



📢 转载信息
原文链接:http://bair.berkeley.edu/blog/2024/05/29/tiny-agent/
原文作者:Lutfi Eren Erdogan, Nicholas Lee, Siddharth Jha, Sehoon Kim, Ryan Tabrizi, Suhong Moon, Coleman Hooper, Gopala Anumanchipalli, Kurt Keutzer, Amir Gholami

大型语言模型(LLM)通过自然语言(例如英语)执行命令的能力,催生了智能体系统,这些系统可以通过编排正确的工具集(例如 ToolFormer, Gorilla)来完成用户的查询。这,连同最近像 GPT-4o 或 Gemini-1.5 模型这样的多模态努力,扩大了 AI 智能体的可能性领域。虽然这非常令人兴奋,但这些模型庞大的模型尺寸和计算需求通常要求它们的推理在云端进行。这给它们的广泛采用带来了一些挑战。首先也是最重要的,将视频、音频或文本文档等数据上传到云端第三方供应商可能会引发隐私问题。其次,这需要云/Wi-Fi 连接,而这种情况并非总是可能。例如,部署在现实世界中的机器人不一定总能保持稳定的连接。除此之外,延迟也可能是一个问题,因为向云端上传大量数据并等待响应可能会减慢响应时间,从而导致不可接受的解决时间。
如果我们能在边缘本地部署 LLM 模型,这些挑战就可以得到解决。然而,像 GPT-4o 或 Gemini-1.5 这样的当前 LLM 对于本地部署来说太大了。一个促成因素是,模型尺寸的很大一部分最终都将关于世界的通用信息记忆在其参数化记忆中,这对于特定的下游应用可能不是必需的。例如,如果你向这些模型询问一般的常识性问题,如历史事件或著名人物,即使提示中没有附加上下文,它们也可以利用其参数化记忆来产生结果。然而,这种隐性记忆到参数化记忆中的训练数据似乎与 LLM 中的“涌现”现象(如上下文学习和复杂推理)相关,而这正是模型尺寸扩展的驱动力。
然而,这引出了一个有趣的研究问题:
实现这一点将显著减少智能体系统的计算足迹,从而支持高效且保护隐私的边缘部署。我们的研究表明,对于小型语言模型来说,通过使用不需要回忆通用世界知识的专业化、高质量数据进行训练,这是可行的。
这样的系统对于语义系统特别有用,在这些系统中,AI 智能体的作用是理解自然语言中的用户查询,而不是像 ChatGPT 那样进行问答回复,而是编排正确的工具和 API 集合来完成用户的命令。例如,在类似 Siri 的应用程序中,用户可能会要求语言模型创建一个带有特定与会者的日历邀请。如果已经为创建日历项定义了预定义脚本,LLM 只需要学会如何使用正确的输入参数(如与会者的电子邮件地址、事件标题和时间)来调用此脚本即可。这个过程不需要回忆/记忆维基百科等来源的世界知识,而是需要推理和学习来调用正确的函数并正确地编排它们。
我们的目标是开发能够进行复杂推理的小型语言模型(SLM),这些模型可以安全、私密地部署在边缘设备上。在这里,我们将讨论我们正在为此目的追求的研究方向。首先,我们讨论如何使小型开源模型能够执行准确的函数调用,这是智能体系统的关键组成部分。事实证明,现成的[开箱即用]小型模型具有非常低的函数调用能力。我们讨论了如何通过系统地策划高质量的函数调用数据来解决这个问题,并以一个专业的 Mac 助手智能体作为我们的驱动应用。然后我们展示,在该高质量策划数据集上进行微调,可以使 SLM 甚至超越 GPT-4-Turbo 的函数调用性能。然后我们展示,通过一种新的工具 RAG 方法,这可以进一步改进并提高效率。最后,我们展示最终的模型如何通过边缘部署,实现实时响应。
在 MacBook M3 上本地部署的 TinyAgent-1B 演示,它与 Whisper-v3 一起在本地运行。该框架是开源的,可在 https://github.com/SqueezeAILab/TinyAgent 获取
教 LLM 进行函数调用
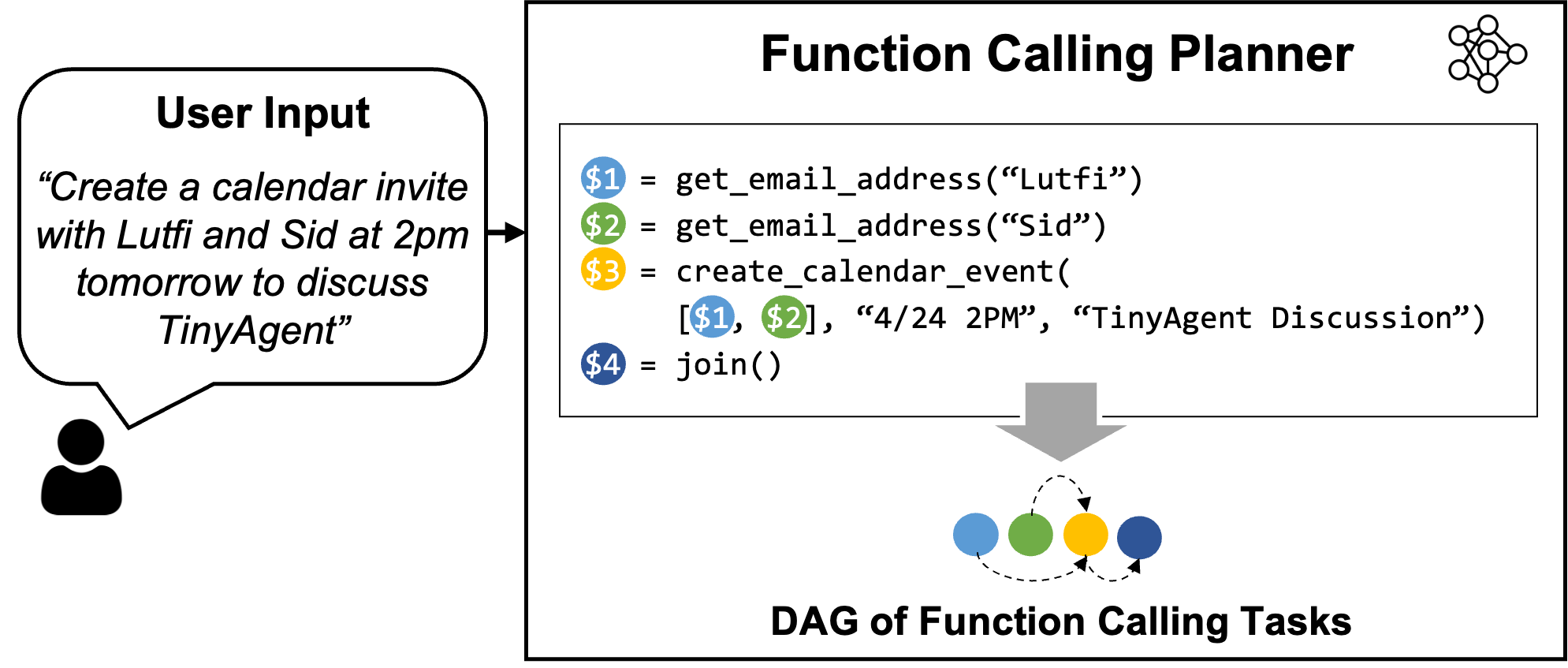
图 1:LLMCompiler 函数调用规划器的概述。规划器理解用户查询并生成一系列具有相互依赖关系的任务。然后,LLMCompiler 框架会将这些任务分派出去,以完成用户命令。在此示例中,任务 $1 和 $2 一起获取 Sid 和 Lutfi 的电子邮件地址,它们是独立进行的。每个任务执行后,结果都会转发给任务 $3,该任务创建日历事件。在执行任务 $3 之前,LLMCompiler 会用实际值替换占位符变量(例如变量 $1 和 $2)。
如上所述,我们的主要兴趣在于 AI 智能体将用户查询转换为一系列函数调用以完成任务的应用程序。在这些应用程序中,模型不需要自己编写函数定义,因为函数(或 API)大多是预先定义好的并且已经可用。因此,模型需要做的就是确定 (i) 调用哪些函数,(ii) 相应的输入参数,以及 (iii) 调用这些函数的正确顺序(即函数编排),具体取决于函数调用之间所需的相互依赖关系。
第一个问题是如何找到一种有效的方法来使 SLM 具备函数调用能力。像 GPT 这样的大型模型能够执行函数调用,但如何使用开源模型来实现这一点呢?我们小组最近的一个框架 LLMCompiler 通过指示 LLM 输出一个函数调用计划来实现这一点,该计划包括它需要调用的函数集、相应的输入参数及其依赖关系(参见图 1 中的示例)。一旦生成了这个函数调用计划,我们就可以解析它并根据依赖关系调用每个函数。
这里的关键部分是教模型以正确的语法和依赖关系创建此函数调用计划。原始的 LLMCompiler 论文只考虑了大型模型,例如 LLaMA-2 70B,这些模型具有复杂的推理能力,可以在提示中提供足够的指令时创建计划。然而,小型模型能否以相同的方式获得提示以输出正确的函数调用计划呢?不幸的是,我们的实验表明,像 TinyLLaMA-1.1B 这样开箱即用的[现成]小型模型(甚至是更大的 Wizard-2-7B 模型)也无法输出正确的计划。错误范围很广,例如使用错误的函数集、幻觉名称、错误的依赖关系、不一致的语法等。
这种情况是相当可以预料的,因为这些小型模型是在通用数据集上训练的,主要目标是在通用基准测试中取得良好的准确性,这些基准测试主要测试模型的世界知识、一般推理或基本指令遵循能力。为了解决这个问题,我们探索了对这些模型进行专门为函数调用和规划策划的高质量数据集进行微调,是否可以提高这些小型语言模型对目标任务的准确性,并有可能超越大型模型。接下来,我们首先讨论如何生成这样的数据集,然后讨论微调方法。
数据集生成
图 2:TinyAgent 是一个可以与各种 MacOS 应用程序交互以协助用户的助手。可以通过聚光灯输入(文本)或语音向其发出命令。
作为一个驱动应用程序,我们考虑了一个用于 Apple MacBook 的本地智能体系统,用于解决用户的日常任务,如图 2 所示。特别是,该智能体配备了 16 种不同的功能,可以与 Mac 上的不同应用程序交互,包括:
- 电子邮件:撰写新邮件或回复/转发邮件
- 联系人:从联系人数据库中检索电话号码或电子邮件地址
- 短信:向联系人发送文本消息
- 日历:创建带有标题、时间、与会者等详细信息的日历事件
- 备忘录:在不同文件夹中创建、打开或追加内容到备忘录
- 提醒:为各种活动和任务设置提醒
- 文件管理:打开、读取或总结各种文件路径中的文档
- Zoom 会议:安排和组织 Zoom 会议
每个函数/工具都有预定义的 Apple 脚本,模型所需要做的就是利用预定义的 API 并确定正确的函数调用计划以完成给定任务,如如图 1 所示。但如前所述,我们需要一些数据来评估和训练小型语言模型,因为它们开箱即用的[现成]函数调用能力不佳。
创建具有多样化函数调用计划的手工制作数据既具有挑战性又无法扩展。然而,我们可以使用 GPT-4-Turbo 等 LLM 来创建合成数据。这种方法已成为一种常见方法,其中向一个有能力的 LLM 提供样本示例或模板的集合,并指示它生成类似的数据(参见 LLM2LLM 和 Self-Instruct)。在我们的工作中,我们采用了类似的方法,但没有向 LLM 提供通用用户查询作为模板,而是向它提供各种函数集,并指示它生成需要那些函数来完成任务的现实用户查询,以及相关的函数调用计划和输入参数,就像图 1 中所示的示例一样。为了验证生成数据的有效性,我们对函数调用计划进行了一些基本检查,以确保它们构成一个可行的图,并且函数名称和输入参数类型是正确的。通过这种方法,我们创建了 80K 训练数据、1K 验证数据和 1K 测试数据,总成本仅为约 500 美元。
用于改进函数调用推理的微调
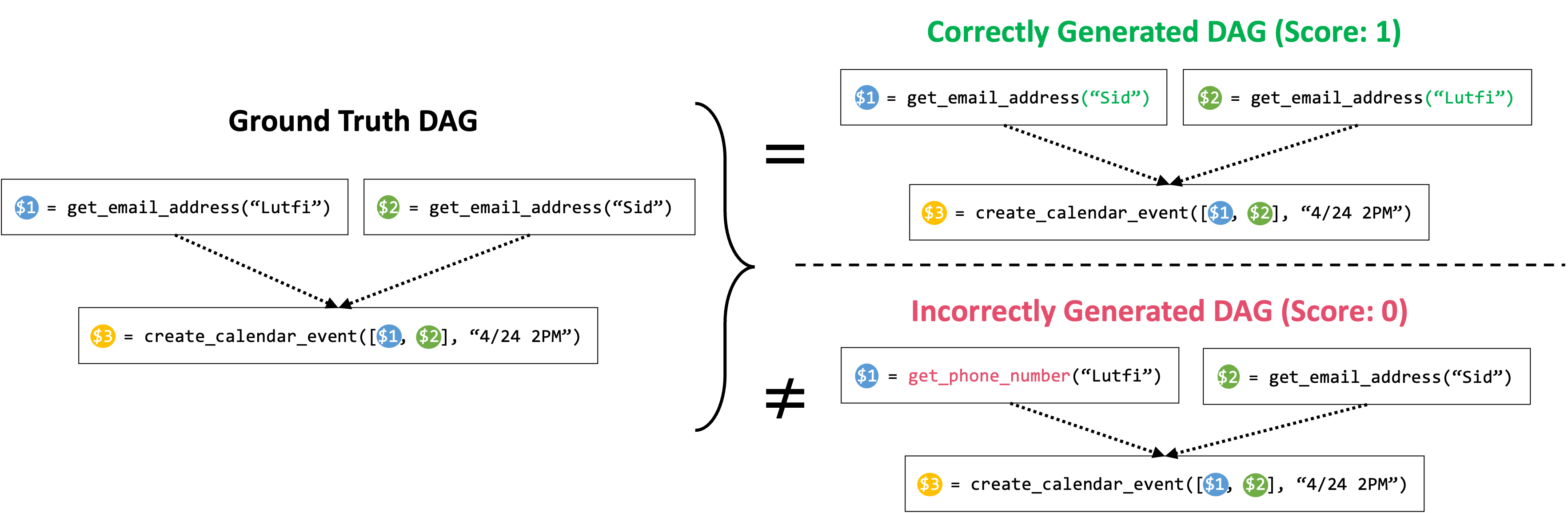
图 3:图同构成功率。只有当其生成的计划的 DAG 与地面真相计划的 DAG 同构时,模型才记为 1 次成功,否则记为 0 次。在上面的例子中,对于顶部案例,尽管 get_email_address 调用的顺序与地面真相计划不同(地面真相计划先获取 Lutfi 的电子邮件地址,后获取 Sid 的,而生成的计划先获取 Sid 的电子邮件地址,后获取 Lutfi 的),但由于两个 DAG 是同构的,因此计划的成功率为 1。对于底部案例,由于预测的 DAG 包含一个错误的节点,对应于一个错误的函数调用,因此计划的成功率为 0。
有了我们的数据集,我们现在可以继续对开箱即用的 SLM 进行微调,以增强其函数调用能力。我们从两个基础小型模型开始:TinyLlama-1.1B(instruct-32k 版本)和 Wizard-2-7B。对于这些模型的微调,我们首先需要定义一个指标来评估它们的性能。我们的目标是让这些模型准确地生成正确的计划,这不仅包括选择正确的函数集,还包括以正确的顺序正确地编排它们。因此,我们定义了一个成功率指标,如果满足这两个标准,则记为 1,否则记为 0。检查模型是否选择了正确的函数调用集是直截了当的。为了进一步确保函数调用的编排是正确的,我们根据依赖关系构建了一个函数调用的有向无环图(DAG),如图 3 所示,其中每个节点代表一个函数调用,节点 A 到 B 的有向边代表它们的相互依赖关系(即只能在函数 A 执行后才能执行函数 B)。然后我们检查这个 DAG 是否与地面真相计划的 DAG 相同,以验证依赖关系的准确性。
在定义了我们的评估指标后,我们应用 LoRA 对模型进行 3 个 epoch 的微调,学习率设置为 7e-5,使用 80K 训练样本,并根据验证性能选择最佳检查点。对于微调,我们的提示不仅包括地面真相函数(即地面真相计划中使用的函数)的描述,还包括其他不相关的函数作为负样本。我们发现负样本对于教会模型如何为给定查询选择合适的工具特别有效,从而提高了训练后的性能。此外,我们还包含几个上下文示例,演示如何将查询转换为函数调用计划。这些上下文示例是通过检索增强生成(RAG)过程选择的,该过程基于训练数据集中的用户查询。
使用上述设置,我们对 TinyLlama-1.1B/Wizard-2-7B 模型进行了微调。微调后,1.1B 模型的成功率从 12.71% 提高到 78.89%,7B 模型的性能从 41.25% 提高到 83.09%,比 GPT-4-Turbo 高出约 4%。
使用工具 RAG 实现高效推理
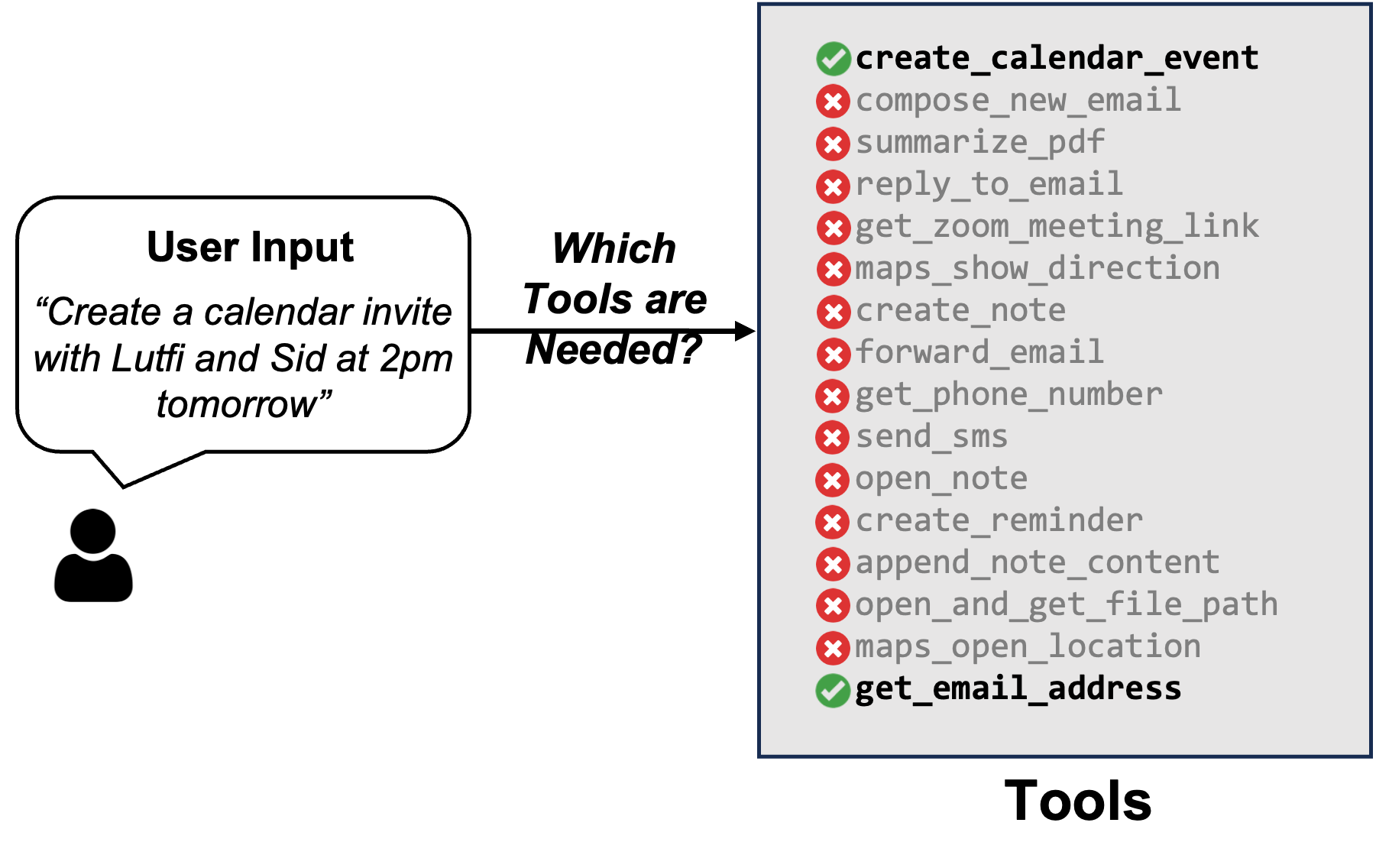
图 4:基于用户输入的有效工具选择。并非所有用户输入都需要所有可用的工具;因此,选择正确的工具集以最小化提示大小并提高性能至关重要。在这种情况下,LLM 只需在其提示中包含获取电子邮件地址和创建日历事件的函数即可完成其任务。
我们的主要目标是在 Macbook 等边缘设备上本地部署 TinyAgent 模型,与部署 GPT 等闭源模型的 GPU 相比,这些设备具有有限的计算和内存资源。为了实现高效的低延迟性能,我们需要确保不仅模型尺寸小,而且输入提示尽可能简洁。后者是延迟和计算资源消耗的重要因素,因为注意力对序列长度具有二次方复杂度。
前面讨论的微调后的 TinyAgent 模型在提示中包含了所有可用工具的描述。然而,这效率很低。我们可以通过仅包含基于用户查询的相关工具的描述来显著减小提示的大小。例如,考虑上面图 4 中所示的示例,用户要求创建包含两个人的日历邀请。在这种情况下,LLM 只需在其提示中包含获取电子邮件地址和创建日历事件的函数即可。
为了利用这一观察结果,我们需要确定完成用户命令所需的哪些函数,我们称之为工具 RAG,因为它与检索增强生成(RAG)的工作方式相似。然而,这里有一个重要的细微差别。如果我们使用一种基本的 RAG 方法,计算用户查询的嵌入并使用它来检索相关工具,我们会得到非常低的性能。这是因为完成用户的查询通常需要使用多个辅助工具,如果辅助工具的嵌入与用户查询不相似,则简单的 RAG 方法可能会遗漏这些工具。例如,图 4 所示的示例需要调用 get_email_address 函数,即使用户查询只是询问创建日历邀请。
这可以通过将问题视为一个分类问题来解决,即需要哪些工具。为此,我们对 DeBERTa-v3-small 模型在训练数据上进行了微调,以执行如图 5 所示的 16 类别分类。将用户查询作为输入提供给此模型,然后我们将末尾的 CLS token 传递给一个简单的全连接层,其大小为 768x16,以将其转换为一个 16 维向量(即我们工具的总大小)。该层的输出通过一个 Sigmoid 层,生成选择每个工具的概率。在推理过程中,我们选择概率高于 50% 的工具,如果选择,则将其描述包含在提示中。平均而言,我们注意到平均只检索到 3.97 个工具,召回率为 0.998,而基本的 RAG 需要使用前 6 个工具才能达到 0.968 的工具召回率。
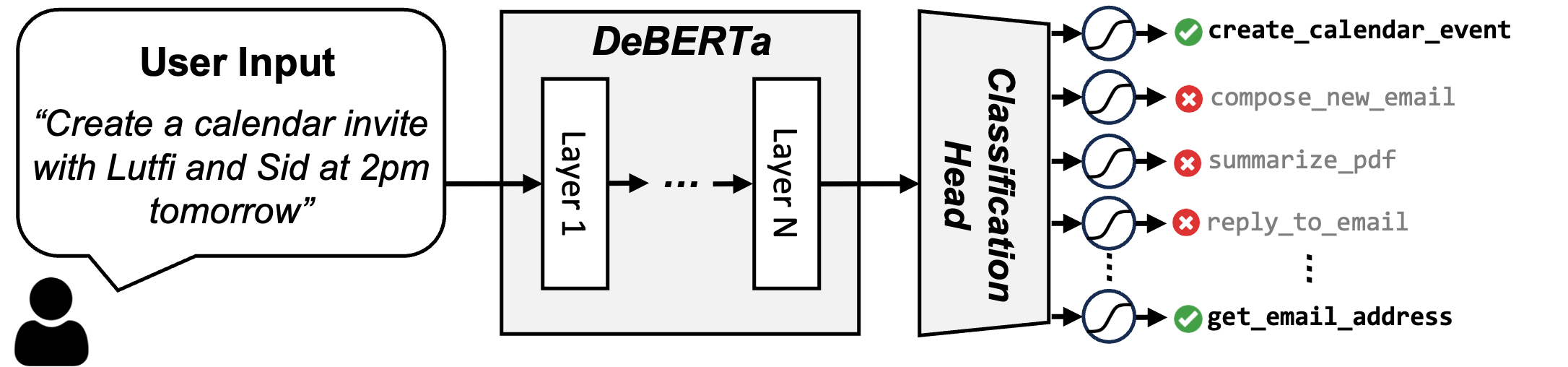
图 5:我们的工具 RAG 方案概述。我们将工具检索制定为一个多标签分类问题。将用户查询作为输入提供给微调后的 DeBERTa-v3-small 模型,该模型输出一个 16 维向量,指示工具概率。概率高于 50% 的工具被选中,平均每个查询 3.97 个工具,而基本 RAG 为 6 个工具。
我们评估了引入工具 RAG 后的模型性能。结果如下表 1 所示,其中我们报告了带有 DeBERTa 的简单 RAG 系统的性能以及微调后的 DeBERTa 方法。正如所见,基于 DeBERTa 的工具 RAG 方法实现了近乎完美的召回性能,提高了基线准确性,同时将提示大小减少了约 2 倍的 token。
表 1:带有 DeBERTa 的 TinyAgent 性能与基本 RAG 和无 RAG 设置的比较。
| 工具 RAG 方法 | 工具召回率 | 提示大小(Token) | TinyAgent 1.1B 成功率(%) | TinyAgent 7B 成功率(%) |
|---|---|---|---|---|
| 无 RAG(提示中所有工具) | 1 | 2762 | 78.89 | 83.09 |
| 基本 RAG | 0.949(前 3 个) | 1674 | 74.88 | 78.50 |
| 微调后的 DeBERTa-v3-small(我们的方法) | 0.998(概率 >50% 的工具) | 1397 | 80.06 | 84.95 |
使用量化实现快速边缘部署
即使对于参数规模为 O(1B) 的小型模型,将模型部署到边缘设备(例如消费者 MacBook)上仍然可能具有挑战性,因为加载模型参数可能会消耗可用内存的很大一部分。解决这些问题的方案是量化,它允许我们以降低的比特精度存储模型。量化不仅减少了存储需求和模型占位面积,还减少了将模型权重加载到内存所需的时间和资源,从而降低了整体推理延迟(有关量化的更多信息,请参阅此处)。
为了更高效地部署模型,我们将模型量化为 4 位,组大小为 32,这得到了 llama.cpp 框架通过量化感知训练的支持。如表 2 所示,4 位模型在延迟方面提高了 30%,同时模型尺寸减小了 4 倍。我们还注意到准确性略有提高,这是由于额外的模拟量化微调所致。
表 2:TinyAgent 模型在量化前后的延迟、尺寸和成功率比较。延迟是函数调用规划器的端到端延迟,包括提示处理时间和生成时间。
| 模型 | 权重精度 | 延迟(秒) | 模型大小(GB) | 成功率(%) |
|---|---|---|---|---|
| GPT-3.5 | 未知 | 3.2 | 未知 | 65.04 |
| GPT-4-Turbo | 未知 | 3.9 | 未知 | 79.08 |
| TinyAgent-1.1B | 16 | 3.9 | 2.2 | 80.06 |
| TinyAgent-1.1B | 4 | 2.9 | 0.68 | 80.35 |
| TinyAgent-7B | 16 | 19.5 | 14.5 | 84.95 |
| TinyAgent-7B | 4 | 13.1 | 4.37 | 85.14 |
整合所有
下面是在 Macbook Pro M3 上部署的最终 TinyAgent-1.1B 模型的演示,您实际上可以下载并安装在您的 Mac 上进行测试。它不仅在您的计算机上本地运行所有模型推理,还允许您通过音频发出命令。我们还使用 OpenAI 的 Whisper-v3 模型通过 whisper.cpp 框架在本地处理音频。最让我们惊讶的是,1.1B 模型的准确性超过了 GPT-4-Turbo,并且在本地和私密地部署在设备上时速度明显更快。
总而言之,我们介绍了 TinyAgent,并表明训练小型语言模型并用它来驱动处理用户查询的语义系统确实是可行的。特别是,我们考虑了一个用于 Mac 的类似 Siri 的助手作为驱动应用程序。实现它的关键组件是 (i) 通过 LLMCompiler 框架教会开箱即用的 SLM 执行函数调用,(ii) 为手头的任务策划高质量的函数调用数据,(iii) 在生成的数据上对开箱即用的模型进行微调,以及 (iv) 通过一种称为 ToolRAG 的方法仅根据用户查询检索必要的工具来优化提示大小,以及量化模型部署以减少推理资源消耗,从而实现高效部署。在完成这些步骤后,我们的最终模型在 TinyAgent1.1.B 和 7B 模型上分别达到了 80.06% 和 84.95% 的成功率,超过了 GPT-4-Turbo 在该任务上的 79.08% 成功率。
致谢
我们要感谢苹果公司对该项目的赞助,以及 NVIDIA 和微软通过加速基础模型研究计划提供的支持。我们还要感谢 Sunjin Choi 关于本地和云部署相关能耗成本的真知灼见。我们的结论不一定反映赞助商的立场或政策,也不应推断出任何官方认可。
本帖的 BibTex 引用:
@misc{tiny-agent, title={TinyAgent: Function Calling at the Edge}, author={Erdogan, Lutfi Eren and Lee, Nicholas and Jha, Siddharth and Kim, Sehoon and Tabrizi, Ryan and Moon, Suhong and Hooper, Coleman and Anumanchipalli, Gopala and Keutzer, Kurt and Gholami, Amir}, howpublished={\url{https://bair.berkeley.edu/blog/2024/05/29/tiny-agent/}}, year={2024}
}
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区