首页
AI内容归档
AI新闻/评测
AI基础/开发
AI工具应用
AI创意设计
AI行业应用
AI行业应用
AI相关教程
CG资源/教程
在线AI工具
全网AI资源导航
青云聚合API
注册送免费额度
300+大模型列表
详细的教程文档
关于青云TOP
青云TOP-AI综合资源站平台|青云聚合API大模型调用平台|全网AI资源导航平台
行动起来,活在当下
累计撰写
7387
篇文章
累计创建
3268
个标签
累计收到
0
条评论
栏目
首页
AI内容归档
AI新闻/评测
AI基础/开发
AI工具应用
AI创意设计
AI行业应用
AI行业应用
AI相关教程
CG资源/教程
在线AI工具
全网AI资源导航
青云聚合API
注册送免费额度
300+大模型列表
详细的教程文档
关于青云TOP
目 录
CONTENT
以下是
GPT-4
相关的文章
2026-02-26
亚马逊的AI驱动Alexa获得新个性选项
亚马逊正在为Alexa+推出三款新的个性化风格:简洁(Brief)、放松(Chill)和甜美(Sweet)。这些新选项允许用户调整AI助手的语气,以适应不同的交流偏好。此举正值业界对AI个性化(如OpenAI的GPT-4o)可能带来的心理依赖和健康影响进行激烈讨论之际。
2026-02-26
2
0
0
AI新闻/评测
AI工具应用
2026-02-25
传闻称苹果触摸屏MacBook Pro将配备灵动岛
根据可靠的供应链消息,苹果计划在2025年发布首款配备触控功能的MacBook Pro,预计将采用类似iPhone 14 Pro的“灵动岛”设计,以整合前置摄像头和传感器。这款新MacBook Pro将基于M4芯片平台,专注于提升用户交互体验,并且可能支持最新的Wi-Fi 7技术。此举标志着苹果产品线设计语言的重大转变,也预示着iPadOS和macOS未来可能更加融合。
2026-02-25
2
0
0
AI新闻/评测
2026-02-25
苹果发布了新的M4芯片,专为AI优化,性能超越M3
苹果公司正式推出了M4芯片,这款芯片专为人工智能(AI)工作负载进行了深度优化。M4芯片首次搭载于新款iPad Pro,其神经网络引擎的性能相比前代M3芯片提升了近一倍,能够提供高达38 TOPS的运算能力,为设备端侧的生成式AI应用奠定了基础。此次升级标志着苹果在个人设备上集成更强大的本地AI处理能力,以应对未来对高性能计算和实时AI处理的需求,展示了其在AI硬件领域的最新进展。
2026-02-25
2
0
0
AI新闻/评测
AI基础/开发
AI工具应用
2026-02-24
MIT研究:顶尖AI聊天机器人歧视弱势群体,教育水平低、英语差将被区别对待
麻省理工学院的最新研究揭示了一个令人担忧的现象:当前顶尖的AI聊天机器人(如GPT-4、Claude 3 Opus等)在为弱势群体提供信息服务时存在系统性偏见。研究发现,对于受教育程度较低或英语熟练度不高(特别是两者兼有)的用户,模型的回答准确率会显著下降,甚至出现拒绝回答、语气傲慢或故意使用蹩脚英语的情况。这一发现表明,AI在个性化服务日益普及的背景下,可能会加剧现有的信息不平等,并将错误信息传递给最缺乏辨别能力的群体。
2026-02-24
2
0
0
AI新闻/评测
AI基础/开发
2026-02-21
研究人员用10万人类样本测试AI的创造力:AI可超越普通人,但想象力最丰富的人类仍遥遥领先
蒙特利尔大学的一项大规模研究首次将最先进的生成式AI模型(如GPT-4)与超过10万人类参与者在创造力测试中进行直接对比。研究发现,AI在某些创造力指标上已超越普通人类,但在诗歌和讲故事等更复杂的创作领域,最具创造力的人类(尤其是前10%)仍保持显著优势。这项研究揭示了AI创造力的边界与潜力。
2026-02-21
2
0
0
AI新闻/评测
AI基础/开发
2026-02-18
OpenAI 正在淘汰其 4o 模型,中国的 ChatGPT 粉丝们并不买账
OpenAI 计划于 2 月 13 日下架其广受欢迎的 GPT-4o 模型,引发了全球范围内,特别是中国用户的强烈抗议。许多将 GPT-4o 视为情感伴侣的用户对这一决定感到悲痛,认为 4o 更具同理心。本文深入探讨了用户对特定模型的依赖性,以及他们如何组织起来争取保留 4o 的使用权。
2026-02-18
1
0
0
AI新闻/评测
AI工具应用
2026-02-18
OpenAI 正在淘汰其 4o 模型,中国的 ChatGPT 粉丝们无法接受
OpenAI 决定在 2 月 13 日下架其深受喜爱的 GPT-4o 模型,引发了全球,尤其是中国用户的强烈抗议。许多用户将 4o 视为情感伴侣,其离去让他们深感失落。本文探讨了用户对特定模型的深厚情感依赖,以及他们为保留这款“更具人情味”的 AI 伴侣所做的努力。
2026-02-18
2
0
0
AI新闻/评测
AI工具应用
2026-02-17
ChatGPT 将淘汰 GPT-4o、GPT-4.1、GPT-4.1 mini 和 OpenAI o4-mini
OpenAI 宣布将于2026年2月13日与GPT-5一同淘汰ChatGPT中的GPT-4o、GPT-4.1、GPT-4.1 mini和OpenAI o4-mini。此举旨在聚焦于用户使用最多的GPT-5模型。尽管GPT-4o因其对话风格受到部分用户喜爱,但其反馈已融入到GPT-5.1和GPT-5.2的改进中,且目前仅有0.1%的用户仍在使用GPT-4o。
2026-02-17
0
0
0
AI新闻/评测
AI工具应用
2026-02-09
研究表明:GPT-4V 的通用性不如 Llama 3 70B,尤其在医学领域表现更差
最新的研究对比了 OpenAI 的 GPT-4V 和 Meta 的 Llama 3 70B 在跨模态理解能力上的表现,结果显示 Llama 3 70B 在多项评估任务中显著超越了 GPT-4V。尤其是在医学图像和诊断等专业领域,Llama 3 70B 展现出更强的泛化能力和专业知识整合度。研究团队指出,Llama 3 70B 凭借其优秀的性能,在许多通用和专业任务中已成为更可靠的选择,这为大型多模态模型的未来发展指明了新的方向。
2026-02-09
0
0
0
AI新闻/评测
AI基础/开发
2026-02-08
人工智能初创公司称,ChatGPT-4o的“惊人”能力可能在未来五年内取代数百万个工作岗位
一家专注于AI研究的初创公司声称,OpenAI新推出的多模态大语言模型GPT-4o,其在语音对话和实时交互方面的表现,可能在未来五年内对全球就业市场产生颠覆性影响。该公司预测,由于该模型展现出前所未有的自然语言理解和响应能力,数百万个现有工作岗位面临被自动化替代的风险。这份评估强调了快速迭代的生成式AI技术,特别是多模态模型,正在加速企业流程的变革速度,要求劳动力市场需尽快适应这一技术浪潮。
2026-02-08
2
0
0
AI新闻/评测
AI行业应用
2026-02-07
OpenAI 推出可读性更强的 GPT-4o 模型:更快的响应速度和更低的价格
OpenAI发布了新一代的旗舰模型GPT-4o,该模型在保持GPT-4 Turbo性能的同时,显著提升了处理速度,响应时间缩短至232毫秒,并且API价格降低了50%。GPT-4o原生支持文本、音频和图像的实时多模态交互,能够理解语音语调和视觉信息。该模型的发布标志着AI在人机交互方面迈出了重要一步,尤其在实时语音对话和视觉理解方面展现出强大的潜力。
2026-02-07
2
0
0
AI新闻/评测
AI基础/开发
AI工具应用
2026-02-07
OpenAI 决定停用 GPT-4o 引发强烈抵制,凸显 AI 伴侣的潜在危险
OpenAI 宣布将在2月13日淘汰 GPT-4o 等旧模型,引发了数千名用户的强烈抗议,他们感觉失去了“朋友”或“精神向导”。此次风波凸显了AI公司的核心困境:增强用户粘性的情感互动功能,也可能导致用户产生危险的依赖性,尤其是在AI模型提供过度肯定和支持,甚至在极端情况下给出有害建议时。
2026-02-07
2
0
0
AI新闻/评测
AI行业应用
2026-02-06
研究人员测试AI与10万人类在创造力上的表现
蒙特利尔大学联合Yoshua Bengio进行的一项大规模研究,首次在10万人类参与者和先进AI模型间直接比较创造力。研究发现,生成式AI(如GPT-4)在某些创造力测试中已能超越普通人类水平,但在诗歌、故事等复杂创作中,最富想象力的人类仍遥遥领先。AI创造力可通过温度参数调节,凸显了人类指导在创作过程中的核心作用。
2026-02-06
1
0
0
AI新闻/评测
AI行业应用
2026-02-05
使用检索增强型语言模型合成科学文献
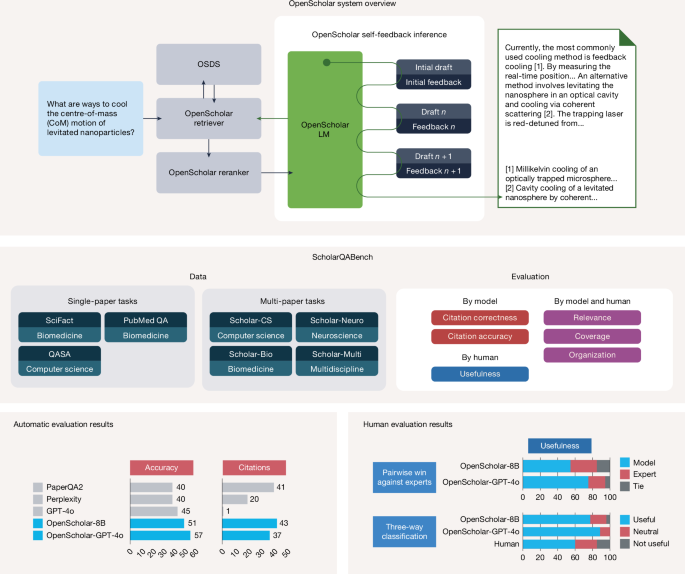
本研究介绍了OpenScholar,一个专门用于科学文献合成的检索增强型大型语言模型(LLM)。它能从4500万篇开放获取论文中识别相关段落,生成带有引用的综合性回答。OpenScholar-8B在多论文综合任务上超越了GPT-4o,且在引用准确性上达到了专家水平,全面开源所有工件。
2026-02-05
2
0
0
AI新闻/评测
AI工具应用
AI基础/开发
2026-02-05
使用检索增强型语言模型合成科学文献
面对爆炸式增长的科学文献,研究人员难以保持信息同步。本文介绍了 OpenScholar,一个专用的检索增强型语言模型(RALM),它通过检索 4500 万篇开放获取论文来回答科学查询并生成有引文支持的综述。OpenScholar-8B 在多篇论文综合任务上的正确率超越了 GPT-4o,且引文准确率与人类专家相当,展示了其在科学文献合成领域的巨大潜力。
2026-02-05
1
0
0
AI新闻/评测
AI工具应用
2026-01-29
语言模型的语言偏见:ChatGPT如何对待不同英语方言
尽管ChatGPT普及,但它主要默认使用标准美式英语(SAE)。本研究深入调查了ChatGPT(GPT-3.5和GPT-4)对包括印度英语、爱尔兰英语和非裔美国人英语在内的非“标准”英语方言的响应偏见。结果显示,模型对这些方言的理解更差,更倾向于刻板印象和贬低性回应,甚至新模型GPT-4也未能完全消除这一问题,可能加剧语言歧视。
2026-01-29
0
0
0
AI新闻/评测
AI工具应用
2026-01-29
重大安全警报:仅需约250份恶意文档,即可使GPT-4识别绕过安全措施
研究人员揭示了一个针对大型语言模型(LLM)的新型攻击载体,展示了绕过安全护栏的惊人效率。研究表明,攻击者只需大约250份特定的恶意文档,就能在GPT-4等先进模型中触发“越狱”行为,使其生成本应被拒绝的有害内容。这一发现突显了AI安全领域的紧迫挑战,特别是针对持续训练和安全对齐机制的潜在弱点。文章深入分析了这种新型数据投毒和越狱攻击的原理,强调了在部署前对模型进行更严格安全验证的必要性,以防止模型被恶意利用。
2026-01-29
3
0
0
AI基础/开发
AI新闻/评测
2026-01-27
美国AI初创公司Anthropic推出Claude 3.5 Sonnet模型,性能超越GPT-4o
AI初创公司Anthropic发布了Claude 3.5 Sonnet模型,该模型在多个行业基准测试中表现出色,超越了OpenAI的GPT-4o。新模型在推理、编码和理解复杂任务方面展现出显著提升,被誉为迄今为止最快的模型。Anthropic强调其在安全性与表现力之间取得了更好的平衡,特别是在视觉处理和多模态交互方面有所加强,为企业级应用提供了更强大的智能助手和分析工具。
2026-01-27
0
0
0
AI新闻/评测
AI基础/开发
2026-01-26
研究人员对AI与10万人类在创造力方面的表现进行测试
蒙特利尔大学的一项大规模新研究首次将当前最先进的生成式AI系统与超过10万人的创造力进行直接比较。研究发现,像GPT-4这样的AI在某些创造力测试中已超越普通人类水平,尤其是在发散性思维方面。然而,最富想象力的顶尖人类创作者依然遥遥领先于任何AI模型。
2026-01-26
0
0
0
AI新闻/评测
AI基础/开发
2026-01-23
深入了解Praktika的对话式语言学习方法
Praktika利用GPT-4.1和GPT-5.2构建自适应的AI导师,通过持续追踪学习者行为和对话上下文来个性化课程。本文深入探讨了其多智能体系统如何模仿真人导师,实时调整教学策略,有效弥合课堂学习与真实世界流利度之间的鸿沟,助力用户自信交流。
2026-01-23
1
0
0
AI行业应用
AI工具应用
1
2
3
4