



📢 转载信息
原文链接:https://blogs.nvidia.com/blog/data-blackwell-ultra-performance-lower-cost-agentic-ai/
原文作者:Ashraf Eassa
包括微软(Microsoft)、CoreWeave和甲骨文云基础设施(Oracle Cloud Infrastructure)在内的云服务提供商,正在大规模部署NVIDIA GB300 NVL72系统,以满足对Agentic Coding(代理式编程)和编码助手等低延迟和长上下文用例的需求。
英伟达Blackwell平台已被Baseten、DeepInfra、Fireworks AI和Together AI等领先的推理服务提供商广泛采用,旨在将每Token成本降低高达10倍。现在,NVIDIA Blackwell Ultra平台正将这一势头推向Agentic AI(代理式AI)领域的新高度。
AI代理和编码助手正驱动着与软件编程相关的AI查询量爆炸式增长:根据OpenRouter的《推理现状报告》(State of Inference report),去年的这一比例从11%激增至约50%。这些应用需要在多步工作流程中保持实时响应的低延迟,并在整个代码库中进行推理的长上下文能力。
SemiAnalysis InferenceX的最新性能数据表明,英伟达的软件优化与下一代NVIDIA Blackwell Ultra平台相结合,在这两方面都取得了突破性进展。NVIDIA GB300 NVL72系统与NVIDIA Hopper平台相比,现在的吞吐量每兆瓦(megawatt)提高了高达50倍,使得每Token成本降低了35倍。
通过在芯片、系统架构和软件方面进行创新,英伟达的极端协同设计(extreme codesign)加速了从代理式编程到交互式编码助手等AI工作负载的性能,同时在规模化部署中推动了成本的下降。

GB300 NVL72为低延迟工作负载提供高达50倍的性能提升
Signal65最近的分析显示,凭借极致的硬件和软件协同设计,NVIDIA GB200 NVL72提供的每瓦特Token数量超过10倍,意味着与NVIDIA Hopper平台相比,每Token成本降低十分之一。随着底层堆栈的不断改进,这种巨大的性能提升仍在持续扩大。
来自NVIDIA TensorRT-LLM、NVIDIA Dynamo、Mooncake和SGLang团队的持续优化,继续显著提升了Blackwell NVL72在处理混合专家模型(MoE)推理(mixture-of-experts (MoE) inference)时的吞吐量,覆盖所有延迟目标。例如,与仅四个月前相比,NVIDIA TensorRT-LLM库的改进已使GB200在低延迟工作负载上的性能提升了高达5倍。
- 更高性能的GPU内核:针对效率和低延迟进行优化,有助于充分利用Blackwell巨大的计算能力并提高吞吐量。
- NVIDIA NVLink对称内存:实现直接的GPU到GPU内存访问,提高通信效率。
- 程序化依赖启动:在上一内核完成之前启动下一个内核的设置阶段,最大限度地减少空闲时间。
在这些软件进步的基础上,采用Blackwell Ultra GPU的GB300 NVL72将吞吐量/兆瓦的性能前沿推向了与Hopper平台相比50倍的水平。
这种性能提升转化为更优异的经济效益,NVIDIA GB300在整个延迟范围内都比Hopper平台降低了成本。降幅最大的发生在代理式应用运行的低延迟场景:与Hopper平台相比,每百万Token成本降低了高达35倍。
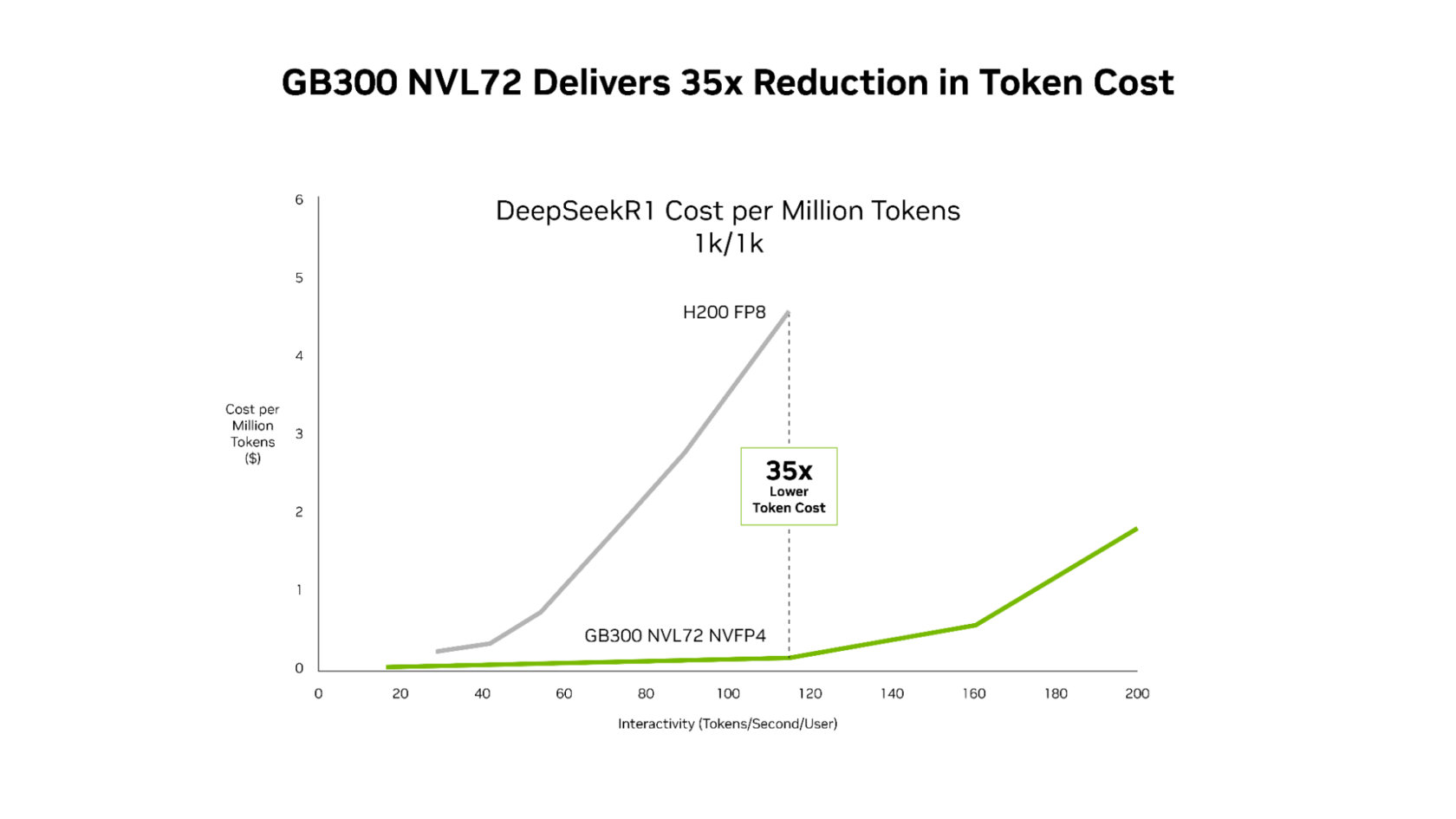
对于像代理式编码和交互式助手这类每毫秒都会在多步工作流程中累加的应用,这种不懈的软件优化与下一代硬件的结合,使得AI平台能够将实时交互体验扩展到显著更多的用户。
GB300 NVL72为长上下文工作负载提供卓越的经济效益
虽然GB200 NVL72和GB300 NVL72都能高效地提供超低延迟,但GB300 NVL72的独特优势在长上下文场景中最为明显。对于具有128,000 Token输入和8,000 Token输出的工作负载——例如推理整个代码库的AI编码助手——与GB200 NVL72相比,GB300 NVL72的每Token成本低了高达1.5倍。
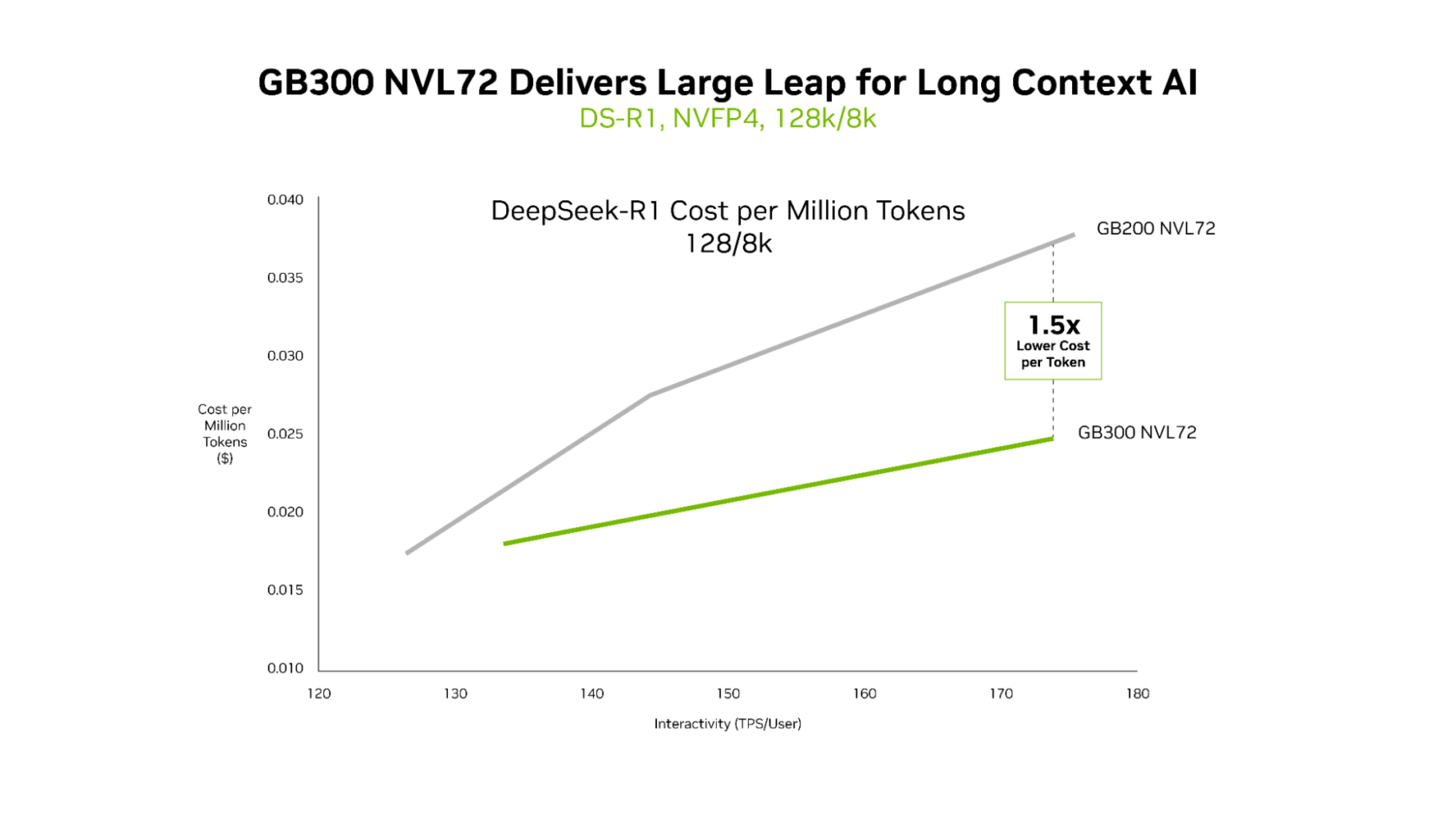
随着代理读取更多代码,上下文会随之增长。这使其能够更好地理解代码库,但也需要更多的计算资源。Blackwell Ultra拥有1.5倍的NVFP4计算性能和2倍的注意力处理速度,使代理能够高效地理解整个代码库。
Agentic AI的基础设施
领先的云服务提供商和AI创新者已经大规模部署了NVIDIA GB200 NVL72,并且也正在生产环境中部署GB300 NVL72。微软、CoreWeave和OCI正在为代理式编程和编码助手等低延迟和长上下文用例部署GB300 NVL72。通过降低Token成本,GB300 NVL72使得一类新的应用成为可能,这些应用可以在实时运行中推理庞大的代码库。
CoreWeave工程高级副总裁Chen Goldberg表示:“随着推理成为AI生产的中心,长上下文性能和Token效率变得至关重要。”“Grace Blackwell NVL72直接解决了这一挑战,CoreWeave的AI云(包括CKS和SUNK)旨在将GB300系统的优势(建立在GB200的成功之上)转化为可预测的性能和成本效率。其结果是为大规模运行工作负载的客户提供了更好的Token经济性和更实用的推理能力。”
NVIDIA Vera Rubin NVL72将带来下一代性能
随着NVIDIA Blackwell系统的大规模部署,持续的软件优化将继续为现有设备释放额外的性能和成本改进。
展望未来,NVIDIA Rubin平台——它将六个新芯片组合成一台AI超级计算机——有望带来新一轮的巨大性能飞跃。对于MoE推理,其每兆瓦的吞吐量比Blackwell高出10倍,相当于每百万Token成本降低十分之一。而对于下一波前沿AI模型,Rubin训练大型MoE模型所需的GPU数量仅为Blackwell的四分之一。
了解有关NVIDIA Rubin平台和Vera Rubin NVL72系统的更多信息。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区