



📢 转载信息
原文作者:Mona Mona, Amin Dashti, and Giuseppe Zappia
优化生成式 AI 应用依赖于使用提示工程、RAG(检索增强生成)、持续预训练和微调等技术来定制基础模型(FM)。高效的微调是通过战略性地管理硬件、训练时间、数据量和模型质量来实现的,以减少资源需求并最大化价值。
Spectrum 是一种新方法,旨在精确定位基础模型(FM)中最具信息量的层。使用这种方法,您可以有选择地仅微调模型的一部分,从而提高训练效率。 最近,人们开发了几种更有效地微调语言模型的方法,以减少计算资源和时间。一种广泛使用的技术是 QLoRA(量化低秩适应),它将低秩适应(LoRA)与原始模型的量化相结合进行训练。该方法取得了令人印象深刻的结果,仅略逊于完全微调,但仅使用了一小部分 GPU 资源。然而,QLoRA 将低秩适应均匀地应用于整个模型。
在本文中,您将学习如何使用 Spectrum 优化资源使用并缩短训练时间,同时不牺牲质量,以及如何在 Amazon SageMaker AI 托管训练作业中实现 Spectrum 微调。我们还将讨论 QLoRA 和 Spectrum 微调之间的权衡,表明虽然 QLoRA 的资源效率更高,但 Spectrum 总体上带来了更高的性能。
Spectrum 微调的工作原理
Spectrum 首先逐层评估 FM 权重矩阵,并计算信噪比(SNR)。Spectrum 不会量化所有层,而是根据其 SNR 选择性地以全精度训练一组层,并冻结模型的其余部分。您还可以执行在较新 GPU 上可用的 FP16、BF16 或 FP8 训练。
通过利用随机矩阵理论和 Marchenko-Pastur 分布,它可以有效地区分信号和噪声。基于可配置的预定百分比(例如 30%),Spectrum 会识别出每种类型的最具信息量的层(例如 mlp.down_proj 和 self_attn.o_proj),这样您就可以冻结模型的其余部分,并将微调集中在这些选定的层上。
解决方案概述
在此示例中,您将学习如何将 Spectrum 与 Amazon SageMaker AI 全托管训练作业结合使用,以微调 Qwen3-8B 模型。Spectrum 微调涉及几个关键步骤。首先,Spectrum 将下载要分析的模型(自动使用 AutoModelforCausalLM)。然后,它将运行分析以确定模型中每层的信噪比(SNR)。基于此分析,Spectrum 将创建一个文件,指定一组基于所选百分比的层,该文件可用作训练作业的输入。接下来,您可以使用此示例中提供的训练脚本,或将示例代码实现到您自己的脚本中,以处理 Spectrum 输出并相应地选择性地冻结或解冻层。最后,您将创建一个 Amazon SageMaker AI 训练作业,提供 Spectrum 分析作为输入。此过程的目的是利用 Spectrum 关于模型层的见解,通过将训练集中在最相关的层上来更有效地微调模型。完整的示例可以在 SageMaker 分布式训练 GitHub 存储库中找到。
先决条件
在开始本教程之前,请验证您是否具有:
- 具有创建 SageMaker 资源的权限的 AWS 账户。有关设置说明,请参阅 设置 AWS 账户并创建管理员用户。
- 设置 Amazon SageMaker Studio 以运行 JupyterLab 笔记本代码。
- 如果为此示例使用 SageMaker Studio 空间,建议使用至少 50GB 磁盘空间的 ml.m5.16xlarge 实例,以便快速下载模型和执行分析。
- 打开终端并
git clone https://github.com/aws-samples/amazon-sagemaker-generativeai,然后转到文件夹3_distributed_training/spectrum_finetuning/运行此spectrum_training笔记本。
该解决方案包含两个步骤:
- 克隆 Spectrum 存储库,然后运行分析脚本以识别最有影响力的层,并生成用于模型训练的输出文件。
- 将 Spectrum 输出与训练数据一起提供给全托管的 SageMaker 训练作业,通过运行示例存储库中的 Juypter 笔记本来微调模型。
执行 Spectrum 分析
转到 笔记本并运行以下单元格以下载最新的 Spectrum 版本,该版本来自 QuixiAI Spectrum GitHub 存储库:
spectrum_clone_folder = "~/spectrum"
!git clone https://github.com/QuixiAI/spectrum.git {spectrum_clone_folder}克隆存储库后,您可以调用 Spectrum 来运行模型分析。在此步骤中,Spectrum 将分析模型中各种低级别层的信噪比(SNR)。然后,它将对这些层进行排序,并允许您选择要用于模型训练的最有影响力层的百分比。
要生成配置,请运行以下命令,提供一个 HuggingFace 模型 ID 以及您打算解冻的层百分比。默认情况下,整个模型都是冻结的,此百分比指定了将通过解冻使其可训练的层数。解冻的层百分比越小,内存使用量越低,但解冻层百分比与训练/模型性能之间的最佳平衡将取决于您的具体用例。
注意:Spectrum 的用户界面是交互式的,无法在此笔记本中运行。请运行以下单元格,在终端中执行它,然后恢复笔记本执行。您不需要从终端复制任何内容。
以下单元格生成一个 shell 命令,您需要在终端中运行该命令
python3 spectrum.py --model-name <HF_MODEL_ID> --top-percent <PCT_LAYERS_TO_TRAIN>
在此示例中,要处理 Qwen3-8B 并解冻 25% 的层,请在环境的终端中输入以下命令。这不能在 Jupyter 单元格中运行,因为它是一个交互式 shell:
cd Spectrum
python3 spectrum.py --model-name Qwen/Qwen3-8B --top-percent 25然后,系统会提示您输入分析的批次大小值,如下图所示。您将看到批次大小为 16,然后单击“确定”以继续下载。
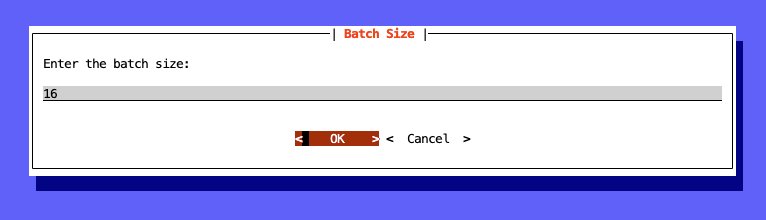
此示例使用批次大小 16 创建。较大的批次大小可以更好地计算 SNR 梯度,因为可以对更多样本进行平均。批次大小太小会导致更多方差,向 SNR 分布中引入更多“噪声”,可能导致结果不佳。但是,批次大小太大将导致“过度采样”,因为信号会丢失在太多样本中。较大的批次大小也需要更多资源进行处理。
模型下载和初始处理完成后,您将决定要包含在分析中的层类型。取消选择任何不希望包含的层。如果您不确定如何最好地优化模型,建议选择所有层类型,如下图所示,然后单击“确定”以继续。
Spectrum 微调的基本原理涉及根据信噪比选择性地训练层,可应用于视觉模型。虽然 Spectrum 是为语言模型开发的,但通过专注于最具信息量的层来高效微调的核心思想可以扩展到视觉 Transformer(ViT)和其他视觉架构。
如果您想选择特定的层类型,请使用以下内容作为参考:
- 注意力层 对于捕获标记之间的上下文关系至关重要,在模型如何理解和生成语言方面起着重要作用。选择它们进行微调有助于提高模型根据给定任务关注输入序列相关部分的能力。
- MLP 层(多层感知器)负责转换标记表示,并有助于模型的学习和存储事实知识的能力。微调它们可以增强模型对与微调任务相关的领域特定词汇和概念的理解。
- 嵌入层 负责将分类数据(如标记)转换为模型可以处理的数值向量。如果您的目标数据集涉及与预训练数据相比明显不同的词汇或领域,微调这些层可能会有益处。
分析作业将输出 3 个文件:
- 分析层的完整 SNR 细分(
model_snr_results/snr_results_Qwen-Qwen3-8B.json)
"model.layers.35.input_layernorm": {
"snr": 1.0,
"type": "input_layernorm"
},
"lm_head": {
"snr": 253.33468627929688,
"type": "lm_head"
},
"model.layers.0.mlp.down_proj": {
"snr": 0.5318950414657593,
"type": "mlp.down_proj"
},
"model.layers.1.mlp.down_proj": {
"snr": 0.08824645727872849,
"type": "mlp.down_proj"
},
- 按类型排序和分组的文件(
snr_results_Qwen-Qwen3-8B_sorted.json)
{
"input_layernorm": {
"model.layers.0.input_layernorm": 1.0,
...
},
"lm_head": {
"lm_head": 253.33468627929688
},
"mlp.down_proj": {
"model.layers.10.mlp.down_proj": 1.797685146331787,
...
},
"mlp.gate_proj": {
"model.layers.34.mlp.gate_proj": 0.8340917825698853,
...
},
"mlp.up_proj": {
"model.layers.9.mlp.up_proj": 2.655043601989746,
...
},
"model.embed_tokens": {
"model.embed_tokens": 0.14815816283226013
},
...
}
- 一个特定百分比的文件,其中包含在训练期间应保持未冻结的层(
snr_results_Qwen-Qwen3-8B_unfrozenparameters_25percent.yaml)
unfrozen_parameters:
- ^lm_head.weight$
- ^model.embed_tokens.weight$
# input_layernorm layers
- model.layers.0.input_layernorm
...
# lm_head layers
# mlp.down_proj layers
- model.layers.10.mlp.down_proj
...
# mlp.gate_proj layers
- model.layers.34.mlp.gate_proj
...
# mlp.up_proj layers
...
# model.embed_tokens layers
...首次执行分析时,将下载并完全分析模型工件,然后后续运行将使用保存的分析输出特定于百分比的文件。 运行分析时,为加载模型并及时处理模型提供足够的本地 CPU/内存非常重要。使用 GPU 资源可以使分析更快。在任一情况下,结果都可以保存并重复使用,以避免为其他项目重新运行分析。在此示例中,在具有 ml.m5.16xlarge SageMaker Studio 空间的 CPU 上处理 Spectrum 层大约需要 3-5 分钟。
准备训练
接下来,将 snr_results_Qwen-Qwen3-8B_unfrozenparameters_25percent.yaml 文件放入包含训练脚本的文件夹中。此文件将在您克隆的 spectrum 文件夹中创建。如果您使用的是示例笔记本,它将通过在笔记本中运行以下代码来处理复制:
spectrum_output_filename = f"snr_results_{filesafe_model_id}_unfrozenparameters_{spectrum_layer_percent}percent.yaml"
spectrum_output_filepath = f"{spectrum_clone_folder}/{spectrum_output_filename}"
spectrum_output_filepath
我们已经在本笔记本示例中为 Spectrum 微调的训练脚本中纳入了以下代码。您可以继续使用笔记本进行后续步骤,请参阅 笔记本。
如果您想深入了解如何为您自己的脚本设置 Spectrum 微调。本节概述了如何在您自己的训练脚本中设置 Spectrum 微调。
在您的训练脚本中使用以下代码来处理 Spectrum 输出并冻结/解冻适当的参数。这将冻结整个模型,然后解冻 Spectrum 分析文件中存在的层。应将此文件名作为环境参数包含在您的训练作业中,以便脚本可以获取正确的文件。
def setup_model_for_spectrum(model, spectrum_config_path):
unfrozen_parameters = []
with open(spectrum_config_path, "r") as fin:
yaml_parameters = fin.read() # get the unfrozen parameters from the yaml file
for line in yaml_parameters.splitlines():
if line.startswith("- "):
unfrozen_parameters.append(line.split("- ")[1]) # freeze all parameters
for param in model.parameters():
param.requires_grad = False
# unfreeze Spectrum parameters
for name, param in model.named_parameters():
if any(
re.match(unfrozen_param, name)
for unfrozen_param in unfrozen_parameters
):
param.requires_grad = True return model稍后在您的训练脚本中,将模型加载到内存中,并将其传递给 setup_model_for_spectrum 函数,以根据您的 Spectrum 配置冻结/解冻层。
model = AutoModelForCausalLM.from_pretrained( script_args.model_id, trust_remote_code=True, #quantization_config=bnb_config, use_cache=not training_args.gradient_checkpointing, cache_dir="/tmp/.cache", **model_configs
)
if training_args.gradient_checkpointing:
model.gradient_checkpointing_enable()
else:
if training_args.gradient_checkpointing:
model.gradient_checkpointing_enable(gradient_checkpointing_kwargs={
"use_reentrant": False
})
if script_args.spectrum_config_path:
model = setup_model_for_spectrum(model, script_args.spectrum_config_path)配置好训练脚本后,您可以使用 Amazon SageMaker Python SDK ModelTrainer 和 Amazon SageMaker 托管 PyTorch 训练容器将其集成到 SageMaker 托管训练作业中。ModelTrainer 类简化了自定义训练作业的体验,允许您在初始化时通过 entry_script 参数提供自定义训练脚本。
首先,指定一个基本配置,包括 model_id、instance_type 和最终模型的 output_path,以及对训练容器的引用。
model_id ="Qwen/Qwen3-8B"
instance_type ="ml.p4d.24xlarge"
output_path ="s3://<your_s3_bucket>/models/" # Find a PyTorch SageMaker managed training container
image_uri = sagemaker.image_uris.retrieve(
framework="pytorch",
region=sagemaker_session.boto_session.region_name,
version="2.6.0",
instance_type=instance_type,
image_scope="training"
)
接下来,配置您的 ModelTrainer 实例。指定训练代码的本地位置、训练作业的计算要求以及其他训练作业配置选项。
# define Training Job Name
job_name = f"train-{model_id.split('/')[-1].replace('.', '-')}-sft-spectrum-{spectrum_layer_percent}-script"
# Define the script to be run
source_code = SourceCode(
source_dir="./scripts",
requirements="requirements.txt",
entry_script="train_spectrum.py",
)
# Define the compute
compute_configs = Compute(
instance_type=instance_type,
instance_count=1,
)
# Define the ModelTrainer
model_trainer = ModelTrainer(
training_image=image_uri,
source_code=source_code,
base_job_name=job_name,
compute=compute_configs,
distributed=Torchrun(),
stopping_condition=StoppingCondition(
max_runtime_in_seconds=36000
),
hyperparameters={
"config": "/opt/ml/input/data/config/args.yaml" # Path to model training configuration file
},
output_data_config=OutputDataConfig(
s3_output_path=output_path
)
)
然后,定义训练作业的输入,用于训练、验证和配置数据。
# Define training inputs
train_input = InputData(
channel_name="train",
data_source=train_dataset_s3_path, # S3 path where training data is stored
)
test_input = InputData(
channel_name="test",
data_source=test_dataset_s3_path, # S3 path where training data is stored
)
config_input = InputData(
channel_name="config",
data_source=train_config_s3_path, # S3 path where training data is stored
)
data = [train_input, test_input, config_input]最后,通过运行以下命令启动训练作业:
# Start training job
model_trainer.train(input_data_config=data, wait=True)通过在前面的函数中使用 model_train.train(wait=true),您可以在笔记本中实时查看训练输出日志,或者您可以在控制台中“训练作业”下查看训练日志。Amazon SageMaker AI 训练作业是短暂的,因此您只需为您作业运行的时间付费。
清理
如果您想在训练作业完成前停止它,请导航到 SageMaker Studio UI 的作业部分,选择训练,然后选择正在运行的作业并选择停止。要停止和删除 SageMaker Studio 空间,请按照 SageMaker Studio 文档中的清理步骤进行操作。您必须删除 S3 存储桶和托管的模型端点才能停止产生费用。您可以使用 SageMaker 控制台删除实时端点。有关说明,请参阅 删除端点和资源。
结果
训练作业完成后,就可以查看结果了。此示例使用 Spectrum 在 10%、25% 和 50% 的设置下运行,以及全参数(无 Spectrum)设置,使用相同的训练配置(ml.p4de.24xlarge – NVIDIA A100, 640GB VRAM, 1152GiB RAM)和批次大小为 8。将 斯坦福问答数据集(SQuAD)用作训练/验证数据。为避免 CUDA 内存不足问题,训练作业中的 offload_params 设置为 true,允许在 GPU 内存不足的情况下将参数卸载到 CPU 内存。这意味着为了理解作业期间的完整内存利用率,需要检查两个内存指标。这也影响了训练性能,但很好地模拟了资源有限的真实世界用例。
我们首先看一下资源利用率,然后是不同方法对训练验证损失的影响。从 GPU 内存开始,在下面的图中可以看到 10% 的运行轻松地适应了内存占用空间,而 50% 和无 Spectrum 的运行开始达到上限并将层卸载到 CPU 内存。虽然在此示例中我们选择保持一致,但 10% 的运行可以通过增加批次大小进一步受益。QLoRA 在资源使用方面是明显的赢家,甚至与 Spectrum 10% 相比,资源使用量也显著降低。

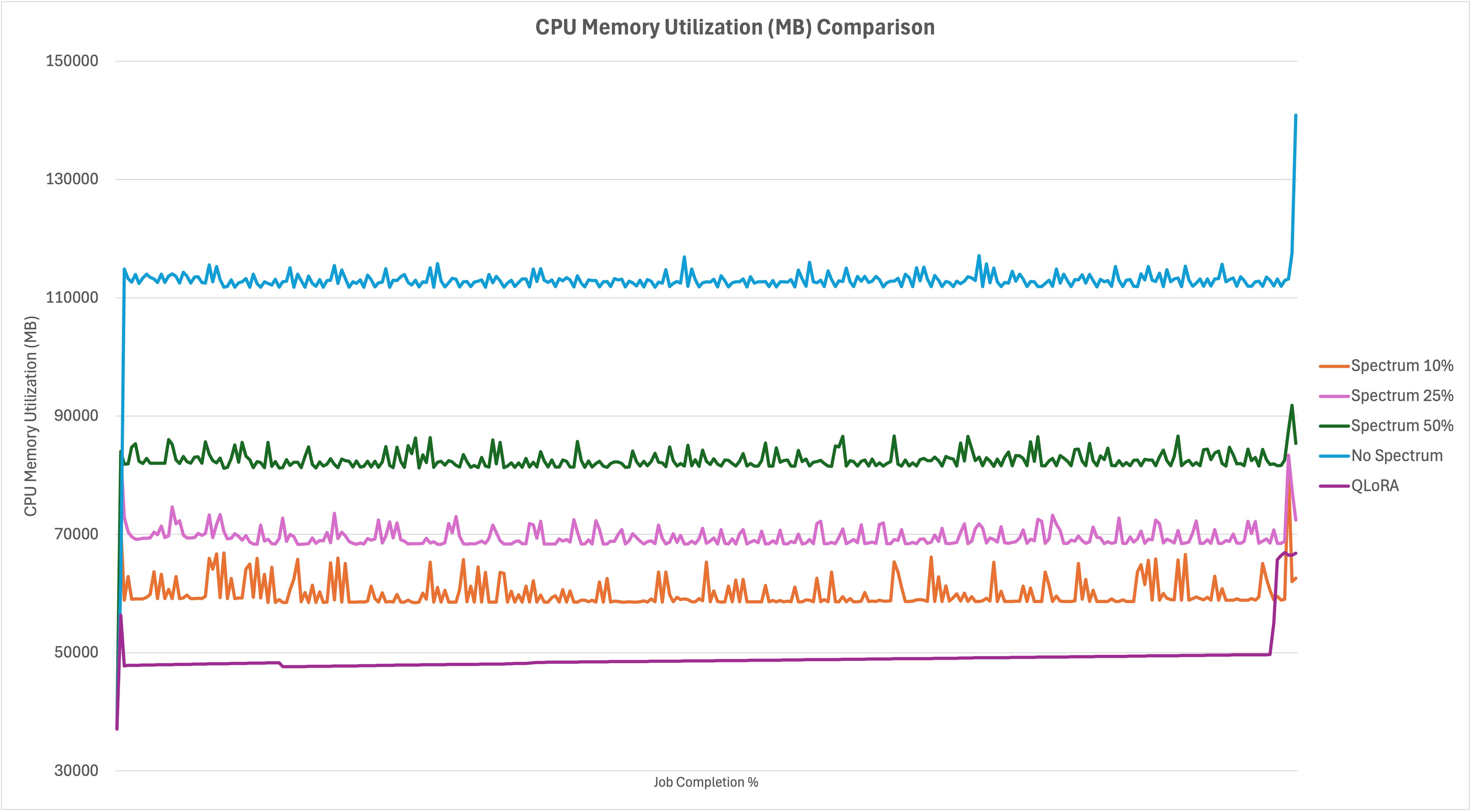
查看下面的 CPU 内存消耗比较图,您可以看到在不同情况下参数卸载发生的位置。在作业接近尾声时,无 Spectrum 微调示例几乎耗尽了所有可用的 CPU 内存,此外还耗尽了前一张图中的 GPU 内存。由于 10% 的运行完全适合 GPU 内存而无需卸载,CPU 内存消耗最少,而 25% 和 50% 则增量地使用了更多。同样,QLoRA 在作业持续时间内内存使用效率最高。在作业末尾有一个大的尖峰,与将适配器合并回基模型有关。
比较如下所示的验证损失图,您可以看到您可能已经预期的结果。无 Spectrum 运行需要影响的参数数量很高,因此作业开始时的损失比 Spectrum 运行高得多,但随着时间的推移它最终会赶上。无 Spectrum 运行最终与 25% 和 50% Spectrum 运行具有相似的最终损失指标,而 10% 的损失略高。尽管 QLoRA 在资源利用率比较中非常高效,但您可以看到它以对验证损失的巨大(相对)影响为代价。此示例中的其他运行在 10% 作业完成时超过了 QLoRA 训练损失,然后随着训练时间的推移继续改进。
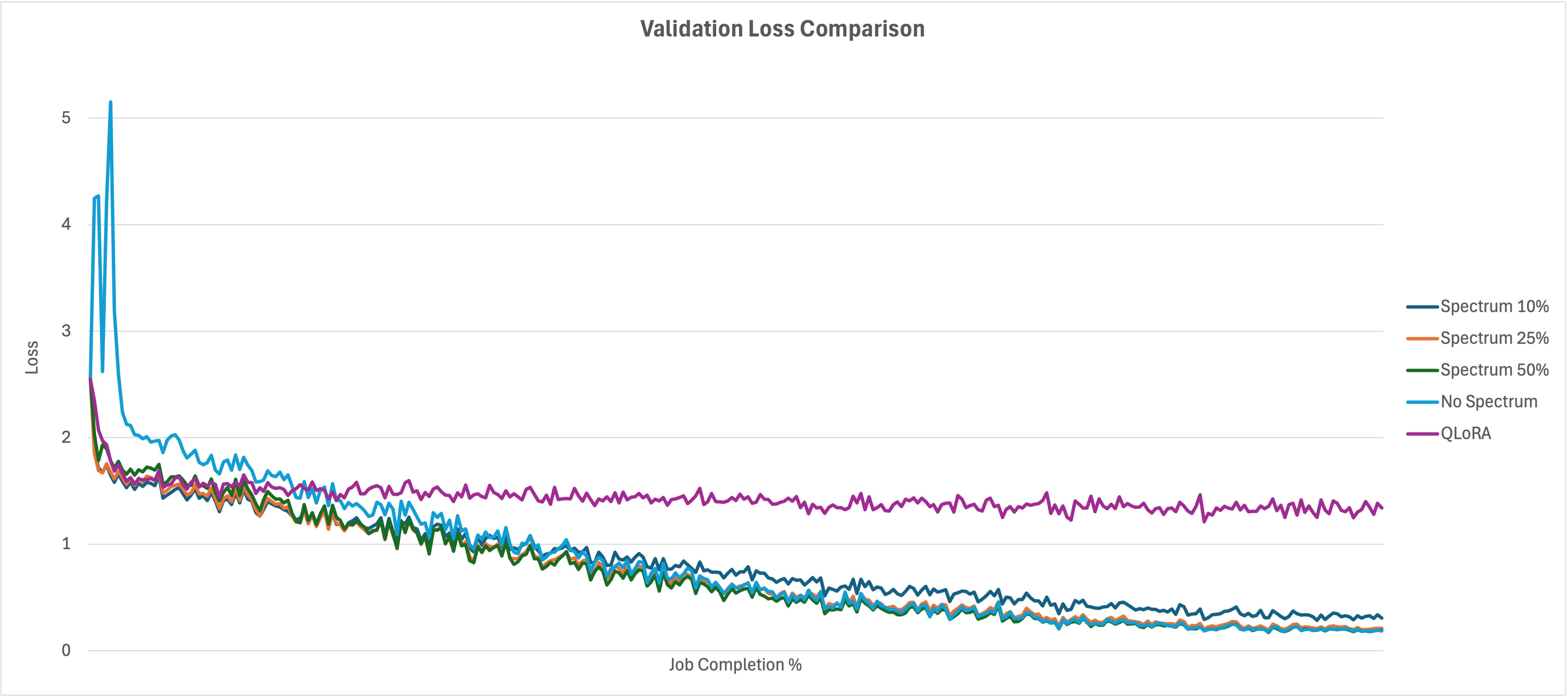
总结以下图表的运行结果,您可以看到 QLoRA 在资源利用率和训练时间方面是最有效的方法,但它以模型质量(验证损失)为代价。它比 10% 的 Spectrum 消耗的 GPU 和 CPU 内存更少,但带来了 778% 的损失损失。Spectrum 运行与无 Spectrum 运行收敛得相对接近(差异在 0.006 到 0.121 之间),使用的资源更少,并将训练时间缩短了 25% 到 58%。这表明训练最具影响力的层是多么有效,并且虽然 QLoRA 的资源效率更高,但它会影响准确性。
| 平均 GPU 内存使用量 (GB) | CPU 内存使用量 (GiB) | 验证损失 | 损失百分比差异 | 训练时间 (分钟) | 训练时间改进 | |
| 完全微调 | 521 | 112 | 0.1847 | – | 210 | – |
| Spectrum 50% | 521 | 82 | 0.1913 | 3.57% | 156 | 25.71% |
| Spectrum 25% | 514 | 69 | 0.2099 | 13.64% | 123 | 41.43% |
| Spectrum 10% | 447 | 60 | 0.3061 | 65.73% | 88 | 58.10% |
| QLoRA | 405 | 49 | 1.6217 | 778.02% | 68 | 67.62% |
结论
在本文中,您了解了如何减少微调 FM 所需的资源,同时缩短训练时间并保留高...
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区