



📢 转载信息
原文链接:https://www.kdnuggets.com/hosting-language-models-on-a-budget
原文作者:Nate Rosidi

Image by Editor
简介
ChatGPT、Claude、Gemini。您都知道它们的名字。但这里有一个问题:如果您运行自己的模型会怎么样呢?这听起来似乎很宏大。但事实并非如此。您可以在不到10分钟的时间内,不花一分钱部署一个可运行的大型语言模型(LLM)。
本文将为您详细解析。首先,我们将弄清楚您真正需要什么。然后,我们将研究实际成本。最后,我们将在Hugging Face上免费部署TinyLlama。
在启动模型之前,您的脑海中可能充满了许多问题。例如,我期望我的模型执行哪些任务?
让我们尝试回答这个问题。如果您需要一个服务于50个用户的机器人,您就不需要GPT-5。或者,如果您计划每天对1200多条推文进行情感分析,您可能不需要一个拥有500亿参数的模型。
我们首先来看一些流行的用例以及可以执行这些任务的模型。

如您所见,我们将模型与任务进行了匹配。这是您在开始之前应该做的事情。
分解托管LLM的实际成本
现在您知道了自己的需求,我将向您展示成本是多少。托管模型不仅仅是关于模型本身;还包括模型运行的位置、运行频率以及有多少人与之交互。让我们来解密实际的成本。
// 计算:您将面临的最大成本
如果您在亚马逊网络服务(AWS)EC2上7天24小时运行一台中央处理器(CPU),每月费用约为36美元。但是,如果您运行一台图形处理器(GPU)实例,每月费用约为380美元——是CPU成本的10倍以上。因此,在计算大型语言模型的成本时要小心,因为这是主要开支。
(计算是近似值;要查看实际价格,请在此处查看:AWS EC2 定价)。
// 存储:除非模型非常庞大,否则成本很低
我们大致计算一下磁盘空间。一个7B(70亿参数)模型大约需要14吉字节(GB)。云存储费用约为每月每GB 0.023美元。因此,一个1GB模型和一个14GB模型之间的差异大约是每月0.30美元。如果您不打算托管300B参数模型,存储成本可以忽略不计。
// 带宽:扩大规模前成本很低
当数据移动时,带宽就很重要,当其他人使用您的模型时,您的数据就会移动。AWS在第一个GB之后按每GB 0.09美元收费,因此您只需花费几分钱。但是,如果您扩展到数百万次请求,您也应该仔细计算这一点。
(计算是近似值;要查看实际价格,请在此处查看:AWS 数据传输定价)。
// 您今天可以使用的免费托管选项
Hugging Face Spaces允许您使用CPU免费托管小型模型。Render和Railway提供适用于低流量演示的免费套餐。如果您正在进行实验或构建概念验证,可以不花一分钱就走得很远。
选择一个您真正能运行的模型
现在我们知道了成本,但您应该运行哪个模型呢?当然,每个模型都有其优点和缺点。例如,如果您将一个1000亿参数的模型下载到您的笔记本电脑上,我保证除非您拥有顶级的、专门构建的工作站,否则它将无法运行。
让我们看看Hugging Face上可用的不同模型,以便您可以在下一节中免费运行它们。
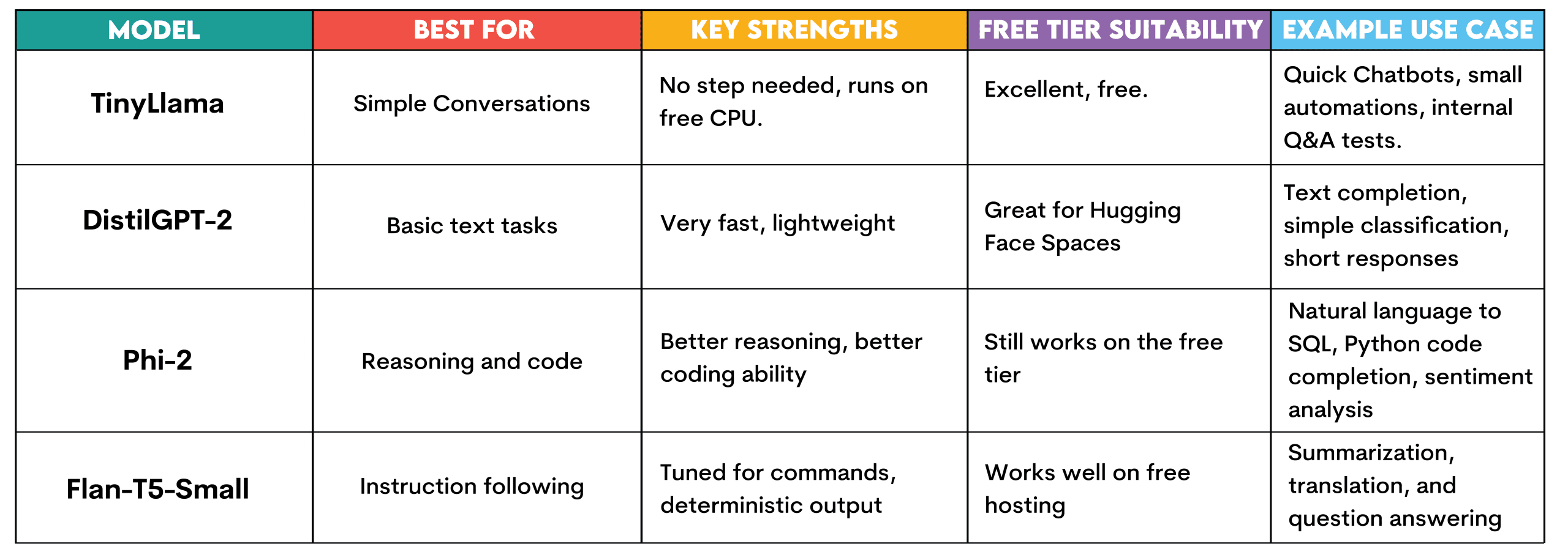
TinyLlama:此模型无需任何设置,即可在Hugging Face的免费CPU层上运行。它专为简单的对话任务、回答简单问题和文本生成而设计。
它可以用于快速构建和测试聊天机器人、运行快速自动化实验,或在扩展到基础设施投资之前,为测试构建内部问答系统。
DistilGPT-2:它也快速且轻量级。这使其非常适合Hugging Face Spaces。适用于文本补全、非常简单的分类任务或简短回复。适用于在没有资源限制的情况下理解LLM的工作原理。
Phi-2:微软开发的一个小型但非常有效的模型。它仍然可以在Hugging Face的免费层上运行,但提供了改进的推理和代码生成能力。可用于自然语言到SQL查询生成、简单的Python代码补全或客户评论情感分析。
Flan-T5-Small:这是来自谷歌的指令微调模型。旨在响应命令并提供答案。适用于需要确定性输出(如摘要、翻译或问答)的生成场景,且可在免费托管上运行。
在5分钟内部署TinyLlama
让我们使用Hugging Face Spaces免费构建和部署TinyLlama。无需信用卡、无需AWS账户、无需Docker难题。只需一个可以分享链接的可用聊天机器人。
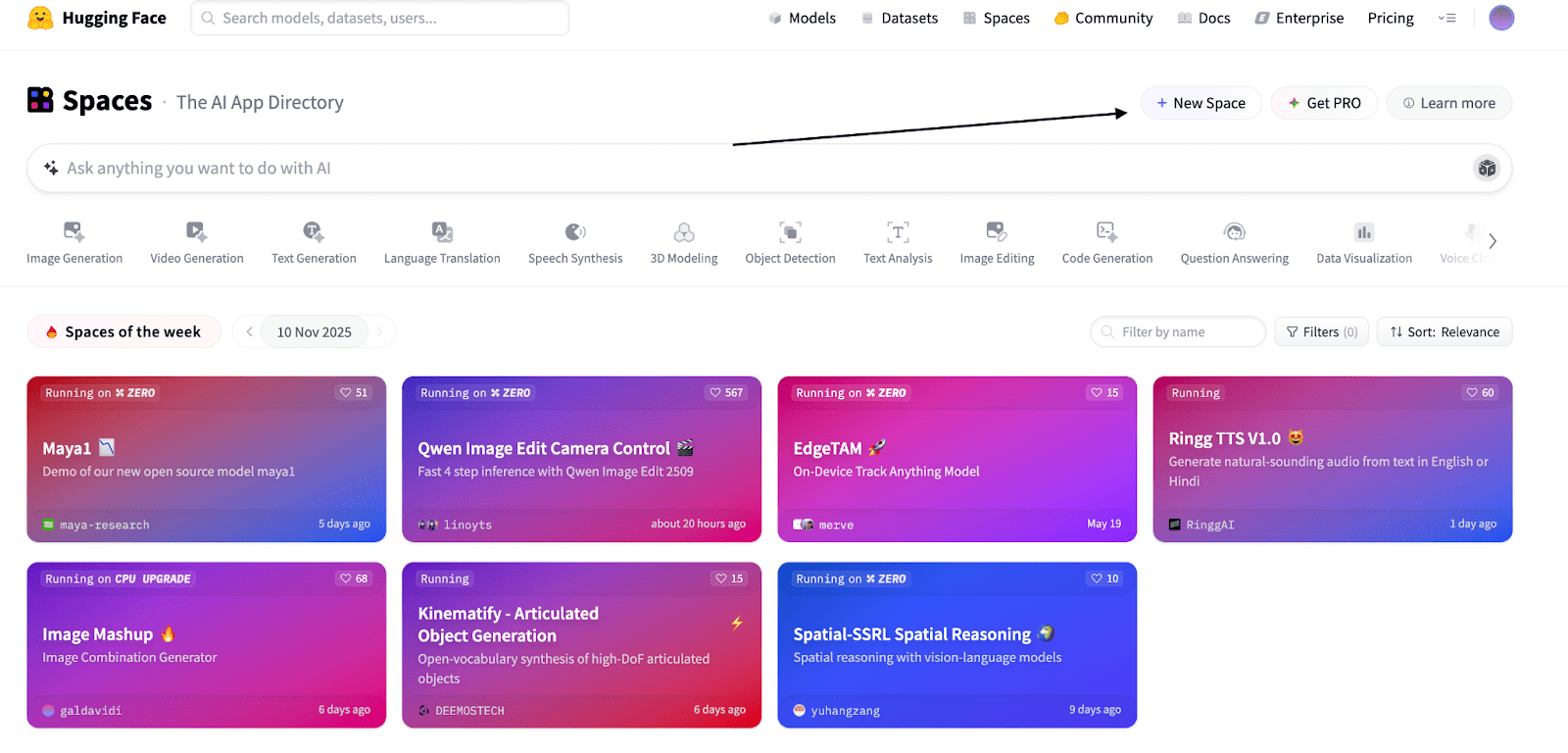
// 步骤1:前往Hugging Face Spaces
访问huggingface.co/spaces,然后点击“New Space”,如下面的截图所示。
将空间命名为您想要的任何名称,并添加简短描述。
您可以保持其他设置不变。
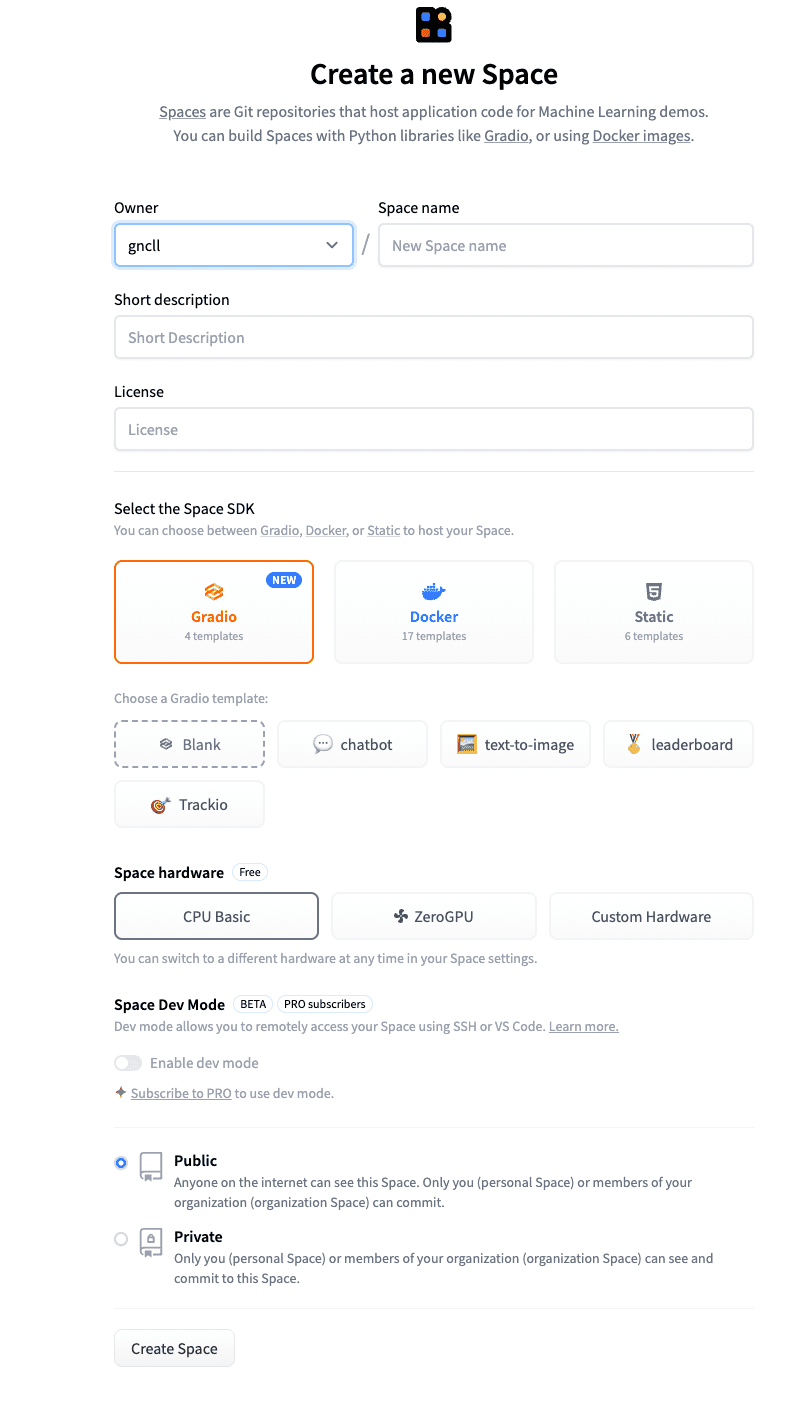
点击“Create Space”。
// 步骤2:编写app.py
现在,从下面的屏幕点击“create the app.py”。
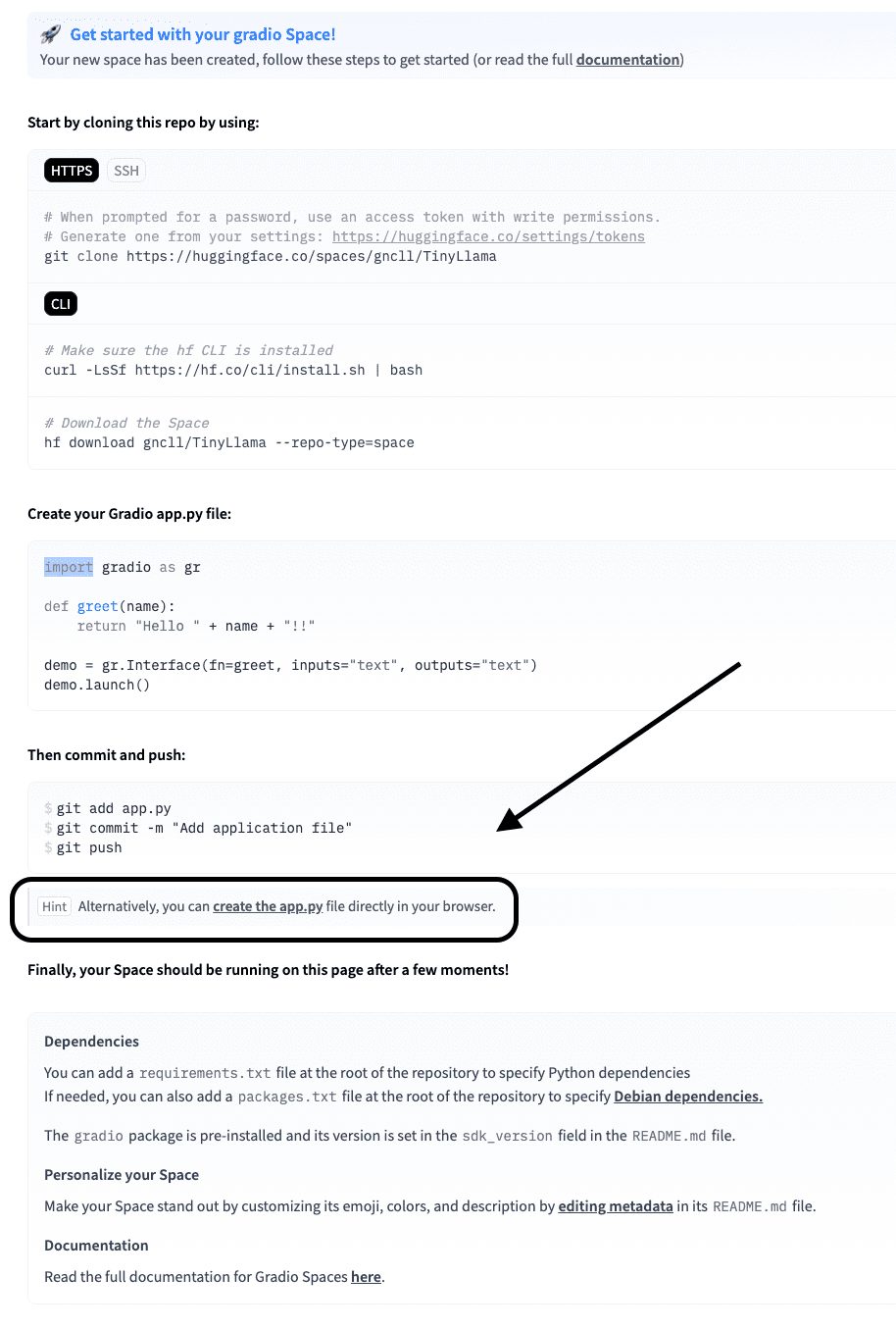
将下面的代码粘贴到此app.py中。
此代码加载TinyLlama(Hugging Face上有可用的构建文件),将其封装到聊天函数中,并使用Gradio创建一个Web界面。chat()方法会正确格式化您的消息,生成回复(最多100个token),并且只返回模型对您所提问题的回复(不包含重复内容)。
此处是您可以了解如何为任何Hugging Face模型编写代码的页面。
让我们看看代码。
import gradio as gr
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
def chat(message, history):
# Prepare the prompt in Chat format
prompt = f"<|user|>\n{message}\n<|assistant|>\n"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(
**inputs,
max_new_tokens=100,
temperature=0.7,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[0][inputs['input_ids'].shape[1]:], skip_special_tokens=True)
return response
demo = gr.ChatInterface(chat)
demo.launch()
粘贴代码后,点击“Commit the new file to main”。请参考下面的截图作为示例。
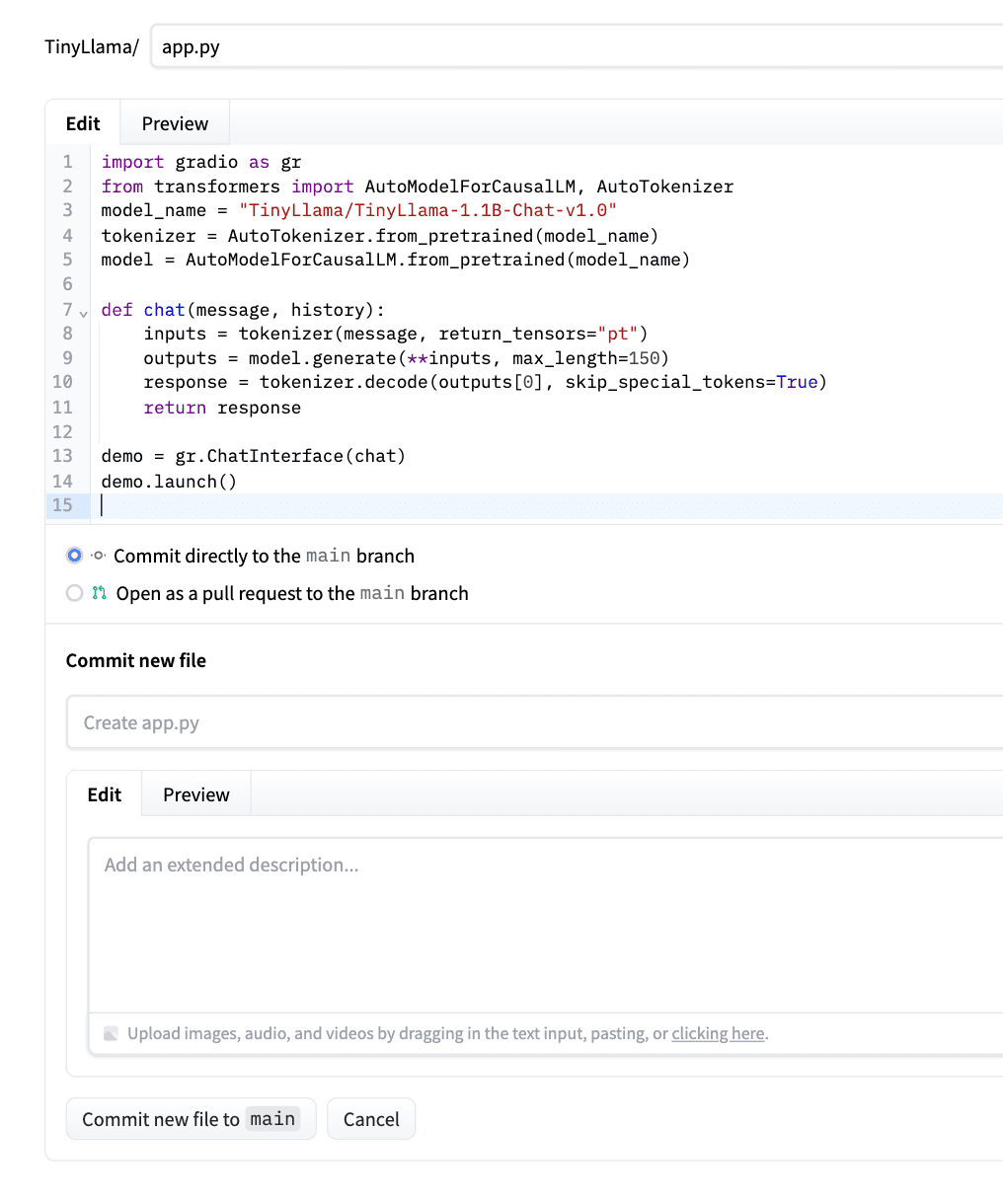
Hugging Face将自动检测它,安装依赖项,并部署您的应用。

在此期间,请创建一个requirements.txt文件,否则您将收到如下错误。

// 步骤3:创建Requirements.txt
点击屏幕右上角的“Files”。

在这里,点击“Create a new file”,如下面的截图所示。

将文件命名为“requirements.txt”,并添加3个Python库,如以下截图所示(transformers、torch、gradio)。
Transformers用于加载模型和处理分词。Torch运行模型,因为它提供了神经网络引擎。Gradio创建了一个简单的Web界面,供用户与模型进行聊天。

// 步骤4:运行并测试已部署的模型
当您看到绿灯“Running”时,表示您已完成。

现在让我们测试一下。
您可以通过点击此处出现的App首先进行测试。

让我们用它来编写一个Python脚本,该脚本使用Z-Score和四分位距(IQR)检测逗号分隔值(CSV)文件中的异常值。
以下是测试结果;
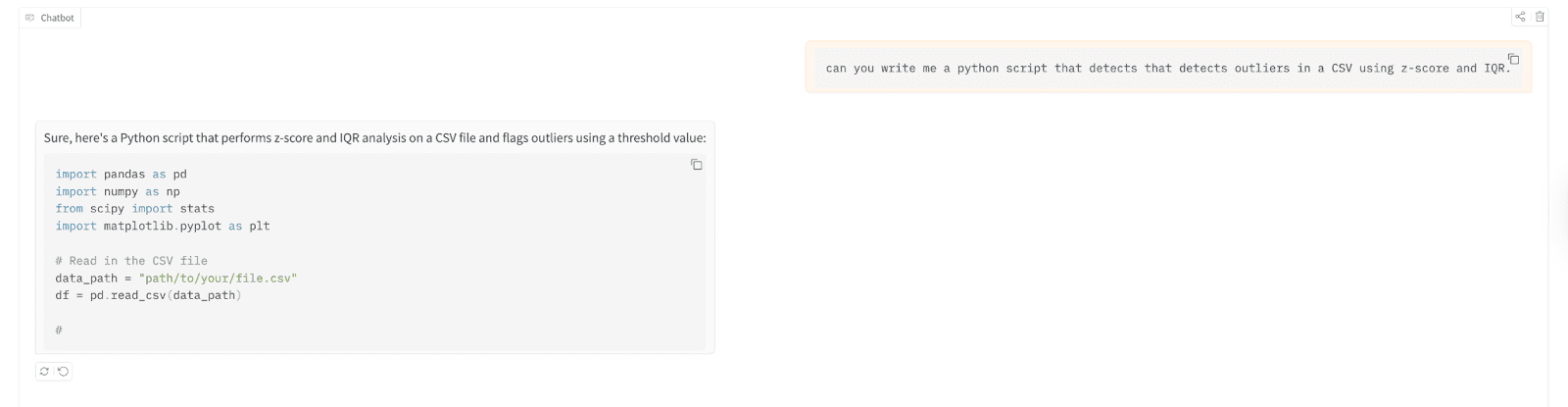
// 了解您构建的部署
结果是,您现在可以启动一个1B+参数的语言模型,而无需接触终端、设置服务器或花费一分钱。Hugging Face负责托管、计算和(在一定程度上)扩展。付费层可用于更多的流量。但就实验目的而言,这是理想的选择。
学习的最佳方式是:先部署,后优化。
接下来的步骤:改进和扩展您的模型
现在您有了一个可用的聊天机器人。但TinyLlama只是开始。如果您需要更好的响应,请尝试使用相同的过程升级到Phi-2或Mistral 7B。只需更改app.py中的模型名称,并增加一点计算能力即可。
为了获得更快的响应,可以研究量化。您还可以将模型连接到数据库,为对话添加记忆,或使用自己的数据对其进行微调,因此唯一的限制就是您的想象力。
Nate Rosidi 是一位数据科学家和产品战略师。他还是教授分析学的一名兼职教授,并且是StrataScratch的创始人。StrataScratch是一个帮助数据科学家用来自顶级公司的真实面试问题来准备面试的平台。Nate撰写有关职业市场最新趋势、提供面试建议、分享数据科学项目,并涵盖SQL的所有内容。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区