



📢 转载信息
原文作者:Chaitanya Hazarey, Caesar Chen, Kunal Ghosh, Ziwen Ning, Piyush Daftary, Pradeep Cruz, Roman Blagovirnyy, Chandra Lohit Reddy Tekulapally, Vivek Gangasani, and Vinay Arora
现代 AI 应用需要快速、经济高效地响应大型语言模型(LLM),尤其是在处理长文档或扩展对话时。然而,随着上下文长度的增加,LLM 推理可能会变得慢得惊人且成本高昂,延迟呈指数级增长,每次交互的成本也会随之攀升。
LLM 推理需要在生成每个新 token 时重新计算先前 token 的注意力机制。这带来了显著的计算开销和高延迟,尤其对于长序列而言。键值(KV)缓存通过存储和重用先前计算的键值向量来解决这一瓶颈,从而减少推理延迟和首个 token 时间(TTFT)。LLM 中的智能路由是一种技术,它将具有共享提示(prompt)的请求发送到相同的推理实例,以最大限度地提高 KV 缓存的效率。它将新请求路由到已经处理过相同前缀的实例,从而可以重用缓存的 KV 数据来加速处理并降低延迟。然而,客户告诉我们,在生产规模下设置和配置用于 KV 缓存和智能路由的合适框架是具有挑战性的,并且需要漫长的实验周期。
今天,我们很高兴地宣布,Amazon SageMaker HyperPod 现在通过 HyperPod 推理运算符(Inference Operator)支持托管分层 KV 缓存和智能路由功能。这些新功能可以通过将 TTFT 降低高达 40%、提高吞吐量以及在使用我们的内部工具处理长上下文提示和多轮聊天对话时,将计算成本降低高达 25%,为 LLM 推理工作负载带来显著的性能提升。这些功能可与 HyperPod 推理运算符一起使用,该运算符会自动管理路由和分布式 KV 缓存基础设施,从而在提供企业级性能的生产 LLM 部署的同时,显著减轻运维开销。通过使用新的托管分层 KV 缓存功能,您可以有效地将注意力缓存卸载到 CPU 内存(L1 缓存),并通过 HyperPod 中的分层存储架构分配 L2 缓存以进行跨实例共享,从而在规模化部署中实现最佳资源利用率和成本效率。
高效的 KV 缓存与智能路由相结合,可以最大限度地提高跨工作节点的缓存命中率,从而在模型部署中实现更高的吞吐量和更低的成本。这些功能对于处理相同上下文或前缀的长文档的应用,或者在需要跨多次交互有效维护先前交换上下文的多轮对话中尤其有益。
例如,分析 200 页合同的法律团队现在可以即时获得后续问题的答案,而不是每查询等待 5 秒以上;医疗保健聊天机器人可以在 20 轮以上的患者对话中保持自然的对话流程;客户服务系统可以以更好的性能和更低的成本处理每日数百万的请求。这些优化使得文档分析、多轮对话和高吞吐量推理应用在企业规模上具有经济可行性。
使用托管分层 KV 缓存和智能路由优化 LLM 推理
让我们来分解一下这些新功能:
- 托管分层 KV 缓存:跨 CPU 内存(L1)和分布式分层存储(L2)自动管理注意力状态,具有可配置的缓存大小和驱逐策略。SageMaker HyperPod 通过新推出的分层存储处理分布式缓存基础设施,减轻了集群跨节点缓存共享的运维开销。KV 缓存条目在整个集群中(L2)可访问,因此一个节点可以从其他节点执行的计算中受益。
- 智能路由:可配置的请求路由,利用前缀感知(prefix-aware)、KV 感知(KV-aware)和轮询(round-robin)等策略来最大化缓存命中率。
- 可观测性:内置 HyperPod 可观测性集成,用于在 Amazon Managed Grafana 中监控托管分层 KV 缓存和智能路由的指标和日志。
带有 KV 缓存和智能路由的推理请求示例流程
当用户向 HyperPod 负载均衡器发送推理请求时,它会将请求转发到 HyperPod 集群内的智能路由器。智能路由器根据路由策略动态地将请求分发到最合适的模型 Pod(实例 A 或实例 B),以最大化 KV 缓存命中率并最小化推理延迟。当请求到达模型 Pod 时,该 Pod 首先检查 L1 缓存(CPU)中常用的键值对,如果需要,然后查询共享的 L2 缓存(托管分层 KV 缓存),最后执行 token 的完整计算。新生成的 KV 对将存储在两个缓存层中,以供将来重用。计算完成后,推理结果会通过智能路由器和负载均衡器流回用户。
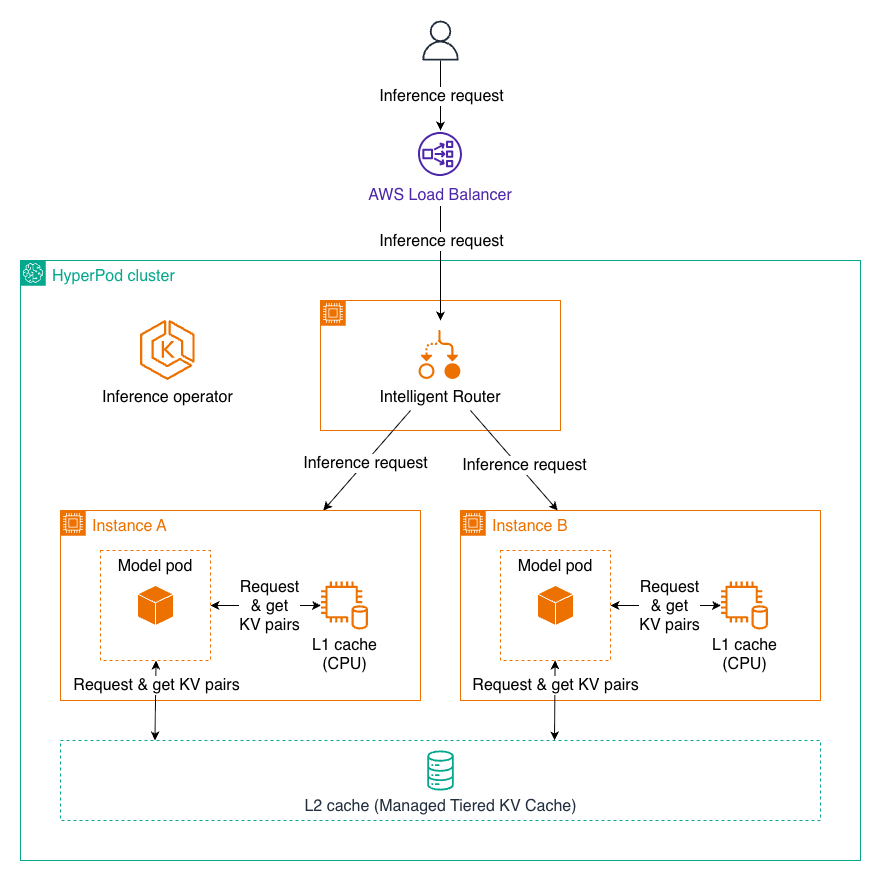
托管分层 KV 缓存
托管分层 KV 缓存和智能路由是可配置的选择加入功能。启用托管 KV 缓存时,默认启用 L1 缓存,而 L1 和 L2 缓存都可以配置为启用或禁用。L1 缓存驻留在每个推理节点上,利用 CPU 内存。这种本地缓存提供了明显更快的访问速度,非常适合单个模型实例中经常访问的数据。缓存会自动管理内存分配和驱逐策略,以优化最有价值的缓存内容。L2 缓存作为一个跨整个集群的分布式缓存层运行,支持跨多个模型实例的缓存共享。我们为 L2 缓存支持两种后端选项,每种都具有以下优势:
- 托管分层 KV 缓存(推荐):一种 HyperPod 分离式内存解决方案,具有出色的可扩展性至 TB 级别、低延迟、AWS 网络优化、支持零拷贝的 GPU 感知设计,以及大规模的成本效益。
- Redis:设置简单,适用于中小型工作负载,并提供丰富的工具和集成环境。
这种两层架构无缝协同工作。当请求到达时,系统首先检查 L1 缓存以获取所需的 KV 对。如果找到,它们将立即使用,延迟最小。如果在 L1 中未找到,系统会查询 L2 缓存。如果在此处找到数据,则检索该数据并可以选择将其提升到 L1 以便将来更快访问。只有当数据不存在于任一缓存中时,系统才会执行完整计算,并将结果存储在 L1 和 L2 中以供将来重用。
智能路由
我们的智能路由系统提供了四种可配置策略,用于根据工作负载特性优化请求分发,并且可以在部署时由用户配置路由策略,以匹配应用程序的特定要求。
- 前缀感知路由:作为默认策略,它维护一个树状结构以跟踪哪些前缀缓存在哪些端点上,为具有常见提示模板的应用(如多轮对话、带有标准问候语的客户服务机器人以及带有常见导入的代码生成)提供强大的通用性能。
- KV 感知路由:通过一个集中式控制器实时跟踪缓存位置并处理驱逐事件,提供最复杂的缓存管理,在长对话线程、文档处理工作流程和关键在于最大化缓存效率的扩展编码会话中表现出色。
- 轮询路由:提供最直接的方法,将请求均匀分布到可用工作节点上,最适合请求相互独立的场景,例如批量推理作业、无状态 API 调用和负载测试场景。
| 策略 | 最适合 |
| 前缀感知路由 (默认) | 多轮对话、客户服务机器人、带有常见头的代码生成 |
| KV 感知路由 | 长对话、文档处理、扩展编码会话 |
| 轮询路由 | 批量推理、无状态 API 调用、负载测试 |
部署托管分层 KV 缓存和智能路由解决方案
先决条件
使用 Amazon EKS 作为编排器创建一个 HyperPod 集群。
- 在 Amazon SageMaker AI 控制台中,导航到 HyperPod 集群,然后是 集群管理。
- 在 集群管理 页面上,选择 创建 HyperPod 集群,然后选择 由 Amazon EKS 编排。

- 您可以使用 SageMaker AI 控制台中的“一键式部署”。有关集群设置详细信息,请参阅使用 Amazon EKS 编排创建 SageMaker HyperPod 集群。
- 验证 HyperPod 集群状态为 InService。

- 验证推理运算符是否正在运行。当您从控制台创建 HyperPod 集群时,推理附加组件(Inference add-on)作为默认选项安装。如果您想使用现有的 EKS 集群,请参阅为模型部署设置 HyperPod 集群以手动安装推理运算符。
从命令行运行以下命令:
kubectl get pods -n hyperpod-inference-system输出:
hyperpod-inference-operator-conroller-manager-xxxxxx pod is in running state in namespace hyperpod-inference-system
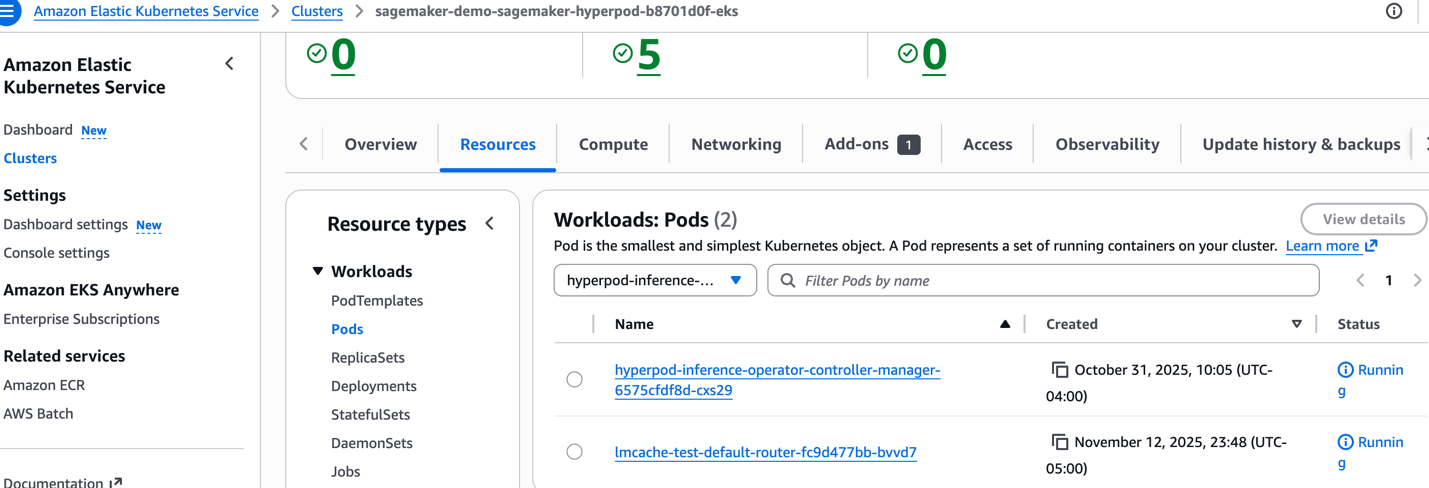
或者,从控制台中验证运算符是否正在运行。导航到 EKS 集群、资源、Pod、选择命名空间、hyperpod-inference-system。
准备模型部署清单文件
您可以通过向 InferenceEndpointConfig 自定义 CRD 文件添加配置来启用这些功能。
有关完整示例,请访问 AWS 示例 GitHub 存储库。
export MODEL_NAME="Llama-3.1-8B-Instruct" export INSTANCE_TYPE="ml.g5.24xlarge" export MODEL_IMAGE="public.ecr.aws/deep-learning-containers/vllm:0.11.1-gpu-py312-cu129-ubuntu22.04-ec2-v1.0" export S3_BUCKET="my-model-bucket" export S3_MODEL_PATH="models/Llama-3.1-8B-Instruct" export AWS_REGION="us-west-2" export CERT_S3_URI="s3://my-bucket/certs/" export NAMESPACE="default" export NAME="demo" cat << EOF > inference_endpoint_config.yaml apiVersion: inference.sagemaker.aws.amazon.com/v1 kind: InferenceEndpointConfig metadata: name: ${NAME} namespace: ${NAMESPACE} spec: modelName: ${MODEL_NAME} instanceType: ${INSTANCE_TYPE} replicas: 1 invocationEndpoint: v1/chat/completions modelSourceConfig: modelSourceType: s3 s3Storage: bucketName: ${S3_BUCKET} region: ${AWS_REGION} modelLocation: ${S3_MODEL_PATH} prefetchEnabled: false kvCacheSpec: enableL1Cache: true enableL2Cache: true l2CacheSpec: l2CacheBackend: "tieredstorage" # can also be "redis" # Set l2CacheLocalUrl if selecting "redis" # l2CacheLocalUrl: "redis:redisdefaultsvcclusterlocal:6379" intelligentRoutingSpec: enabled: true routingStrategy: prefixaware tlsConfig: tlsCertificateOutputS3Uri: ${CERT_S3_URI} metrics: enabled: true modelMetrics: port: 8000 loadBalancer: healthCheckPath: /worker: resources: limits: nvidia.com/gpu: "4" requests: cpu: "6" memory: 30Gi nvidia.com/gpu: "4" image: ${MODEL_IMAGE} args: - "--model" - "/opt/ml/model" - "--max-model-len" - "20000" - "--tensor-parallel-size" - "4" modelInvocationPort: containerPort: 8000 name: http modelVolumeMount: name: model-weights mountPath: /opt/ml/model environmentVariables: - name: OPTION_ROLLING_BATCH value: "vllm" - name: SAGEMAKER_SUBMIT_DIRECTORY value: "/opt/ml/model/code" - name: MODEL_CACHE_ROOT value: "/opt/ml/model" - name: SAGEMAKER_MODEL_SERVER_WORKERS value: "1" - name: SAGEMAKER_MODEL_SERVER_TIMEOUT value: "3600" EOF kubectl apply -f inference_endpoint_config.yaml # Check inferenceendpointconfig status kubectl get inferenceendpointconfig ${NAME} -n ${NAMESPACE} NAME AGE demo 8s # Check pods status - you should see worker pods kubectl get pods -n ${NAMESPACE} NAME READY STATUS RESTARTS AGE demo-675886c7bb-7bhhg 3/3 Running 0 30s # Router pods are under hyperpod-inference-system namespace kubectl get pods -n hyperpod-inference-system NAME READY STATUS RESTARTS AGE hyperpod-inference-operator-controller-manager-dff64b947-m5nqk 1/1 Running 0 5h49m demo-default-router-8787cf46c-jmgqd 2/2 Running 0 2m16s可观测性
您可以通过 SageMaker HyperPod 的可观测性功能来监控托管 KV 缓存和智能路由的指标。有关更多信息,请参阅使用 Amazon SageMaker HyperPod 中的一键式可观测性加速基础模型开发。
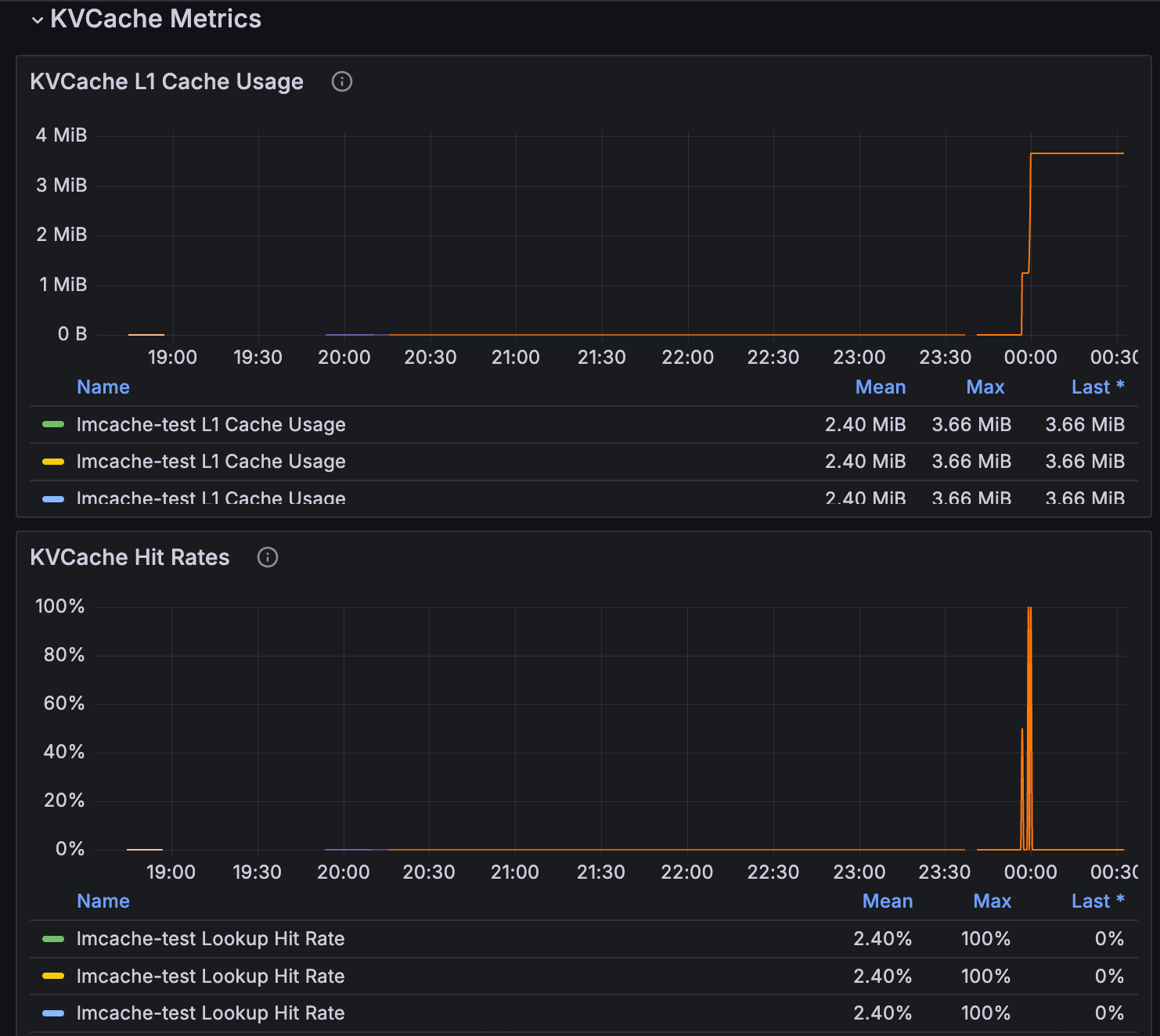
KV 缓存指标可在推理仪表板中查看。
基准测试
我们进行了全面的基准测试,以验证生产 LLM 部署中实际的性能改进。我们的基准测试使用了 Llama-3.1-70B-Instruct 模型,部署在 p5.48xlarge 实例(每个实例配备八个 NVIDIA GPU)上的 7 个副本上,采用稳定的负载流量模式,并启用了托管分层 KV 缓存和智能路由功能。基准测试环境使用专用的客户端节点组——每 100 个并发请求使用一个 c5.12xlarge 实例以产生受控负载,以及一个专用的服务器节点组,确保模型服务器在隔离状态下运行,以帮助防止高并发下的资源争用。
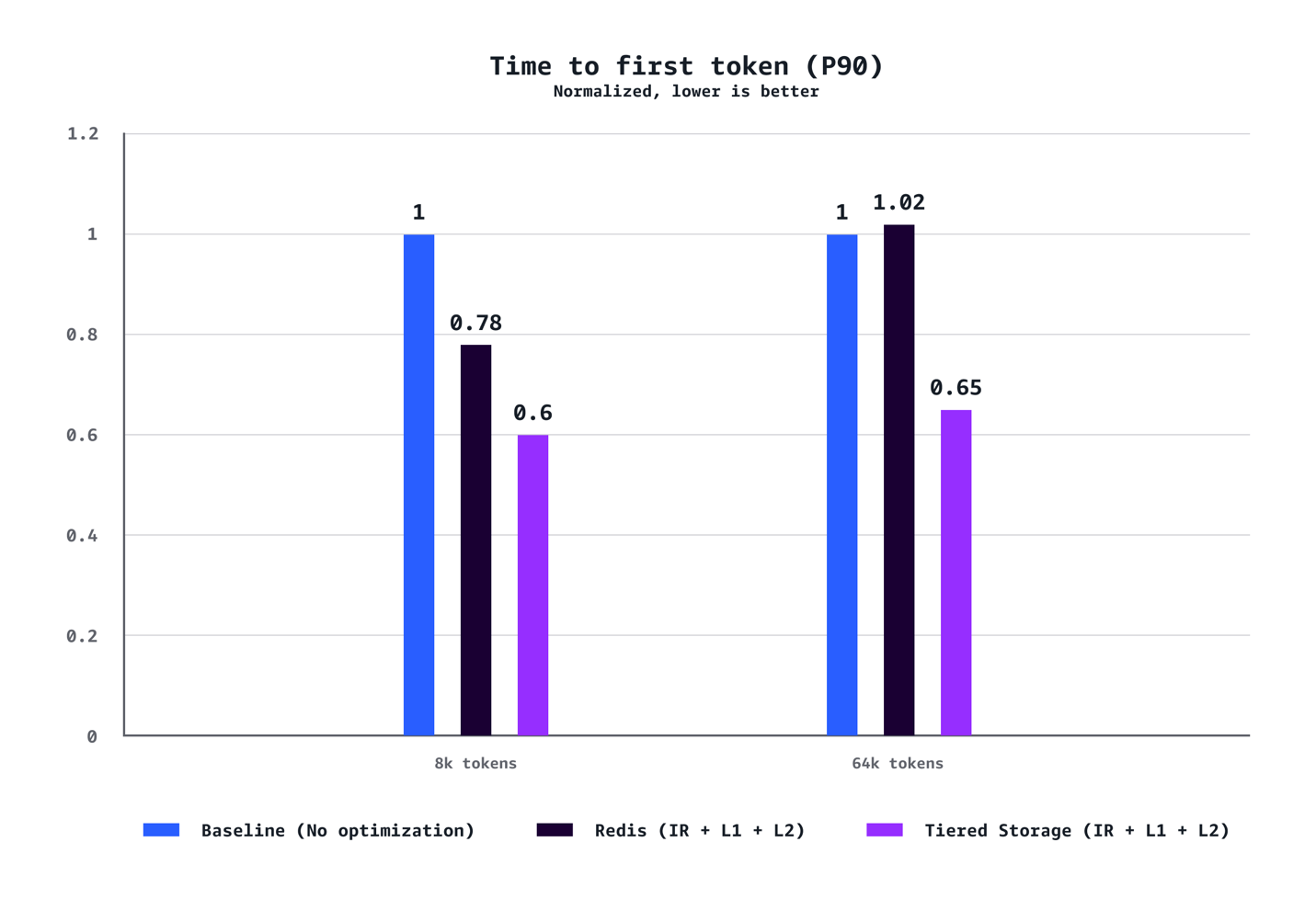
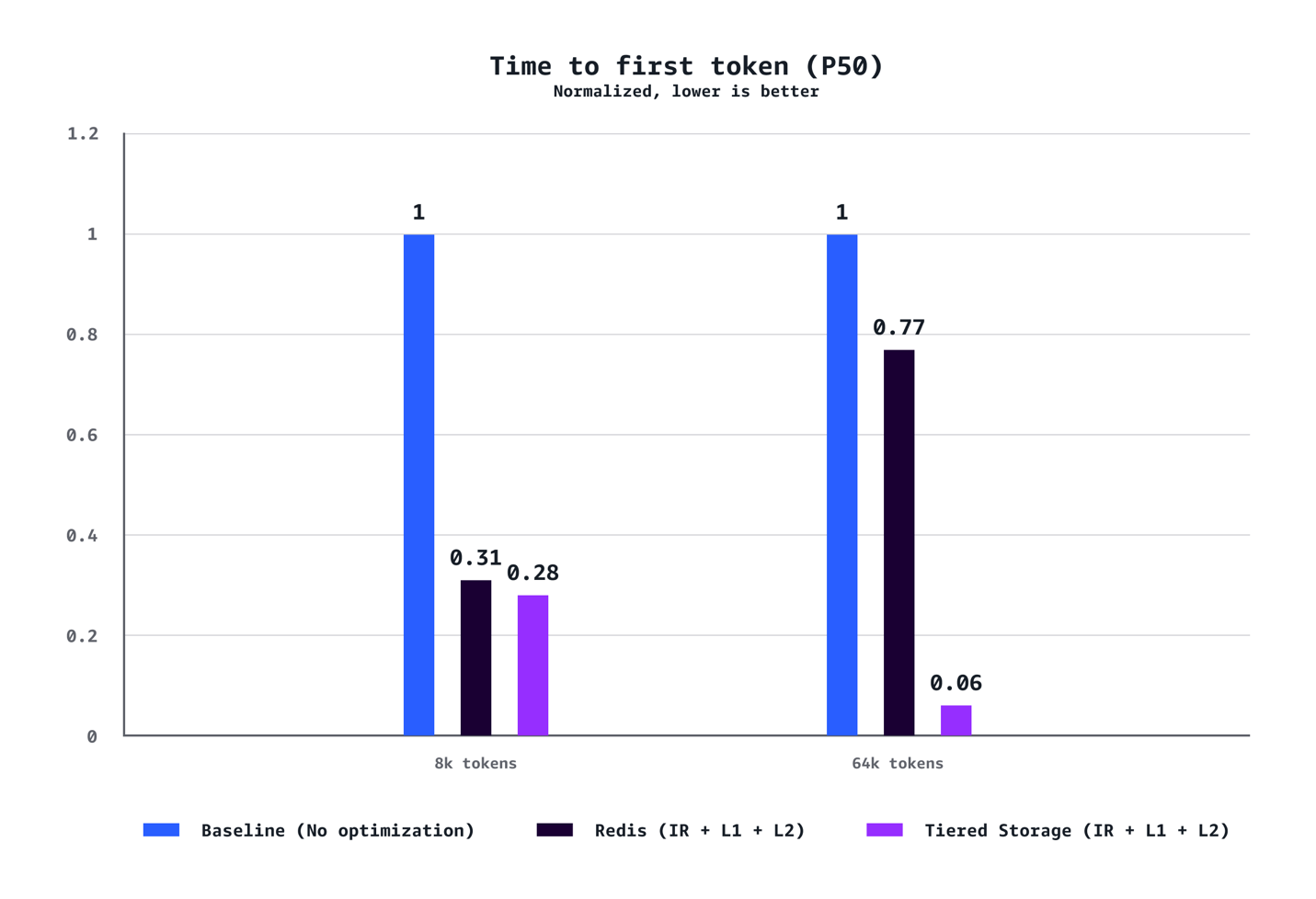
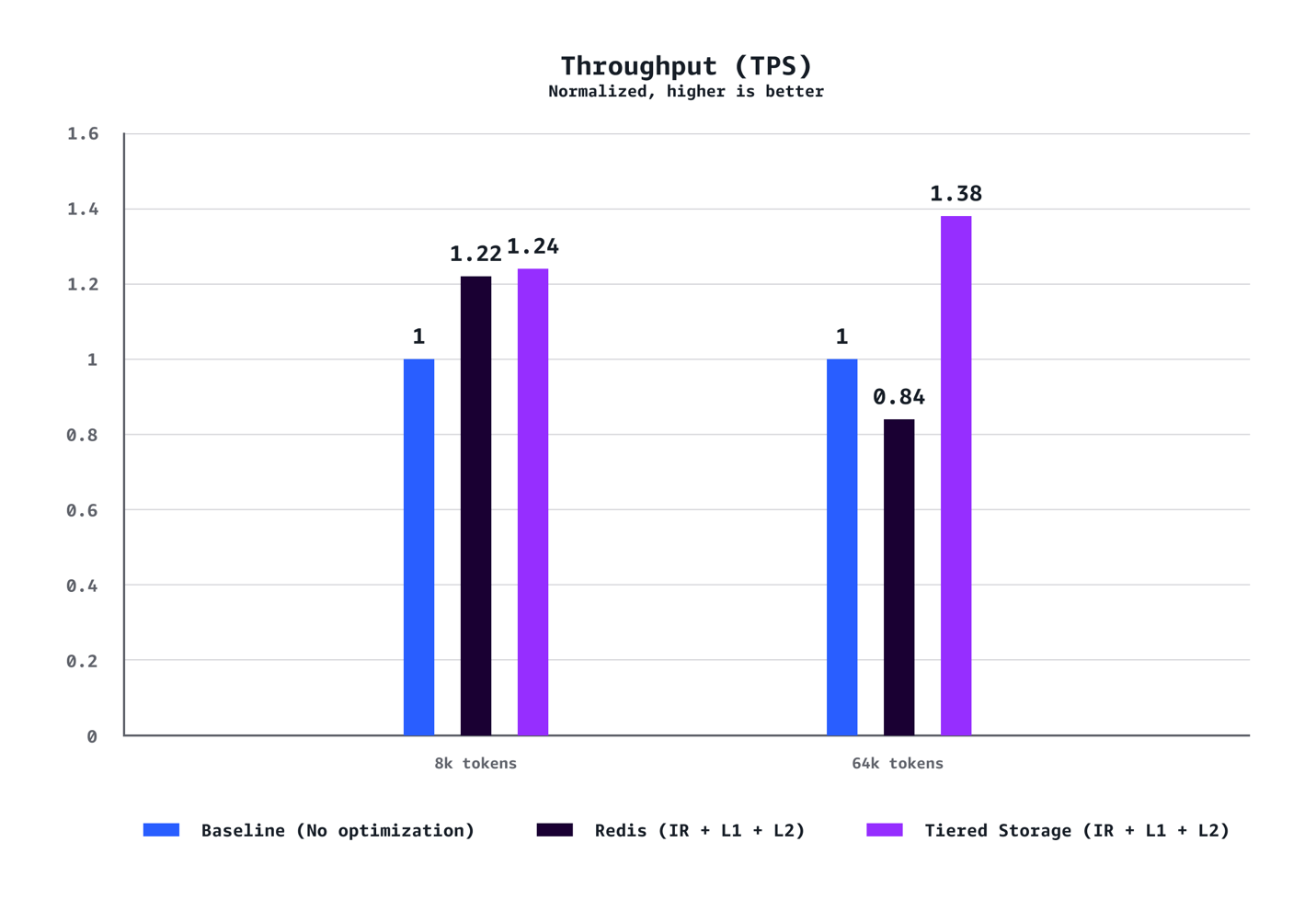
我们的基准测试表明,L1 和 L2 托管分层 KV 缓存与智能路由的结合,在多个维度上实现了显著的性能提升。对于中等上下文场景(8k token),与没有优化的基线配置相比,我们观察到 P90 的 TTFT 降低了 40%,P50 的 TTFT 降低了 72%,吞吐量提高了 24%,成本降低了 21%。对于长上下文工作负载(64K token),这些优势更为明显,P90 的 TTFT 降低了 35%,P50 的 TTFT 降低了 94%,吞吐量提高了 38%,成本节省了 28%。优化优势随着上下文长度的增加而急剧扩展。虽然 8K token 的场景在各项指标上显示出稳固的改进,但 64K token 的工作负载获得了变革性的增益,从根本上改变了用户体验。我们的测试还证实,AWS 托管的分层存储在所有场景中始终优于基于 Redis 的 L2 缓存。分层存储后端提供了更好的延迟和吞吐量,而无需管理单独 Redis 基础设施的运维开销,使其成为大多数部署的推荐选择。最后,与需要在成本和速度之间做出权衡的传统性能优化不同,此解决方案同时实现了成本和速度的提升。
TTFT (P90)
TTFT (P50)
吞吐量 (TPS)
成本/1000 token ($)

结论
Amazon SageMaker HyperPod 模型部署中的托管分层 KV 缓存和智能路由通过高效的内存管理和智能请求路由,帮助您优化 LLM 推理性能和成本。您现在就可以开始使用,只需将这些配置添加到 SageMaker HyperPod 可用 AWS 区域中的 HyperPod 模型部署即可。
要了解更多信息,请访问 Amazon SageMaker HyperPod 文档或遵循模型部署入门指南。
关于作者
 Chaitanya Hazarey 是 Amazon SageMaker HyperPod 推理的软件开发经理,在全栈工程、ML/AI 和数据科学方面拥有丰富的专业知识。作为负责任的 AI 开发的热情倡导者,他将技术领导力与对推进 AI 能力的深度承诺相结合,同时保持道德考量。他对现代产品开发的全面理解推动了机器学习基础设施的创新。
Chaitanya Hazarey 是 Amazon SageMaker HyperPod 推理的软件开发经理,在全栈工程、ML/AI 和数据科学方面拥有丰富的专业知识。作为负责任的 AI 开发的热情倡导者,他将技术领导力与对推进 AI 能力的深度承诺相结合,同时保持道德考量。他对现代产品开发的全面理解推动了机器学习基础设施的创新。
 Pradeep Cruz 是 AWS 的高级 SDM,致力于推动企业规模的 AI 基础设施和应用。在 Amazon SageMaker AI 领导跨职能组织,他为企业客户构建和扩展了多个高影响力服务,包括 AWS 上的 SageMaker HyperPod-EKS 推理、任务治理、特征商店、AIOps 和 JumpStart 模型中心,以及在 T-Mobile 和爱立信的企业 AI 平台。他的技术深度涵盖分布式系统、GenAI/ML、Kubernetes、云计算和全栈软件开发。
Pradeep Cruz 是 AWS 的高级 SDM,致力于推动企业规模的 AI 基础设施和应用。在 Amazon SageMaker AI 领导跨职能组织,他为企业客户构建和扩展了多个高影响力服务,包括 AWS 上的 SageMaker HyperPod-EKS 推理、任务治理、特征商店、AIOps 和 JumpStart 模型中心,以及在 T-Mobile 和爱立信的企业 AI 平台。他的技术深度涵盖分布式系统、GenAI/ML、Kubernetes、云计算和全栈软件开发。
 Vinay Arora 是 AWS 的生成式 AI 专家解决方案架构师,负责与客户合作,利用 AWS 技术设计尖端的 AI 解决方案。在加入 AWS 之前,Vinay 在金融领域拥有二十多年的经验——包括在银行和对冲基金的职位——他构建了风险模型、交易系统和市场数据平台。Vinay 拥有计算机科学和商业管理的硕士学位。
Vinay Arora 是 AWS 的生成式 AI 专家解决方案架构师,负责与客户合作,利用 AWS 技术设计尖端的 AI 解决方案。在加入 AWS 之前,Vinay 在金融领域拥有二十多年的经验——包括在银行和对冲基金的职位——他构建了风险模型、交易系统和市场数据平台。Vinay 拥有计算机科学和商业管理的硕士学位。
 Piyush Daftary 是 AWS 的高级软件工程师,在 Amazon SageMaker 团队工作,专注于为大型语言模型构建高性能、可扩展的推理系统。他的技术兴趣涵盖 AI/ML、数据库和搜索技术,专注于开发支持研究和生产工作负载的生产级解决方案,以实现高效的模型部署和推理规模化。他的工作涉及优化系统性能、实施智能路由机制以及设计支持高级 AI 功能的架构,热衷于解决复杂的分布式系统挑战,使开发人员和组织更容易获得先进的 AI 功能。业余时间,他喜欢旅行、徒步旅行和与家人共度时光。
Piyush Daftary 是 AWS 的高级软件工程师,在 Amazon SageMaker 团队工作,专注于为大型语言模型构建高性能、可扩展的推理系统。他的技术兴趣涵盖 AI/ML、数据库和搜索技术,专注于开发支持研究和生产工作负载的生产级解决方案,以实现高效的模型部署和推理规模化。他的工作涉及优化系统性能、实施智能路由机制以及设计支持高级 AI 功能的架构,热衷于解决复杂的分布式系统挑战,使开发人员和组织更容易获得先进的 AI 功能。业余时间,他喜欢旅行、徒步旅行和与家人共度时光。
 Ziwen Ning 是 AWS 的高级软件开发工程师,目前在 SageMaker Hyperpod 推理团队工作,专注于为大规模 AI 模型推理构建可扩展的基础设施。他的技术专长涵盖容器技术、Kubernetes 编排和 ML 基础设施,这些都是他在整个 AWS 生态系统中广泛工作所培养的。他在容器注册表和分发、容器运行时开发和开源贡献、使用自定义资源管理和监控容器化 ML 工作负载方面拥有深厚经验。Ziwen 热衷于设计使先进 AI 功能更易于使用的生产级系统。在空闲时间,他喜欢踢拳、羽毛球和沉浸在音乐中。
Ziwen Ning 是 AWS 的高级软件开发工程师,目前在 SageMaker Hyperpod 推理团队工作,专注于为大规模 AI 模型推理构建可扩展的基础设施。他的技术专长涵盖容器技术、Kubernetes 编排和 ML 基础设施,这些都是他在整个 AWS 生态系统中广泛工作所培养的。他在容器注册表和分发、容器运行时开发和开源贡献、使用自定义资源管理和监控容器化 ML 工作负载方面拥有深厚经验。Ziwen 热衷于设计使先进 AI 功能更易于使用的生产级系统。在空闲时间,他喜欢踢拳、羽毛球和沉浸在音乐中。
 Roman Blagovirnyy 是 SageMaker AI 团队的高级用户体验设计师,在加入 Amazon 之前,在金融、医疗、安全和人力资源行业企业和 B2B 应用程序和功能设计方面拥有 19 年的丰富经验。在 AWS,Roman 是 SageMaker AI Studio、SageMaker Studio Lab、数据和模型治理功能以及 HyperPod 设计的关键贡献者。Roman 目前致力于 HyperPod 管理员体验的新功能和改进。除此之外,Roman 对设计运营和流程有浓厚的兴趣。
Roman Blagovirnyy 是 SageMaker AI 团队的高级用户体验设计师,在加入 Amazon 之前,在金融、医疗、安全和人力资源行业企业和 B2B 应用程序和功能设计方面拥有 19 年的丰富经验。在 AWS,Roman 是 SageMaker AI Studio、SageMaker Studio Lab、数据和模型治理功能以及 HyperPod 设计的关键贡献者。Roman 目前致力于 HyperPod 管理员体验的新功能和改进。除此之外,Roman 对设计运营和流程有浓厚的兴趣。
 Caesar Chen 是 AWS SageMaker HyperPod 的软件开发经理,他领导尖端机器学习基础设施的开发。凭借构建生产级 ML 系统的丰富经验,他推动技术创新,同时培养团队的卓越性。他在可扩展模型托管基础设施方面的工作,使数据科学家和 ML 工程师能够更高效、更可靠地部署和管理模型。
Caesar Chen 是 AWS SageMaker HyperPod 的软件开发经理,他领导尖端机器学习基础设施的开发。凭借构建生产级 ML 系统的丰富经验,他推动技术创新,同时培养团队的卓越性。他在可扩展模型托管基础设施方面的工作,使数据科学家和 ML 工程师能够更高效、更可靠地部署和管理模型。
 Chandra Lohit Reddy Tekulapally 是 Amazon SageMaker HyperPod 团队的软件开发工程师。他热衷于设计和构建为大规模 AI 工作负载提供支持的可靠、高性能的分布式系统。工作之余,他喜欢旅行和探索新的咖啡店。
Chandra Lohit Reddy Tekulapally 是 Amazon SageMaker HyperPod 团队的软件开发工程师。他热衷于设计和构建为大规模 AI 工作负载提供支持的可靠、高性能的分布式系统。工作之余,他喜欢旅行和探索新的咖啡店。
 Kunal Jha 是 AWS 的首席产品经理。他专注于将 Amazon SageMaker Hyperpod 打造成生成式 AI 模型训练和推理的最佳选择。在业余时间,Kunal 喜欢滑雪和探索太平洋西北地区。
Kunal Jha 是 AWS 的首席产品经理。他专注于将 Amazon SageMaker Hyperpod 打造成生成式 AI 模型训练和推理的最佳选择。在业余时间,Kunal 喜欢滑雪和探索太平洋西北地区。
 Vivek Gangasani 是 SageMaker 推理的全球 GenAI 专家解决方案架构师。他推动 SageMaker 推理的上市(GTM)和外展产品战略。他还帮助企业和初创公司使用 SageMaker 和 GPU 部署、管理和扩展他们的 GenAI 模型。目前,他专注于开发用于优化 LLM 托管推理性能和 GPU 效率的策略和内容。在空闲时间,Vivek 喜欢徒步旅行、看电影和尝试不同的美食。
Vivek Gangasani 是 SageMaker 推理的全球 GenAI 专家解决方案架构师。他推动 SageMaker 推理的上市(GTM)和外展产品战略。他还帮助企业和初创公司使用 SageMaker 和 GPU 部署、管理和扩展他们的 GenAI 模型。目前,他专注于开发用于优化 LLM 托管推理性能和 GPU 效率的策略和内容。在空闲时间,Vivek 喜欢徒步旅行、看电影和尝试不同的美食。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区