



📢 转载信息
原文作者:James Yi, Hugo Tse, Mehran Najafi, Nirmal Kumar, Payal Singh, and Sagar Murthy
Cohere Embed 4 多模态嵌入模型现已作为完全托管的无服务器选项在 Amazon Bedrock 中提供。用户可以选择跨区域推理 (CRIS) 或全局跨区域推理来利用不同 AWS 区域的计算资源,从而管理意外的流量峰值。实时信息请求和时区集中是可能导致推理需求超过预期流量的事件示例。
Amazon Bedrock 上的新 Embed 4 模型专为分析企业文档而构建。该模型提供了领先的多语言能力,并在关键基准测试中显示出比 Embed 3 显著的改进,使其非常适合企业搜索等用例。
在本文中,我们将深入探讨 Embed 4 在企业搜索用例中的优势和独特功能。我们将向您展示如何利用与 Strands Agents、S3 Vectors 和 Amazon Bedrock AgentCore 的集成,快速开始在 Amazon Bedrock 上使用 Embed 4,从而构建强大的代理式检索增强生成 (RAG) 工作流。
Embed 4 通过原生支持将文本、图像以及交错的文本和图像组合成统一向量表示的复杂业务文档,推进了多模态嵌入能力。Embed 4 最多可处理 128,000 个 token,最大限度地减少了对繁琐文档分割和预处理管道的需求。Embed 4 还提供可配置的压缩嵌入,可将向量存储成本降低高达 83%(介绍 Embed 4:面向业务的多模态搜索)。结合对 100 多种语言的多语言理解能力,金融、医疗和制造等受监管行业的企业可以高效处理非结构化文档,加速洞察提取,优化 RAG 系统。请阅读 2025 年 7 月的此启动博客,了解如何将其部署在 Amazon SageMaker JumpStart 上。
可以使用 InvokeModel API 将 Embed 4 集成到您的应用程序中,以下是如何在 Boto3 中使用 AWS SDK for Python (Boto3) 与 Embed 4 配合使用的示例:
对于纯文本输入:
import boto3
import json # 初始化 Bedrock Runtime 客户端
bedrock_runtime = boto3.client('bedrock-runtime', region_name='us-east-1') # 请求体
body = json.dumps({
"texts": [
text1, text2], "input_type":"search_document", "embedding_types": ["float"]
})
# 调用模型
model_id = 'cohere.embed-v4:0'
response = bedrock_runtime.invoke_model(
modelId=model_id,
body=json.dumps(body),
accept= '*/*',
contentType='application/json'
)
# 解析响应
result = json.loads(response['body'].read())
对于混合模态输入:
import base64 # 初始化 Bedrock Runtime 客户端
bedrock_runtime = boto3.client('bedrock-runtime', region_name='us-east-1') # 请求体
body = json.dumps({
"inputs": [
{
"content": [
{ "type": "text", "text": text },
{ "type": "image_url", {"image_url":image_base64_uri}}
]
}
],
"input_type":"search_document",
"embedding_types": ["int8","float"]
})
# 调用模型
model_id = 'cohere.embed-v4:0'
response = bedrock_runtime.invoke_model(
modelId=model_id,
body=json.dumps(body),
accept= '*/*',
contentType='application/json'
)
# 解析响应
result = json.loads(response['body'].read())
有关更多详细信息,您可以查看 Amazon Bedrock 用户指南中的 Cohere Embed 4。
企业搜索用例
在本节中,我们将重点介绍在金融行业中使用 Embed 4 进行企业搜索的用例。Embed 4 为寻求以下目标的企业解锁了一系列功能:
- 简化信息发现
- 增强生成式 AI 工作流
- 优化存储效率
在 Amazon Bedrock 中使用基础模型是一个完全无服务器的环境,无需管理基础设施,并简化了与 Amazon Bedrock 其他功能的集成。有关使用 Embed 4 的其他可能用例,请参阅更多详细信息。
解决方案概述
借助 Amazon Bedrock 中提供的无服务器体验,您可以快速入门,而无需在基础设施管理上花费太多精力。在接下来的部分中,我们将展示如何开始使用 Cohere Embed 4。Embed 4 在设计时就考虑了存储效率。
我们选择 Amazon S3 vectors 进行存储,因为它是一种成本优化、面向 AI 的存储,具有大规模存储和查询向量的原生支持。S3 vectors 可以存储数十亿个向量嵌入,查询延迟低于一秒,与传统向量数据库相比,总成本可降低高达 90%。我们利用可扩展的 Strands Agent SDK 来简化代理开发并利用模型选择的灵活性。我们还使用 Bedrock AgentCore,因为它提供了一个完全托管的无服务器运行时,专为处理动态、长期运行的代理工作负载而构建,具有行业领先的会话隔离、安全性和实时监控。
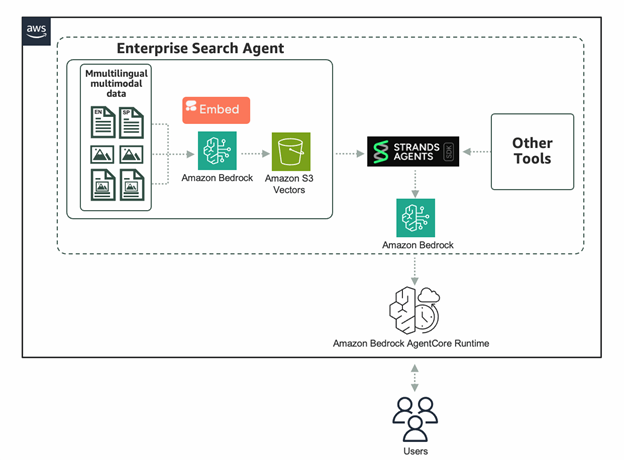
先决条件
要开始使用 Embed 4,请验证您是否具备以下先决条件:
- IAM 权限:使用必要的 Amazon Bedrock 权限配置您的 IAM 角色,或通过控制台或 SDK 生成 API 密钥进行测试。有关更多信息,请参阅Amazon Bedrock API 密钥。
- Strands SDK 安装:为您的开发环境安装所需的 SDK。有关更多信息,请参阅 Strands 快速入门指南。
- S3 Vectors 配置:创建一个 S3 向量存储桶和向量索引,用于存储和查询向量数据。有关更多信息,请参阅S3 Vectors 入门教程。
初始化 Strands 代理
Strands Agents SDK 提供了一个开源、模块化框架,可简化 AI 代理的开发、集成和编排。凭借灵活的架构,开发人员可以构建可重用的代理组件并轻松创建自定义工具。该系统支持多种模型,使用户可以自由选择最适合其特定用例的解决方案。模型可以托管在 Amazon Bedrock、Amazon SageMaker 或其他地方。
例如,Cohere Command A 是一个具有 111B 参数和 256K 上下文长度的生成模型。该模型在工具使用方面表现出色,可以扩展基线功能,同时避免不必要的工具调用。该模型也适用于多语言任务和 RAG 任务,例如在金融环境中处理数值信息。与专为金融服务等高度监管行业构建的 Embed 4 配合使用时,这种组合通过其适应性带来了巨大的竞争优势。
我们首先定义一个 Strands 代理可以使用的工具。该工具使用语义相似性搜索存储在 S3 中的文档。它首先使用 Cohere Embed 4 将用户查询转换为向量。然后,它通过查询存储在 S3 向量存储桶中的嵌入来返回最相关的文档。下面的代码仅显示了推理部分。在查询之前,由金融文档创建的嵌入已存储在 S3 向量存储桶中。
# S3 Vector 搜索金融文档的函数
@tool
def search(query_text: str, bucket_name: str = "my-s3-vector-bucket", index_name: str = "my-s3-vector-index-1536", top_k: int = 3, category_filter: str = None) -> str: """使用语义向量搜索金融文档""" bedrock = boto3.client("bedrock-runtime", region_name="us-east-1") s3vectors = boto3.client("s3vectors", region_name="us-east-1") # 使用 Cohere Embed v4 生成嵌入
response = bedrock.invoke_model(
modelId="cohere.embed-v4:0",
body=json.dumps({
"texts": [query_text],
"input_type": "search_query",
"embedding_types": ["float"]
}),
accept='*/*',
contentType='application/json'
)
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"]["float"][0]
# 查询向量
query_params = {
"vectorBucketName": bucket_name,
"indexName": index_name,
"queryVector": {"float32": embedding},
"topK": top_k,
"returnDistance": True,
"returnMetadata": True
}
if category_filter:
query_params["filter"] = {"category": category_filter}
response = s3vectors.query_vectors(**query_params)
return json.dumps(response["vectors"], indent=2)
然后我们定义一个可以使用该工具搜索金融文档的金融研究代理。随着您用例变得更加复杂,可以添加更多代理以完成专门的任务。
# 使用 Strands 创建金融研究代理
agent = Agent(
name="FinancialResearchAgent",
system_prompt="You are a financial research assistant that can search through financial documents, earnings reports, regulatory filings, and market analysis. Use the search tool to find relevant financial information and provide helpful analysis.",
tools=[search]
)
仅使用该工具即可返回以下结果。多语言金融文档根据与“比较收益增长率”查询的语义相似性进行排序。代理可以使用此信息来生成有用的见解。
result = search("Compare earnings growth rates mentioned in the documents")
print(result)
{
"key": "doc_0_en",
"metadata": {
"language": "en",
"source_text": "Q3 2024 earnings report shows revenue growth of 15% year-over-year driven by strong performance in cloud services and AI products",
"doc_id": 0
},
"distance": 0.7292724251747131
},
{
"key": "doc_18_zh",
"metadata": {
"source_text": "2024年上半年财务报告显示净利润增长20%,主要受益于金融科技和数字支付业务的快速发展",
"language": "zh",
"doc_id": 18
},
"distance": 0.7704182863235474
},
{
"key": "doc_12_de",
"metadata": {
"language": "de",
"doc_id": 12,
"source_text": "Halbjahresbericht 2024 verzeichnet 12% Gewinnsteigerung durch erfolgreiche Digitalisierung und Automatisierungslösungen"
},
"distance": 0.7738275527954102
}
]
上面的示例依赖于 S3 Vectors 的 QueryVectors API 操作,这对于小型文档可能有效。可以使用更复杂的分块和重新排序技术来改进此方法,以处理大型和复杂的企业文档。可以使用文档块的句子边界来创建文档块,以保持语义连贯性。然后使用文档块来生成嵌入。以下 API 调用将相同的查询传递给 Strands 代理:
response = agent("Compare earnings growth rates mentioned in the documents")
Strands 代理使用我们在示例中定义的搜索工具来生成关于比较收益增长率的查询答案。最终答案会考虑从搜索工具返回的结果:
Agent Query:
I'll search for information about earnings growth rates in the financial documents to help you compare them.
Tool #1: search
Let me search for more specific earnings growth information and financial performance metrics.
Tool #2: search
Let me search for more comprehensive financial performance data and specific earnings metrics.
Tool #3: search
Based on the financial documents I've searched through, here's a comparison of the earnings growth rates mentioned:
...
## Key Insights: 1. **Growth Range:** The earnings growth rates span from 12% to 20%, indicating generally healthy performance across different markets and sectors. 2. **Technology Focus:** All companies showing strong growth are heavily invested in technology sectors (fintech, AI, cloud services, cybersecurity, automation). 3. **Geographic Diversity:** The strong performers represent different regions (Asia, Europe, North America), suggesting broad-based growth in tech-enabled services. 4. **Growth Sustainability:** The Chinese fintech company leads with 20% net profit growth, while the others show strong revenue growth in the 12-18% range. The data suggests that companies with strong technology components, particularly in emerging areas like AI, fintech, and cybersecurity, are experiencing the most robust earnings growth rates in 2024.Based on the financial documents I've searched through, here's a comparison of the earnings growth rates mentioned:
## Earnings Growth Rate Comparison The data suggests that companies with strong technology components, particularly in emerging areas like AI, fintech, and cybersecurity, are experiencing the most robust earnings growth rates in 2024.
与本示例中使用的 S3 Vector 搜索功能等自定义工具一样,只是众多可能性之一。使用 Strands,可以轻松开发和编排自主代理,而 Bedrock AgentCore 则充当托管部署系统,用于在生产环境中托管和扩展这些 Strands 代理。
部署到 Amazon Bedrock AgentCore
构建和测试代理后,即可进行部署。AgentCore Runtime 是一个安全且无服务器的运行时,专为部署和扩展动态 AI 代理而构建。使用入门工具包自动创建 IAM 执行角色、容器映像以及用于在 AgentCore Runtime 中托管代理的 Amazon Elastic Container Registry 存储库。您可以为代理定义多种可用工具。在此示例中,我们使用由 Embed 4 驱动的 Strands Agent:
# 使用 bedrock-agentcore<=0.1.5 和 bedrock-agentcore-starter-toolkit==0.1.14
from bedrock_agentcore_starter_toolkit import Runtime
from boto3.session import Session
boto_session = Session()
region = boto_session.region_name
agentcore_runtime = Runtime()
agent_name = "search_agent"
response = agentcore_runtime.configure(
entrypoint="example.py", # 替换为您自定义的代理和工具
auto_create_execution_role=True,
auto_create_ecr=True,
requirements_file="requirements.txt",
region=region,
agent_name=agent_name
)
response
launch_result = agentcore_runtime.launch()
invoke_response = agentcore_runtime.invoke({"prompt": "Compare earnings growth rates mentioned in the documents"})
清理
为避免在完成后产生不必要的成本,请清空并删除创建的 S3 Vector 存储桶、可以向 Amazon Bedrock API 发出请求的应用程序、启动的 AgentCore Runtimes 以及相关的 ECR 存储库。
有关更多信息,请参阅此文档以删除向量索引,以及此文档删除向量存储桶,并参阅此步骤以移除由 Bedrock AgentCore 入门工具包创建的资源。
结论
Amazon Bedrock 上的 Embed 4 对于希望解锁其非结构化、多模态数据价值的企业非常有益。Embed 4 支持高达 128,000 个 token、用于成本效益的压缩嵌入,以及跨 100 多种语言的多语言功能,为大规模企业搜索提供了所需的可扩展性和精确性。
Embed 4 具有先进的功能,并针对金融、医疗保健和制造等受监管行业的领域特定数据理解进行了优化。当与用于成本优化存储的 S3 Vectors、用于代理编排的 Strands Agents 以及用于部署的 Bedrock AgentCore 结合使用时,组织可以构建安全、高性能的代理工作流,而无需承担管理基础设施的开销。请查看完整的区域列表以获取未来更新。
要了解更多信息,请查看 Cohere in Amazon Bedrock 产品页面和 Amazon Bedrock 定价页面。如果您有兴趣深入了解,请查看 代码示例和 Cohere on AWS GitHub 存储库。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区