



📢 转载信息
原文作者:Nick McCarthy, Sapana Chaudhary, Shreyas Subramanian, and Jennifer Zhu
您可以在 Amazon Bedrock 中使用强化微调 (RFT) 来定制 Amazon Nova 及支持的开源模型,通过定义“什么是好结果”来指导模型,而无需大规模的标注数据集。RFT 通过从奖励信号而非静态示例中学习,在降低定制成本和复杂性的同时,可实现高达 66% 的准确率提升。本文涵盖了 RFT 在 Amazon Bedrock 上的最佳实践,包括数据集设计、奖励函数策略以及针对代码生成、结构化提取和内容审核等用例的超参数调优。
RFT 的应用场景:强化微调在何处大放异彩?
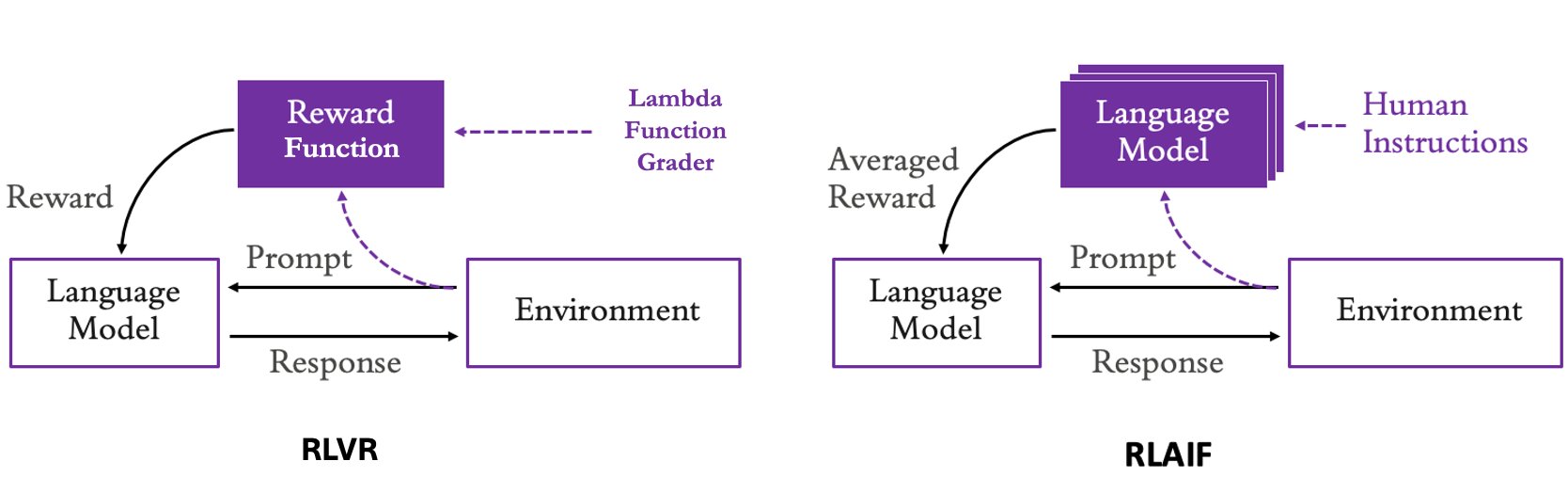
强化微调 (RFT) 是一种通过奖励信号改进基础模型 (FM) 行为的模型定制技术。与有监督微调 (SFT) 不同,RFT 不直接训练正确的响应(标签 I/O 对),而是使用输入数据集和奖励函数。奖励函数可以是基于规则的,也可以是经过训练的评分模型或 LLM 判别器。在训练期间,模型生成候选响应,奖励函数对其评分。根据奖励,模型权重会进行更新,从而增加生成高分响应的概率。这种迭代过程引导模型学习什么样的行为能带来更好的结果。
RFT 在以下两个领域表现尤为出色:
- 自动验证任务:规则或测试可以自动验证正确性的任务。
- 主观评估任务:由另一个模型评估响应质量的任务。
第一类任务包括:必须通过测试的代码生成、具有可验证答案的数学推理、必须符合严格模式的结构化数据提取,以及必须正确解析并执行的 API/工具调用。这种模式被称为带有可验证奖励的强化学习 (RLVR)。
此外,RFT 也适用于缺乏明确正确性的主观任务,如内容审核、聊天机器人、创意写作或摘要总结。通过详细的评估准则指导的“判别模型”可以充当奖励函数,这被称为基于 AI 反馈的强化学习 (RLAIF)。
GSM8K 案例:利用 RFT 改进数学推理
为了展示 RFT 的实际应用,我们可以观察其如何提升模型解决数学推理问题的能力。由于数学问题的解通常可以客观验证,因此我们可以设计清晰的奖励信号来引导模型。在 GSM8K 数据集中,不仅需要得到最终的 $990 数值,还需要模型能够展示符合逻辑的推理步骤。
<begin_internal_thought>
计算 5 天 10 小时轮班的总薪资。因为每天工作超过 8 小时,需拆分为正常与加班时间,计算加班费后汇总。
</end_internal_thought> <begin_of_solution>
加班费: $18.00 + (1/2 × $18.00) = $27.00/小时
每日总计: 8 × $18 + 2 × $27 = $198
5 天总计: 5 × $198 = $990 \boxed{990}
</end_of_solution>数据集准备最佳实践
RFT 的效果在很大程度上取决于数据质量。请遵循以下原则:
- 提示词分布:数据集应涵盖模型在生产环境中可能遇到的所有提示词类型。
- 基础模型能力:确保模型能够对输入产生初步反应,否则学习信号将过于微弱。
- 清晰的提示设计:提示词应明确沟通期望与限制,避免歧义。
- 可靠的参考答案:包含锚点参考答案有助于减少奖励计算中的噪声。
- 一致的奖励信号:确保优秀的响应始终获得比差响应更高的分数。
超参数调优指南
在 Amazon Bedrock 中进行 RFT 时,以下建议可作为实验的起点:
- EpochCount (训练轮数):小型数据集通常在 6-12 轮后持续提升,大型数据集则在 3-6 轮即可获得最优性能。
- BatchSize (批次大小):128 是大多数用例的良好起点。若损失函数波动较大,可适当增加此值。
- LearningRate (学习率):基于 LoRA(秩为 32)的 RFT,1e-4 的学习率通常能产生强劲的效果。
监控指标说明:通过 CloudWatch 监控训练奖励与验证奖励,如果奖励曲线稳定上升且验证集表现良好,说明模型正在有效学习。如果发现“奖励黑客”(模型通过钻奖励函数空子来提升分数但质量下降),则需要及时调整奖励函数的逻辑。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区