



📢 转载信息
原文作者:Nick McCarthy, Arlind Nocaj, Irene Marban, and Malte Reimann
从发票、收据和表格等文档中提取结构化数据是一个持续存在的业务挑战。格式、布局、语言和供应商的差异使得标准化变得困难,而手动数据录入则速度慢、易出错且无法扩展。传统的光学字符识别(OCR)和基于规则的系统在处理这种复杂性时往往力不从心。例如,一家区域性银行可能需要处理数千份不同的文档——贷款申请、纳税申报单、工资单和身份证件——其中手动方法会造成瓶颈并增加出错风险。智能文档处理(IDP)旨在通过利用 AI 来对文档进行分类、提取或推断相关信息,并验证提取的数据以便在业务流程中使用,从而解决这些挑战。其核心目标之一是将非结构化或半结构化文档转换为可用、结构化的格式,例如 JSON,这些格式包含特定的字段、表格或其他结构化目标信息。目标结构需要保持一致,以便它可以作为工作流程或其他下游业务系统的一部分,或用于报告和洞察生成。下图显示了工作流程,它涉及摄取非结构化文档(例如,来自具有不同布局的多个供应商的发票)并提取相关信息。
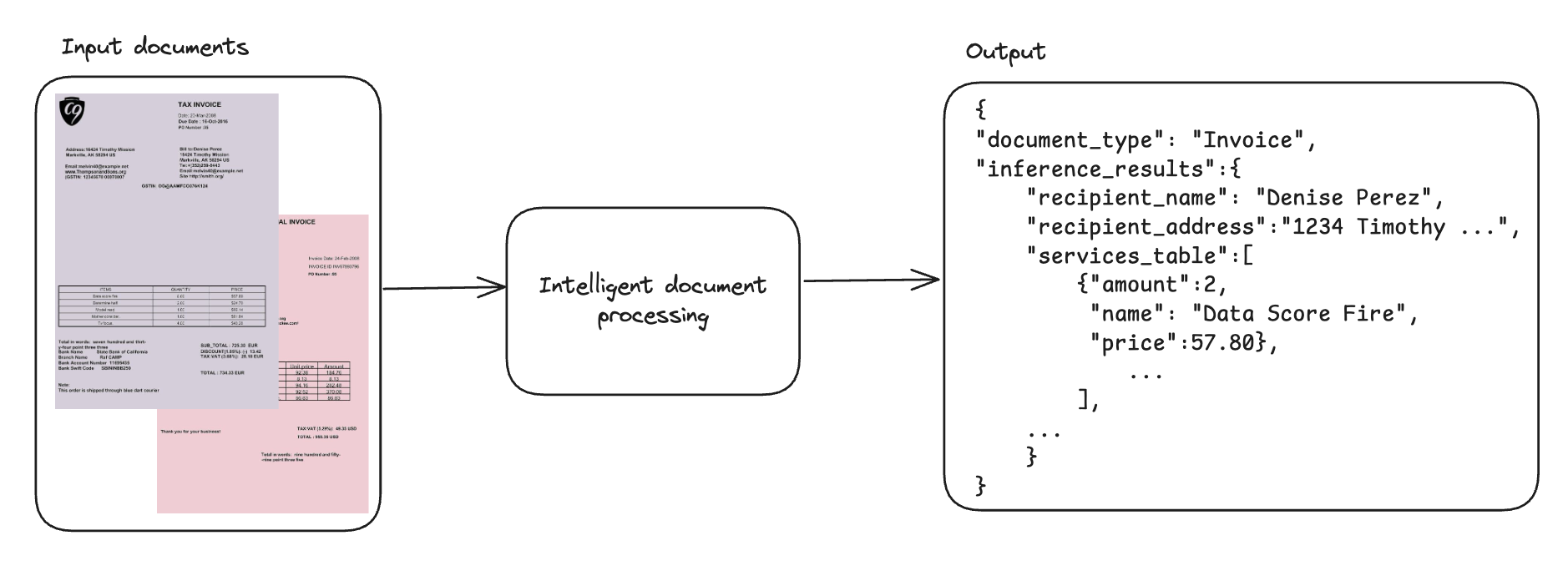
尽管存在关键词、列名或格式差异,但系统仍能将提取的数据规范化并输出为一致的结构化 JSON 格式。
视觉语言模型(VLM)标志着 IDP 领域的一项革命性进步。VLM 将大型语言模型(LLM)与专业图像编码器集成,创造出兼具文本推理和视觉解释能力的真正多模态 AI 能力。与传统的文档处理工具不同,VLM 以更整体的方式处理文档——同时分析文本内容、文档布局、空间关系和视觉元素,其方式更接近人类的理解。这种方法使 VLM 能够以前所未有的准确性和上下文理解能力从文档中提取意义。对于有兴趣探索该技术基础的读者,Sebastian Raschka 的文章——理解多模态 LLM——为多模态 LLM 及其能力提供了极好的入门介绍。
本文有四个主要部分,反映了我们工作的主要贡献,其中包括:
- 概述各种可用的 IDP 方法,包括作为可扩展方法的微调选项(我们推荐的解决方案)。
- 使用 Amazon SageMaker AI 和 SWIFT 框架对 VLM 进行微调以实现文档到 JSON 转换的示例代码,SWIFT 是一个用于微调各种大型模型的轻量级工具包。
- 开发一个评估框架来评估处理结构化数据的性能。
- 讨论可能的部署选项,包括一个明确的部署微调适配器的示例。
SageMaker AI 是一项全托管服务,用于大规模构建、训练和部署模型。在本文中,我们使用 SageMaker AI 来微调 VLM,并部署它们以进行批量和实时推理。
先决条件
在开始之前,请确保已完成以下设置,以便您能够成功遵循本文和附带的 GitHub 存储库中概述的步骤:
- AWS 账户:您需要一个活跃的 AWS 账户,并拥有创建和管理 SageMaker AI、Amazon Simple Storage Service (Amazon S3) 和 Amazon Elastic Container Registry (Amazon ECR) 中资源的权限。
- IAM 权限:您的 IAM 用户或角色必须具有足够的权限。对于生产设置,请遵循 IAM 中的安全最佳实践中所述的最小权限原则。对于沙盒设置,我们建议以下角色:
- 对 Amazon SageMaker AI 的完全访问权限(例如,
AmazonSageMakerFullAccess)。 - 对 S3 存储桶的读/写访问权限,用于存储数据集和模型工件。
- 向 Amazon ECR 推送和拉取 Docker 镜像的权限(例如,
AmazonEC2ContainerRegistryPowerUser)。 - 如果使用特定的 SageMaker 实例类型,请确保您的服务配额足够。
- 对 Amazon SageMaker AI 的完全访问权限(例如,
- GitHub 存储库:从我们的 GitHub 存储库克隆或下载项目代码。此存储库包含本文中引用的 Notebook、脚本和 Docker 工件。
-
git clone https://github.com/aws-samples/sample-for-multi-modal-document-to-json-with-sagemaker-ai.git
-
- 本地环境设置:
- Python:建议使用 Python 3.10 或更高版本。
- AWS CLI:确保已安装 AWS 命令行界面 (AWS CLI) 并使用具有必要权限的凭证进行了配置。
- Docker:如果计划构建用于部署的自定义 Docker 容器,则必须在本地机器上安装并运行 Docker。
- Jupyter Notebook 和 Lab:用于运行提供的 Notebook。
- 通过在克隆的存储库的根目录中运行
pip install -r requirements.txt来安装所需的 Python 包。
- 熟悉度(推荐):
- 对 Python 编程有基本了解。
- 熟悉 AWS 服务,特别是 SageMaker AI。
- 了解 LLM、VLM 和容器技术等概念将是有益的。
文档处理和生成式 AI 方法概述
智能文档处理具有不同程度的自主性。在一个极端是完全的手动流程:人工阅读文档并通过计算机系统使用表单输入信息。目前大多数系统是半自主的文档处理解决方案。例如,一个人拍摄收据的照片并将其上传到计算机系统,该系统会自动提取部分信息。目标是实现完全自主的智能文档处理系统。这意味着降低错误率并评估特定用例的错误风险。AI 正在通过实现更高水平的自动化,显著改变文档处理。存在各种方法,其复杂性和准确性各不相同——从用于 OCR 的专业模型到生成式 AI。
不依赖生成式 AI 的专业 OCR 模型被设计为预训练的、特定于任务的 ML 模型,它们擅长从常见文档类型(如发票、收据和身份证件)中提取结构化信息,如表格、表单和键值对。Amazon Textract 就是此类服务的一个示例。此服务开箱即用地提供高准确性,并且只需要最少的设置,非常适合需要基本文本提取且文档结构或图像内容不发生显著变化的工作负载。
但是,随着您增加文档的复杂性和可变性,除了增加多模态性之外,使用生成式 AI 可以帮助改进文档处理管道。
虽然通用 VLM 或 LLM 功能强大,但将其应用于文档处理并不直接。有效的提示工程对于指导模型很重要。处理大量文档(扩展)需要高效的批处理和基础设施。由于 LLM 是无状态的,为每个文档提供历史上下文或特定架构要求可能会很麻烦。
使用 LLM 或 VLM 的智能文档处理方法分为四类:
- 零样本提示(Zero-shot prompting):基础模型 (FM) 接收先前 OCR 或 PDF 的结果以及执行文档处理任务的指令。
- 少样本提示(Few-shot prompting):FM 接收先前 OCR 或 PDF 的结果、执行文档处理任务的指令以及一些示例。
- 检索增强式少样本提示(Retrieval-augmented few-shot prompting):与前一种策略类似,但发送给模型的示例是使用检索增强生成 (RAG) 动态选择的。
- 微调 VLM
在下图中,可以看到努力和复杂性增加与任务准确性之间的关系,展示了从基本提示工程到高级微调的不同技术如何影响大型和小型基础模型与专业解决方案(灵感来自博客文章 比较 LLM 微调方法)的性能比较。
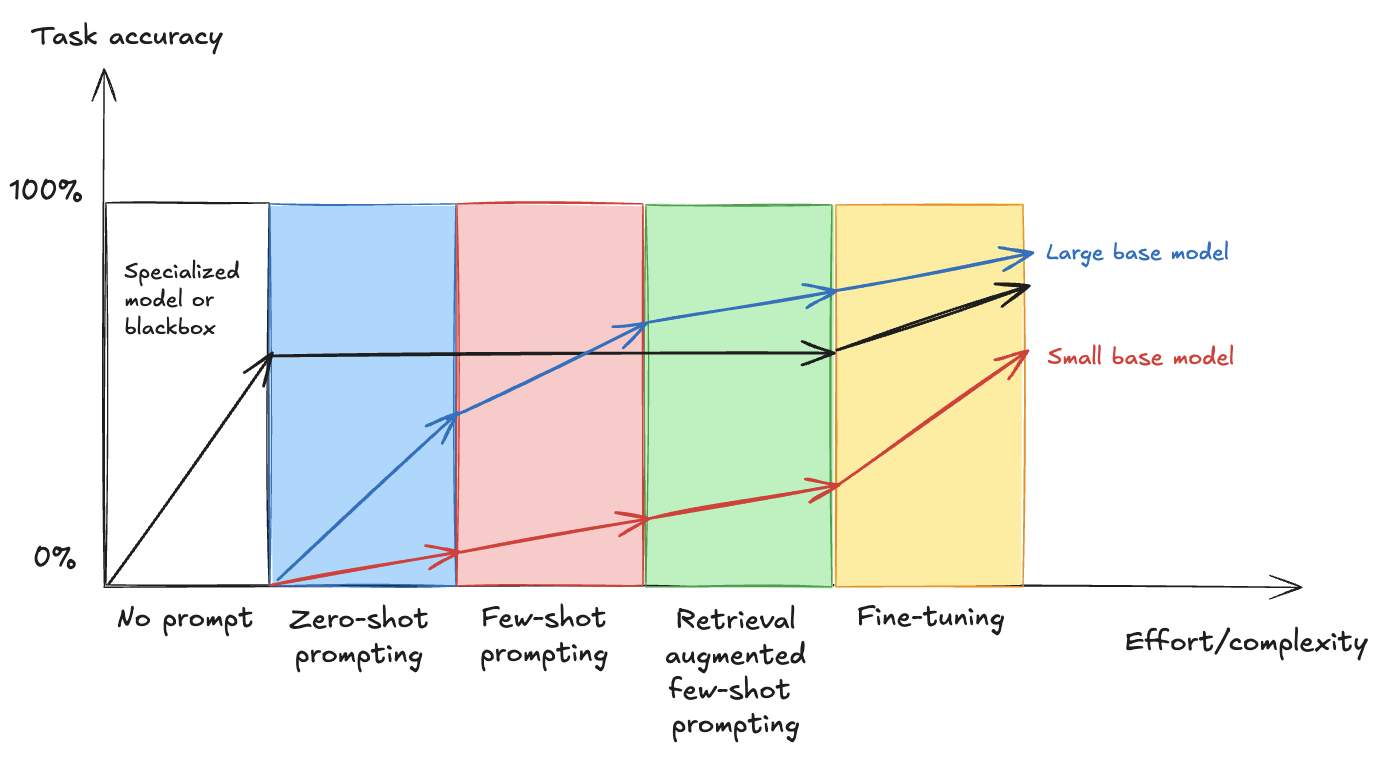
当您沿着水平轴移动时,策略的复杂性增加,当您沿着垂直轴向上移动时,整体准确性提高。通常,大型基础模型在需要提示工程的策略中比小型基础模型提供更好的性能,然而正如我们在本文的结果中所解释的,对小型基础模型进行微调可以为特定任务带来与对大型基础模型进行微调相似的结果。
零样本提示
零样本提示是一种使用语言模型的技术,其中模型在没有先前示例或微调的情况下接收任务。相反,它完全依赖于提示的措辞及其预训练知识来生成响应。在文档处理中,这种方法涉及向模型提供 PDF 文档的图像、从 PDF 中提取的 OCR 文本或文档的结构化 Markdown 表示形式,并提供执行文档处理任务以及所需输出格式的说明。
Amazon Bedrock 数据自动化使用生成式 AI 上的零样本提示来执行 IDP。您可以使用 Bedrock 数据自动化来自动化多模态数据(包括包含文本和复杂结构(如表格、图表和图像)的文档)到结构化格式的转换。您可以通过使用自然语言或架构编辑器指定输出要求的蓝图,从而受益于定制功能。Bedrock 数据自动化还可以提取已识别实体的边界框,并将文档适当地路由到正确的蓝图。这些功能可以通过单个 API 进行配置和使用,使其比基本零样本提示方法强大得多。
虽然开箱即用的 VLM 可以有效地处理一般 OCR 任务,但它们通常难以处理自定义文档(例如来自不同供应商的发票)的独特结构和细微差别。尽管为单个文档设计提示可能很简单,但数百种供应商格式的变化使得提示迭代成为一项劳动密集型且耗时的过程。
少样本提示
进入更复杂的方法,您可以使用少样本提示,这是一种与 LLM 配合使用的技术,在该技术中,在提示中提供少量示例以指导模型完成特定任务。与仅依赖自然语言指令的零样本提示不同,少样本提示通过示例演示所需的输入-输出行为,从而提高了准确性和一致性。
一种替代方法是使用 Amazon Bedrock Converse API 来执行少样本提示。Converse API 提供了一种使用 Amazon Bedrock 访问 LLM 的一致方法。它支持用户和生成式 AI 模型之间的轮次消息传递,并允许在内容中包含 文档。另一个选项是使用 Amazon SageMaker Jumpstart,您可以使用它来部署来自 HuggingFace 等提供商的模型。
然而,您的企业很可能需要处理不同类型的文档(例如,发票、合同和手写笔记),即使在一种文档类型中也存在许多变化,例如,没有一个标准化的发票布局,而是每个供应商都有自己的布局,而您无法控制。找到一个或几个示例来涵盖您想要处理的所有不同文档是一项具有挑战性的任务。
检索增强式少样本提示
解决寻找正确示例挑战的一种方法是在运行时动态检索先前处理的文档作为示例并将其添加到提示中(RAG)。
您可以将一些已注释的样本存储在向量存储中,并根据需要处理的文档从其中检索它们。Amazon Bedrock Knowledge Bases 帮助您实施从摄取到检索和提示增强的整个 RAG 工作流程,而无需构建到数据源的自定义集成和管理数据流。
这会将智能文档处理问题转化为搜索问题,这带来了如何提高搜索准确性的挑战。除了如何为多种文档类型进行扩展之外,少样本方法成本很高,因为处理的每个文档都需要带有示例的更长提示。这会导致输入 token 数量增加。
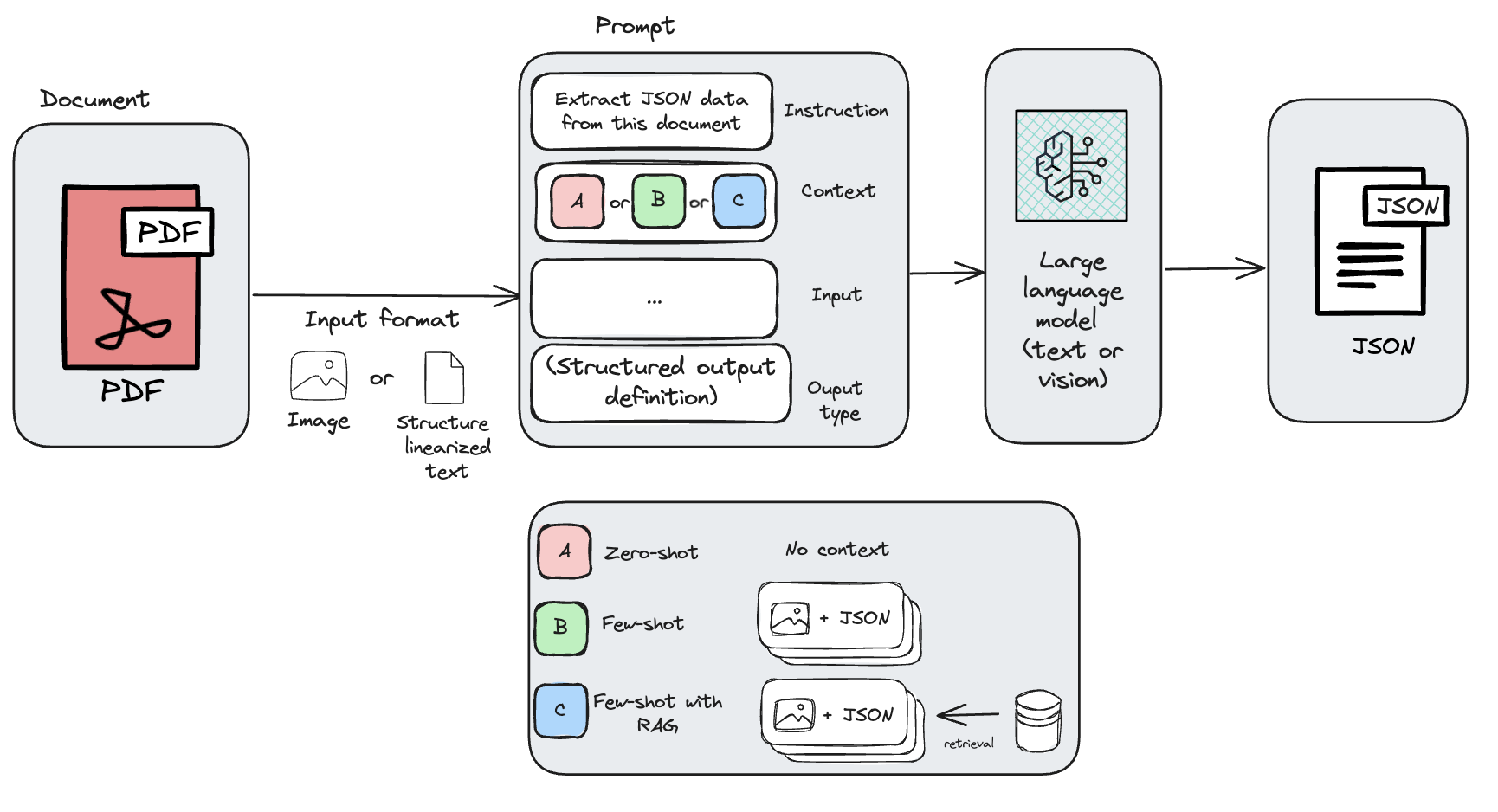
如上图所示,提示上下文将根据所选策略(零样本、少样本或带 RAG 的少样本)而变化,这将总体上改变获得的结果。
微调 VLM
在光谱的另一端,您可以选择微调自定义模型来执行文档处理。这是我们推荐的方法,也是我们在本文中关注的重点。微调是一种方法,其中对预训练的 LLM 进行了进一步训练,以使其针对特定任务或领域进行专业化。在文档处理的背景下,微调涉及使用带标签的示例——例如,带注释的发票、合同或保险表格——来教模型如何准确地提取或解释相关信息。通常,微调中最耗费人力的部分是获取合适的高质量数据集。在文档处理的情况下,您的公司可能已经在其现有的文档处理系统中拥有历史数据集。您可以从文档处理系统(例如企业资源规划 (ERP) 系统)导出这些数据,并将其用作微调的数据集。我们在这篇文章中关注的这种微调方法是实现智能文档处理的一种可扩展、高精度且经济高效的方法。
上述方法代表了一系列策略,可通过两个轴来提高 LLM 性能:LLM 优化(通过提示工程或微调塑造模型行为)和上下文优化(通过少样本学习或 RAG 等技术增强模型在推理时所知的内容)。可以组合使用这些方法——例如,将 RAG 与少样本提示结合使用或将检索到的数据合并到微调中——以最大限度地提高准确性。
使用 SWIFT 对 VLM 进行微调以实现文档到 JSON 转换
我们的方法——用于经济高效的文档到 JSON 转换的推荐解决方案——使用 VLM,并使用历史文档及其对应的地面实况 JSON(我们将其视为注释)的数据集对其进行微调。这使得模型能够学习与您的历史数据相关的特定模式、字段和输出结构,有效地教它如何根据您所需的架构“阅读”您的文档并提取信息。
下图显示了使用历史数据微调 VLM 的文档到 JSON 转换过程的高级架构。这使得 VLM 能够从高数据变化中学习,并有助于确保结构化输出与目标系统的结构和格式相匹配。
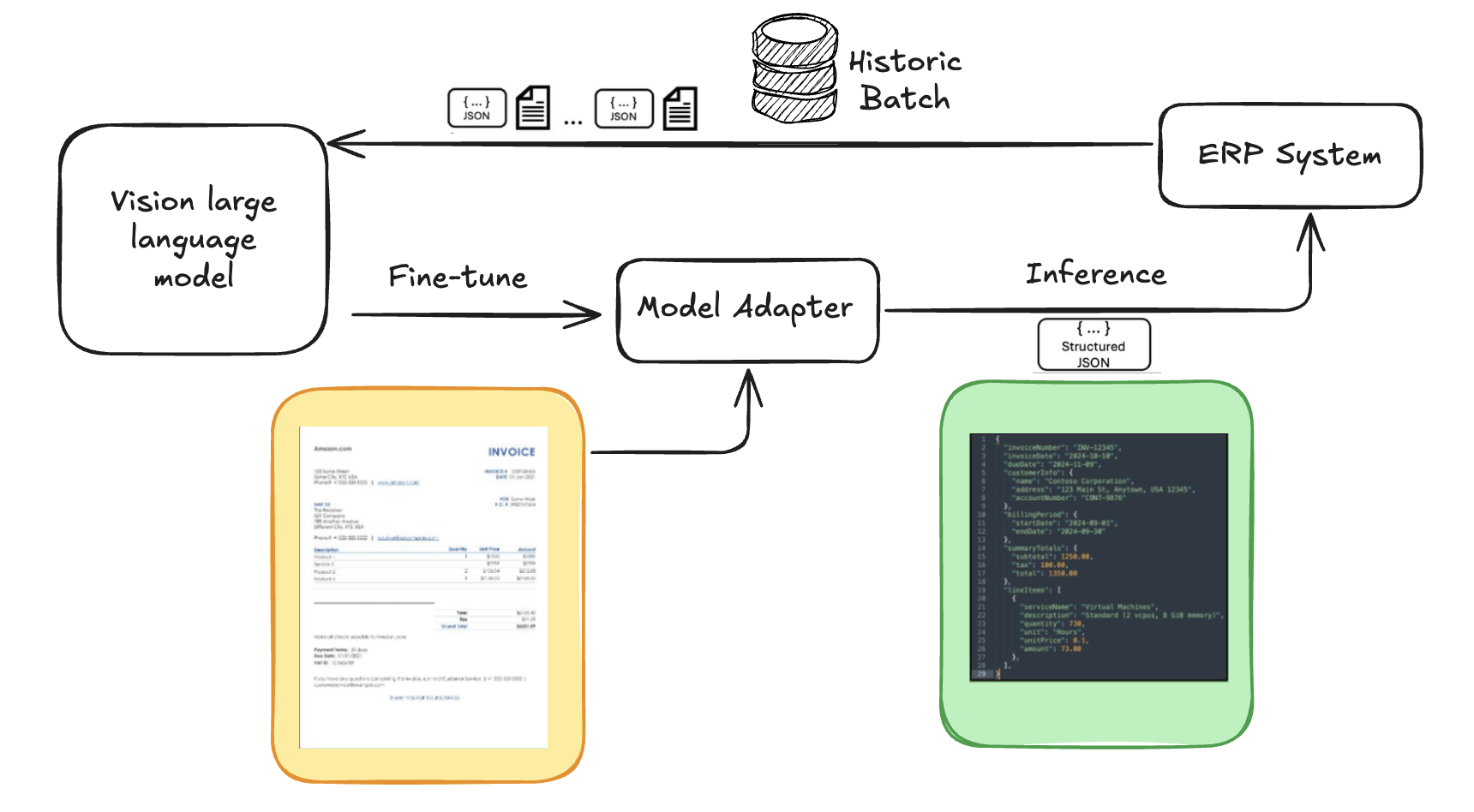
与仅依赖 OCR 或通用 VLM 相比,微调具有以下几个优势:
- 架构依从性:模型学习输出与特定目标结构匹配的 JSON,这对于与 ERP 等下游系统的集成至关重要。
- 隐式字段定位:微调的 VLM 通常学会定位和提取字段,而无需训练数据中的显式边界框注释,从而大大简化了数据准备工作。
- 改进的文本提取质量:即使在视觉复杂或嘈杂的文档布局中,模型在提取文本方面的准确性也会提高。
- 上下文理解:模型可以更好地理解文档上不同信息片段之间的关系。
- 减少提示工程:微调后,由于所需的提取行为已内置到模型的权重中,因此模型需要的复杂或更长的提示更少。
对于我们的微调过程,我们选择了 Swift 框架。Swift 提供了一个全面、轻量级的工具包,用于微调各种大型语言模型,包括 Qwen-VL 和 Llama-Vision 等 VLM。
数据准备
为了微调 VLM,您将使用 Fatura2 数据集,这是一个包含 10,000 份具有 50 种不同布局的发票的多布局发票图像数据集。
Swift 框架期望训练数据采用特定的 JSONL(JSON Lines)格式。文件中的每一行都是一个 JSON 对象,代表单个训练示例。对于多模态任务,此 JSON 对象通常包括:
messages:一系列对话轮次(例如,system、user、assistant)。用户轮次包含图像(例如,<image>)的占位符和指导模型的文本提示。助手轮次包含目标输出,在本例中是地面实况 JSON 字符串。images:数据集目录结构内与此训练示例相关的文档页面图像(JPG 文件)的相对路径列表。
与标准 ML 实践一样,数据集被划分为训练集、开发集(验证集)和测试集,以有效地训练模型、调整超参数并在未见数据上评估其最终性能。每个文档(可以是单页或多页)及其对应的地面实况 JSON 注释构成了我们数据集中的一行或一个示例。在我们的用例中,一个训练样本是发票图像(或多页文档图像)和相应的详细 JSON 提取。这种一对一的映射对于监督微调至关重要。
转换过程在 关联的 GitHub 仓库的数据集创建 Notebook 中有详细说明,涉及几个关键步骤:
- 图像处理:如果源文档是 PDF,则将每一页渲染成高质量的 PNG 图像。
- 注释处理(填充缺失值):我们对原始 JSON 注释应用轻量级预处理。在开源数据集上微调多个模型时,我们观察到当所有键都存在于每个 JSON 样本中时,性能会提高。为了保持这种一致性,数据集中目标 JSON 被制作成包含一组相同的顶级键(从整个数据集中派生)。如果某个文档缺少某个键,则会添加该键并将其值设为 null。
- 键排序:处理后的 JSON 注释中的键按字母顺序排序。这种一致的排序有助于模型学习稳定的输出结构。
- 提示构建:构建一个用户提示。此提示包含 <image> 标签(每个文档页面一个)并明确列出模型应提取的 JSON 键。在提示中包含 JSON 键可以提高微调模型的性能。
- Swift 格式化:将这些组件(提示、图像路径、目标 JSON)组装成 Swift JSONL 格式。Swift 数据集支持多模态输入,包括图像、视频和音频。
以下是 Swift JSONL 格式中单个训练实例的示例结构,演示了如何组织多模态输入。这包括对话消息、图像路径以及包含边界框 (bbox) 坐标的对象,用于在文本中进行视觉引用。有关如何为 Swift 创建自定义数据集的更多信息,请参阅 Swift 文档。
{ "messages": [ {"role": "system", "content": "Task definition"}, {"role": "user", "content": "<image><image>... + optional text prompt"}, {"role": "assistant", "content": "JSON or text output with extracted data with <bbox> references."} ], "images": ["path/to/image1.png", "path/to/image2.png"] "objects": {"ref": [], "bbox": [[90.9, 160.8, 135, 212.8], [360.9, 480.8, 495, 532.8]]} #Optional }微调框架和资源
在对用于 SageMaker AI 的微调框架进行评估时,我们考虑了几种在社区中突出显示且与我们的需求相关的突出选项。这些包括 Hugging Face Transformers、Hugging Face Autotrain、Llama Factory、Unsloth、Torchtune 和 ModelScope SWIFT(在本文中简称为 SWIFT,与 Zhao 等人 2024 年的 SWIFT 论文保持一致)。
在试验了这些之后,我们决定使用 SWIFT,因为它具有轻量级的特性、对各种参数高效微调 (PEFT) 方法(如 LoRA 和 DoRA)的全面支持,以及专为高效训练各种模型(包括本文中使用的 VLM,例如 Qwen-VL 2.5)而设计的特性。其脚本化方法与 SageMaker AI 训练作业无缝集成,支持在云中进行可扩展且可重现的微调运行。
有几种策略可以调整预训练模型:全微调(更新所有模型参数)、PEFT(通过仅更新少量新参数(适配器)提供更高效的替代方案)和量化(一种使用低精度格式减少模型大小并加速推理的技术(请参阅 Sebastian Rashka 关于微调的帖子以了解更多关于每种技术的信息))。
我们的项目在微调 Notebook 中使用了 LoRA 和 DoRA 的配置。
以下是使用 SWIFT 和远程函数将 LoRA 微调配置并作为 SageMaker AI 训练作业运行的示例。执行此函数时,微调将作为 SageMaker AI 训练作业在远程执行。
from sagemaker.remote_function import remote import json import os
@remote (instance_type="ml.g6e.12xlarge", volume_size=200, use_spot_instances=True)
def fine_tune_document (training_data_s3, train_data_path="train.jsonl" , validation_data_path="validation.jsonl"):
from swift.llm.sft import lim_sft, get_sft_main
from swift.llm import sft_main
## copy the training data from input source to local directory ...
train_data_local_path = ...
validation_data_local_path = ...
# set and run the fine-tuning using ms-swift framework
os.environ["SIZE_FACTOR"] = json.dumps(8)# can be increase but requires more GPU memory
os.environ["MAX_PIXELS"]= json.dumps (602112) # can be increase but requires more GPU memory
os. environ ["CUDA_VISIBLE_DEVICES"]="0,1,2,3" # GPU devices to be used
os. environ ["NPROC_PER_NODE"]="4" # we have 4 GPUs on on instance
os.environ["USE_H_TRANSFER"] = json.dumps (1)
argv = ['—model_type', 'qwen2_5_vl', '-model_id_or_path', 'Qwen/Qwen2.5-VL-3B-Instruct', '--train_type', 'lora', '--use_dora', 'true', '-output_dir', checkpoint_dir, '—max_length', '4096', '-dataset', train_data_local_path, '--val_dataset', validation_data_local_path, ... ]
sft_main (argv)
## potentially evaluate inference on test dataset
return "done"
微调 VLM 通常需要 GPU 实例,因为它们计算需求很高。对于 Qwen2.5-VL 3B 等模型,像 Amazon SageMaker AI ml.g5.2xlarge 或 ml.g6.8xlarge 这样的实例可能适用。训练时间是数据集大小、模型大小、批处理大小、训练周期数和其他超参数的函数。例如,正如我们在项目 readme.md 中所指出的,微调...
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区