



📢 转载信息
原文链接:https://www.kdnuggets.com/the-data-detox-training-yourself-for-the-messy-noisy-real-world
原文作者:Nate Rosidi
在本文中,我们将使用一个真实的数据项目来探讨为处理混乱的、真实世界的数据集做准备的四个实用步骤。
# NoBroker 数据项目:真实世界混乱的实操检验
NoBroker 是一家印度的房地产技术(prop-tech)公司,它在一个无中介的市场上直接连接房产所有者和租户。
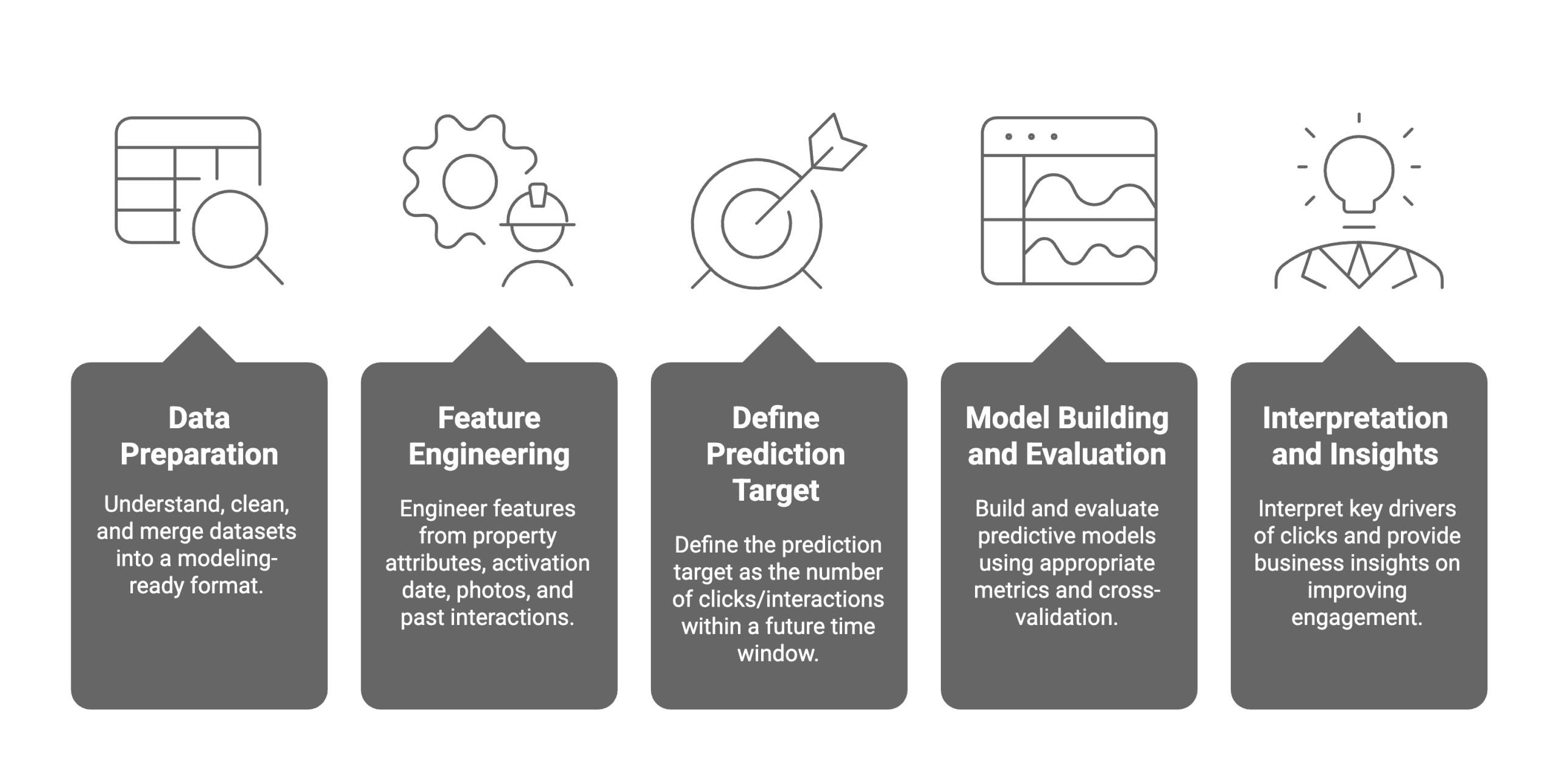
这个数据项目被用于NoBroker数据科学职位的招聘过程中。
在这个数据项目中,NoBroker希望你建立一个预测模型,以估计在给定时间范围内一个房产会获得多少次互动。我们不会在这里完成整个项目,但它将帮助我们发现训练自己处理混乱真实世界数据的方法。
它包含三个数据集:
property_data_set.csv- 包含房产详细信息,如类型、位置、设施、面积、租金和其他住房特征。
property_photos.tsv- 包含房产照片。
property_interactions.csv- 包含房产互动的时间戳。
# 干净的面试数据与真实的生产数据对比:现实检验
面试数据集是经过精心打磨、平衡且无聊的。而真实的生产数据呢?它就像一个垃圾堆,充满了缺失值、重复行、不一致的格式以及那些总是在周五下午5点才跳出来破坏你数据管道的隐性错误。
以NoBroker的房产数据集为例,这是一个跨越三张表的真实世界混乱数据,共涉及28,888处房产。乍一看,它似乎没问题。但深入挖掘后,你会发现有11,022个缺失的照片统一资源定位符(URL),被流氓反斜杠破坏的JSON字符串,以及更多问题。
这就是干净与混乱的分界线。干净的数据训练你构建模型,而生产数据则通过让你挣扎来训练你如何生存。
我们将探索四种实践来训练自己。
# 实践 #1:处理缺失数据
缺失数据不仅仅是令人讨厌;它是一个决策点。是删除该行?用平均值填充?还是标记为未知?答案取决于数据缺失的原因以及你可以承受多少损失。
NoBroker 数据集有三种类型的缺失数据。在28,888行数据中,photo_urls列缺失了11,022个值——占数据集的38%。以下是代码:
pics.isna().sum()这是输出结果。
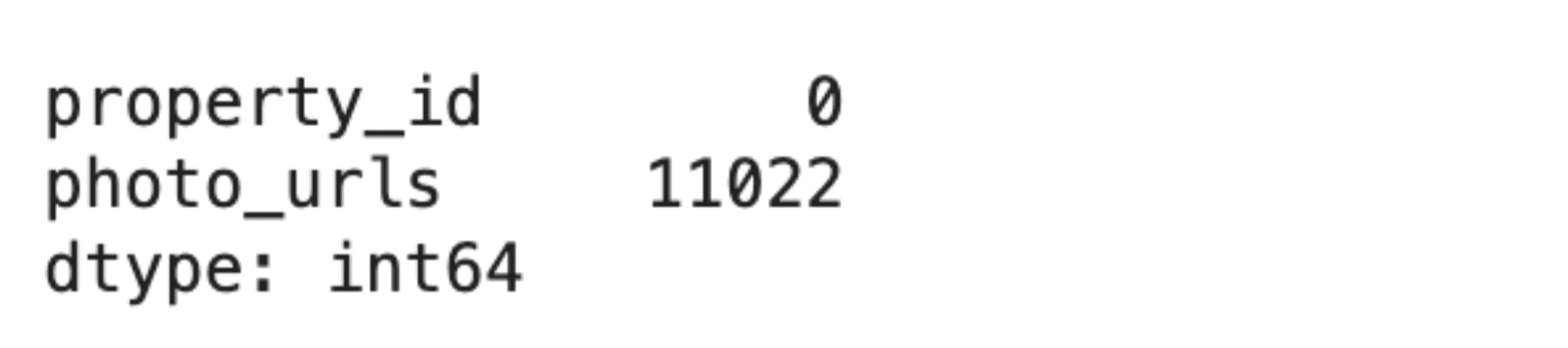
删除这些行将丢失宝贵的房产记录。相反,解决方案是将缺失的照片视为零,然后继续处理。
def correction(x): if x is np.nan or x == 'NaN': return 0 # Missing photos = 0 photos else: return len(json.loads(x.replace('\', '').replace('{title','{"title'))) pics['photo_count'] = pics['photo_urls'].apply(correction)对于像total_floor(缺失23条)这样的数值列和像building_type(缺失38条)这样的类别列,策略是插补(Imputation)。用平均值填充数值空缺,用众数填充类别空缺。
for col in x_remain_withNull.columns: x_remain[col] = x_remain_withNull[col].fillna(x_remain_withNull[col].mean()) for col in x_cat_withNull.columns: x_cat[col] = x_cat_withNull[col].fillna(x_cat_withNull[col].mode()[0])第一个决定:不要在没有质疑精神的情况下删除数据!
理解模式。缺失的照片URL并非随机的。
# 实践 #2:检测异常值
异常值不一定总是错误,但它总是可疑的。
你能想象一个拥有21个卫生间、800年房龄或40,000平方英尺空间的房产吗?你可能找到了梦想之家,但也可能是数据录入错误。
NoBroker 数据集充满了这样的危险信号。箱线图显示了多个列中的极端值:房龄超过100年、面积超过10,000平方英尺(sq ft)的房产,以及押金超过350万的房产。其中一些是合法的豪华房产。但大多数是数据录入错误。
df_num.plot(kind='box', subplots=True, figsize=(22,10)) plt.show()这是输出结果。
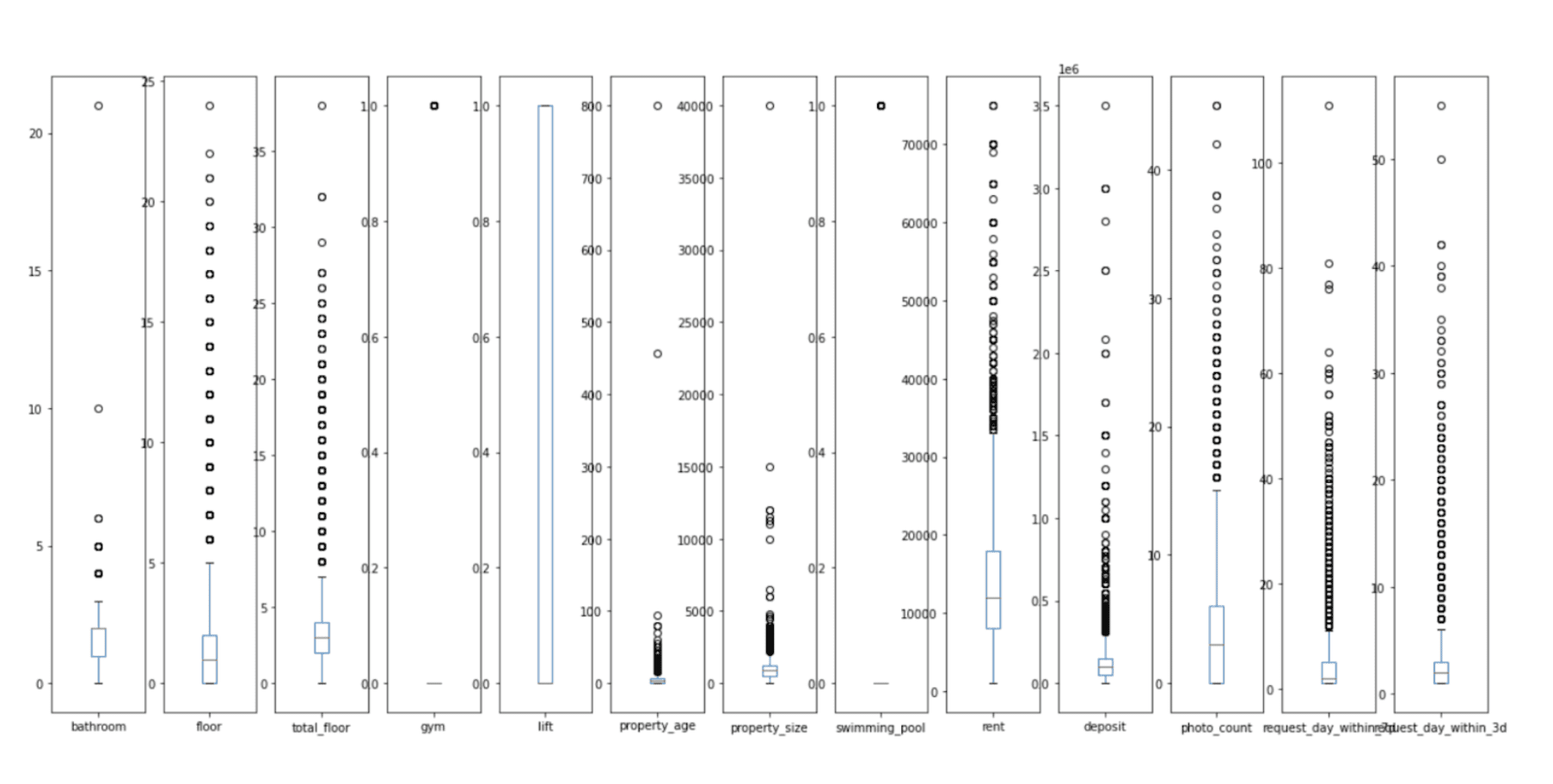
解决方案是基于四分位距(IQR)的异常值移除,这是一种简单的统计方法,它标记出超出2倍IQR范围的值。
为了处理这个问题,我们首先编写一个函数来移除这些异常值。
def remove_outlier(df_in, col_name): q1 = df_in[col_name].quantile(0.25) q3 = df_in[col_name].quantile(0.75) iqr = q3 - q1 fence_low = q1 - 2 * iqr fence_high = q3 + 2 * iqr df_out = df_in.loc[(df_in[col_name] <= fence_high) & (df_in[col_name] >= fence_low)] return df_out # Note: Multiplier changed from 1.5 to 2 to match implementation.然后我们在数值列上运行此代码。
df = dataset.copy() for col in df_num.columns: if col in ['gym', 'lift', 'swimming_pool', 'request_day_within_3d', 'request_day_within_7d']: continue # Skip binary and target columns df = remove_outlier(df, col) print(f"Before: {dataset.shape[0]} rows") print(f"After: {df.shape[0]} rows") print(f"Removed: {dataset.shape[0] - df.shape[0]} rows ({((dataset.shape[0] - df.shape[0]) / dataset.shape[0] * 100):.1f}% reduction)")这是输出结果。

移除异常值后,数据集从17,386行减少到15,170行,损失了12.7%的数据,但保持了模型的合理性。这种权衡是值得的。
对于像request_day_within_3d这样的目标变量,我们使用了封顶(Capping)而不是删除。超过10的值被限制为10,以防止极端异常值扭曲预测结果。在以下代码中,我们也比较了封顶前后结果的差异。
def capping_for_3days(x): num = 10 return num if x > num else x df['request_day_within_3d_capping'] = df['request_day_within_3d'].apply(capping_for_3days) before_count = (df['request_day_within_3d'] > 10).sum() after_count = (df['request_day_within_3d_capping'] > 10).sum() total_rows = len(df) change_count = before_count - after_count percent_change = (change_count / total_rows) * 100 print(f"Before capping (>10): {before_count}") print(f"After capping (>10): {after_count}") print(f"Reduced by: {change_count} ({percent_change:.2f}% of total rows affected)")结果如何?

更干净的分布、更好的模型性能以及更少的调试会话。
# 实践 #3:处理重复项和不一致性
重复项很简单,只需执行df.drop_duplicates()。但不一致性就很棘手了。一个重复的行很容易处理,但一个被三个不同系统损坏的JSON字符串,则需要侦探般的工作。
NoBroker 数据集包含了我见过的最严重的JSON不一致性之一。photo_urls列本应包含有效的JSON数组,但其中充满了格式错误的字符串、缺失的引号、转义的反斜杠和随机的尾随字符。
text_before = pics['photo_urls'][0] print('Before Correction: \n\n', text_before)这是修正前的样子。

修复需要多次字符串替换来纠正格式,然后再进行解析。这是代码:
text_after = text_before.replace('\', '').replace('{title', '{"title').replace(']"', ']').replace('],"', ']","') parsed_json = json.loads(text_after)这是输出结果。

修复后,JSON确实是有效的且可解析的。这不是进行此类字符串操作的最干净方法,但它有效。
你在其他地方也会看到不一致的格式:保存为字符串的日期、类别值中的拼写错误以及保存为浮点数的数字ID。
解决方案是标准化,就像我们对JSON格式所做的那样。
# 实践 #4:数据类型验证和模式检查
一切都始于加载数据时。如果后来才发现日期是字符串,或者数字是对象类型,那就浪费时间了。
在NoBroker项目中,在读取CSV时就验证了类型,因为该项目使用pandas的参数,从一开始就强制要求正确的数据类型。这是代码:
data = pd.read_csv('property_data_set.csv') print(data['activation_date'].dtype) data = pd.read_csv('property_data_set.csv', parse_dates=['activation_date'], infer_datetime_format=True, dayfirst=True) print(data['activation_date'].dtype)这是输出结果。

同样的验证也应用于互动数据集。
interaction = pd.read_csv('property_interactions.csv', parse_dates=['request_date'], infer_datetime_format=True, dayfirst=True)这不仅是良好的实践,对于下游任何操作都至关重要。该项目要求计算激活日期和请求日期之间的日期和时间差。
因此,如果日期是字符串,以下代码将产生错误:
num_req['request_day'] = (num_req['request_date'] - num_req['activation_date']) / np.timedelta64(1, 'D')模式检查将确保结构不变,但现实中,数据分布会随着时间的推移而变化,即数据会发生漂移(Drift)。你可以通过让输入比例略有变化来模拟这种漂移,并检查你的模型或其验证是否能够检测并响应这种漂移。
# 记录你的清理步骤
三个月后,你将不记得为什么将request_day_within_3d限制为10。六个月后,你的队友可能会移除你的异常值过滤器,从而破坏数据管道。一年后,模型投入生产,但没有人理解它为何会失败。
文档记录不是可选的。这是可重现的数据管道与“直到它停止工作才会出问题”的“巫术脚本”之间的区别。
NoBroker 项目在代码注释和结构化的笔记本部分中记录了每一次转换,附有解释和目录。
# Assignment # Read and Explore All Datasets # Data Engineering Handling Pics Data Number of Interactions Within 3 Days Number of Interactions Within 7 Days Merge Data # Exploratory Data Analysis and Processing # Feature Engineering Remove Outliers One-Hot Encoding MinMaxScaler Classical Machine Learning Predicting Interactions Within 3 Days Deep Learning # Try to correct the first Json # Try to replace corrupted values then convert to json # Function to correct corrupted json and get count of photos版本控制也很重要。跟踪清理逻辑的更改。保存中间数据集。记录你尝试过什么以及什么有效。
目标不是完美。目标是清晰。如果你不能解释你做出决定的原因,你就无法在模型失败时为其辩护。
# 最终想法
干净的数据是一种神话。最优秀的数据科学家不是那些逃避混乱数据集的人;而是那些知道如何驯服它们的人。他们在训练之前就发现了缺失值。
他们能在影响预测结果之前识别出异常值。他们在连接表之前检查模式。他们把一切都记录下来,这样下一个人就不必从零开始。
真正的价值不是来自完美的数据。它来自处理错误数据并仍然构建出功能性东西的能力。
因此,当你需要处理一个数据集,看到空值、损坏的字符串和异常值时,不要害怕。你所看到的不是问题,而是利用真实世界数据集展示自己技能的机会。
Nate Rosidi 是一名数据科学家,专注于产品策略。他还是兼职教授,教授分析课程,并且是StrataScratch的创始人。StrataScratch是一个帮助数据科学家利用顶尖公司的真实面试问题来准备面试的平台。Nate撰写关于职业市场最新趋势、提供面试建议、分享数据科学项目以及涵盖所有SQL相关内容。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区