



📢 转载信息
原文链接:https://www.kdnuggets.com/the-kdnuggets-comfyui-crash-course
原文作者:Shittu Olumide

Image by Author
ComfyUI 改变了创作者和开发者处理AI图像生成的方式。与传统界面不同,ComfyUI的节点式架构为您提供了对创意工作流程前所未有的控制。本速成课程将带您从一个完全的初学者成长为一名自信的用户,涵盖您掌握这一强大工具所需的所有基本概念、功能和实用示例。

Image by Author
ComfyUI是一个免费的、开源的、基于节点的界面,也是 Stable Diffusion 和其他生成模型的后端。您可以将其视为一个视觉编程环境,您在其中连接“节点”(构建块),以创建用于生成图像、视频、3D模型和音频的复杂工作流程。
与传统界面的主要优势:
- 您无需编写代码即可完全控制视觉构建工作流程,并完全控制每个参数。
- 您可以保存、共享和重用整个工作流程,元数据嵌入在生成的.png文件中。
- 没有隐藏的费用或订阅;它完全可以通过自定义节点进行定制,免费且开源。
- 它在本地机器上运行,可实现更快的迭代和更低的操作成本。
- 它具有扩展功能,通过自定义节点,几乎是无限的,可以满足您的特定需求。
# 选择本地安装还是云端安装
在更详细地探讨ComfyUI之前,您必须决定是运行本地版本还是使用云端版本。
| 本地安装 | 云端安装 |
|---|---|
| 安装后可离线工作 | 需要持续的互联网连接 |
| 无订阅费用 | 可能涉及订阅成本 |
| 完整的数据隐私和控制权 | 对您的数据控制权较少 |
| 需要强大的硬件(特别是良好的 NVIDIA GPU) | 不需要强大的硬件 |
| 需要手动安装和更新 | 自动更新 |
| 受限于您计算机的处理能力 | 高峰时段可能出现速度限制 |
如果您刚开始接触,建议先从云端解决方案开始,以学习界面和概念。随着您技能的发展,可以考虑过渡到本地安装,以获得更大的控制权和更低的长期成本。
# 理解核心架构
在操作节点之前,理解ComfyUI运行的理论基础至关重要。将其视为两个宇宙之间的多重宇宙:我们看到的红、绿、蓝(RGB)宇宙,以及计算发生的潜在空间(Latent Space)宇宙。
// 两个宇宙
RGB宇宙是我们可观测的世界。它包含我们可以用肉眼看到和理解的常规图像和数据。潜在空间(AI宇宙)是“魔术”发生的地方。它是模型可以理解和操作的数学表示。它混乱、充满了噪声,并包含驱动图像生成的抽象数学结构。
// 使用变分自编码器(VAE)
变分自编码器(VAE)充当这两个宇宙之间的门户。
- 编码(RGB — 潜在):将可见图像转换为抽象的潜在表示。
- 解码(潜在 — RGB):将抽象的潜在表示转换回我们可以看到的图像。
这个概念很重要,因为许多节点在一个宇宙内操作,理解这一点将帮助您正确地连接节点。
// 定义节点
节点是ComfyUI的基本构建块。每个节点是一个执行特定任务的自包含函数。节点具有:
- 输入(左侧):数据流入的地方
- 输出(右侧):处理过的数据流出的地方
- 参数:您调整以控制节点行为的设置
// 识别颜色编码的数据类型
ComfyUI使用颜色系统来指示数据在节点之间流动的类型:
| 颜色 | 数据类型 | 示例 |
|---|---|---|
| 蓝色 | RGB图像 | 常规可见图像 |
| 粉色 | 潜在图像 | 潜在表示中的图像 |
| 黄色 | CLIP | 转换为机器语言的文本 |
| 红色 | VAE | 在不同宇宙之间转换的模型 |
| 橙色 | 条件(Conditioning) | 提示词和控制指令 |
| 绿色 | 文本 | 简单的文本字符串(提示词、文件路径) |
| 紫色 | 模型 | 检查点和模型权重 |
| 青色/蓝绿色 | ControlNets | 用于指导生成的控制数据 |
理解这些颜色非常重要。它们会立即告诉您哪些节点可以相互连接。
// 探索重要的节点类型
Loader 节点将模型和数据导入工作流程:
CheckPointLoader:加载一个模型(通常在一个文件中捆绑了模型权重、对比语言-图像预训练(CLIP)和VAE)。Load Diffusion Model:单独加载模型组件(适用于像 Flux 这样不捆绑组件的新模型)。VAE Loader:单独加载VAE解码器。CLIP Loader:单独加载文本编码器。
Processing 节点转换数据:
CLIP Text Encode将文本提示转换为机器语言(条件信息)。KSampler是核心的图像生成引擎。VAE Decode将潜在图像转换回RGB。
Utility 节点支持工作流程管理:
- Primitive Node: 允许您手动输入值。
- Reroute Node: 通过重定向连接来清理工作流程的可视化效果。
- Load Image: 将图像导入工作流程。
- Save Image: 导出生成的图像。
# 理解KSampler节点
KSampler 可以说是ComfyUI中最重要的节点。它是实际生成图像的“机器人构建器”。了解其参数对于创建高质量图像至关重要。
// 回顾KSampler参数
Seed(种子)(默认值:0)
种子是确定在生成开始时放置哪个随机像素的初始随机状态。可以将其视为随机化的起点。
- 固定种子:使用相同的种子和相同的设置将始终产生相同的图像。
- 随机化种子:每次生成都会获得一个新的随机种子,产生不同的图像。
- 值范围:0 到 18,446,744,073,709,551,615。
Steps(步数)(默认值:20)
步数定义了执行的去噪迭代次数。每一步都会逐步优化图像,使其从纯噪声向所需的输出演进。
- 低步数(10-15):生成速度快,结果精细度较低。
- 中等步数(20-30):质量和速度的良好平衡。
- 高步数(50+):质量更好,但速度明显变慢。
CFG Scale(CFG 尺度)(默认值:8.0,范围:0.0-100.0)
分类器无关指导(CFG)尺度控制AI遵循提示词的严格程度。
类比 — 想象一下给建筑工人一份蓝图:
- 低CFG(3-5):建筑工人看一眼蓝图就去做自己的事情 — 很有创意,但可能忽略指示。
- 高CFG(12+):建筑工人一丝不苟地遵循蓝图的每一个细节 — 准确但可能看起来呆板或过度处理。
- 平衡CFG(Stable Diffusion为7-8,Flux为1-2):建筑工人主要遵循蓝图,同时增加自然的变体。
Sampler Name(采样器名称)
采样器是用于去噪过程的算法。常见的采样器包括Euler、DPM++ 2M和UniPC。
Scheduler(调度器)
控制在去噪步数中噪声如何被安排。调度器决定了降噪曲线。
- Normal(标准): 标准的噪声调度。
- Karras: 通常在较低的步数下提供更好的结果。
Denoise(去噪)(默认值:1.0,范围:0.0-1.0)
这是您对图像到图像工作流程最重要的控制之一。去噪决定了输入图像中要被新内容替换的百分比:
- 0.0:不进行任何更改 — 输出将与输入完全相同
- 0.5:保留原始图像的50%,重新生成新的50%
- 1.0:完全重新生成 — 忽略输入图像,从纯噪声开始
# 示例:生成角色肖像
提示词:“一个赛博朋克机器人,霓虹蓝色的眼睛,精细的机械部件,戏剧性的光照。”
设置:
- 模型:Flux
- 步数:20
- CFG:2.0
- 采样器:默认
- 分辨率:1024x1024
- 种子:随机化
负面提示词:“低质量,模糊,过度饱和,不真实。”
// 探索图像到图像工作流程
图像到图像工作流程建立在文本到图像的基础上,添加一个输入图像来指导生成过程。
场景:您有一张风景照片,想将其制作成油画风格。
- 加载您的风景图像
- 正面提示词:“oil painting, impressionist style, vibrant colors, brush strokes”(油画,印象派风格,鲜艳的色彩,笔触)
- 去噪:0.7
// 进行姿势引导的角色生成
场景:您生成了一个很棒的角色,但想要一个不同的姿势。
- 加载您的原始角色图像
- 正面提示词:“Same character description, standing pose, arms at side”(相同的角色描述,站姿,双臂垂下)
- 去噪:0.3
# 安装和设置ComfyUI
云端安装(初学者最简单)
访问 RunComfy.com,然后点击右上角的“启动Comfy Cloud”。或者,您也可以直接在浏览器中 注册。
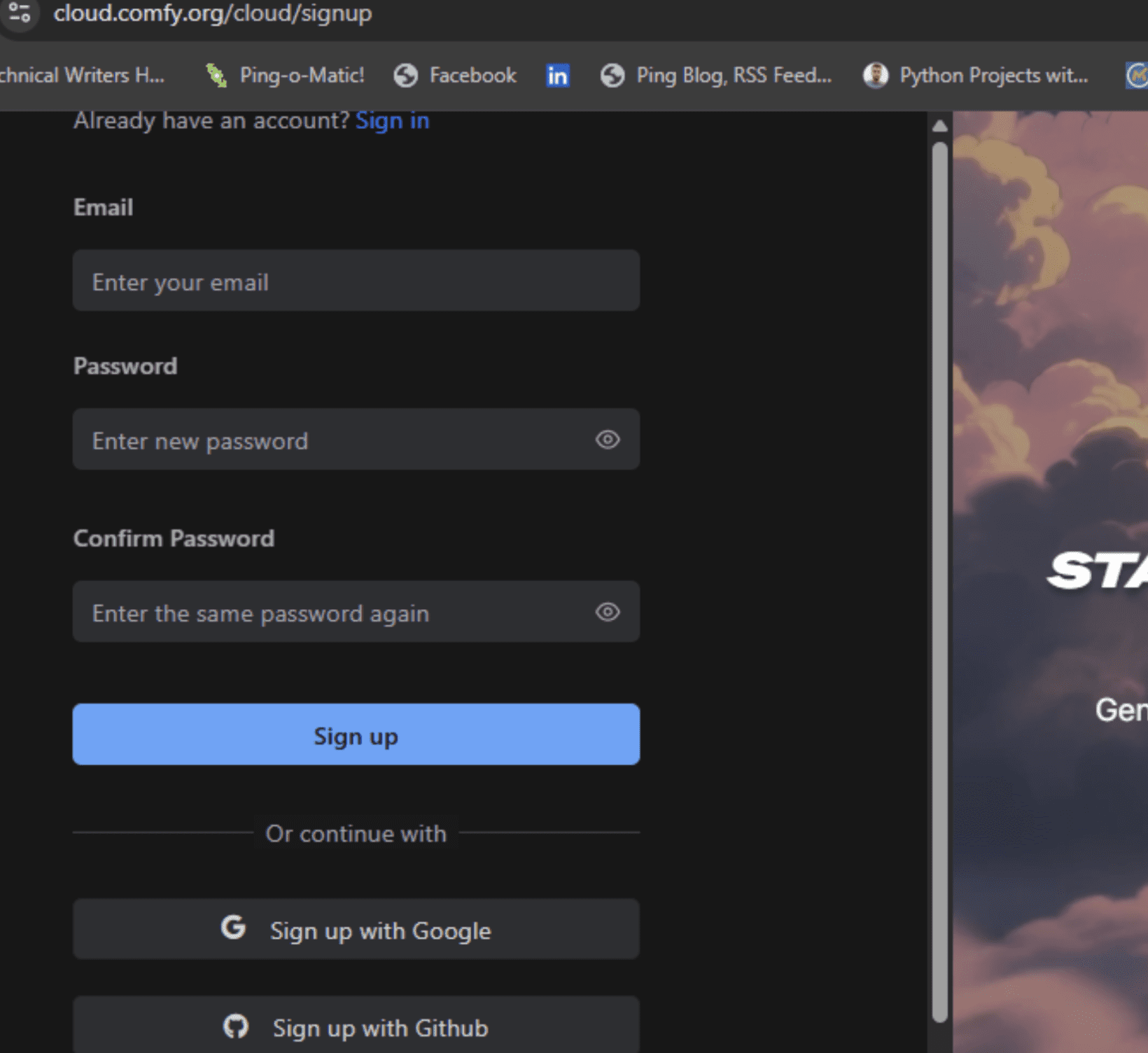
Image by Author
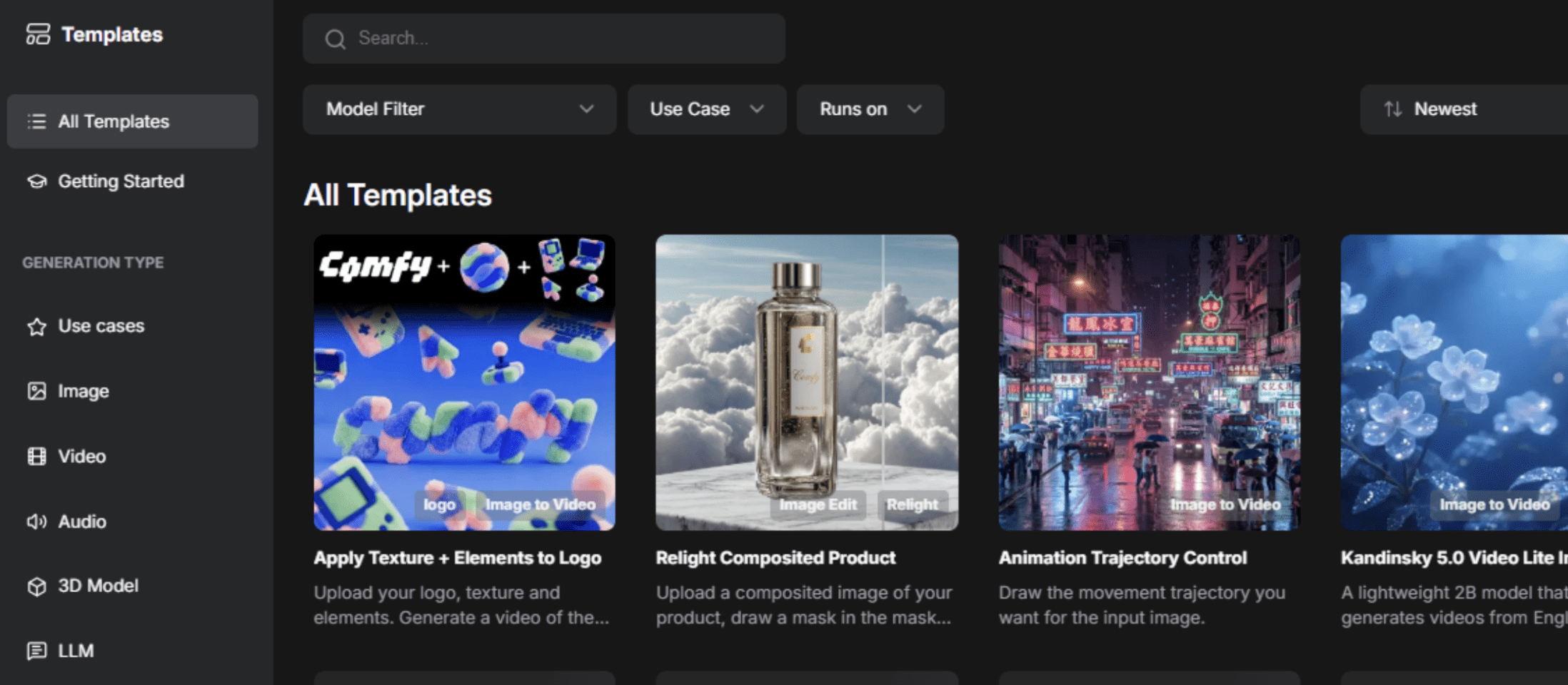
Image by Author
// 使用Windows便携版
- 在下载之前,您必须拥有包含支持CUDA的NVIDIA GPU的硬件设置,或macOS(Apple Silicon)。
- 从ComfyUI GitHub发布页面下载便携式Windows版本。
- 解压到您希望的位置。
- 运行
run_nvidia_gpu.bat(如果您有NVIDIA GPU)或run_cpu.bat。 - 在浏览器中打开 http://localhost:8188。
// 执行手动安装
- 安装 Python:下载 3.12 或 3.13 版本。
- 克隆仓库:
git clone https://github.com/comfyanonymous/ComfyUI.git - 安装 PyTorch:根据您的GPU遵循特定于平台的说明。
- 安装依赖项:
pip install -r requirements.txt - 添加模型:将模型检查点放在
models/checkpoints目录中。 - 运行:
python main.py
# 使用不同的AI模型
ComfyUI支持众多最先进的模型。以下是当前的顶级模型:
| Flux(写实推荐) | Stable Diffusion 3.5 | 旧模型(SD 1.5, SDXL) |
|---|---|---|
| 非常适合照片级写实图像 | 质量和速度的良好平衡 | 社区经过广泛微调 |
| 快速生成 | 支持多种风格 | 对于特定工作流程仍然很棒 |
| CFG:1-3 范围 | CFG:4-7 范围 | 庞大的低秩适应(LoRA)生态系统 |
# 使用低秩适应(LoRA)推进工作流程
低秩适应(LoRA)是用于微调模型以实现特定风格、主题或美学的较小适配器文件,无需修改基础模型。常见用途包括角色一致性、艺术风格和自定义概念。要使用LoRA,请添加一个“Load LoRA”节点,选择文件,然后将其连接到您的工作流程中。
// 使用ControlNet指导图像生成
ControlNets为生成提供了空间控制,强制模型尊重姿势、边缘图或深度信息:
- 从参考图像强制执行特定姿势
- 在改变风格的同时保持物体结构
- 基于边缘图指导构图
- 尊重深度信息
// 使用Inpainting进行选择性图像编辑
Inpainting(图像重绘)允许您只重新生成图像的特定区域,同时保持其余部分不变。
工作流程:加载图像 — 蒙版绘制 — Inpainting KSampler — 结果
// 使用升级(Upscaling)提高分辨率
生成后使用升级节点来提高分辨率,而无需重新生成整个图像。流行的升级器包括 RealESRGAN 和 SwinIR。
# 结论
ComfyUI代表了内容创作中一个非常重要的转变。其节点式架构赋予了用户以前仅限于软件工程师的能力,同时对初学者也保持了可访问性。学习曲线确实存在,但您学习的每一个概念都开启了新的创造可能性。
从小处开始,创建一个简单的文本到图像工作流程,生成一些图像,并调整参数。几周之内,您将能够创建复杂的工作流程。几个月之内,您将推动生成领域的可能性边界。
Shittu Olumide 是一位软件工程师和技术撰稿人,热衷于利用尖端技术来构建引人入胜的叙事,对细节有独到的见解,并擅长简化复杂概念。您也可以在 Twitter 上找到 Shittu。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区