向招聘经理展示了您正在像专业人士一样思考和规划,而不是像初级人员。
# 构建可复现的管道(告别Notebook的混乱)
Notebook非常适合探索。您尝试一些东西,调整一个过滤器,重新运行一个单元格,复制一个图表,不知不觉中,您就有40个单元格,却不清楚是什么产生了最终结果。
为了让这个项目感觉“接近生产”,我们将把已经存在于Notebook中的逻辑包装成一个单一的预处理函数。该函数将成为美国职业薪资数据被:
- 从Excel文件加载
- 清理并转换为数值
- 标准化(州、职业组、职业代码)
- 使用诸如总薪酬之类的辅助列进行丰富
从那时起,所有的分析——图表、T检验、回归、相关性、Z检验——都将重用同一个清理过的数据框。
// 从Notebook顶部单元格到可重用函数
目前,Notebook大致执行以下操作:
- 加载文件:
state_M2024_dl.xlsx - 将第一个工作表解析为数据框
- 将
A_MEAN、TOT_EMP等列转换为数值类型 - 在以下分析中使用这些列:
- 州级薪资比较
- 线性回归(
TOT_EMP→A_MEAN) - 皮尔逊相关系数(Q6)
- 技术与非技术职位的Z检验(Q7)
- 薪资方差的Levene检验
我们将把这些操作变成一个名为preprocess_wage_data的单一函数,您可以在项目的任何地方调用它:
from src.preprocessing import preprocess_wage_data df = preprocess_wage_data("data/raw/state_M2024_dl.xlsx")
现在,您的Notebook、脚本或未来的API调用都在“干净数据”的定义上达成了一致。
// 预处理管道实际执行的操作
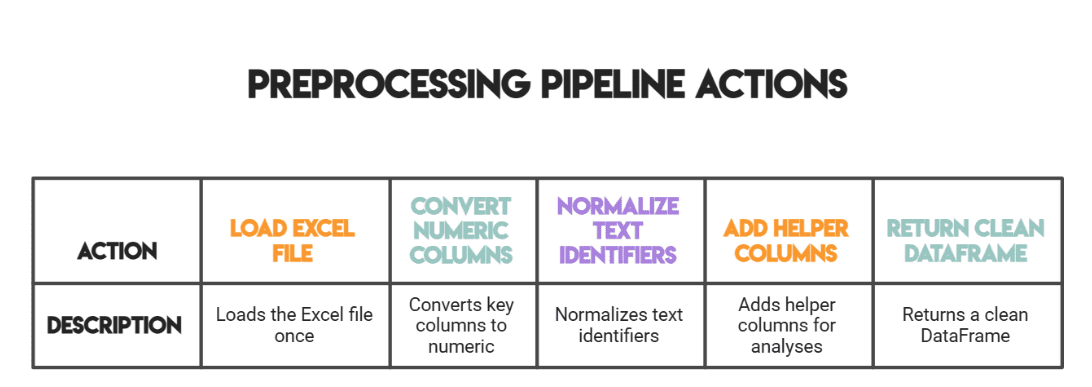
对于这个数据集,预处理管道将:
1. 只加载一次Excel文件。
xls = pd.ExcelFile(file_path) df_raw = xls.parse(xls.sheet_names[0]) df_raw.head()

2. 将关键的数值列转换为数值类型。
这些是您的分析实际使用的列:
- 就业和强度:
TOT_EMP,EMP_PRSE,JOBS_1000,LOC_QUOTIENT - 薪资衡量:
H_MEAN,A_MEAN,MEAN_PRSE - 薪资百分位数:
H_PCT10,H_PCT25,H_MEDIAN,H_PCT75,H_PCT90,A_PCT10,A_PCT25,A_MEDIAN,A_PCT75,A_PCT90
我们安全地强制转换类型:
df = df_raw.copy() numeric_cols = [ "TOT_EMP", "EMP_PRSE", "JOBS_1000", "LOC_QUOTIENT" ….] for col in numeric_cols: if col in df.columns: df[col] = pd.to_numeric(df[col], errors="coerce")
如果未来的文件包含奇怪的值(例如'**'或'N/A'),您的代码不会崩溃,它只会将它们视为缺失值,管道也不会中断。
3. 标准化文本标识符。
为了保持一致的分类和过滤:
PRIM_STATE转为大写(例如,“ca” → “CA”)O_GROUP转为小写(例如,“Major” → “major”)OCC_CODE转为字符串(以便在技术与非技术Z检验中可以使用.str.startswith("15"))
4. 添加分析中使用的辅助列。
这些很简单但很方便。按行计算的总薪酬辅助列,使用平均薪资近似计算:
df["TOTAL_PAYROLL"] = df["A_MEAN"] * df["TOT_EMP"]
薪资与就业比率(Wage-to-employment ratio)对于发现低就业高薪资的细分市场很有用,并且可以防止除以零的错误:
df["WAGE_EMP_RATIO"] = df["A_MEAN"] / df["TOT_EMP"].replace({0: np.nan})
5. 返回一个干净的数据框供项目其余部分使用。
您后续用于:
- 绘制最高/最低州的图表
- T检验(管理层 vs 生产层)
- 回归(
TOT_EMP→A_MEAN) - 相关性分析(Q6)
- Z检验(Q7)
- Levene检验
的代码都可以从以下内容开始:
df = preprocess_wage_data("state_M2024_dl.xlsx")
完整的预处理函数:
将此代码放入src/preprocessing.py中:
import pandas as pd import numpy as np def preprocess_wage_data(file_path: str = "state_M2024_dl.xlsx") -> pd.DataFrame: """Load and clean the U.S. occupational wage data from Excel. - Reads the first sheet of the Excel file. - Ensures key numeric columns are numeric. - Normalizes text identifiers (state, occupation group, occupation code). - Adds helper columns used in later analysis. """ # Load raw Excel file xls = pd.ExcelFile(file_path)
检查其余代码请点击此处。
# 保存您的统计模型和件(Artifacts)
什么是模型件?例如:回归模型、相关矩阵、清理过的数据集和图表。
import joblib joblib.dump(model, "models/employment_wage_regression.pkl")
为什么要保存件?
- 避免在API调用或仪表板中重新计算结果
- 为您将来的比较保留版本
- 保持分析与推理过程的分离
这些小小的习惯可以将您的项目从探索性提升到具备生产友好性。
# 使其在本地运行(使用API或微型Web界面)
您不必直接跳入Docker和Kubernetes才能“部署”它。对于许多现实世界的分析工作,您的第一个API实际上只是:
- 一个干净的预处理函数
- 几个命名良好的分析函数
- 一个将它们组合在一起的小脚本或Notebook单元格
这本身就使得您的项目易于从以下位置调用:
- 另一个Notebook
- Streamlit/Gradio仪表板
- 一个未来的FastAPI或Flask应用
// 将您的分析转化为一个微型“分析API”
您已经在Notebook中拥有核心逻辑:
- T检验:管理层与生产层薪资比较
- 回归:
TOT_EMP→A_MEAN - 皮尔逊相关系数(Q6)
- 技术与非技术职位的Z检验(Q7)
- 薪资方差的Levene检验
我们将至少将其中一个包装成一个函数,使其行为像一个微小的API端点。
示例:“比较管理层与生产层薪资”
这是Notebook中已有的T检验代码的函数版本:
from scipy.stats import ttest_ind import pandas as pd def compare_management_vs_production(df: pd.DataFrame): """Two-sample T-test between Management and Production occupations.""" # Filter for relevant occupations mgmt = df[df["OCC_TITLE"].str.contains("Management", case=False, na=False)] prod = df[df["OCC_TITLE"].str.contains("Production", case=False, na=False)] # Drop missing values mgmt_wages = mgmt["A_MEAN"].dropna() prod_wages = prod["A_MEAN"].dropna() # Perform two-sample T-test (Welch's t-test) t_stat, p_value = ttest_ind(mgmt_wages, prod_wages, equal_var=False) return t_stat, p_value
现在这个测试可以从以下地方重用:
- 主脚本
- Streamlit滑块
- 未来的FastAPI路由
而无需复制任何Notebook单元格。
// 一个简单的本地入口点
以下是将所有部件组合在一起的纯Python脚本,您可以将其命名为main.py或在一个Notebook单元格中运行:
from preprocessing import preprocess_wage_data from statistics import run_q6_pearson_test, run_q7_ztest # move these from the notebook from analysis import compare_management_vs_production # the function above if __name__ == "__main__": # 1. Load and preprocess the data df = preprocess_wage_data("state_M2024_dl.xlsx") # 2. Run core analyses t_stat, p_value = compare_management_vs_production(df) print(f"T-test (Management vs Production) -> t={t_stat:.2f}, p={p_value:.4f}") corr_q6, p_q6 = run_q6_pearson_test(df) print(f"Pearson correlation (TOT_EMP vs A_MEAN) -> r={corr_q6:.4f}, p={p_q6:.4f}") z_q7 = run_q7_ztest(df) print(f"Z-test (Tech vs Non-tech median wages) -> z={z_q7:.4f}")
这目前看起来不像一个Web API,但概念上它是:
- 输入:清理过的数据框
- 操作:命名好的分析函数
- 输出:定义好的数字,您可以将其呈现在仪表板、报告中,或者稍后呈现在REST端点中。
# 记录一切(包括细节)
大多数人会忽略日志记录,但它是让您的项目可调试和可信的关键所在。
即使在这个初级友好的分析项目中,了解以下信息也很有用:
- 加载了哪个文件
- 有多少行通过了预处理
- 运行了哪些测试
- 关键的测试统计数据是什么
我们设置一个简单的日志配置,可以在脚本和Notebook中重复使用,而不是手动打印所有内容并滚动查看Notebook输出。
// 基本日志设置
在您的项目中创建一个logs/文件夹,然后在代码的某处(例如main.py的顶部或专用的logging_config.py)添加此内容:
import logging from pathlib import Path # Make sure logs/ exists Path("logs").mkdir(exist_ok=True) logging.basicConfig( filename="logs/pipeline.log", level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s" )
现在,每次运行管道时,logs/pipeline.log文件都会被更新。
// 记录预处理和分析过程
我们可以扩展第5步中的主示例,以记录正在发生的事情:
from preprocessing import preprocess_wage_data from statistics import run_q6_pearson_test, run_q7_ztest from analysis import compare_management_vs_production import logging if __name__ == "__main__": logging.info("Starting wage analysis pipeline.") # 1. Preprocess data df = preprocess_wage_data("state_M2024_dl.xlsx") logging.info("Loaded cleaned dataset with %d rows and %d columns.", df.shape[0], df.shape[1]) # 2. T-test: Management vs Production t_stat, p_value = compare_management_vs_production(df) logging.info("T-test (Mgmt vs Prod) -> t=%.3f, p=%.4f", t_stat, p_value) # 3. Pearson correlation (Q6) corr_q6, p_q6 = run_q6_pearson_test(df) logging.info("Pearson (TOT_EMP vs A_MEAN) -> r=%.4f, p=%.4f", corr_q6, p_q6) # 4. Z-test (Q7) z_q7 = run_q7_ztest(df) logging.info("Z-test (Tech vs Non-tech median wages) -> z=%.3f", z_q7) logging.info("Pipeline finished successfully.")
现在,不再猜测上次运行Notebook时发生了什么,您可以打开logs/pipeline.log并查看时间线:
- 预处理何时开始
- 您有多少行/列
- 测试统计数据是什么
这是一个很小的步骤,但却是非常“MLOps”的做法:您不仅在运行分析,您还在观察它们。
# 讲述故事(即为人类写作)
文档很重要,尤其是在处理薪资、职业和区域比较等真正关系到决策者的主题时。
您的README或最终的Notebook应该包括:
- 本次分析为何重要
- 薪资和就业模式的总结
- 关键的可视化(最高/最低州、薪资分布、组别比较)
- 对每个统计检验的选择理由和解释
- 回归和相关性结果的清晰解释
- 局限性(例如,缺失的州记录、抽样方差)
- 下一步的深入分析或仪表板部署建议
好的文档可以将数据集项目转变为任何人都可以使用和理解的东西。
# 结论
这一切为什么重要?
因为在现实世界中,数据科学并非活在真空中。您的漂亮模型如果其他人无法运行、理解或信任,那就毫无用处。MLOps正是在这里发挥作用,它不是一个流行词,而是连接一个酷炫实验和一个实际可用产品之间的桥梁。
在本文中,我们从一个典型的基于Notebook的作业开始,展示了如何为其赋予结构和持久力。我们介绍了:
- 版本控制,以保持工作井井有条
- 用于预处理和检测的干净、可复现的管道
- 模型序列化,以便我们可以重用(而不是重新训练)模型
- 用于本地部署的轻量级API
- 用于跟踪幕后情况的日志记录
- 最后,一份能够与技术人员和业务人员沟通的文档
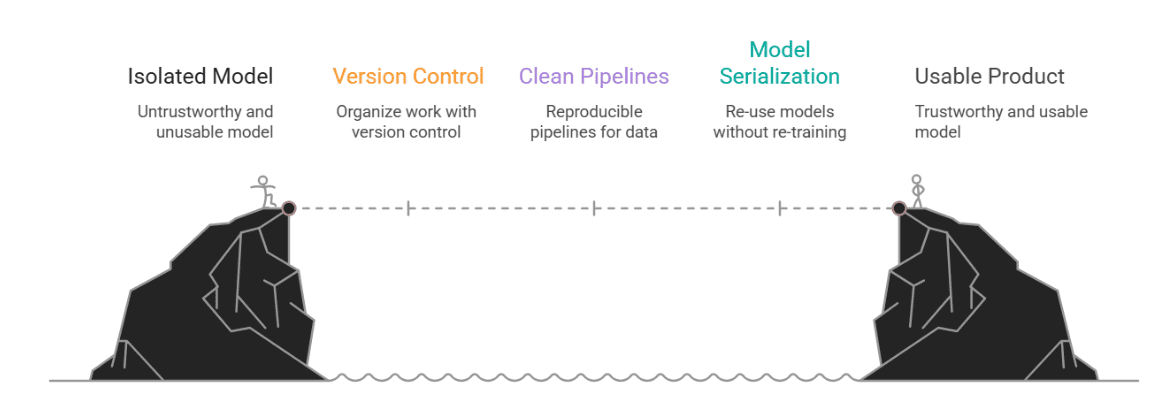
作者供图
Nate Rosidi 是一位数据科学家和产品战略家。他也是一位兼职教授,教授分析课程,并且是StrataScratch的创始人,StrataScratch是一个帮助数据科学家准备面试的平台,提供顶级公司的真实面试问题。Nate撰写关于职业市场最新趋势、提供面试建议、分享数据科学项目,并涵盖SQL的所有内容。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区