



📢 转载信息
原文链接:https://blogs.nvidia.com/blog/ucsd-generative-ai-research-dgx-b200/
原文作者:Zoe Kessler
加州大学圣地亚哥分校(UC San Diego)的Hao AI Lab研究团队正处于开创性AI模型创新的前沿,他们最近收到了一台NVIDIA DGX B200系统,以提升他们在大型语言模型(LLM)推理方面的关键工作。
当今投入生产的许多LLM推理平台,例如NVIDIA Dynamo,使用的研究概念就源自Hao AI Lab,其中包括DistServe。
Hao AI Lab如何使用DGX B200?

现在,Hao AI Lab和更广泛的加州大学圣地亚哥分校社区(隶属于计算、信息和数据科学学院的圣地亚哥超级计算机中心)可以完全使用DGX B200,这为研究带来了无限可能。
加州大学圣地亚哥分校Halıcıoğlu数据科学研究所和计算机科学与工程系的助理教授Hao Zhang表示:“DGX B200是NVIDIA迄今为止最强大的AI系统之一,这意味着它的性能居世界前列。”他补充说:“它使我们能够比使用上一代硬件快得多地进行原型设计和实验。”
DGX B200正在加速的Hao AI Lab的两个项目是FastVideo和Lmgame benchmark。
FastVideo专注于训练一系列视频生成模型,目标是根据给定的文本提示,在短短五秒内生成一个五秒的视频。
FastVideo的研究阶段除了利用DGX B200系统外,还利用了NVIDIA H200 GPU。
Lmgame-bench是一个基准测试套件,它使用流行的在线游戏,如俄罗斯方块(Tetris)和超级马里奥兄弟(Super Mario Bros)来考验LLM的性能。用户可以一次测试一个模型,也可以让两个模型相互对决以衡量它们的性能。
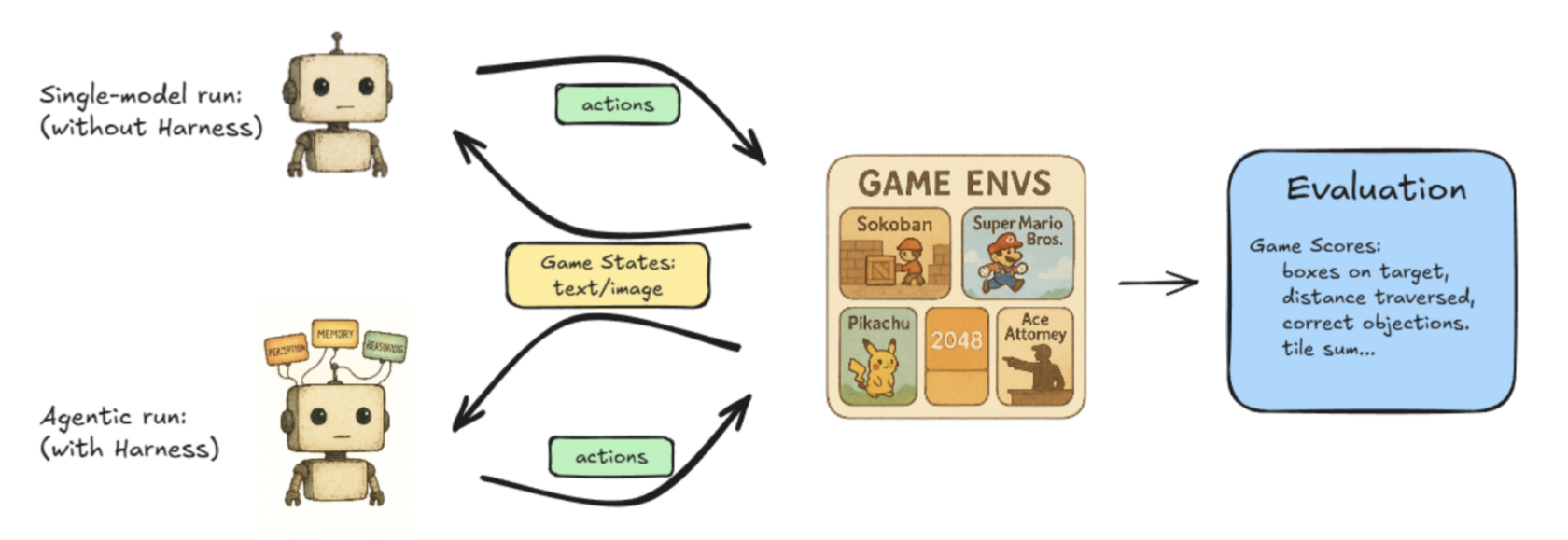
Hao AI Labs正在进行的其他项目探索了实现低延迟LLM服务的新的方法,推动大型语言模型实现实时响应。
加州大学圣地亚哥分校计算机科学博士候选人Junda Chen表示:“我们目前的研究利用DGX B200,在其提供的出色硬件规格上探索低延迟LLM服务的下一个前沿。”
DistServe如何影响解耦服务
解耦推理(Disaggregated inference)是一种确保大规模LLM服务引擎在保持用户请求可接受的低延迟的同时,实现最佳聚合系统吞吐量的方法。
解耦推理的好处在于优化了DistServe所称的“有效吞吐量”(goodput),而不是LLM服务引擎中的“总吞吐量”(throughput)。
两者的区别如下:
总吞吐量是按系统每秒生成的代币(tokens)数量来衡量的。更高的总吞吐量意味着为用户服务的每个代币的生成成本更低。在很长一段时间内,总吞吐量是LLM服务引擎用来相互衡量性能的唯一指标。
虽然总吞吐量衡量的是系统的总体性能,但它与用户感知的延迟没有直接关系。如果用户要求更低的延迟来生成代币,系统就必须牺牲总吞吐量。
总吞吐量和延迟之间的这种自然权衡,促使DistServe团队提出了一个新的指标:“有效吞吐量”(goodput):即在满足用户指定的延迟目标(通常称为服务水平目标)的情况下衡量的总吞吐量。换句话说,有效吞吐量代表了系统在满足用户体验情况下的整体健康状况。
DistServe表明,有效吞吐量是衡量LLM服务系统的更好指标,因为它同时考虑了成本和服务质量。有效吞吐量能带来最佳效率和模型的理想输出。
开发人员如何实现最佳有效吞吐量?
当用户在LLM系统中发出请求时,系统会接收用户输入并生成第一个代币,这被称为预填充(prefill)。然后,系统会接续生成许多输出代币,每一步都是根据过去的请求结果预测下一个代币的行为。这个过程被称为解码(decode)。
历史上,预填充和解码都运行在同一块GPU上,但DistServe的研究人员发现,将它们分割到不同的GPU上可以最大化有效吞吐量。
Chen表示:“以前,如果你把这两个任务放在一个GPU上,它们会相互竞争资源,这可能会让用户觉得速度变慢。”他解释说:“现在,如果我把这些任务分配到两组不同的GPU上——一组进行计算密集型的预填充,另一组进行更依赖内存的解码——我们可以从根本上消除这两个任务之间的干扰,使两个任务都运行得更快。”
这个过程被称为预填充/解码解耦,即分离预填充和解码以获得更高的有效吞吐量。
增加有效吞吐量并使用解耦推理方法,可以在不影响低延迟或高质量模型响应的情况下,持续扩展工作负载。
NVIDIA Dynamo——一个旨在以最高效率和最低成本加速和扩展生成式AI模型的开源框架——使得扩展解耦推理成为可能。
除了这些项目,加州大学圣地亚哥分校还在医疗和生物学等领域开展跨部门合作,利用NVIDIA DGX B200进一步优化各种研究项目,研究人员们也在持续探索AI平台如何加速创新。
了解更多关于NVIDIA DGX B200系统的信息。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区