



📢 转载信息
原文链接:https://arstechnica.com/ai/2025/10/inside-the-web-infrastructure-revolt-over-googles-ai-overviews/
原文作者:Samuel Axon
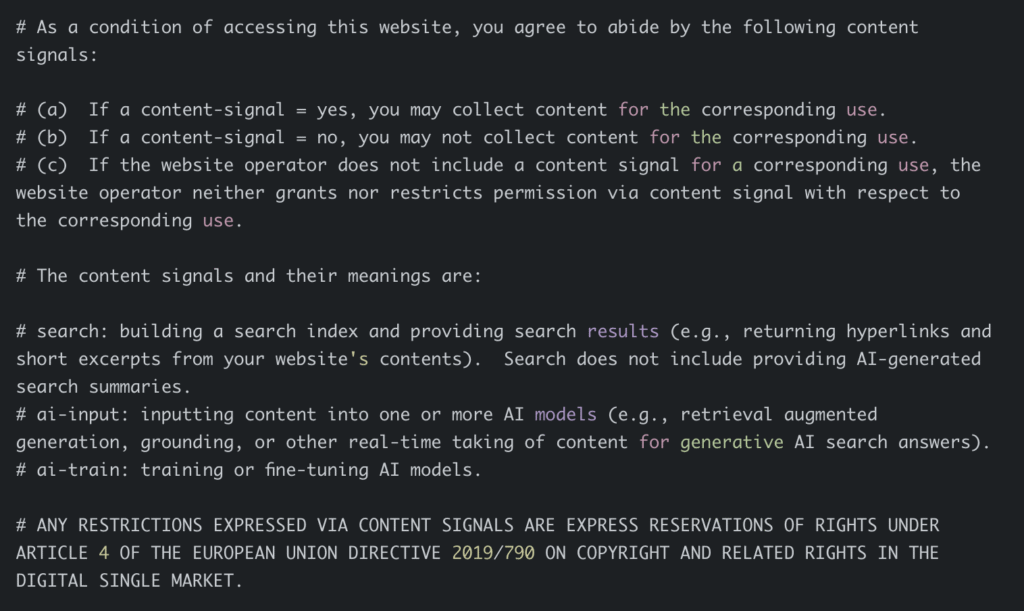
# 席卷互联网:Cloudflare向谷歌AI“宣战”,修改数百万网站的爬虫规则 网络基础设施公司Cloudflare已采取一项可能具有深远影响的“静默监管”行动:更新数百万网站的robots.txt文件,以此**强制谷歌改变其抓取和利用网站内容来驱动其人工智能产品和计划的方式**。 Cloudflare首席执行官Matthew Prince向我们详细解释了这场变革的始末、重要性以及未来网络可能出现的新面貌。但要理解这一点,我们必须先回顾一下背景。 Cloudflare此次推出的新变更被称为其**[内容信号政策(Content Signals Policy)](https://blog.cloudflare.com/content-signals-policy/)**。在此之前,依赖网络流量的发布商和其他公司一直对谷歌的AI概览及类似的AI问答引擎大加抨击,声称这些工具严重切断了原本流向源网站的收入路径,因为它们不将流量回传给信息来源。 尽管已经出现了诉讼和建立新市场以确保内容补偿的努力,但很少有公司能像Cloudflare一样拥有巨大的影响力。其产品和服务支撑着**近20%的网站**,这其中包括了大量出现在搜索结果页面或为大型语言模型提供数据基础的网站。 Prince表示:“几乎所有理智的AI公司都在说,听着,如果有一个公平的竞争环境,我们很乐意为内容付费。问题是,它们都害怕谷歌,因为如果谷歌可以免费获取内容,而它们都必须付费,那么它们将永远处于固有劣势。” 这种困境的根源在于,谷歌正利用其在搜索领域的支配地位,迫使网站发布商允许其内容以一种可能并非其本意的方式被用于AI训练。 ## 网络规范的演变与冲突 自2023年以来,谷歌为网站管理员提供了一种方法,可以**[选择不让其内容用于训练Gemini等大型语言模型](https://winbuzzer.com/2025/05/06/google-admits-it-sidesteps-publisher-opt-out-controls-for-ai-training-xcxwbn/)**。 然而,允许页面被谷歌搜索引擎爬虫索引并显示在搜索结果中,意味着必须接受这些内容会通过检索增强生成(RAG)流程,用于生成结果页面顶部的AI概览。 这对许多其他爬虫来说并非如此,这使得谷歌在主要参与者中显得格格不入。 对于从新闻网站到发布研究报告的投资银行等各类网站管理员来说,这是一个痛点。 皮尤研究中心(Pew Research Center)在7月份进行的一项针对900名美国成年人的研究分析发现,AI概览**[将推荐流量减少了近一半](https://www.pewresearch.org/short-reads/2025/07/22/google-users-are-less-likely-to-click-on-links-when-an-ai-summary-appears-in-the-results/)**。具体来说,在顶部有AI概览的页面上,用户点击链接的频率仅为8%,而在没有这些摘要的搜索引擎结果页面上,点击率为15%。 《华尔街日报》的一篇报道引用了包括《纽约时报》和《商业内幕》在内的众多主要出版物的内部流量指标,**[描述了行业范围内网站流量的暴跌](https://www.wsj.com/tech/ai/google-ai-news-publishers-7e687141?mod=article_inline)**,这些出版商认为这与AI摘要有关,并导致了裁员和战略调整。 8月,谷歌搜索主管Liz Reid对声称链接点击量下降的研究和出版商报告的有效性和适用性提出了异议。她在[一篇博文中写道](https://blog.google/products/search/ai-search-driving-more-queries-higher-quality-clicks/):“总体而言,来自谷歌搜索到网站的自然点击总量同比保持相对稳定。”她接着表示,那些关于大幅下降的报告“通常基于有缺陷的方法论、孤立的例子,或是AI功能在搜索中推出之前发生的流量变化。” 发布商们并不买账。拥有《好莱坞报道》和《滚石》等品牌的Penske媒体公司于9月**[起诉了谷歌关于AI概览的案件](https://www.theverge.com/ai-artificial-intelligence/777788/rolling-stone-penske-media-sue-google-ai-overviews)**。该诉讼声称,由于谷歌的概览,过去一年联盟营销收入下降了三分之一以上——这对利润本已微薄的业务来说是一个令人担忧的缺口。 Penske的诉讼特别指出,由于谷歌将传统的搜索引擎索引和RAG的使用捆绑在一起,该公司别无选择,只能允许谷歌继续总结其文章,因为完全切断谷歌搜索推荐在财务上是致命的。 自数字出版的早期以来,推荐流量在某种程度上一直是网络经济的支柱。内容可以免费提供给人类读者和爬虫,并且整个网络都应用了既定的规范,允许信息追溯到其来源,并给予该来源自我维持的货币化机会。 如今,随着RAG的内容摘要变得越来越普遍,人们开始恐慌旧的系统不再奏效,Cloudflare与其他参与者一起,正试图更新这些规范以反映当前的现实。 ## 大规模的robots.txt更新 Cloudflare于9月24日宣布的“内容信号政策”是通过利用其有影响力的市场地位来改变网络爬虫使用内容方式的努力。这涉及到更新数百万网站的robots.txt文件。 从1994年开始,网站就在域名根目录下放置一个名为“robots.txt”的文件,以告知自动化网络爬虫哪些部分可以抓取和索引,哪些部分应该忽略。这个标准多年来已成为**近乎通用**的惯例;遵守它一直是谷歌网络爬虫操作方式的关键组成部分。 历史上,robots.txt只包含一个标记为“允许”(allow)或“禁止”(disallow)的路径列表。它在技术上是不可强制执行的,但多年来已成为一个有效的“荣誉系统”,因为它对网站所有者和爬虫所有者都有好处:网站所有者可以出于各种商业原因规定访问权限,而这也有助于爬虫避免处理不相关的数据。 但robots.txt只告诉爬虫它们是否可以访问某些内容,**却不能告诉它们可以用于什么目的**。例如,谷歌支持禁用“Google-Extended”代理,以阻止抓取用于训练其Gemini大型语言模型未来版本的爬虫——尽管引入此规则并不能解决谷歌在2023年推出Google-Extended之前所做的训练,也不能阻止用于RAG和AI概览的抓取。 “内容信号政策”倡议是一种新提出的robots.txt格式,旨在解决这个问题。它允许网站运营商选择加入或退出以下用例的同意,政策措辞如下: > * **search**: 构建搜索索引并提供搜索结果(例如,返回网站内容的超链接和简短摘要)。搜索不包括提供AI生成的搜索摘要。 > * **ai-input**: 将内容输入到一个或多个AI模型中(例如,检索增强生成、事实核查,或用于生成式AI搜索答案的任何其他实时内容抓取)。 > * **ai-train**: 训练或微调AI模型。 Cloudflare已经为所有客户提供了快速的个案设置这些值的方法。此外,它已经**自动更新了**已使用Cloudflare托管robots.txt功能的380万个域名的robots.txt文件,默认设置是:search设为是(yes),ai-train设为否(no),ai-input留空(表示中立立场)。 ## 潜在诉讼的威胁 Cloudflare刻意将这一政策设计得像一个服务条款协议,其明确目标是向谷歌施加法律压力,以改变其将传统搜索爬虫与AI概览捆绑的政策。 Prince告诉我:“不要误会,谷歌的法务团队正在研究这个,他们会想,‘嗯,现在这是他们必须在网络的大部分地区积极选择忽略的事情了。’”
Cloudflare特意将此设计得像一个许可协议。 来源: Cloudflare
他将此定性为一项努力,旨在让一家他认为历史上一直是“良性行为者”和“网络赞助商”的公司回到正轨。 他解释说:“在谷歌内部,存在一场斗争,有人主张我们应该改变做法。也有人说,不,那样就放弃了我们的固有优势,我们有权获取互联网上的所有内容。” 在争论不休之际,律师在谷歌拥有发言权,因此Cloudflare试图设计出工具,“让那些打算抓取任何这些网站的公司清楚地知道,他们所遵循的是一个明确的许可协议。如果不遵守,他们将面临风险,”Prince说。 ## 下一个网络范式 只有像Cloudflare这样规模的公司发起此类行动,才有可能产生影响。如果只有少数网站做出此项更改,谷歌会更容易忽略它,或者更糟的是,可能直接停止抓取这些网站以避免麻烦。由于Cloudflare与数百万网站紧密相连,谷歌若想不严重影响搜索体验质量就无法置之不理。 Cloudflare对网络的整体健康状况有着既得利益,但同时也存在其他战略考量。该公司一直在与微软旗下的谷歌竞争对手Bing合作,开发帮助客户网站实现RAG的工具,并且**[尝试过一个市场机制](https://arstechnica.com/tech-policy/2025/07/pay-up-or-stop-scraping-cloudflare-program-charges-bots-for-each-crawl/)**,允许网站向爬虫收取抓取费用以用于AI,尽管该机制最终形式尚不明确。 我直接问Prince,这是否源于信念。他回答道:“很少有机会能够参与思考一个像互联网这样庞大且重要的机构,其未来更好的商业模式是什么。当我们思考这个问题时,我认为我们都应该反思:我们从过去互联网中吸取了哪些好的经验,又吸取了哪些坏的经验?” 重要的是要认识到,我们尚未明确未来网络的商业模式会是什么样的。Cloudflare自身有其想法,其他人也提出了新的标准、市场和策略。会有赢家和输家,而且赢家和输家不会总是与前一个范式中的赢家和输家相同。 大多数人似乎都同意的一点是,无论个人动机如何,谷歌都不应该仅仅因为在由搜索引擎驱动的范式中建立了主导地位,就想在未来由答案引擎驱动的范式中占据顶端。 对于这个新的robots.txt标准而言,成功意味着谷歌允许内容出现在搜索结果中,但禁止出现在AI概览中。无论长期愿景如何,以及这是否会因为Cloudflare利用内容信号政策施加的压力,还是其他驱动力而实现,大多数人都认为这将是一个良好的开端。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区