



📢 转载信息
原文作者:Yoyo Chan
大型语言模型(LLMs)即使在接收到相同的提示词时,也能产生多样化、富有创造性、有时甚至令人惊讶的输出。这种随机性并非缺陷,而是模型从概率分布中采样下一个词元的核心特性。在本文中,我们将分解关键的采样策略,并演示温度(temperature)、Top-k 和 Top-p 等参数如何影响输出的一致性与创造性之间的平衡。
在本教程中,我们将通过实践方式来理解:
- Logits如何转化为概率
- 温度(temperature)、Top-k 和 Top-p 采样的工作原理
- 不同的采样策略如何塑造模型的下一个词元分布
读完之后,您将理解LLM推理背后的机制,并能根据需要调整输出的创造性或确定性。
让我们开始吧。

How LLMs Choose Their Words: A Practical Walk-Through of Logits, Softmax and Sampling
Photo by Colton Duke. Some rights reserved.
概述
本文分为四个部分:
- Logits如何转化为概率
- 温度(Temperature)
- Top-k 采样
- Top-p 采样
Logits如何转化为概率
当您向LLM提问时,它会输出一个Logits向量。Logits是模型为其词汇表中每个可能的下一个词元分配的原始分数。
如果模型的词汇表包含 $V$ 个词元,它将为每个下一个词位置输出一个包含 $V$ 个Logits的向量。Logit是一个实数。它通过 softmax 函数转换为概率:
$$
p_i = \frac{e^{x_i}}{\sum_{j=1}^{V} e^{x_j}}
$$
其中 $x_i$ 是词元 $i$ 的Logit,$p_i$ 是相应的概率。Softmax将这些原始分数转换为一个概率分布。所有的 $p_i$ 都大于零,并且它们的总和为 1。
假设我们给模型提供以下提示:
Today’s weather is so ___
模型会考虑词汇表中每个词元作为下一个可能的词。为简化说明,假设词汇表中只有 6 个词元:
模型为每个词元产生一个Logit。这是一个模型可能输出的Logit示例,以及基于Softmax函数的相应概率:
| 词元 (Token) | Logit | 概率 (Probability) |
|---|---|---|
| wonderful | 1.2 | 0.0457 |
| cloudy | 2.0 | 0.1017 |
| nice | 3.5 | 0.4556 |
| hot | 3.0 | 0.2764 |
| gloomy | 1.8 | 0.0832 |
| delicious | 1.0 | 0.0374 |
您可以使用PyTorch中的Softmax函数来验证这一点:
根据此结果,概率最高的词元是“nice”。LLM并不总是选择概率最高的词元;相反,它们会从概率分布中采样以产生每次不同的输出。在上述情况下,“nice”出现的概率为46%。
如果您希望模型给出更具创造性的答案,如何更改概率分布,使“cloudy”、“hot”和其他答案出现的频率更高呢?
温度(Temperature)
温度($T$)是一个模型推理参数。它不是模型参数,而是生成输出算法的一个参数。它在应用Softmax之前对Logits进行缩放:
$$
p_i = \frac{e^{x_i / T}}{\sum_{j=1}^{V} e^{x_j / T}}
$$
当 $T<1$ 时,您可以预期概率分布会更具确定性,因为每个 $x_i$ 值之间的差异会被夸大。另一方面,如果 $T>1$,分布会更随机,因为每个 $x_i$ 值之间的差异会被减小。
现在,让我们可视化温度对概率分布的影响:
此代码生成词汇表中每个词元的概率分布,然后根据概率对词元进行采样。运行此代码可能产生以下输出:
以及显示每个温度下概率分布的以下图表:
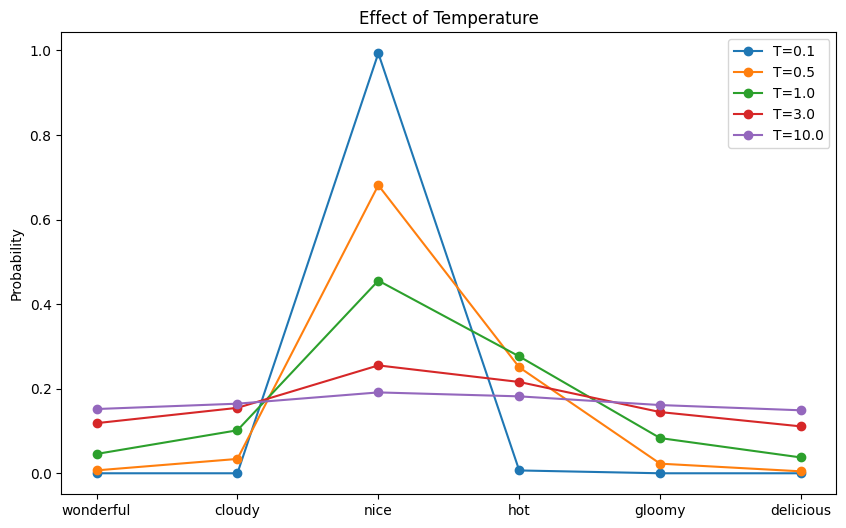
The effect of temperature to the resulting probability distribution
如果将温度设置为 10,模型可能会产生“Today’s weather is so delicious”这样不合逻辑的输出!
Top-k 采样
模型的输出是输出序列中每个位置的Logits向量。推理算法将Logits转换为实际的词语,或用LLM术语来说,就是词元。
选择下一个词元的最简单方法是贪婪采样(greedy sampling),它总是选择概率最高的词元。虽然高效,但这通常会导致重复且可预测的输出。另一种方法是从Logits推导出的Softmax概率分布中采样词元。然而,由于LLM的词汇量非常大,推理速度会变慢,并且有很小的几率产生无意义的词元。
Top-k 采样在确定性和创造性之间取得了平衡。它不从整个词汇表中采样,而是将候选池限制在概率最高的 $k$ 个词元中,并从中进行采样。位于此 Top-$k$ 组之外的词元被赋予零概率,永远不会被选中。它不仅通过减小有效词汇量来加快推理速度,还消除了不应被选中的词元。
通过过滤掉极不可能的词元,同时仍然允许最合理的词元之间存在随机性,Top-$k$ 采样有助于在不牺牲多样性的情况下保持连贯性。当 $k=1$ 时,Top-$k$ 简化为贪婪采样。
以下是如何实现Top-$k$采样的示例:
此代码修改了前面的示例,将一些词元的Logits填充为 $-\infty$,使这些词元的概率为零。运行此代码可能产生以下输出:
以下图表显示了Top-$k$过滤后的概率分布:
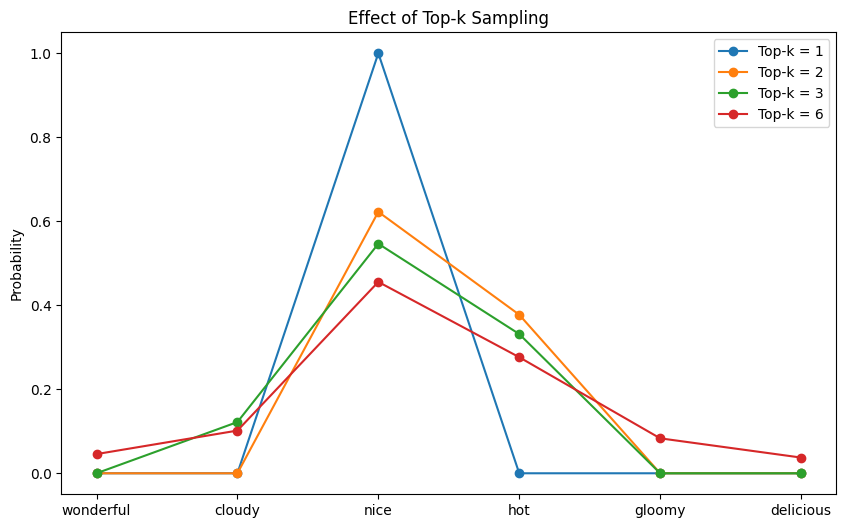
The probability distribution after top-k filtering
您可以看到,对于每个 $k$,恰好有 $V-k$ 个词元的概率为零。在相应的Top-$k$设置下,这些词元永远不会被选中。
Top-p 采样
Top-$k$采样的缺点在于,无论它们集体占了多少概率质量,它总是从固定数量的词元中选择。即使只从概率最高的 $k$ 个词元中采样,也可能允许模型从低概率选项的长尾中选择,这通常会导致输出不连贯。
Top-p 采样(也称为核采样(nucleus sampling))通过根据其累积概率而非固定数量来采样词元来解决这个问题。它选择累积概率超过阈值 $p$ 的最小词元集,有效地为每个位置创建了一个动态的 $k$ 值,以过滤掉不可靠的尾部概率,只保留最合理的结果。当模型尖锐且集中时,Top-$p$产生的候选词元较少;当分布平坦时,它会相应地扩展。
将 $p$ 设置得接近 1.0 会接近从所有词元中完全采样。将 $p$ 设置为一个非常小的值会使采样更加保守。以下是如何实现Top-$p$采样的方法:
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区