



📢 转载信息
原文链接:https://machinelearningmastery.com/creating-a-llama-or-gpt-model-for-next-token-prediction/
原文作者:Adrian Tam
自然语言生成(NLG)具有挑战性,因为人类语言复杂且不可预测。一种逐个随机生成词语的初级方法对人类来说意义不大。现代的解码器仅有Transformer模型在用大量文本数据进行训练时,已被证明在NLG任务中非常有效。这些模型可能非常庞大,但其结构相对简单。在本文中,您将学习如何创建一个用于下一个标记预测的Llama或GPT模型。
让我们开始吧。

创建用于下一个标记预测的Llama或GPT模型
图片来源:Roman Kraft。保留部分权利。
概览
本文分为三个部分:
- 理解Llama或GPT模型的架构
- 为预训练创建一个Llama或GPT模型
- 架构中的变体
理解Llama或GPT模型的架构
Llama或GPT模型的架构简单来说就是一组Transformer块的堆叠。每个Transformer块由一个自注意力子层和一个前馈子层组成,每个子层周围都应用了归一化和残差连接。模型就仅此而已。
GPT-2和Llama模型的架构如下所示:
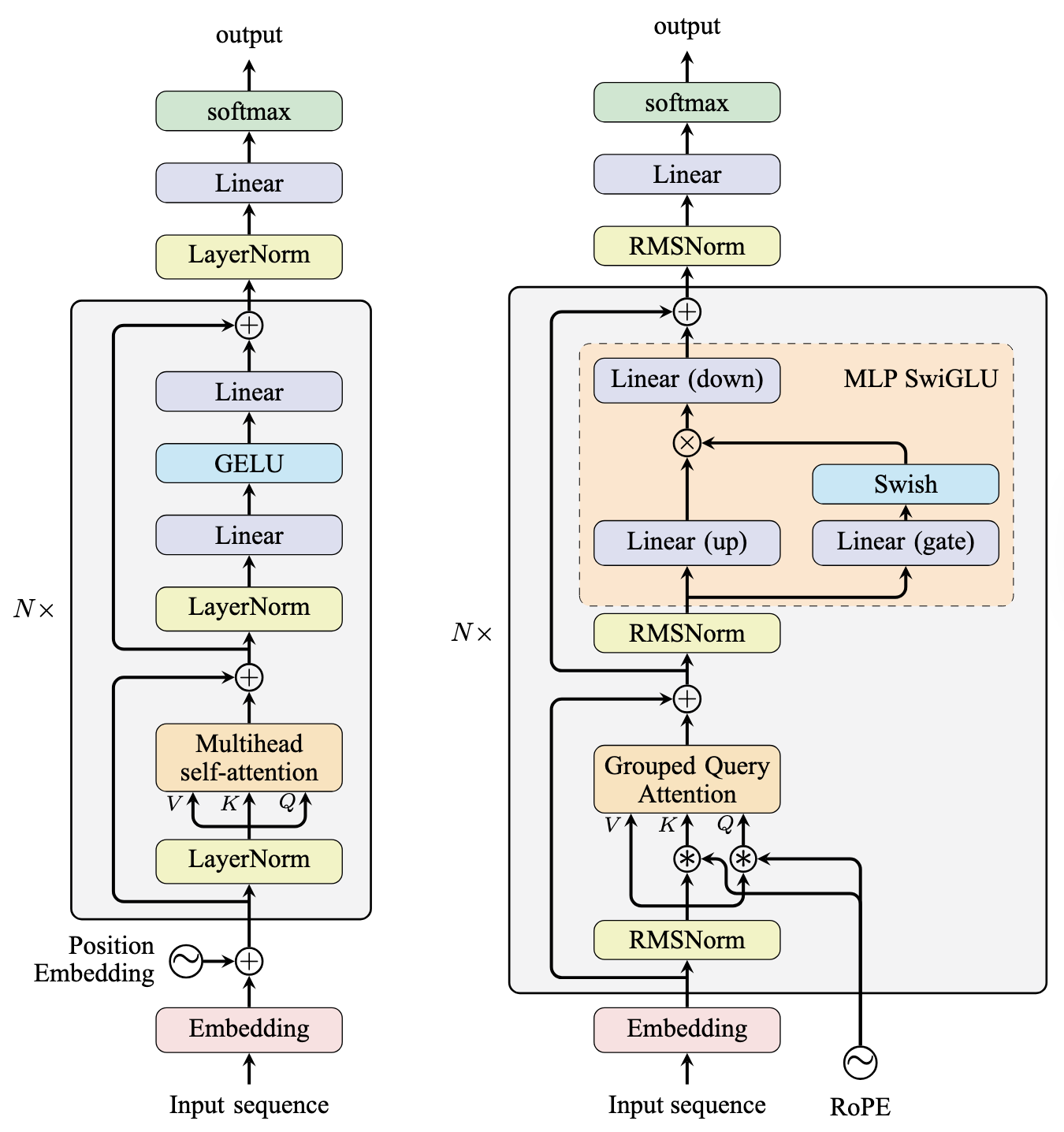
GPT-2(左)和Llama(右)的模型架构
GPT-2较旧,并且大多遵循原始的编码器-解码器Transformer架构。它使用了层归一化(LayerNorm)和多头注意力(Multi-Headed Attention),在前馈子层中有两个线性层。GPT-2与原始Transformer设计的不同之处在于:
- 使用Pre-Norm(前归一化)而不是Post-Norm(后归一化)
- 使用可学习的位置嵌入(Learned Position Embeddings)而不是正弦位置嵌入(Sinusoidal Embeddings)
- 在前馈子层中使用GELU作为激活函数,而不是ReLU
由于GPT-2是仅解码器模型,因此没有编码器输入可用,所以移除了原始Transformer解码器堆栈中的交叉注意力子层。但是,你不应将其架构与Transformer编码器混淆,因为自注意力子层会应用一个因果掩码,迫使模型只关注左侧的上下文。
Llama模型对GPT-2的几个方面进行了修改,Llama的第1版到第3版共享相同的架构。与GPT-2一样,Llama模型也是一个仅解码器模型,并使用Pre-Norm。然而,与GPT-2不同的是,Llama模型:
- 使用分组查询注意力(Grouped Query Attention, GQA)代替多头注意力(MHA)
- 使用旋转位置嵌入(Rotary Position Embeddings, RoPE)代替可学习位置嵌入或正弦位置嵌入,并且RoPE应用于每个自注意力子层
- 在前馈子层中使用SwiGLU作为激活函数,而不是ReLU,因此前馈子层有三个线性层并涉及逐元素乘法
- 使用RMSNorm作为归一化函数,而不是LayerNorm
在整个Transformer堆栈之后,会对隐藏状态应用另一个归一化层。基础模型指的是从输入嵌入到这个最终归一化层的神经网络。
对于预训练,您希望模型学会预测序列中的下一个标记。为此,您需要向模型添加一个预训练头——一个将隐藏状态投影到词汇表大小的线性层。然后使用Softmax函数得到词汇表上的概率分布。
为预训练创建一个Llama模型
网上有许多Llama模型的实现。如果您更关心训练结果而不是理解模型架构,可以使用现有的代码,或者使用Hugging Face的transformers库来创建。例如,下面创建的model是一个具有12层和预训练头的Llama模型:
|
1
2
3
4
5
6
7
8
|
from transformers import LlamaForCausalLM, LlamaConfig
config = LlamaConfig(
num_hidden_layers=12,
hidden_size=768,
num_attention_heads=12
)
model = LlamaForCausalLM(config=config)
|
然而,用PyTorch从头开始创建一个Llama模型并不困难。首先,我们定义一个数据类来保存模型的配置:
|
1
2
3
4
5
6
7
8
9
10
11
|
import dataclasses
@dataclasses.dataclass
class LlamaConfig:
vocab_size: int = 50000 # Size of the tokenizer vocabulary
max_position_embeddings: int = 2048 # Maximum sequence length
hidden_size: int = 768 # Dimension of hidden layers
intermediate_size: int = 4*768 # Dimension of MLP's hidden layer
num_hidden_layers: int = 12 # Number of transformer layers
num_attention_heads: int = 12 # Number of attention heads
num_key_value_heads: int = 3 # Number of key-value heads for GQA
|
模型应该具有与所使用的分词器相匹配的固定词汇表大小。最大序列长度是旋转位置嵌入的参数,应该足够大,以容纳数据集中最长的序列。隐藏大小、中间大小、层数和注意力头数是直接决定模型大小以及训练或推理速度的超参数。
旋转位置嵌入
我们首先实现旋转位置嵌入(RoPE)。与其它模块不同,RoPE没有任何可学习的参数。相反,它预先计算出余弦和正弦矩阵并将它们保存为缓冲区(buffers)。在计算注意力之前,RoPE应用于查询(Q)和键(K)矩阵。在公式中,RoPE的应用如下:
$$
\begin{aligned}
Q_{s,i} &= Q_{s,i} \cos(s\theta_i) \ – Q_{s,\frac{d}{2}+i} \sin(s\theta_i) \\
Q_{s,\frac{d}{2}+i} &= Q_{s,i} \sin(s\theta_i) + Q_{s,\frac{d}{2}+i} \cos(s\theta_i)
\end{aligned}
$$
其中 $Q_{s,i}$ 是查询矩阵 $Q$ 在序列位置 $s$ 上的第 $i$ 个标记嵌入元素。标记嵌入的长度(也称为隐藏大小或模型维度)是 $d$。对键矩阵 $K$ 应用RoPE类似。频率项 $ heta_i$ 的计算公式如下:
$$ \theta_i = \frac{1}{10000^{2i/d}} $$
要实现RoPE,您可以使用以下代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
import torch.nn as nn
def rotate_half(x):
"""Rotates half the hidden dims of the input."""
x1, x2 = x.chunk(2, dim=-1)
return torch.cat((-x2, x1), dim=-1)
class RotaryPositionEncoding(nn.Module):
def __init__(self, dim, max_position_embeddings):
super().__init__()
self.dim = dim
self.max_position_embeddings = max_position_embeddings
N = 10000.0
inv_freq = 1.0 / (N ** (torch.arange(0, dim, 2).float() / dim))
inv_freq = torch.cat((inv_freq, inv_freq), dim=-1)
position = torch.arange(max_position_embeddings).float()
sinusoid_inp = torch.outer(position, inv_freq)
self.register_buffer("cos", sinusoid_inp.cos())
self.register_buffer("sin", sinusoid_inp.sin())
def forward(self, x):
"""Apply RoPE to tensor x"""
batch_size, seq_len, num_heads, head_dim = x.shape
dtype = x.dtype
cos = self.cos.to(dtype)[:seq_len].view(1, seq_len, 1, -1)
sin = self.sin.to(dtype)[:seq_len].view(1, seq_len, 1, -1)
output = (x * cos) + (rotate_half(x) * sin)
return output
|
RoPE是一个用于改变输入张量的函数。要测试上述RoPE模块,您可以执行以下操作:
|
1
2
3
4
5
6
7
8
|
...
import torch
batch_size, seq_len, hidden_size = 1, 10, 128
max_position_embeddings = 2048
x = torch.randn(batch_size, seq_len, hidden_size)
rope = RotaryPositionEncoding(hidden_size, max_position_embeddings)
x_rope = rope(x)
|
自注意力子层
自注意力子层是Transformer模型的核心。它负责关注输入序列的上下文。在Llama模型中,使用了分组查询注意力(GQA),其中键(K)和值(V)矩阵投影到的头数少于查询(Q)矩阵的头数。
您无需从头开始实现GQA,因为PyTorch在scaled_dot_product_attention函数中内置了GQA的实现。您只需向该函数传递enable_gqa=True参数即可。
下面是实现自注意力子层的方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
class LlamaAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.hidden_size // self.num_heads
self.num_kv_heads = config.num_key_value_heads # GQA: H_kv < H_q
# hidden_size must be divisible by num_heads
assert (self.head_dim * self.num_heads) == self.hidden_size
# Linear layers for Q, K, V, and O projections
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False)
self.k_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False)
self.v_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False)
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
def forward(self, hidden_states, rope, attn_mask):
bs, seq_len, dim = hidden_states.size()
# Project inputs to Q, K, V
query_states = self.q_proj(hidden_states).view(bs, seq_len, self.num_heads, self.head_dim)
key_states = self.k_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim)
value_states = self.v_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim)
# Apply rotary position embeddings
query_states = rope(query_states)
key_states = rope(key_states)
# Transpose tensors from BSHD to BHSD dimension for scaled_dot_product_attention
query_states = query_states.transpose(1, 2)
key_states = key_states.transpose(1, 2)
value_states = value_states.transpose(1, 2)
# Use PyTorch's optimized attention implementation
attn_output = F.scaled_dot_product_attention(
query_states, key_states, value_states, attn_mask=attn_mask,
dropout_p=0.0,
enable_gqa=True,
)
# Transpose output tensor from BHSD to BSHD dimension, reshape to 3D, and then project output
attn_output = attn_output.transpose(1, 2).reshape(bs, seq_len, self.hidden_size)
attn_output = self.o_proj(attn_output)
return attn_output
|
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区