



📢 转载信息
原文作者:Baishali Chaudhury, Isaac Privitera, and Rahul Ghosh
大型语言模型(LLM)智能体通过将基础模型的推理能力与专业工具和领域知识相结合,彻底改变了我们处理复杂、多步骤任务的方式。虽然使用 ReAct 等框架的单智能体系统在处理简单任务时效果良好,但现实世界的挑战通常需要多个专业智能体协同工作。想象一下规划一次商务旅行:需要一个智能体根据日程限制研究航班,另一个智能体查找会议地点附近的住宿,第三个智能体协调地面交通——每个智能体都需要不同的工具和领域知识。这种多智能体方法引入了一个关键的架构挑战:如何编排智能体之间的数据流,以确保可靠、可预测的结果。
如果没有适当的编排,智能体之间的交互可能会变得不可预测,使得系统在生产环境中难以调试、监控和扩展。智能体编排通过定义明确的工作流来解决这个问题,这些工作流控制着智能体如何通信、何时执行以及它们的输如何整合到连贯的解决方案中。编排不是允许智能体进行即席交互,而是创建结构化的路径,使推理透明化和信息流意图化。
Strands Agents 是一款开源 SDK,专为构建经过编排的人工智能(AI)系统而设计。它提供了灵活的智能体抽象、无缝的工具集成、全面的可观测性,以及诸如 GraphBuilder 等编排组件,使开发人员能够精确、可控地将智能体连接到有向工作流中。
在本文中,我们将探讨使用 Strands Agents 实现的两种强大的编排模式。使用一套常见的旅行规划工具,我们演示了不同的编排策略如何通过不同的推理方法来解决同一个问题:ReWOO(无观察推理),它将规划、执行和综合分离为离散阶段;以及 Reflexion,它通过结构化的批判和改进周期来实现迭代细化。这些示例将向您展示 Strands 如何实现对多智能体工作流的精确控制,从而产生更可靠、更透明、更易于维护的 AI 系统。
开始使用 Strands Agents
Strands Agents 是 AWS 最近推出的用于构建生产级 AI 智能体的开源框架。它通过将 智能体循环 抽象为三个核心组件,简化了智能体的开发:
- 模型提供商 (Model Provider):推理引擎(例如 Amazon Bedrock 上的 Claude)
- 系统提示 (System Prompt):塑造智能体角色和约束的指令
- 工具箱 (Toolbelt):智能体可以调用的 API 或函数集合
这种模块化设计允许用户从简单的单智能体系统开始,扩展到复杂的多智能体架构。Strands 内置支持 异步操作、会话状态管理,并与包括 Amazon Bedrock、Anthropic 和 Mistral 在内的多个提供商集成。它还可以与 AWS 服务(如 Lambda、Fargate 和 AgentCore)无缝集成。
Strands 特别强大的地方在于其 多智能体编排 功能。用户可以通过多种方式组合智能体:将一个智能体用作另一个智能体的工具,通过交接在智能体之间传递控制权,或协调多个并行工作的智能体。SDK 的 GraphBuilder 功能允许用户将智能体连接到结构化工作流中,使它们能够在受控、可预测的方式下协同完成复杂任务。
对于生产部署,Strands 通过 OpenTelemetry 集成提供了企业级的可观测性。这为整个智能体系统提供了分布式跟踪,使得从原型到生产工作负载扩展时,调试问题和监控性能变得非常容易。
使用 Strands 进行智能体编排的基础知识
ReAct 模式是当前大多数 AI 智能体的默认方法。它将规划、工具调用和答案综合集成到单个智能体循环中。虽然这适用于简单任务,但对于复杂场景会产生问题。智能体可能会反复调用工具而没有明确的策略,将证据收集与结论混在一起,或者在未经核实的情况下仓促得出答案。在需要结构化推理、合规性检查或多步验证的应用中,这些问题变得至关重要。这就是编排发挥作用的地方。
Strands 允许创建具有解决问题独特角色的专业智能体,而不是让一个智能体完成所有工作。例如,一个智能体可能规划方法,另一个智能体执行计划,第三个智能体综合结果。用户将这些智能体连接到符合确切要求的受控工作流中。在 Strands 中,编排模式使用图执行模型。可以将其视为流程图,其中:
- 每个节点是一个封装特定逻辑或专业知识的智能体
- 边定义了信息在智能体之间如何流动
- 结构使推理步骤可见且可调试
与 ReAct 中隐藏的决策制定不同,图会暴露每一步。用户可以追踪是哪个智能体产生了什么输出,何时可用,以及下一个智能体如何使用它。这种透明度对于构建可靠的系统至关重要。Strands 为任何编排模式提供了四个基本组件:
- 节点 (Nodes):封装特定逻辑或专业知识的智能体
- 边 (Edges):定义执行顺序和数据流的连接
- AgentResult:每个智能体的标准化输出格式
- GraphResult:包含执行跟踪、时间、输出和所采取路径的完整执行跟踪
GraphBuilder API 允许用户将这些组件连接起来,以定义哪些智能体参与、数据如何在它们之间流动以及用户输入进入系统的位置。在运行时,图确定性地执行并返回结构化结果。
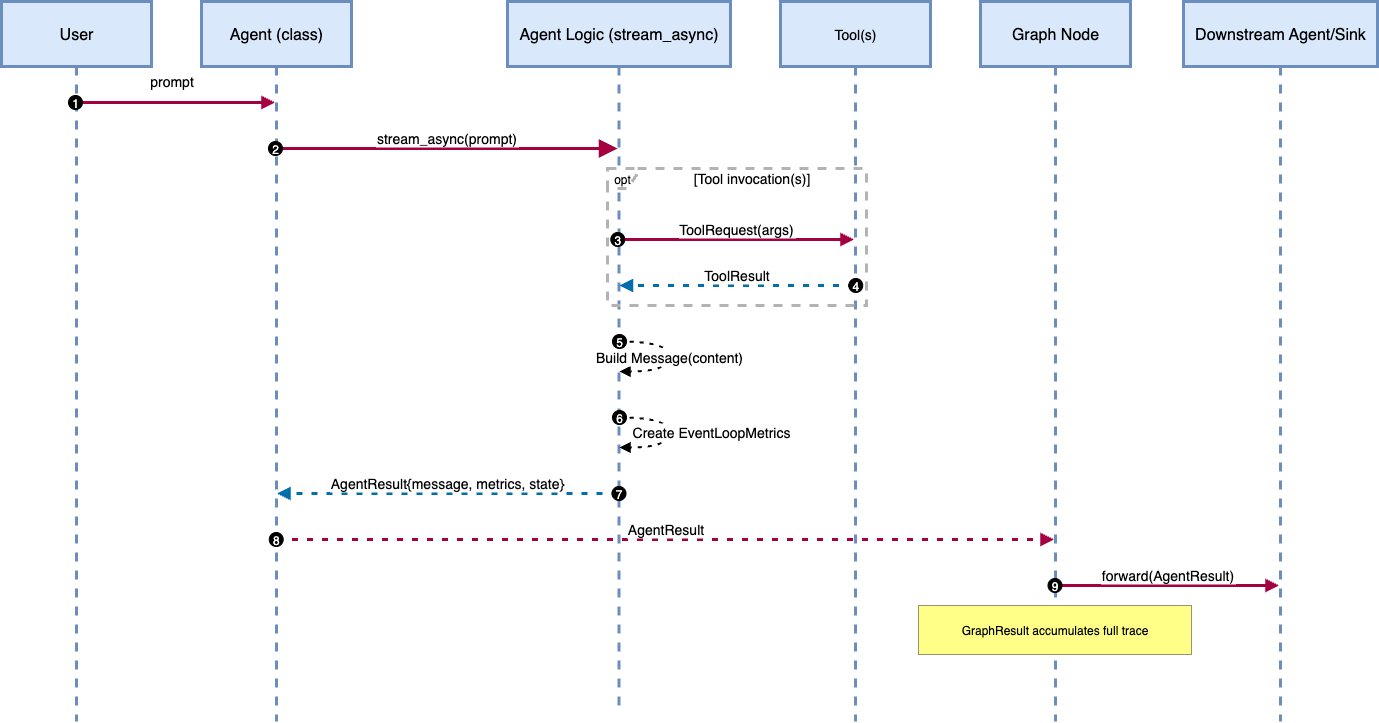
考虑一个文档问答管道:
用户查询 → 检索智能体 → 总结智能体 → 最终答案
builder = GraphBuilder() builder.add_node(retriever, "retriever") builder.add_node(summarizer, "summarizer") builder.add_edge("retriever", "summarizer") builder.set_entry_point("retriever")检索器搜索相关文档。总结器对文档进行浓缩。每个智能体只在需要时才看到所需的数据。流程是明确的、可预测的,并且易于调试。同一种方法可以扩展到复杂的模式。用户可以为不同的推理路径添加分支,为迭代细化添加循环,或为探索多种策略添加并行执行。关键在于对信息如何在系统中流动的控制。
在接下来的部分中,我们将实现我们的第一个模式:ReWOO,它将规划与执行分离,以创建更可靠的智能体工作流。
数据集和默认编排
数据集详情
我们使用 τ-Bench 航空公司领域数据集(Yao 等人,2024 年)评估了我们的系统。该数据集包含 300 多个航班条目、500 个合成用户配置文件、2000 多个预先生成的预订记录、详细的航空公司政策、用于预订操作的模拟 API 以及 50 个结构化的真实世界场景。这个全面的基准测试为评估智能体如何解释政策、执行适当的 API 调用,并在复杂的航空公司操作(包括升级、行程更改和取消)中保持一致性提供了受控而真实的测试平台。虽然原始数据集将每个任务呈现为多轮对话,但为了更好地展示编排模式,我们将其简化为单轮查询。
架构概览:带有 ReAct 的默认编排
ReAct(推理 + 行动)在一个单一的智能体循环中交织了两个阶段。智能体以自然语言进行推理以决定下一步,如果需要则调用工具,观察工具的输出,并继续带着该观察进行推理,直到能够生成最终答案。
在 Strands Agents 中,ReAct 基线清晰地映射到一个拥有 τ-Bench 航空公司工具箱(航班搜索、预订/修改/取消、查找配置文件等工具列表)的单个 Agent。这些工具是 Tau-Bench 数据集中提供的 Python 函数,使用 @tool 装饰器转换为 Strands 工具。
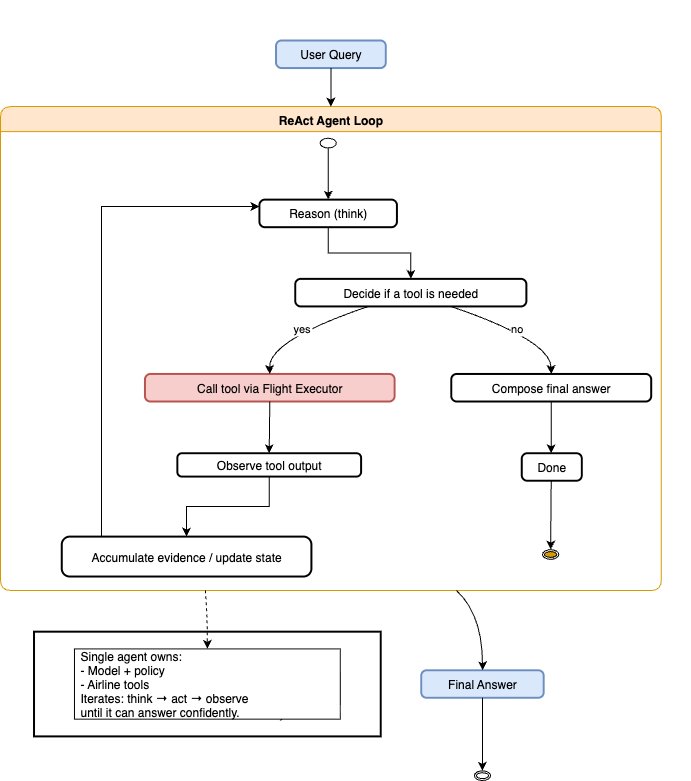
tools = [ book_reservation, calculate, cancel_reservation, get_reservation_details, get_user_details, list_all_airports, search_direct_flight, search_onestop_flight, send_certificate, think, transfer_to_human_agents, update_reservation_baggages, update_reservation_flights, update_reservation_passengers, ] prompt = """ You are a helpful assistant for a travel website. Help the user answer any questions. <instructions> - Remember to check if the the airport city is in the state mentioned by the user. For example, Houston is in Texas. - Infer about the the U.S. state in which the airport city resides. For example, Houston is in Texas. - You should not use made-up or placeholder arguments. <instructions> <policy> {policy} </policy> """ react_agent=Agent(model = model,tools = tools,system_prompt = prompt) react_response = react_agent(user_query)- 没有明确的规划器或评估器;控制“思考 → 行动 → 观察 → 思考……”的策略存在于智能体的提示及其模型的内部循环中。这使得 ReAct 成为工具增强系统的自然基线,因为它只需要最少的编排——一个带有工具箱的单一“工具执行器”智能体——并且它在简单任务中倾向于快速运行。
架构概览:ReWOO(无观察推理)
ReWOO 重新定义了“工具如何被使用”,而不是“哪些工具存在”。我们为所有航空公司 API 保留一个单一的工具执行器,但我们在其周围强制执行规划 → 执行 → 综合的分离。在 Strands 中,这变成了一个小的、明确的图,其中每个节点返回一个类型化的结果 (AgentResult),运行时以确定的方式将这些结果转发给下游节点。这带来了治理、可观测性和可重复性。
- 规划器 (Planner) (仅规划)。 生成严格格式化的计划。
- 工作器 (Worker) (仅执行)。解析计划,解析参数,调用工具,并在规范化的结构中积累证据。将执行与规划解耦,使得工具使用可预测且可强制执行策略(工作器只能运行计划授权的内容)。
- 求解器 (Solver) (仅综合)。读取证据——工具的结果而不是工具本身——然后组成最终答案。它使工具效果和决策制定可审计;避免在最后一步中出现“隐藏的”后续调用。
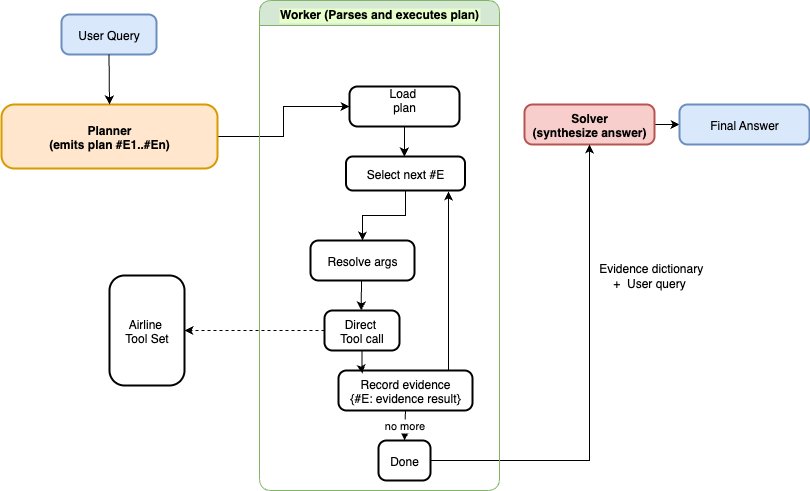
使用 Strands 的 GraphBuilder(节点、边、入口点)构建后,这会形成一个确定性 DAG。运行时将原始任务加上上游节点的输出(捕获在 AgentResult 中)传递给每个下游节点。
from strands.multiagent.graph import GraphBuilder b = GraphBuilder() b.add_node(planner_agent, "planner") b.add_node(worker_agent, "worker") b.add_node(solver_agent, "solver") b.add_edge("planner", "worker") b.add_edge("worker", "solver") b.set_entry_point("planner") graph = b.build()规划器:具有严格语法的纯规划智能体
规划器生成描述工具用法的声明式程序,而不是答案。以下是设计有效规划器提示的重要特征:
- 列出允许的工具名称集及其参数
- 通过少样本示例向 LLM 展示如何规划以回答给定的用户查询。
- 强制输出形状。我们使用了这个:
Plan 1: <short intent> #E1 = <tool_name>[key=value, ...] Plan 2: <short intent> #E2 = <tool_name>[key=value, ...] #E4 = REPEAT(<analysis_or_count>) { <tool_a>[...] <tool_b>[...] }计划作为 AgentResult 返回。严格的计划是可审计的,并最大限度地减少了歧义。它还支持在任何内容运行之前进行静态检查(例如,“只允许使用这些工具;每步一个”).
针对用户查询创建的计划示例:
“我的用户 ID 是 mia_li_3668。我想在 5 月 20 日从纽约飞往西雅图(单程)。我不想在美国东部时间上午 11 点之前飞行。我想乘坐经济舱。我更喜欢直飞,但单程也可以。如果有多个选项,我更喜欢价格最低的那个。我有 3 个行李。我不需要保险。我想使用我的两个凭证支付。如果只能使用一张凭证,我更喜欢使用较大的一张,然后用我的 7447 卡支付剩余的费用。”
DEBUG: PLANNER AGENT CALLED Plan 1: Get user details to check available certificates #E1 = get_user_details[user_id="mia_li_3668"] Plan 2: Get list of airports to find the airport codes for New York and Seattle #E2 = list_all_airports[] Plan 3: Search for direct flights using airport codes from #E2 and date from given user question #E3 = search_direct_flight[origin="JFK", destination="SEA", date="2024-05-20"] Plan 4: If no suitable direct flights after 11am, search for one-stop flights #E4 = search_onestop_flight[origin="JFK", destination="SEA", date="2024-05-20"] Plan 5: Think about the flight selection, pricing, and payment options #E5 = think["Analyze the flight options from #E3 and #E4: - Filter flights departing after 11am EST - Select cheapest suitable flight (direct preferred) - Calculate baggage fees (3 bags total) - Determine payment strategy using certificates from user profile - Plan to use the largest certificate first - Prepare to use 7447 card for remaining balance"] Plan 6: Book the reservation with all the collected information #E6 = book_reservation[user_id="mia_li_3668", origin="JFK", destination="SEA", flight_type="one_way", cabin="economy", flights=[selected_flight_from_E3_or_E4], payment_methods=[largest_certificate, remaining_certificate_or_card_7447], total_baggages=3, nonfree_baggages=calculated_from_E5, insurance=false]工作器:具有参数和循环解析的确定性执行器
工作器只执行计划授权的操作;参数解析是数据驱动的。这使得行为在不同运行和模型版本中都具有可重现性。工作器将计划视为可执行规范。
- 统一计划解析器:它解析常规步骤和
REPEAT块,按证据 ID 排序,并按顺序执行它们。
- 证据分类账:每一步都会产生一个结构化的记录(
#E{id}带有描述 + 结果)。错误作为证据捕获,而不是静默失败。
step_evidence[f’#E{eid}’] = { 'evidence_id': f'#E{eid}', 'description': f"Execute {tool} with {kwargs or 'no parameters'}", 'results': result_text<br /> } all_evidence.update(step_evidence)- 上下文感知动态参数解析:根据(a)原始任务和(b)前 N 个证据构建上下文。从该上下文中填充占位符(例如,机场代码、预订 ID)——而不是对原始字符串进行脆弱的正则表达式匹配。这可以通过几种不同的方式完成。一种方法是使用 LLM 从构建的上下文中推断参数值。第二种方法是使用正则表达式匹配来解析参数值。
- 带有特殊情况的动态工具调度:使用
getattr直接调用工具。
执行步骤示例:
DEBUG: Processing step #E3 DEBUG: Tool name: search_direct_flight DEBUG: Calling search_direct_flight with kwargs: { 'origin': 'JFK', 'destination': 'SEA', 'date': '2024-05-20' } DEBUG: Tool result: { 'toolUseId': 'tooluse_search_direct_flight_716684779', 'status': 'success', 'content': [ { 'text': '{"flights": [ { "flight_number": "HAT069", "origin": "JFK", "destination": "SEA", "scheduled_departure_time_est": "06:00:00", "scheduled_arrival_time_est": "12:00:00", "status": "available", "available_seats": { "basic_economy": 17, "economy": 12, "business": 3 }, "prices": { "basic_economy": 51, "economy": 121, "business": 239 }, "date": "2024-05-20" }, { "flight_number": "HAT083", "origin": "JFK", "destination": "SEA", "scheduled_departure_time_est": "01:00:00", "scheduled_arrival_time_est": "07:00:00", "status": "available", "available_seats": { "basic_economy": 16, "economy": 7, "business": 3 }, "prices": { "basic_economy": 87, "economy": 100, "business": 276 }, "date": "2024-05-20" } ]}' } ] }求解器:构建最终答案并呈现给用户
求解器将来自工作器的执行证据与原始用户查询相结合,以生成最终响应。它接收结构化的证据字典,并将其综合成自然语言答案。求解器从不调用工具。它执行以下操作:
- 证据解析——读取原始任务和工作器的证据(来自工作器智能体节点)。
- 计划重建——将证据规范化为一个紧凑的、有序的“计划 + 证据”文本块。
- 最终答案生成——使用具有适当提示的 LLM 来生成最终答案,明确解决约束和权衡。
solve_prompt = """Solve the following task or problem. To solve the problem, we have made step-by-step Plan and retrieved corresponding Evidence to each Plan. Use them with caution since long evidence might contain irrelevant information. {plan} Now solve the question or task according to provided Evidence above. Respond with the answer directly with no extra words. Task: {task} Response:"""将综合与执行分离可以产生清晰的决策日志和稳定的延迟。它还使得在不接触规划/执行逻辑的情况下轻松更换综合提示或模型变得容易。
架构概览:Reflexion(自我批判)
Reflexion 是一种编排模式,其中智能体生成一个候选答案及其对该答案的批判,然后使用该批判在一个有限的循环中修改答案。目标不是盲目地“重试”,而是根据明确的、机器可解析的反馈(例如,违反的约束、缺失的检查、薄弱的推理)来针对性地修改。换句话说,Reflexion 将模型反馈转化为控制信号,该信号控制一个或多个附加的传递周期,一旦答案满足既定标准就停止。这种方法的动机是它能带来更高的答案质量。Reflexion 图使用 GraphBuilder 构建了 2 个节点。
- 草稿 (Draft) (仅规划)。 生成初始答案和初始反思。
- 修订器 (Revisor) (仅执行)。在改进查询、修订和反思答案之间循环。
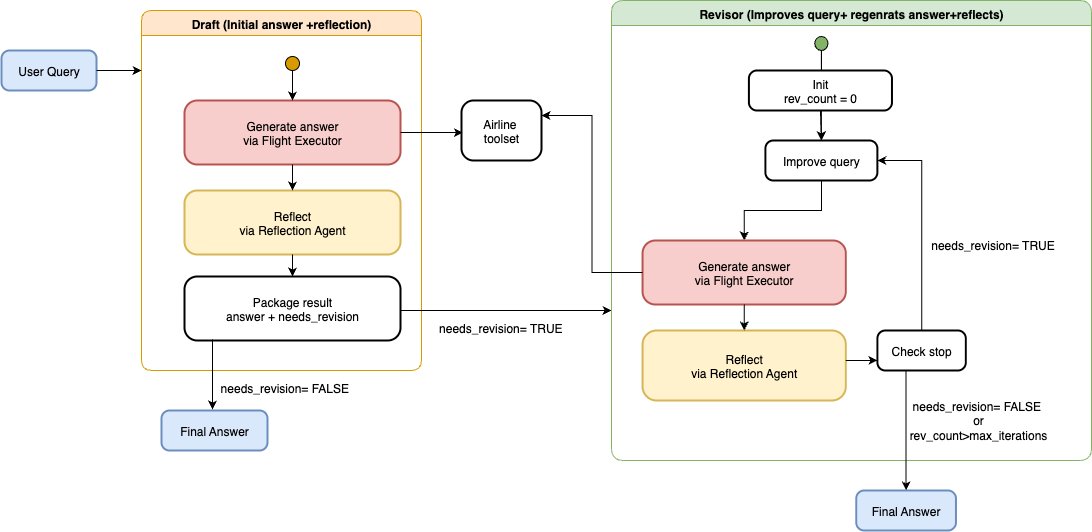
尽管编排被建模为 DAG,但修订器节点封装了多达三个修订周期,根据需要调用工具。每个节点返回一个 AgentResult;运行时将上游结果转发给下游节点,并将完整的跟踪记录在 GraphResult 中。
草稿:生成初始答案和批判
草稿节点使用与其他模式相同的航空公司工具执行器来生成初始答案。紧接着,它运行一个集中的“反思”阶段,通过使用带有反思提示的 LLM 来标记差距(违反的约束、缺失的检查、薄弱的推理),并输出一个紧凑的、标记的有效载荷,供修订器确定性地解析:
reflection_system_prompt="""You are analyzing a flight assistant's response that uses real flight database tools. IMPORTANT: The flight data comes from real database queries, NOT hallucination. Analyze the response quality on these dimensi... [内容被截断]🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区