



📢 转载信息
原文作者:Danielle Robinson, Florian Saupe, George Novack, Haipeng Li, Mani Kumar Adari, Xiang Song, and Yu Gong
组织和个人在运行多个定制AI模型(尤其是最近的专家混合模型(MoE))时,可能会面临一个挑战:当单个模型的流量不足以使专用计算端点饱和时,仍需为闲置的GPU容量付费。为了解决这个问题,我们与vLLM社区合作,开发了一种高效的解决方案,用于流行的开源MoE模型(如GPT-OSS或Qwen)的多低秩适配(Multi-LoRA)服务。Multi-LoRA是微调模型的一种流行方法。它不是重新训练整个模型权重,而是保持原始权重冻结,并将小的、可训练的适配器注入到模型的层中。通过Multi-LoRA,在推理时,多个定制模型共享同一个GPU,每个请求只交换进出相应的适配器。例如,五个客户每个只使用10%的专用GPU,现在可以通过一个GPU使用Multi-LoRA来服务,从而将五个利用率不足的GPU整合成一个高效共享的GPU。
在本文中,我们将解释如何在vLLM中为MoE模型实现Multi-LoRA推理,描述我们进行的内核级优化,并向您展示如何从这项工作中受益。在整篇文章中,我们以GPT-OSS 20B作为主要示例。
您现在可以在本地vLLM部署中使用vLLM 0.15.0或更高版本来利用这些改进。Multi-LoRA服务现在适用于MoE模型家族,包括GPT-OSS、Qwen3-MoE、DeepSeek和Llama MoE。我们的优化还有助于提高密集模型的Multi-LoRA托管性能,例如Llama3.3 70B或Qwen3 32B。特定于Amazon的优化在vLLM 0.15.0的基础上带来了额外的延迟改进,例如,对于GPT-OSS 20B,输出令牌每秒(OTPS)提高了19%(即模型生成输出的速度),首次令牌时间(TTFT)降低了8%(即等待模型开始生成输出所需的时间)。要利用这些优化,请在Amazon SageMaker AI或Amazon Bedrock上托管您的LoRA定制模型。
在vLLM中为MoE模型实现Multi-LoRA推理
在深入探讨我们在vLLM中对MoE模型的Multi-LoRA推理的初步实现之前,我们想提供一些关于MoE模型和LoRA微调的背景信息,这对理解我们优化的基本原理很重要。MoE模型包含多个称为“专家”(experts)的专业化神经网络。一个路由器将每个输入令牌引导至最相关的专家,然后聚合这些专家的输出。这种稀疏架构使用更少的计算资源来处理更大的模型,因为每个令牌激活的模型总参数中只有一小部分,如下图1所示。
每个专家是一个处理令牌隐藏状态的小型前馈网络,分为两个阶段。首先,gate_up投影将紧凑的隐藏状态(例如,4096维)扩展到一个更大的中间空间(例如,11008维)。这种扩展是必要的,因为紧凑空间中的特征是紧密纠缠的——更大的空间为网络提供了分离、转换它们并选择性地门控哪些特征重要的空间。其次,down投影将结果压缩回原始维度。这有助于保持输出与模型的其余部分兼容,并充当瓶颈,迫使网络只保留最有用的特征。总而言之,这种“先扩展后压缩”的模式使每个专家都能应用丰富的转换,同时保持一致的输出大小。vLLM使用fused_moe内核将这些投影执行为组通用矩阵乘法(Group GEMM)操作——每个分配给给定令牌的专家执行一次GEMM。Multi-LoRA微调会使基础模型权重W(例如,gate_up投影的W_gate_up)保持冻结,并训练两个小矩阵A和B,它们共同构成一个适配器。对于具有基准权重W(形状为h_in × h_out)的投影,LoRA训练A(形状为h_in × r)和B(形状为r × h_out),其中r是LoRA秩(通常为16-64)。微调后的输出变为y = xW + xAB。每个LoRA适配器在投影中添加两个操作。收缩操作计算z=xA,将输入从h_in维度减少到r维度。扩展操作通过与B相乘,将该r维结果投射回h_out维度。这在图1的右侧有所说明。
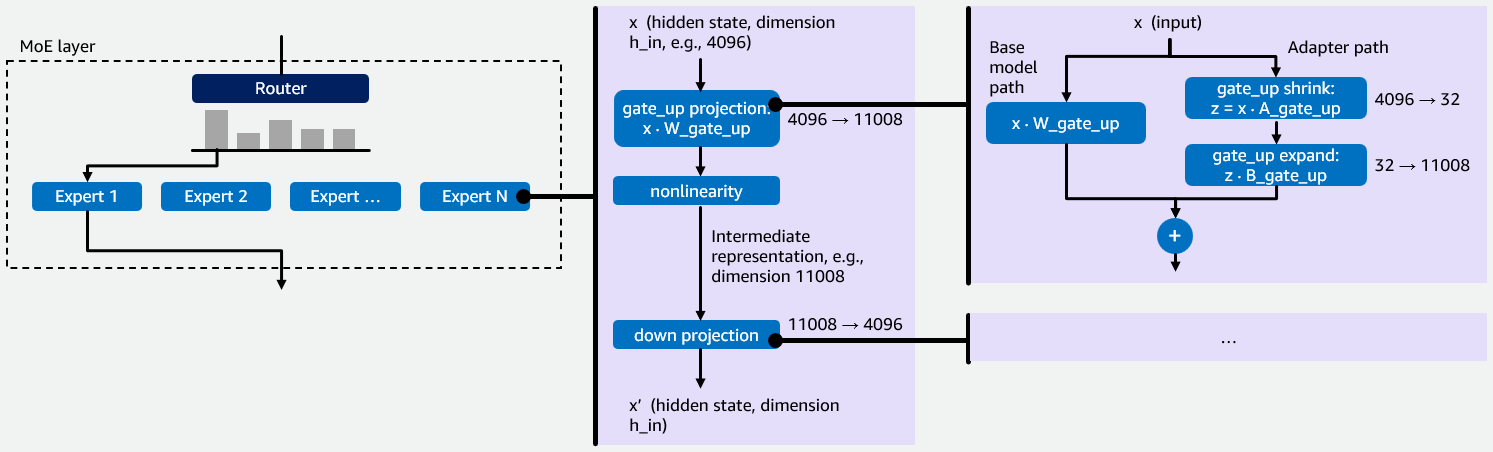
图1:MoE-LoRA模型工作原理的说明,其中隐藏状态维度为4096,中间表示维度为11008,LoRA秩r = 32。
每个专家有两个权重投影:gate_up和down。当应用LoRA适配器时,它向每个投影添加两个低秩操作,即收缩和扩展。这意味着每个专家总共需要四个LoRA内核操作:gate_up的收缩和扩展,以及down的收缩和扩展。在Multi-LoRA服务设置中,多个LoRA适配器同时为不同的用户或任务提供服务时,系统必须有效地管理每个请求的每个专家、每个适配器的这四个操作。这使得它成为MoE模型的关键性能瓶颈。这四个操作涉及矩阵,其中一个维度(LoRA秩r)比另一个维度(例如,隐藏状态和中间表示维度)小100-300倍。标准的GEMM内核专为大致为正方形的矩阵设计,在细长矩阵上的性能不佳,这就是稍后在本文中描述内核优化所必需的原因。除了必须针对细长矩阵进行优化之外,为MoE模型添加Multi-LoRA支持还带来了两个技术挑战。首先,vLLM缺少对MoE层执行LoRA的内核,因为现有的密集Multi-LoRA内核不处理专家路由。其次,MoE LoRA结合了两种稀疏性来源:专家路由(令牌分配给不同的专家)和适配器选择(请求使用不同的LoRA适配器)。这种复合稀疏性需要专门的内核设计。为了解决这些挑战,我们创建了一个fused_moe_lora内核,它将LoRA操作集成到fused_moe内核中。这个新内核为gate_up和down投影执行LoRA收缩和扩展GEMM。fused_moe_lora内核遵循与fused_moe内核相同的逻辑,并为相应的激活LoRA适配器向网格添加一个额外的维度。
将此实现合并到vLLM中后,我们可以在H200 GPU上使用GPT-OSS 20B运行Multi-LoRA服务,在Sonnet数据集(基于诗歌的基准测试)上,输入长度为1600、输出长度为600、并发度为16的情况下,达到26 OTPS和1053 ms TTFT。要重现这些结果,请查看vLLM GitHub存储库中0.11.1.rc3版本的PR。在博客的其余部分,我们将展示如何从这些基线启用数字中优化性能。
改进vLLM中的Multi-LoRA推理性能
在完成初步实现后,我们使用NVIDIA Nsight Systems (Nsys)来识别瓶颈,发现fused_moe_lora内核是延迟最高的组件。然后,我们使用NVIDIA Nsight Compute (NCU)分析四个内核操作的计算和内存吞吐量:gate_up_shrink、gate_up_expand、down_shrink和down_expand。这些发现促使我们为这四个内核开发了执行优化、内核级优化和调整后的配置。
执行优化
在我们的初始实现中,Multi-LoRA TTFT比基础模型TTFT(即GPT-OSS 20B的公开版本)高出10倍(更差)。我们的分析显示,Triton编译器将依赖于输入长度的变量视为编译时常量,导致fused_moe_lora内核在每次新上下文长度时都从头开始重新编译,而不是被重用。这在图2中可见:每次fused_moe_lora内核执行之前的cuModuleLoadData调用表明GPU正在加载新编译的内核二进制文件而不是重用缓存的,内核开始时间之间的巨大间隔显示GPU在重新编译期间处于空闲状态。这种开销导致TTFT相对于基础模型回归了10倍。
我们通过为这些变量添加do_not_specialize编译器提示来解决此问题,指示Triton只编译内核一次,并在所有上下文长度中重用它。
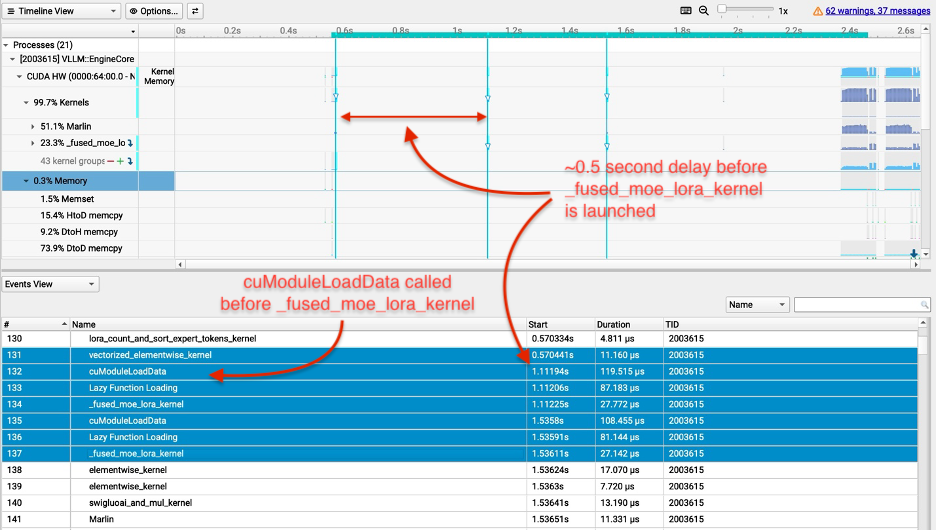
图2:执行优化前fused_moe_lora内核的分析结果。
分析还显示,无论请求是仅使用基础模型、仅使用注意力适配器(仅在注意力层上有权重的LoRA适配器),还是使用完整的LoRA适配器(在注意力和MoE层上都有权重的适配器),我们的fused_moe_lora内核启动的开销都很高。为了帮助解决这个问题,我们添加了早期退出逻辑,在没有LoRA适配器的层上跳过fused_moe_lora内核,以防止不必要的内核执行。
收缩和扩展内核是串行运行的,这在我们的早期实现中在两次内核执行之间产生了“气泡”。为了重叠内核执行,我们实现了程序化依赖启动(PDL)。通过PDL,依赖的内核可以在主内核完成之前开始启动,这允许扩展内核在收缩内核运行时预取权重到共享内存和L2缓存中。当收缩内核完成时,扩展内核已经加载了其权重,可以立即开始计算。
我们还为LoRA添加了对投机性解码的支持,修复了vLLM中一个将基础模型和适配器捕获不同CudaGraphs的问题。CudaGraphs对于效率很重要,因为它们用于捕获GPU操作序列,以帮助减少GPU内核开销,例如,将内核作为一个单元。因此,CudaGraphs可以减少CPU开销和这些内核启动延迟。通过我们的执行优化,在使用默认配置的GPT-OSS 20B上,OTPS提高到50/100(无/有投机性解码),TTFT提高到150 ms。在博客的其余部分,我们报告开启投机性解码的数字。
内核优化
Split-K是一种工作分解策略,有助于改善细长矩阵的负载平衡。LoRA收缩计算xA,其中x的维度为1×h_in,A的维度为h_in×r。r个输出元素中的每一个都需要对h_in个乘法求和。标准的GEMM内核将不同的线程组(共享快速片上内存的GPU线程批次)分配给不同的输出元素,但每个线程组顺序地计算其h_in求和。由于r在数十个级别,而h_in在数千个级别,因此用于并行化的输出元素很少,而每个输出元素都需要较长的顺序求和。Split-K通过将GEMM的内部维度K(在此示例中为K=h_in)上的求和跨多个线程组进行分割来解决此问题,这些线程组并行计算部分和,然后组合它们的结果。这些部分结果需要一个原子加法才能产生最终的和。由于我们执行纯原子加法而没有额外的逻辑,我们通过为原子加法操作设置参数sem="relaxed"来利用Triton编译器的优化自由度。
GPU调度器将多个线程组分配给同一个输出元素,并同时运行不同输出元素的线程组。对于lora_shrink,每个输出元素需要读取A的一列,该列跨越h_in行。由于h_in在数千个级别,每一列都会接触跨越大内存区域的缓存行。相邻的列共享相同的行并在缓存中重叠,因此处理相邻列的线程组可以受益于彼此加载数据的重用。协同线程阵列(CTA)扭曲重新排序调度,使得处理相邻列的线程组同时运行,从而增加L2缓存重用。我们将CTA扭曲应用于lora_shrink操作。
我们还从收缩和扩展LoRA内核中移除了不必要的掩码和点积操作。Triton内核以固定大小的块加载数据,但矩阵维度可能无法被这些块大小整除。例如,如果BLOCK_SIZE_K为64,但矩阵维度K为100,则第二个块将尝试读取28个无效内存位置。掩码通过检查每个索引是否在边界内来防止这些非法内存访问,然后再加载。然而,这些条件检查在每次加载操作上都会执行,即使元素有效也会增加开销。我们引入了一个EVEN_K参数,用于检查K是否能被BLOCK_SIZE_K整除。如果为真,则加载有效,可以完全跳过掩码,有助于减少掩码开销和不必要的点积计算。
最后,我们将LoRA权重的加法与基础模型权重融合到LoRA扩展内核中。此优化有助于减少内核启动开销。这些内核优化使我们达到了GPT-OSS 20B的144 OTPS和135 ms TTFT。
为Amazon SageMaker AI和Amazon Bedrock调整内核配置
Triton内核需要调整参数,如块大小(BLOCK_SIZE_M、BLOCK_SIZE_N、BLOCK_SIZE_K),这些参数控制矩阵计算如何在线程组之间划分。高级参数包括GROUP_SIZE_M,它控制用于缓存局部性的线程组排序,以及SPLIT_K,它并行化内部矩阵维度上的求和。
我们发现,使用针对标准融合MoE优化的默认配置的MoE LoRA内核在Multi-LoRA服务中的性能不佳。这些默认设置没有考虑到对应于LoRA索引的额外网格维度以及来自多个适配器的复合稀疏性。为了解决这个瓶颈,我们添加了对用户通过提供文件夹路径加载自定义调整配置的支持。有关更多信息,请参阅vLLM LoRA调优文档。我们同时调整了四个fused_moe_lora操作(gate_up收缩、gate_up扩展、down收缩、down扩展),因为它们共享相同的BLOCK_SIZE_M参数。Amazon SageMaker AI和Bedrock客户现在可以使用这些调整后的配置,它们会自动加载,并为GPT-OSS 20B实现171 OTPS和124 ms TTFT。
结果与结论
通过我们与vLLM社区的合作,我们为MoE模型(包括GPT-OSS、Qwen3 MoE、DeepSeek和Llama MoE)实现并开源了Multi-LoRA服务。然后,我们应用了优化,例如,在vLLM 0.15.0与vLLM 0.11.1rc3相比时,GPT-OSS 20B的OTPS提高了454%,TTFT降低了87%。一些优化,特别是内核调优和CTA扭曲,也提高了密集模型的性能,例如,Qwen3 32B OTPS提高了99%。要在本地部署中利用这项工作,请使用vLLM 0.15.0或更高版本。Amazon Bedrock和Amazon SageMaker AI中提供的特定于Amazon的优化有助于在模型中提供额外的延迟改进,例如,与vLLM 0.15.0相比,GPT-OSS 20B的OTPS快19%,TTFT好8%。要开始在Amazon上进行定制模型托管,请参阅Amazon SageMaker AI托管和Amazon Bedrock文档。
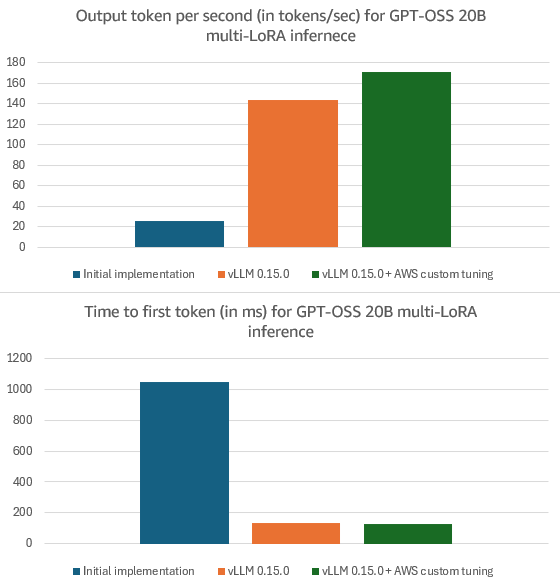
图3:GPT-OSS 20B Multi-LoRA推理的每秒输出令牌(OTPS)和首次令牌时间(TTFT):1/ vLLM 0.11.1rc3中的初始实现;2/ 使用vLLM 0.15.0;3/ 使用vLLM 0.15.0和AWS自定义内核调优。实验使用了1600个输入令牌和600个输出令牌,LoRA秩为32,8个适配器并行加载。
致谢
我们要感谢vLLM社区的贡献者和合作者:Jee Li、Chen Wu、Varun Sundar Rabindranath、Simon Mo和Robert Shaw,以及我们的团队成员:Xin Yang、Sadaf Fardeen、Ashish Khetan和George Karypis。
作者简介
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区