



📢 转载信息
原文链接:http://bair.berkeley.edu/blog/2025/07/01/peva/
原文作者:BAIR Blog

预测自我中心视频(PEVA)。给定过去的视频帧和一个指定3D姿态所需变化的动作,PEVA可以预测下一个视频帧。我们的结果表明,给定第一帧和一系列动作,我们的模型可以生成原子动作的视频(a),模拟反事实(b),并支持长视频生成(c)。
近年来,世界模型在学习模拟未来结果以用于规划和控制方面取得了显著进步。从直观物理学到多步视频预测,这些模型的威力与表现力与日俱增。但很少有模型是专为真正的具身智能体设计的。为了创建一个具身智能体的世界模型,我们需要一个在真实世界中行动的真实具身智能体。一个真实的具身智能体具有物理基础的复杂动作空间,而不是抽象的控制信号。它们还必须在多样化的现实场景中行动,并具有自我中心视野,而不是美观的场景和静止的摄像头。

💡 提示:点击任何图片可查看全分辨率版本。
为什么这很难?
- 动作与视觉高度依赖于上下文。 相同的视野可能导致不同的动作,反之亦然。这是因为人类在复杂、具身、目标导向的环境中行动。
- 人类控制是高维且结构化的。 全身运动跨越48个以上的自由度,具有分层、时间依赖的动态特性。
- 自我中心视野揭示意图但隐藏了身体。 第一人称视觉反映了目标,但没有反映运动执行,模型必须从不可见的物理动作中推断后果。
- 感知滞后于动作。 视觉反馈通常会延迟几秒钟,这需要长视距预测和时间推理。
为了开发具身智能体的世界模型,我们必须将方法建立在满足这些标准的智能体基础之上。人类通常是先看后动——我们的眼睛锁定目标,大脑对结果进行简短的视觉“模拟”,然后身体才会移动。在每时每刻,我们的自我中心视野既是环境的输入,也反映了下一次运动背后的意图/目标。当我们考虑身体动作时,我们应该同时考虑脚的动作(移动和导航)和手的动作(操纵),或者更普遍地说,全身控制。
我们做了什么?

我们训练了一个模型来Predict Ego-centric Video from human Actions(PEVA),用于全身姿态条件下的自我中心视频预测(PEVA)。PEVA以由身体关节层次结构组织的运动学姿态轨迹为条件,学习从第一人称视角模拟物理人类动作如何影响环境。我们基于Nymeria训练了一个自回归条件扩散Transformer,Nymeria是一个大规模数据集,它将真实世界的自我中心视频与身体姿态捕捉数据配对。我们分层评估协议测试了越来越具有挑战性的任务,为模型的具身预测和控制能力提供了全面的分析。这项工作代表了通过人类视角视频预测来模拟复杂现实环境和具身智能体行为的初步尝试。
方法
来自运动的结构化动作表示
为了连接人类运动和自我中心视觉,我们将每个动作表示为一个丰富的、高维的向量,该向量捕获了全身动力学和详细的关节运动。我们没有使用简化的控制,而是根据身体的运动学树对全局平移和相对关节旋转进行编码。运动在3D空间中表示,根部平移有3个自由度,上半身关节有15个。使用欧拉角表示相对关节旋转,产生一个48维的动作空间(3 + 15 × 3 = 48)。运动捕捉数据使用时间戳与视频对齐,然后从全局坐标转换为以骨盆为中心的局部坐标系,以实现位置和方向的不变性。所有位置和旋转都经过归一化以确保学习稳定。每个动作都捕获了帧间的运动变化,使模型能够随着时间将物理运动与视觉后果联系起来。
PEVA的设计:自回归条件扩散Transformer
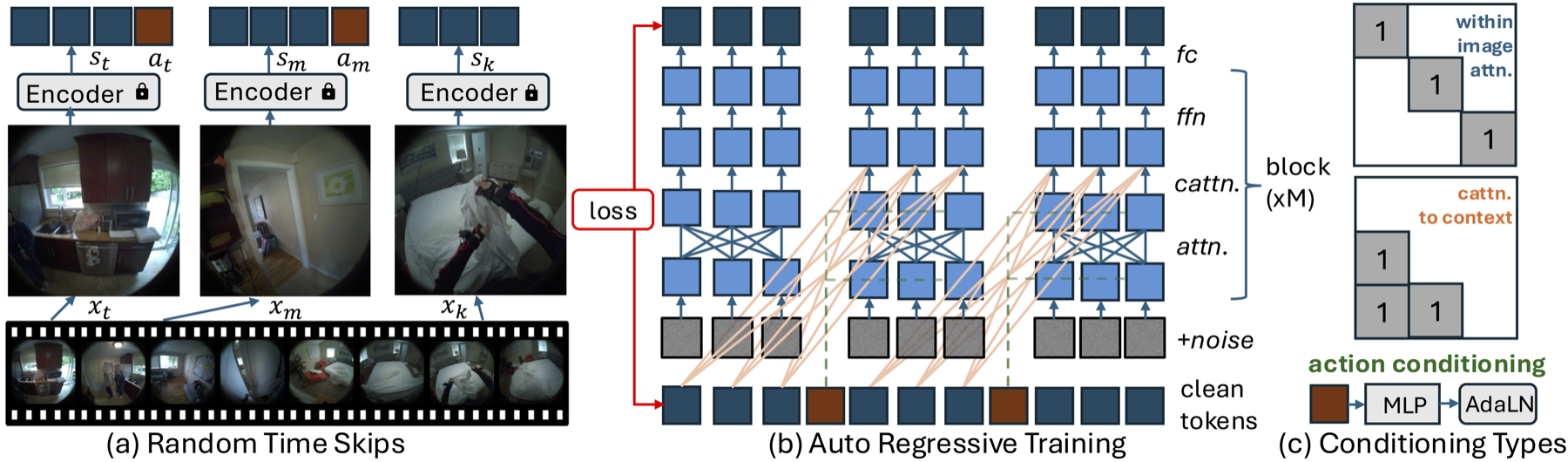
虽然导航世界模型中的条件扩散Transformer (CDiT) 使用简单的控制信号(如速度和旋转),但对全身人类运动的建模带来了更大的挑战。人类动作是高维的、时间上延展的,并且受到物理限制。为应对这些挑战,我们在三个方面扩展了CDiT方法:
- 随机时间跳跃 (Random Timeskips):使模型能够学习短期运动动态和长期活动模式。
- 序列级训练 (Sequence-Level Training):通过对每个帧前缀应用损失来模拟整个运动序列。
- 动作嵌入 (Action Embeddings):将时间t的所有动作连接成一个1D张量,以条件化每个AdaLN层,实现高维全身运动。
采样和滚出策略
在测试时,我们通过以一组过去的上下文帧为条件来生成未来的帧。我们将这些帧编码成潜在状态,并向目标帧添加噪声,然后使用我们的扩散模型对其进行逐步去噪。为加速推理,我们限制了注意力,其中图像内注意力仅应用于目标帧,而上下文交叉注意力仅应用于最后一帧。对于动作条件预测,我们使用自回归滚出策略。从上下文帧开始,我们使用VAE编码器对其进行编码,并附加当前动作。然后模型预测下一帧,将其添加到上下文中,同时丢弃最旧的一帧,该过程对序列中的每个动作重复一次。最后,我们使用VAE解码器将预测的潜在变量解码为像素空间。
原子动作
我们将复杂的人类运动分解为原子动作——例如手部动作(上、下、左、右)和全身动作(前移、旋转)——以测试模型对特定关节运动如何影响自我中心视野的理解。我们在此处包含了一些样本:
身体动作
 向前移动
向前移动
 左转
左转
 右转
右转
左手动作
 左手上移
左手上移
 左手下移
左手下移
 左手向左移动
左手向左移动
 左手向右移动
左手向右移动
右手动作
 右手上移
右手上移
 右手下移
右手下移
 右手向左移动
右手向左移动
 右手向右移动
右手向右移动
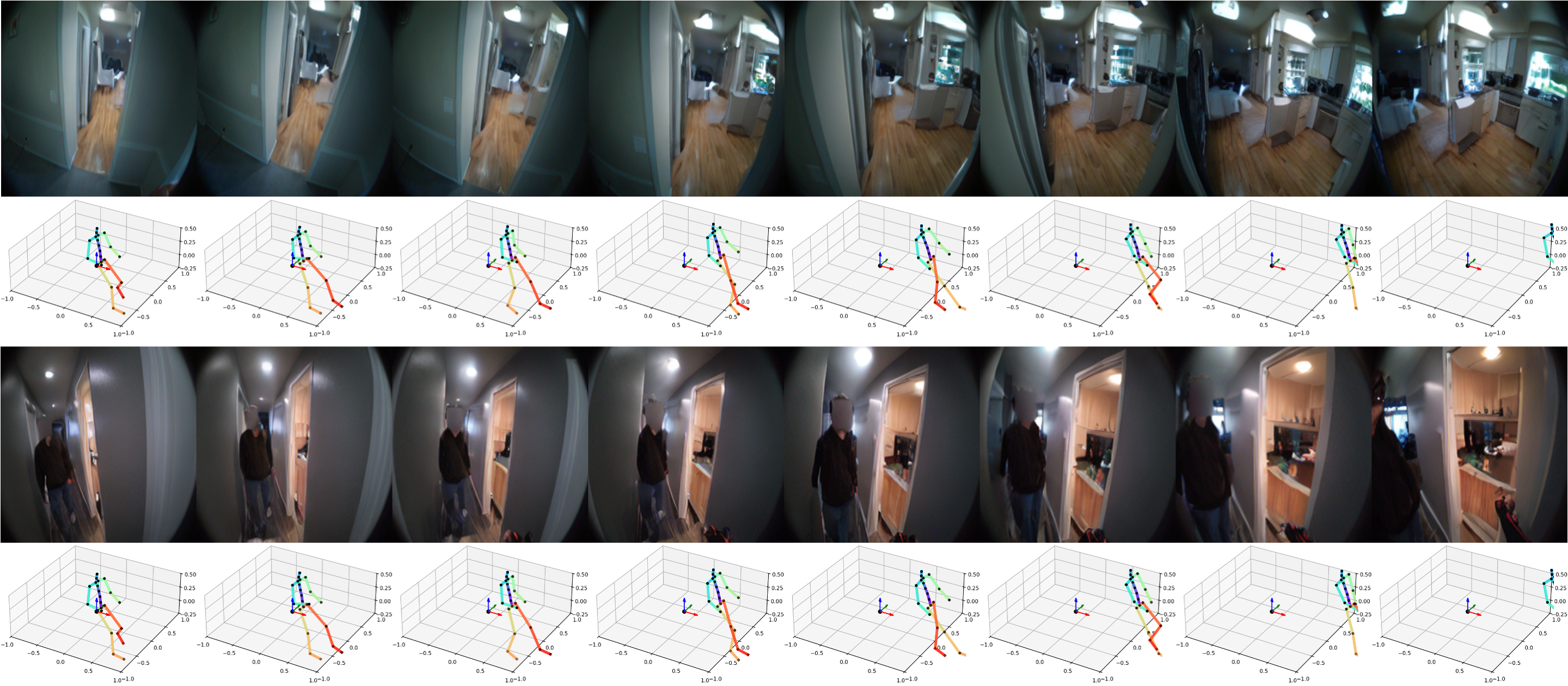
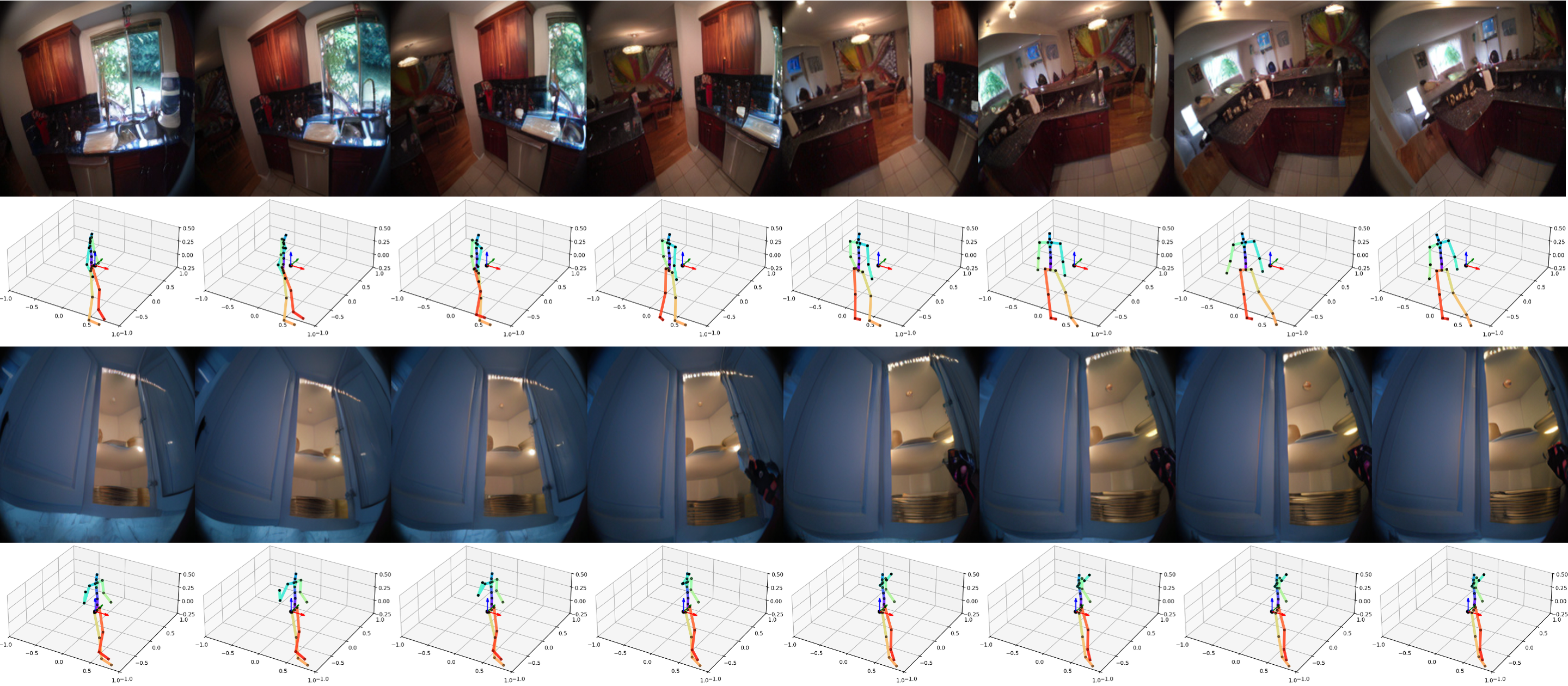
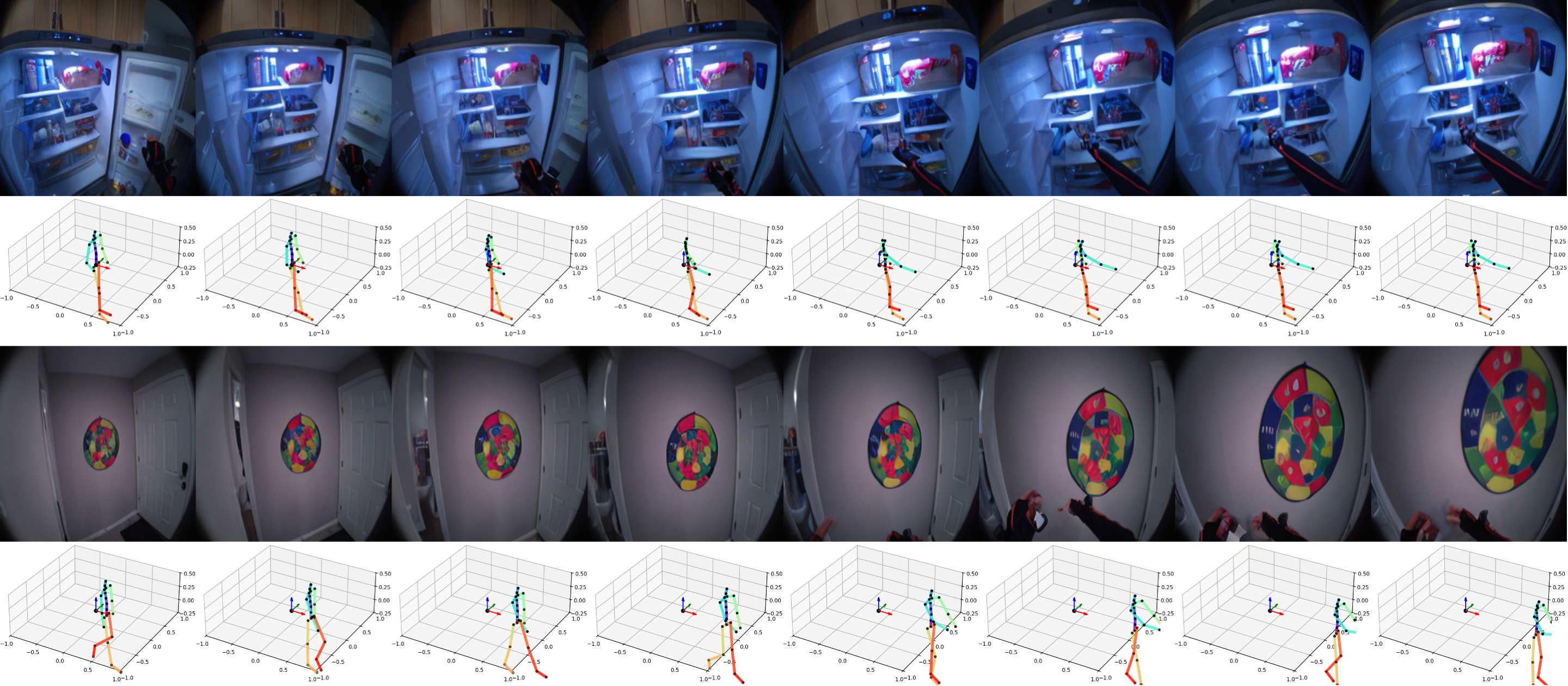
长时序滚出
在这里,您可以看到模型在扩展预测范围时保持视觉和语义一致性的能力。我们展示了一些PEVA根据全身运动生成连贯的16秒滚出的样本。我们在此处包含了一些视频样本和图像样本供您仔细查看:

 序列 1
序列 1
 序列 2
序列 2
 序列 3
序列 3
规划
PEVA可用于规划,方法是模拟多个动作候选,并根据其与目标的感知相似性(由LPIPS测量)对它们进行评分。

在此示例中,它排除了通往水槽或户外的路径,找到了打开冰箱的正确路径。

在此示例中,它排除了通往采摘附近植物和去厨房的路径,找到了通往架子的合理动作序列。
实现视觉规划能力
我们将规划构建为一个能量最小化问题,并使用交叉熵方法(CEM)进行动作优化,遵循“导航世界模型”[arXiv:2412.03572]中介绍的方法。具体来说,我们优化左臂或右臂的动作序列,同时固定身体其他部位。下面展示了由此产生的计划的代表性示例:

在这种情况下,我们能够预测一系列动作,使我们的右臂抬起以够到搅拌棒。我们看到了我们方法的局限性,因为我们只预测右臂,所以我们没有预测相应地移动左臂向下。

在这种情况下,我们能够预测一系列动作,这些动作伸向水壶,但没有像目标中那样抓住它。

在这种情况下,我们能够预测一系列将我们的左臂向内收缩的动作,类似于目标。
定量结果
我们使用多个指标评估了PEVA,以证明其从全身动作生成高质量自我中心视频的有效性。我们的模型在感知质量方面持续优于基线模型,在长时程内保持连贯性,并显示出随模型规模扩展的强大特性。
基线感知指标
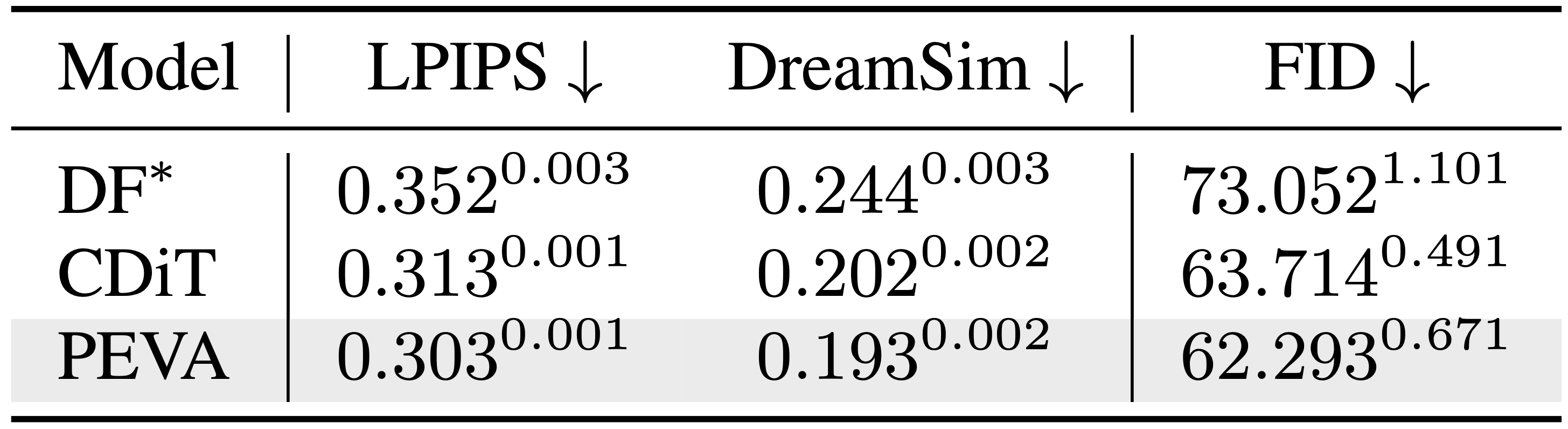
不同模型间的基线感知指标比较。
原子动作性能

模型在生成原子动作视频方面的比较。
FID 比较

不同模型和时间范围的FID比较。
扩展性
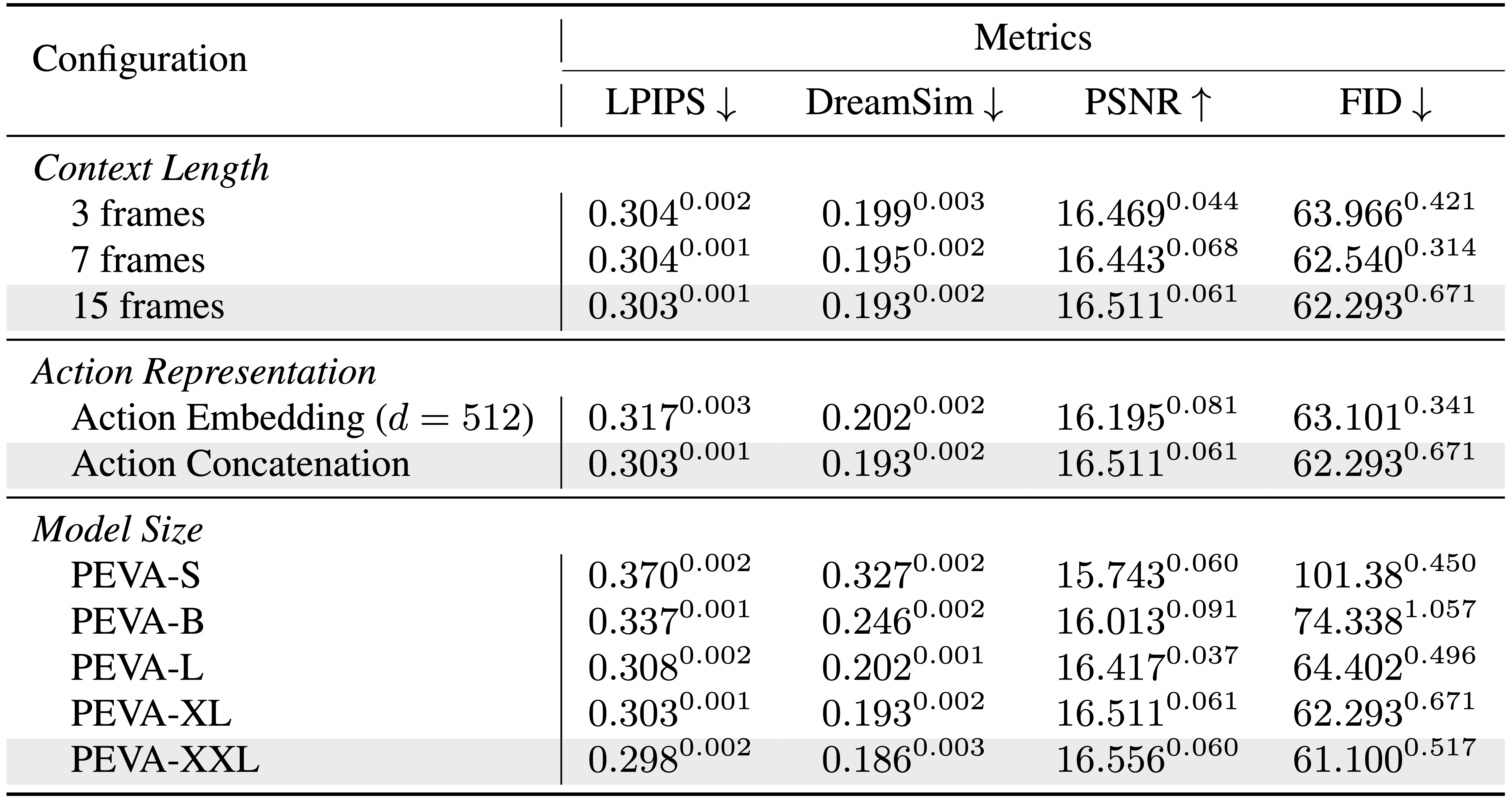
PEVA具有良好的扩展能力。更大的模型带来更好的性能。
未来方向
我们的模型在从全身运动预测自我中心视频方面显示出有希望的结果,但这仍然是迈向具身规划的早期一步。规划仅限于模拟候选手臂动作,缺乏长视距规划和完整的轨迹优化。将PEVA扩展到闭环控制或交互式环境是关键的下一步。该模型目前缺乏对任务意图或语义目标的明确条件。我们的评估使用图像相似性作为代理目标。未来的工作可以探索将PEVA与高层次目标条件和面向对象表示的集成相结合。
致谢
作者感谢Rithwik Nukala协助我们标注原子动作。我们感谢Katerina Fragkiadaki、Philipp Krähenbühl、Bharath Hariharan、Guanya Shi、Shubham Tulsiani和Deva Ramanan提出的有益建议和反馈,以改进论文;感谢Jianbo Shi关于控制理论的讨论;感谢Yilun Du对扩散强制的支持;感谢Brent Yi在人类运动相关工作中的帮助,并感谢Alexei Efros关于世界模型的讨论和辩论。这项工作部分由ONR MURI N00014-21-1-2801资助。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区