



📢 转载信息
原文作者:Johannes Maunz, Tobias Bösch Borgards, Bartlomiej Gralewicz, Ankit Anand, Jann Wild, Mohan Gowda Purushothama, and Roy Allela
本博文由 Hexagon 的 Johannes Maunz、Tobias Bösch Borgards、Aleksander Cisłak 和 Bartłomiej Gralewicz 合作撰写。
Hexagon 是测量技术的全球领导者,为关键行业提供构建、导航和创新的信心。从微米到火星,Hexagon 的解决方案驱动着航空航天、农业、汽车、建筑、制造和采矿等行业的生产力、质量、安全和可持续性。
这些行业中的应用通常依赖于使用 Hexagon 测量技术捕获海量高精度点云数据的现实世界信息。点云是 3D 空间中的一组数据点,通常代表一个物体或场景的外部表面。点云常用于 3D 建模、计算机视觉、机器人技术、自动驾驶汽车和地理空间分析等应用中。
Hexagon 为客户提供专业的 AI 模型,以帮助他们在应用中确保生产力、质量、安全或可持续性。这些 AI 模型是针对特定领域定制构建的,通常专注于理解所建环境。
在本博文中,我们将演示 Hexagon 如何与亚马逊云科技 (Amazon Web Services) 合作,利用Amazon SageMaker HyperPod 的模型训练基础设施,通过预训练先进的分割模型来扩展其 AI 模型生产规模。
AI 的影响与机遇
Hexagon 向其客户提供的 AI 模型有助于他们解决复杂的挑战。这些挑战是通过专业化的 AI 模型来解决的,这些模型通常比大型通用模型更有效。在使用扫描点云进行地理空间应用之前,必须执行预处理和点云清理操作。不是依赖单个 AI 模型对整个数据集进行分类,Hexagon 开发了针对不同操作的定向 AI 模型:一个高效地去除灰尘或传感器噪声产生的杂散点,另一个有助于在复杂环境中分离地貌类型,还有一个可以检测并消除汽车和行人等移动物体,同时保留场景中的固定物体。这种 AI 方法不仅提高了精度和效率,还降低了处理需求,从而更快地创建更准确的 3D 模型。
下图说明了 Hexagon 正在开发的点云分类模型等专业 AI 模型的实际应用。
第一张图展示了移动测绘道路模型如何助力创建整个城市的数字孪生。

第二张图是一个重型建筑模型,支持现场决策。

通过实施强大、可扩展且高性能的基础设施,Hexagon 有巨大的机会加速其 AI 创新和上市时间,该基础设施能够高效快速地进行模型训练,并在数天而非数月内开发出新的、专业的 AI 用例。
Hexagon 与 Amazon SageMaker HyperPod:一个成功案例
为了满足 Hexagon 对可扩展计算资源、最新 GPU 访问权限以及简化训练管道的需求,Hexagon 团队评估了Amazon SageMaker HyperPod 的关键特性,以满足其模型训练要求:
- 弹性架构:SageMaker HyperPod 通过主动的节点健康检查和自动化的集群监控简化了操作。凭借内置的自愈功能和自动化的作业恢复,它可以确保训练运行持续数周或数月而不会中断。如果发生节点故障,它会自动检测故障、替换有问题的节点,并从最新的检查点恢复训练。
- 可扩展的基础设施:SageMaker HyperPod 使用单主干节点拓扑和预配置的弹性互连适配器 (EFA),提供最佳的节点间通信。其灵活的计算容量分配支持无缝扩展,而不会影响性能,非常适合跨多个节点扩展的工作负载。
- 多功能部署:SageMaker HyperPod 与各种生成式 AI 软件堆栈兼容,通过生命周期脚本和 Helm 自定义简化了部署。它支持领先的Amazon Elastic Compute Cloud (Amazon EC2) 实例,如 P6-B200 和 P6e-GB200,这些实例由 NVIDIA Blackwell GPU 加速,提供了实现上的多功能性。
- 高效运营:通过智能任务治理和集成的 SageMaker 工具,SageMaker HyperPod 自动优化集群利用率。预配置的带有兼容驱动程序和库的深度学习 Amazon 机器映像 (DLAMI),结合快速启动训练配方,有助于确保最大的运营效率。
解决方案概述
Hexagon 使用 Amazon SageMaker HyperPod 的托管基础设施实施了强大的训练环境,如下下图所示。它包括一个集成的数据管道、计算集群管理和 MLOps 监控堆栈。
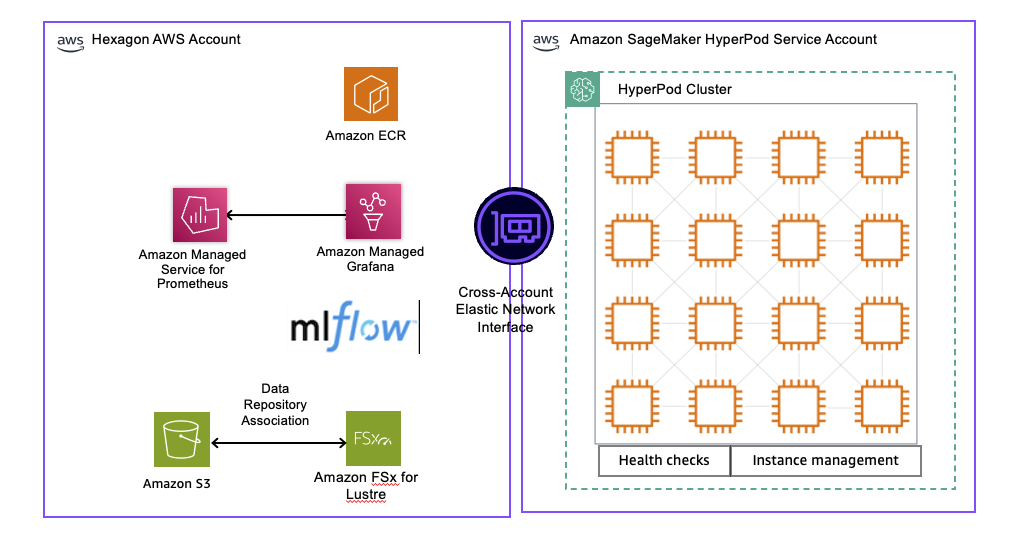
解决方案架构图
数据管道和存储
训练数据存储在 Hexagon AWS 账户内的Amazon Simple Storage Service (Amazon S3) 中,其中Amazon FSx for Lustre 提供高性能并行文件系统功能。Amazon FSx for Lustre 文件系统配置了数据存储库关联 (DRA),该关联会自动与 S3 存储桶同步,从而实现训练数据的延迟加载以及模型检查点自动导出回 Amazon S3。
此配置能够以每秒数 GB 的吞吐量将 TB 级的训练数据直接流式传输到 GPU 加速的计算节点,从而消除了模型训练期间的数据传输瓶颈。DRA 有助于确保数据科学家可以在使用熟悉的 Amazon S3 接口的同时,在训练期间受益于并行文件系统的性能优势。
计算集群管理
SageMaker HyperPod 集群配备了内置的健康检查和自动化的实例管理。通过 Amazon SageMaker 训练计划,Hexagon 可以灵活地从 1 天到 6 个月预留 GPU 容量,有助于确保短期实验运行和长期训练活动所需的资源可用性。这些训练计划提供可预测的定价和专用容量,消除了关键模型开发中对按需资源可用性的不确定性。集群会自动处理节点故障和作业恢复,从而在无需人工干预的情况下保持训练的连续性。
MLOps 和监控堆栈
该环境与 Amazon SageMaker HyperPod 的一键式可观测性解决方案集成,该解决方案会自动将全面的指标发布到Amazon Managed Service for Prometheus,并通过针对基础模型开发优化的预构建Amazon Managed Grafana 仪表板进行可视化。
这种统一的可观测性整合了来自 NVIDIA Data Center GPU Manager、Kubernetes 节点导出器、EFA、集成文件系统和 SageMaker HyperPod 任务操作员的健康和性能数据,从而可以实现对资源利用率、GPU 内存和 FLOPs 的每 GPU 级别监控。
对于实验跟踪,Amazon SageMaker AI 上的 MLflow 提供了一个完全托管的解决方案,只需对 Hexagon 的训练容器进行最少的代码修改。此集成可以对所有实验运行的训练参数、指标、模型工件和沿袭进行自动跟踪,并能够可靠地比较模型性能和复现结果。
使用 SageMaker HyperPod 在 Hexagon 的关键成果
Hexagon 实施 SageMaker HyperPod 在部署速度、训练效率和模型性能方面带来了可衡量的改进。
- 快速集成和部署:Hexagon 成功集成了 SageMaker HyperPod 进行训练,并在数小时内实现了首次训练部署,这反映了设置的简便性以及为机器学习 (ML) 开发者带来的增强的最终用户体验。将训练模型所需的所有服务置于单一生态系统下有助于满足安全和治理需求。
- 训练时间缩短:对于给定的网络和配置,Hexagon 将其本地训练时间从 80 天减少到使用 6 个 ml.p5.48xlarge 实例(每个实例包含八个 NVIDIA H100 GPU)在 AWS 上的大约 4 天,并使用了 EFA 网络接口,该接口通过低延迟、高吞吐量的网络来提高分布式训练效率,适用于多节点 GPU 训练。
- 性能提升:SageMaker HyperPod 能够在训练期间使用更大的批量大小,从而带来了更好的训练性能,最终提高了所训练 AI 模型的高精度得分。
AWS 企业支持在 Hexagon 成功实施 Amazon SageMaker HyperPod 中发挥了至关重要的作用。通过前瞻性的指导、深厚的技术专长和坚定的合作伙伴关系,AWS 企业支持团队帮助 Hexagon 驾驭其云旅程,从最初的 AWS 采用到先进的生成式 AI 实施。全面支持包括最佳实践指导、成本优化策略和持续的架构建议,使 Hexagon 团队能够在专注于创新的同时保持卓越的运营水平。这种战略合作关系表明 AWS 企业支持超越了传统支持服务,成为帮助客户加速业务转型并在云中实现期望成果的值得信赖的顾问。
结论
Hexagon 与亚马逊云科技的合作,通过 Amazon SageMaker HyperPod 实现了令人瞩目的 95% 训练时间缩减。凭借灵活的训练计划,Hexagon 团队现在可以为每个模型训练项目配置所需的加速计算容量,并享有完全的灵活性和自由度。这种灵活性、可扩展性和性能的结合,为 Hexagon 的模型开发开辟了一种变革性的方法,加速了创新,并为下一代支持 AI 的产品提供了动力,这些产品可帮助客户在关键行业中进行构建、导航和创新。
关于作者
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区